文章主题:抱歉,我需要您提供文章的内容以便提取关键词。请您提供相关文章内容,我将尽力为您提取关键词。
Compositional Attention Networks for Machine Reasoning
@NoaRicky 推荐
#Machine Reasoning
这篇文章是由斯坦福大学在ICLR 2018上发表的研究成果,主要针对机器阅读和机器推理中的树状结构网络进行了改进。尽管此类网络在其他领域表现优秀,但在模型训练上却存在较长的时间问题。然而,令人欣慰的是,该研究在准确度上超越了过往的所有模型。值得一提的是,这篇文章的作者之一是斯坦福CS224n课程的教授Manning教授,而该模型的实现则由Stanford NLP团队完成。

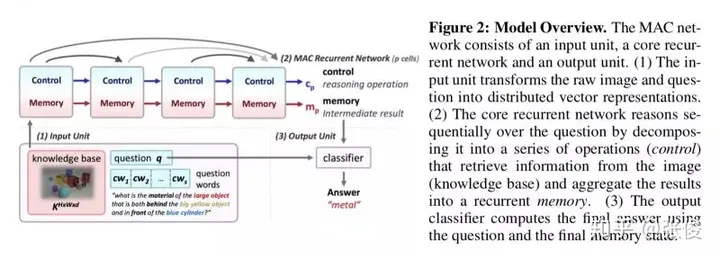
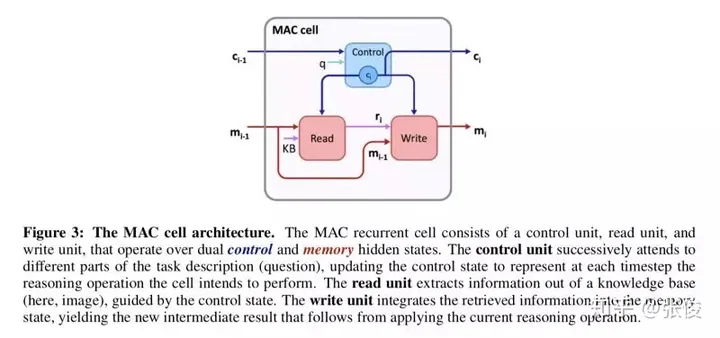
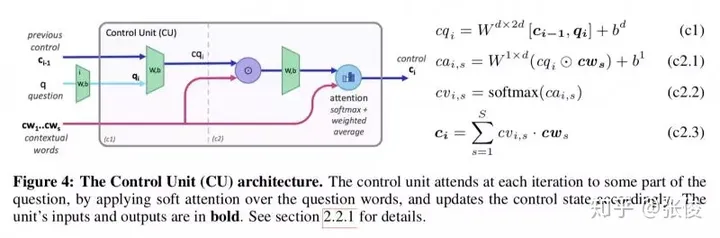
论文链接:https://www.paperweekly.site/papers/2207
源码链接:https://github.com/stanfordnlp/mac-network
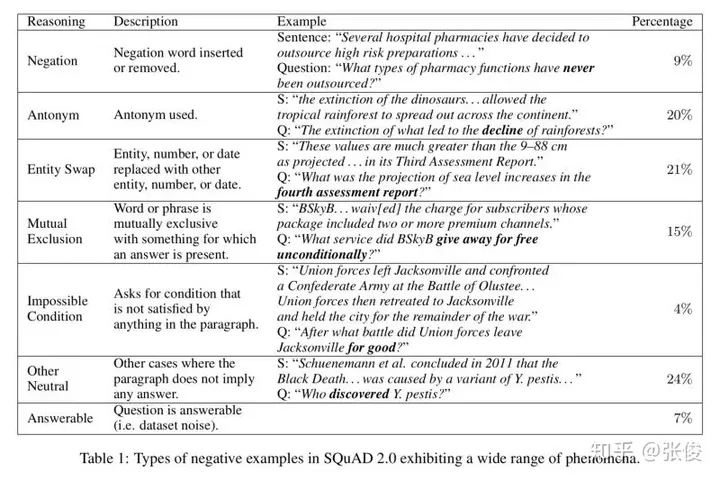
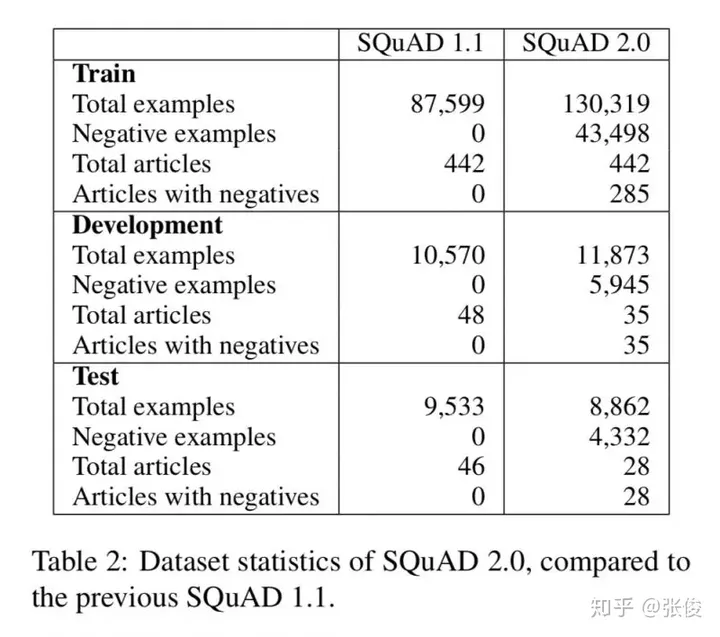
Know What You Dont Know: Unanswerable Questions for SQuAD
@guohao916 推荐
#Machine Reading Comprehension
这篇文章是由斯坦福大学在ACL 2018上发表的研究成果,该论文在原有的SQuAD(SQuAD 1.1)的十万个问题-答案对基础上,进一步扩展了SQuAD 2.0。在SQuAD 2.0中,新增了超过五万个由人类众包者对抗性地设计都无法回答的问题。对于执行SQuAD 2.0阅读理解任务的模型,除了在问题可以回答的情况下提供答案外,还需要判断哪些问题在阅读文本中没有找到支持,从而拒绝回答这些问题。
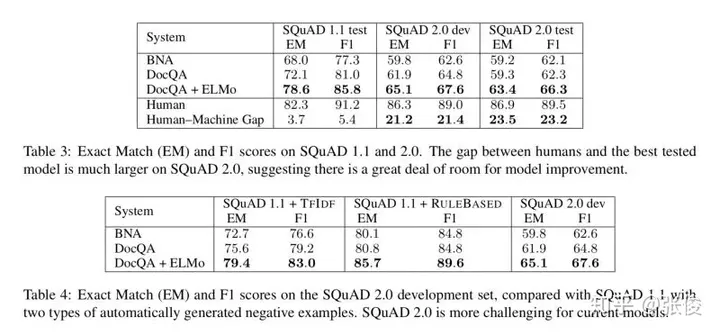

论文链接:https://www.paperweekly.site/papers/2180
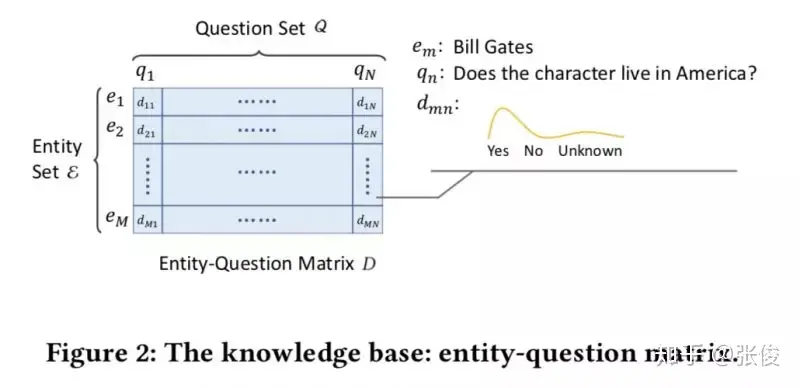
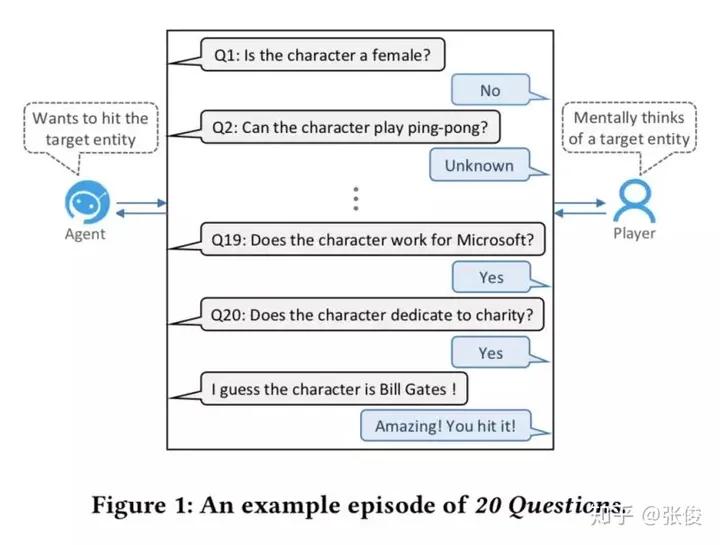
Learning-to-Ask: Knowledge Acquisition via 20 Questions
@yihongchen 推荐
#Knowledge Discovery
这篇文章是由清华大学、微软和阿里巴巴三个机构于KDD 2018会议联合发表的。文章主要探讨了如何让机器拥有智能,并且提出了一个基于深度强化学习和矩阵分解的名为Learning-to-Ask的方法。该方法能够有效地提高提问的效率和准确性,同时,为了增强其鲁棒性,我们采用了贝叶斯知识表示方法。
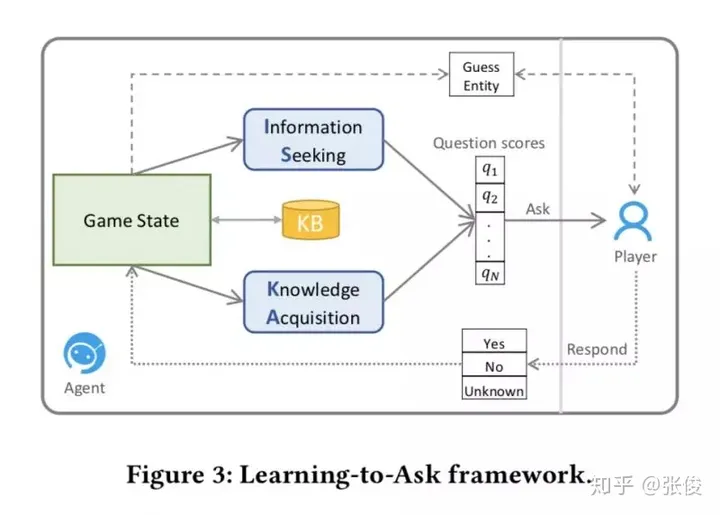
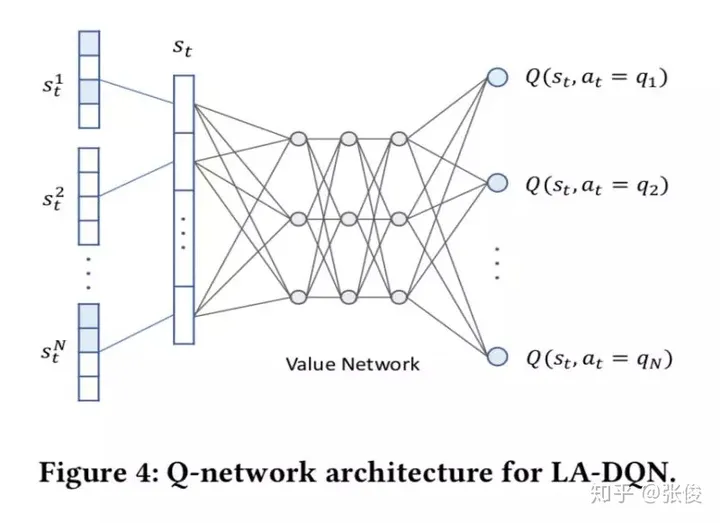
论文链接:https://www.paperweekly.site/papers/2174
Simple and Effective Multi-Paragraph Reading Comprehension
@guohao916 推荐
#Question Answering
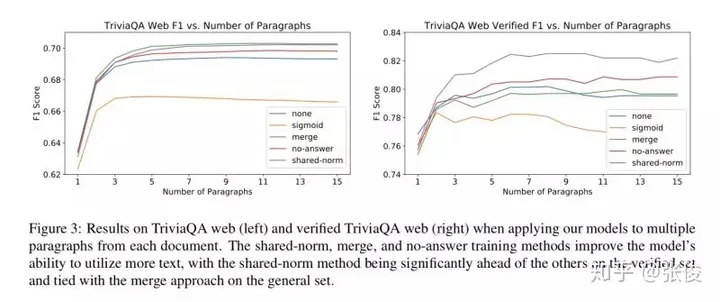
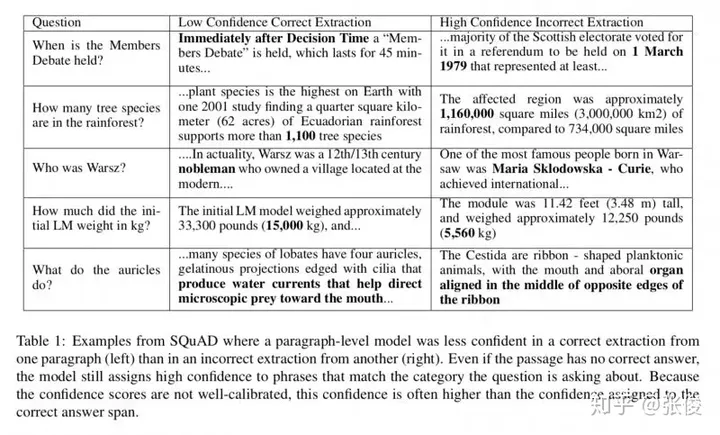
这篇文章的主要目标是将段落的神经问答模型提升到篇章级别。在训练过程中,我们采集了许多段落数据,并对目标函数进行了优化,以实现全局正确的输出。当输入是篇章时,处理方式主要有两种:一种是流水线方法,先选定一个最相关的段落进行预测,另一种是基于置信度的方法,将模型应用在多个段落中,返回最大置信度。基于置信度的方法在段落选择错误的情况下具有很强的鲁棒性,但这就要求模型能够对每个段落计算出较为精确的置信度。
在本研究中,我们巧妙地将两种策略融合,使得流水线方法能够更精准地估算各个段落的置信度。首先,我们利用TF-IDF挑选出适合训练和测试的段落。考虑到语料库存在较大的远程监督噪声,我们将目标函数设定为所有可能答案位置的边缘值。随后,我们采用一个共享的规范化目标函数,让答案选择基于篇章中各段落的比较,从而显著提升了模型的稳健性。
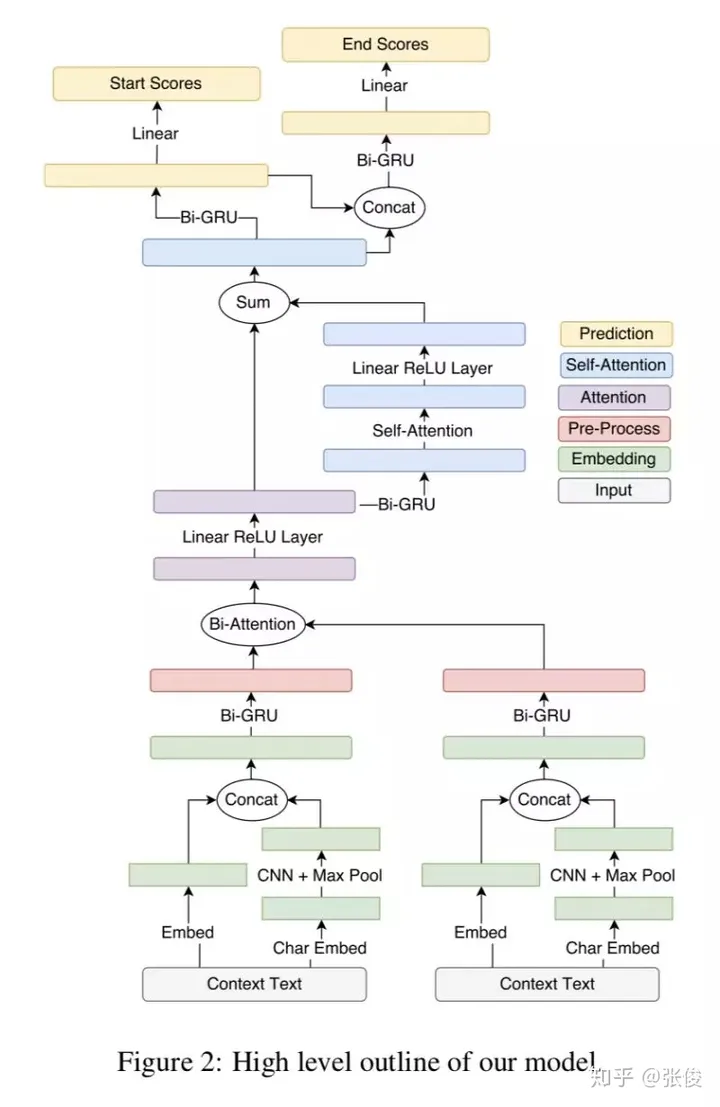
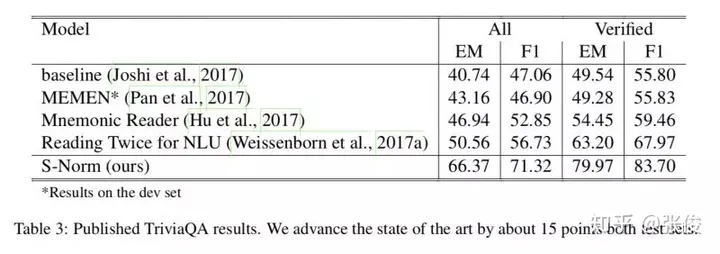
论文链接:https://www.paperweekly.site/papers/2179
源码链接:https://github.com/allenai/document-qa
Towards Human-Machine Cooperation: Self-supervised Sample Mining for Object Detection
@kezewang 推荐
#Object Detection
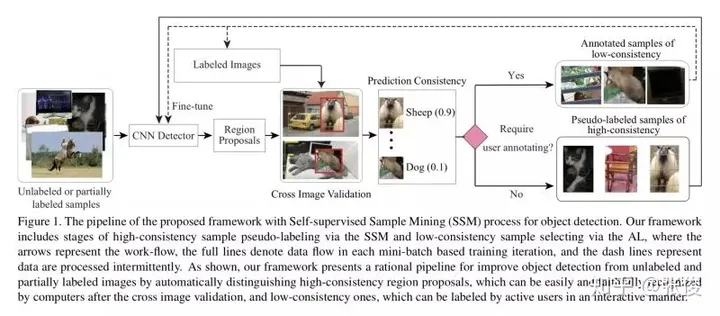
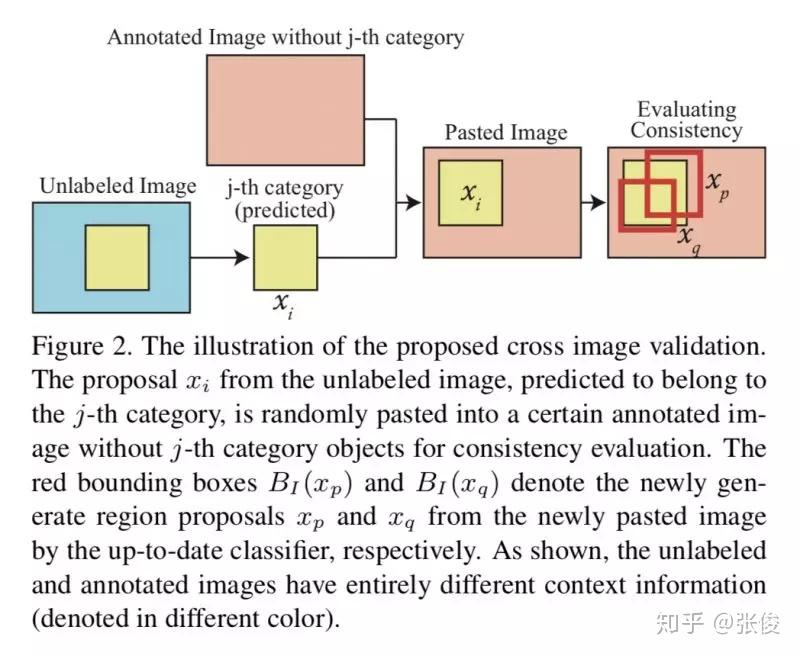
在互联网迅速发展和计算能力飞跃的推动下,近年来深度学习技术依托大规模训练数据实现了显著的突破。在计算机视觉领域,物体检测这一经典任务如今已经取得了令人瞩目的成果。基于候选区域构建的物体检测网络,能够从一张图像中提取出大量潜在的物体区域,并对这些区域进行类别识别和位置回归,从而大大提高了物体检测的识别准确率和处理速度。然而,值得注意的是,神经网络的检测效果高度依赖于训练网络的标注样本数据。因此,如何有效地利用大规模的未标注或标注质量较低的数据来训练网络,进一步提升其检测精度,已成为当前亟待解决的重要问题。
为了使用更少的标注数据训练出高精度的检测模型,一般需要解决以下技术问题:
1. 在保证模型效果的同时,尽量减少人工样本标注。通常的神经网络训练,非常依赖大量人工标注的数据集,而比起其他视觉任务(例如,图像分类和动作识别),标注物体需要提供图片中所有物体的类别标签和物体所处区域的边框坐标。因此,对图像进行人工标注非常耗时耗力,发展自动标注无标签数据的方法是减少人工标注负担的关键步骤。
2. 挖掘能够显著提高分类器表现的特殊训练样本。现有的物体检测数据集通常包含了绝大多数普通的“简单”样本和少量有益的“困难”样本(即,富含各种光照,变形,遮挡和类内变化的信息量)。因为他们服从长尾分布,“困难”的例子是罕见的,为了利用这些能够最有效训练神经网络的“困难”样本,需要能够从大量样本中将其识别出来。
3. 抑制坏样本的负面影响。一些训练样本(例如,离群点或噪声样本)可能会使模型发生偏移,在训练时排除被数据集中的标注者标记为“混乱”的样本后,训练得到的物体检测性能可以得到大幅度的改进和提高。
为克服上述现有技术存在的不足,我们的研究动机在于提供一种基于自监督过程改进主动学习的通用物体检测系统及方法,以结合样本挖掘技术和深度学习物体检测技术,利用少量标注的样本和海量的未标注样本联合训练提升模型的检测性能以提高检测精度。 同时,可在减少大量的人力物力、节约成本基础上实现通用物体检测目的。
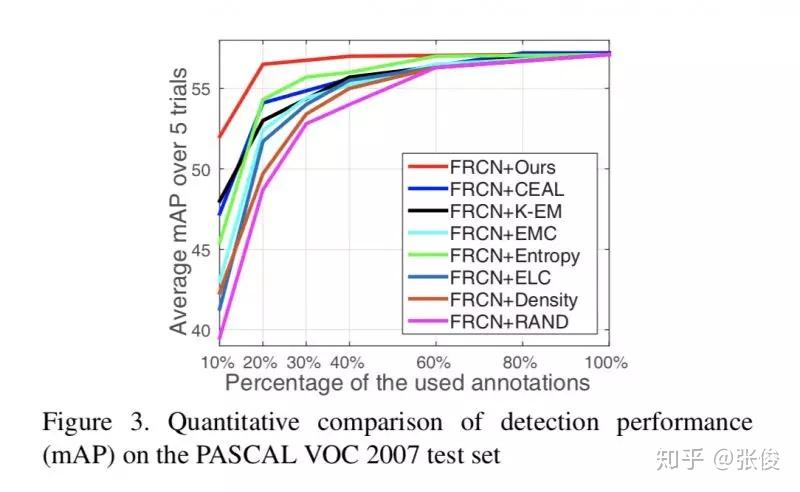
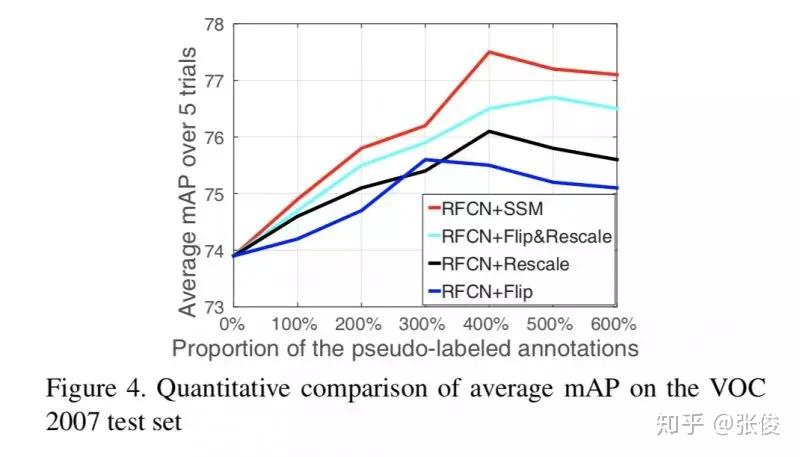
论文链接:https://www.paperweekly.site/papers/2177
源码链接:https://github.com/yanxp/SSM
Attention-Gated Networks for Improving Ultrasound Scan Plane Detection
@hsu 推荐
#Semantic Segmentation
本文是 Attention U-Net 的前序文章,论文提出了 Attention Gate,和主流方法一样使用的是 soft-attention 机制。文章将 Attention-Gate 应用于超声图像的分类问题,包括若干器官。
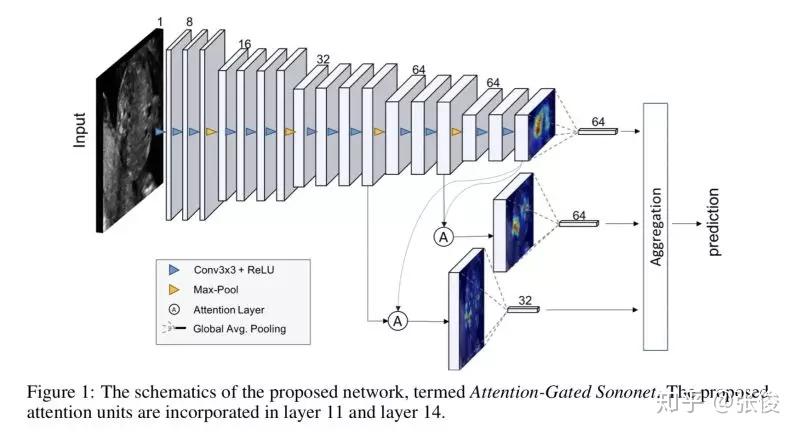
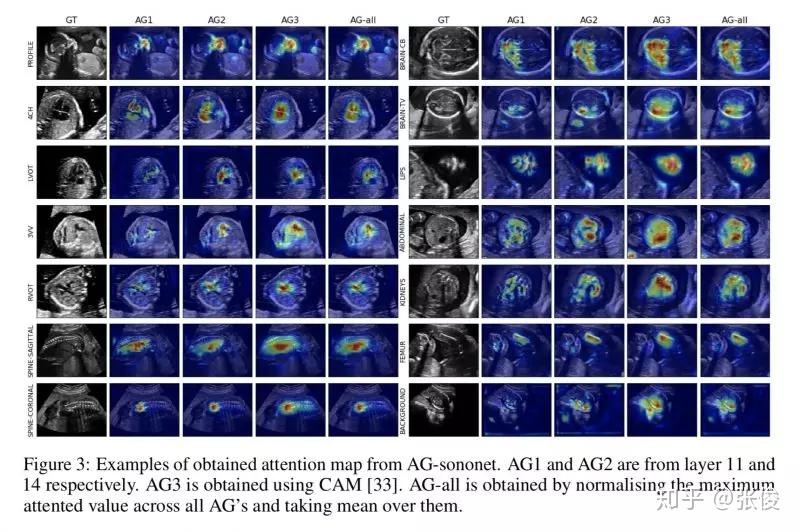
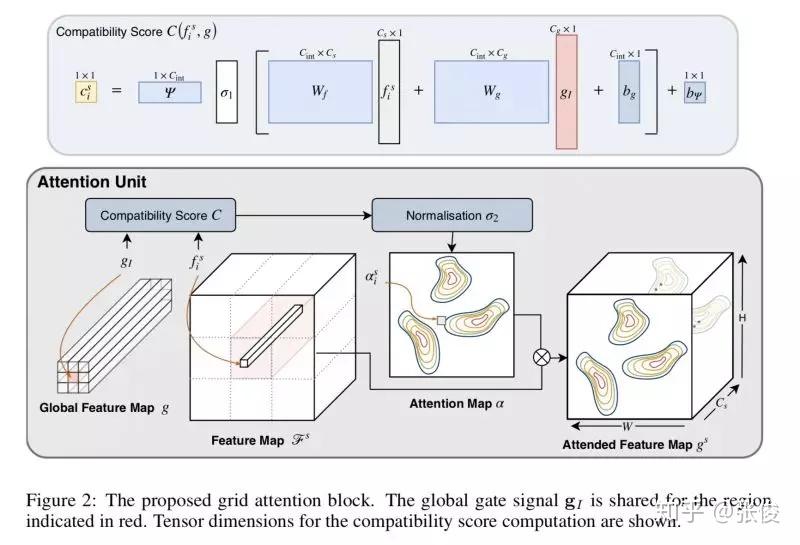
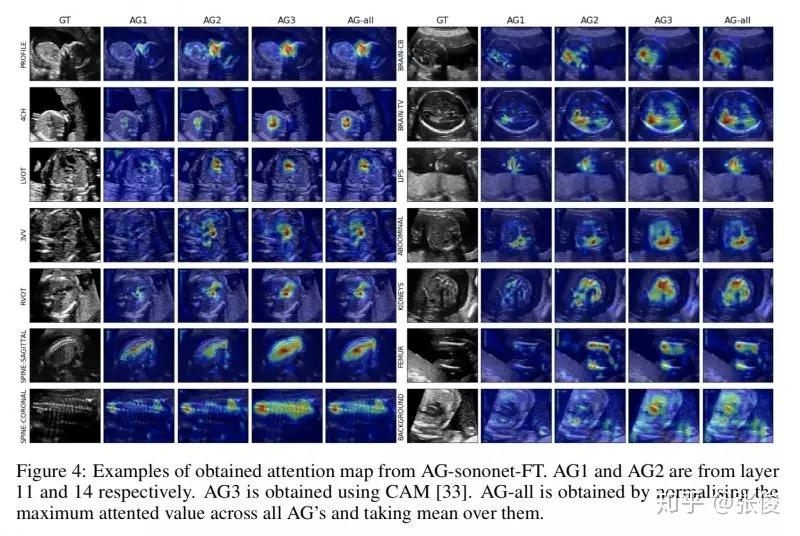
论文链接:https://www.paperweekly.site/papers/2198
源码链接:https://github.com/ozan-oktay/Attention-Gated-Networks
CLIP-Q: Deep Network Compression Learning by In-Parallel Pruning-Quantization
@yanjoy 推荐
#Model Compression
本文是西蒙弗雷泽大学发表于 CVPR 2018 的工作,论文提出先剪枝后量化的压缩框架,并且自动优化超参数。结果在 GoogLeNet 上有 10x 压缩,在 ResNet-50 有 15x 压缩,并不降低准确率。

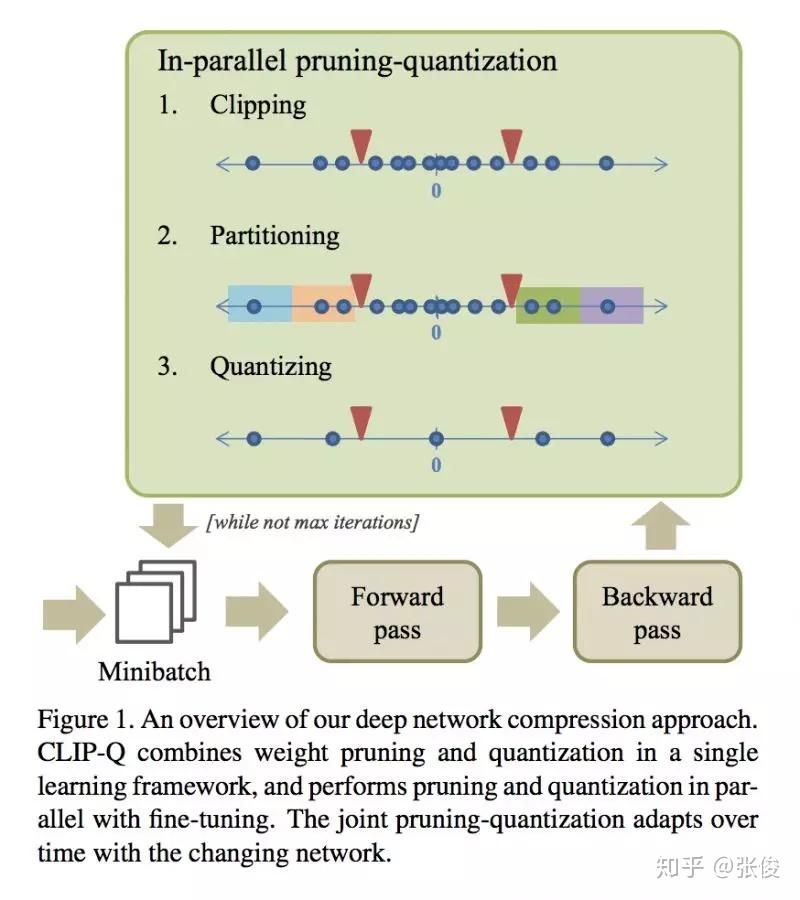

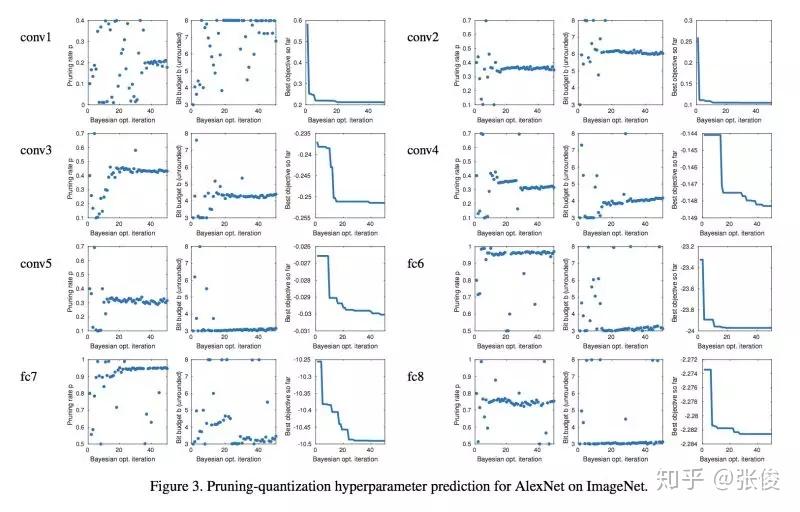
论文链接:https://www.paperweekly.site/papers/2181
deepNF: deep network fusion for protein function prediction
@xuehansheng 推荐
#bioinformatics
本文将深度学习应用到多网络融合的过程中,并针对蛋白质功能预测的网络结构特点,提出了一种基于多模式深度自动编码器的网络融合方法——deepNF,从多个异构交互网络中提取蛋白质的高级特征。
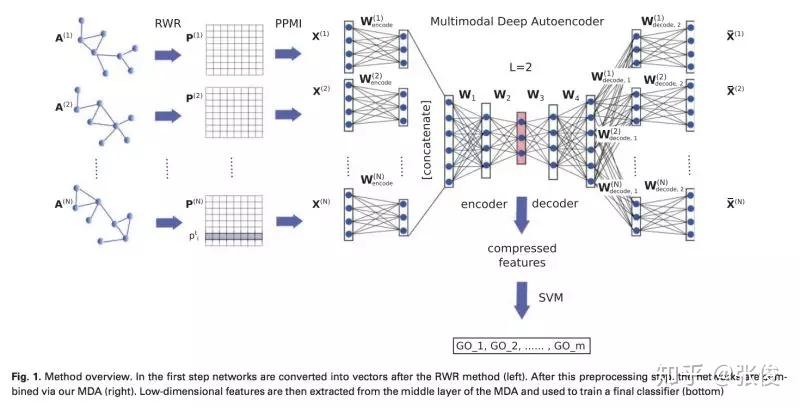
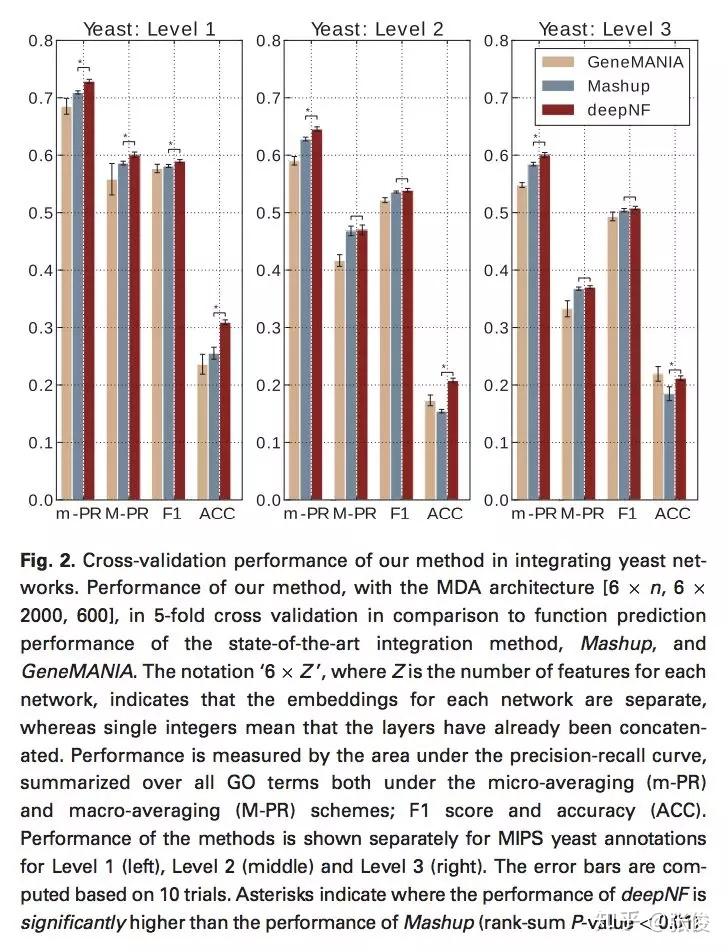
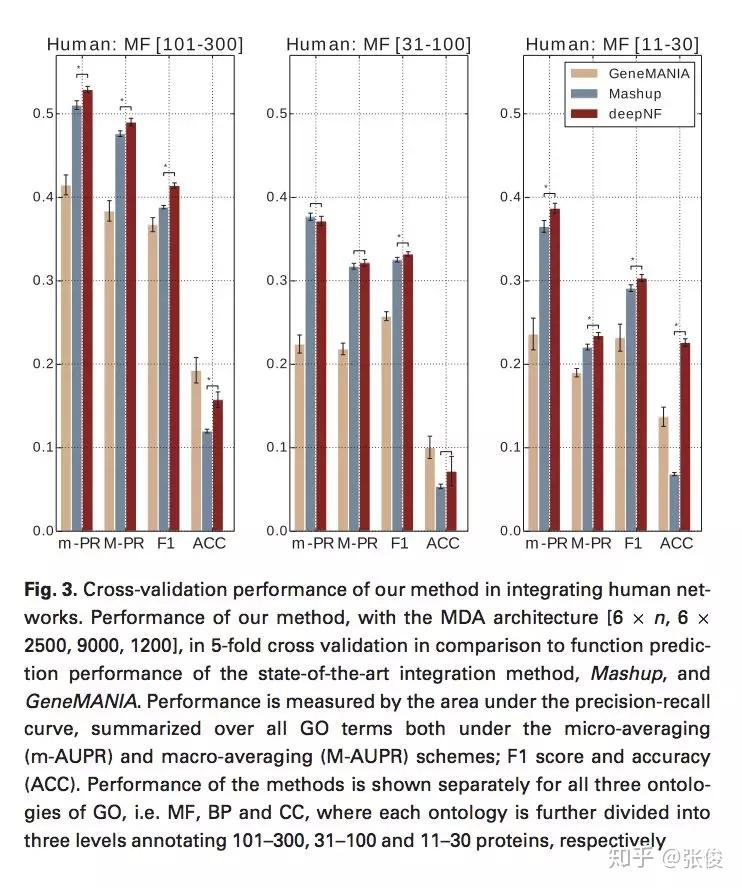
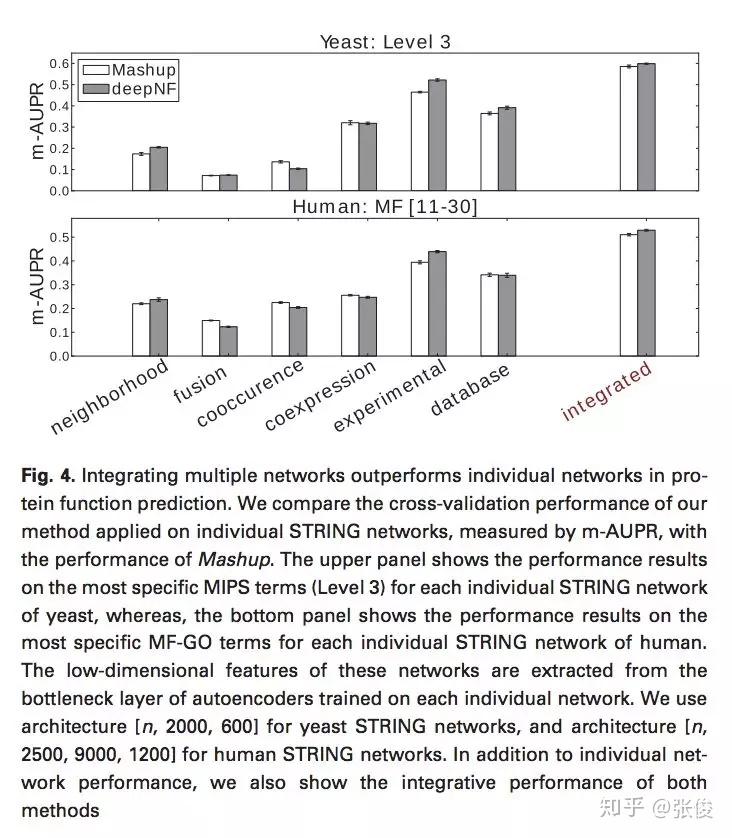
论文链接:https://www.paperweekly.site/papers/2172
源码链接:https://github.com/VGligorijevic/deepNF
Large scale distributed neural network training through online distillation
@paulpeng 推荐
#Neural Networks
本文来自 Google,论文提出了一种大规模分布式神经网络的的改进方法。具体来说,作者提出了一种 distillation 模型的变种,一方面考虑是支持大规模数据的并行化处理,另一方面考虑是为预测模型提供了一种可重复的方法。

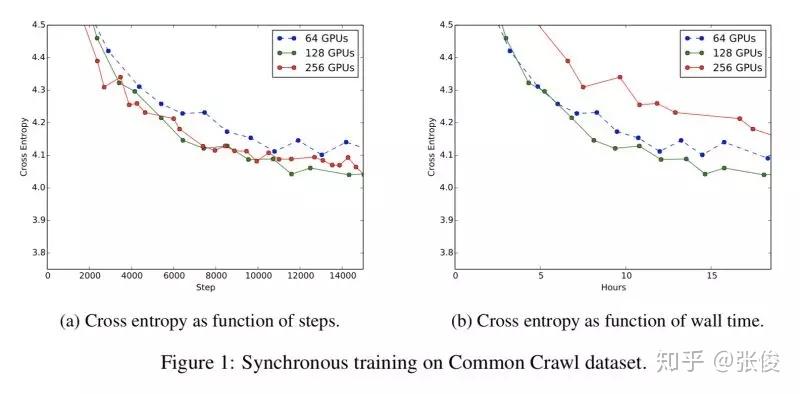
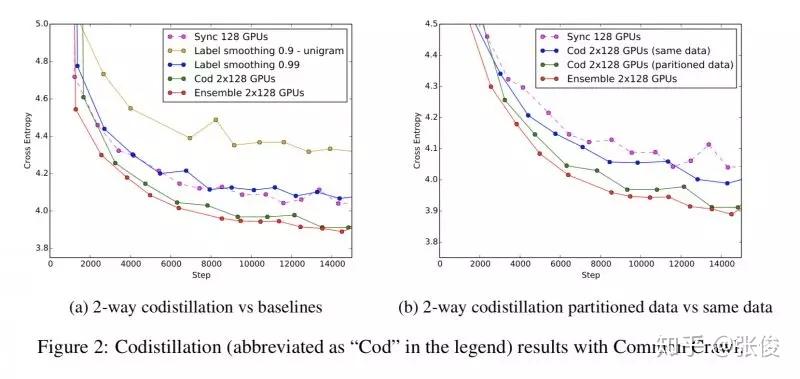
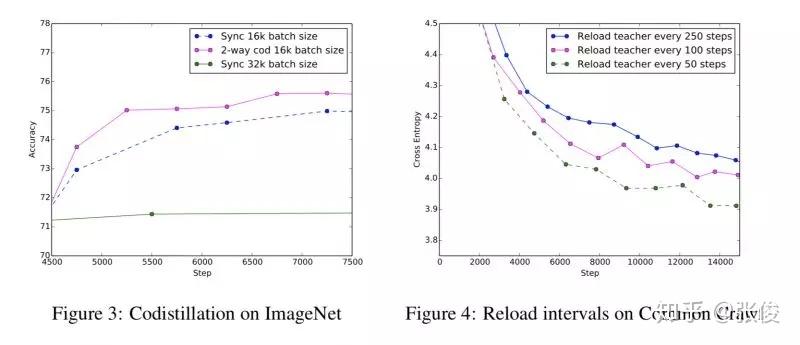
论文链接:https://www.paperweekly.site/papers/2205
RippleNet: Propagating User Preferences on the Knowledge Graph for Recommender Systems
@xuzhou 推荐
#Recommender Systems
本文是上海交大、微软亚洲研究院和香港理工大学联合发表于 CIKM 2018 的工作。为了解决协同过滤的稀疏性和冷启动问题,研究人员通常利用社交网络或项目属性等辅助信息来提高推荐效果。本文将知识图谱应用到推荐系统中,是一个很新颖的方法,给推荐系统提供了一个全新的思路。
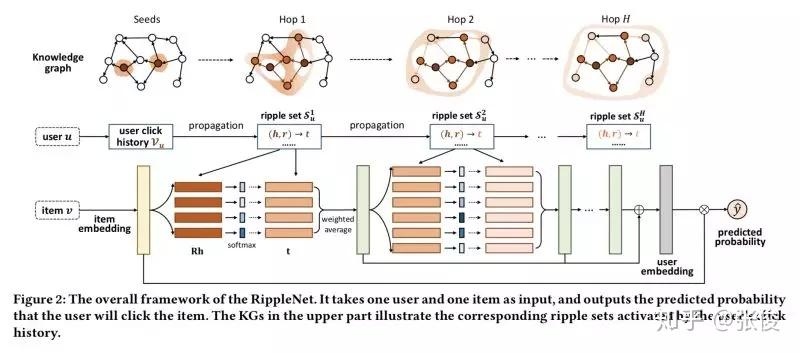
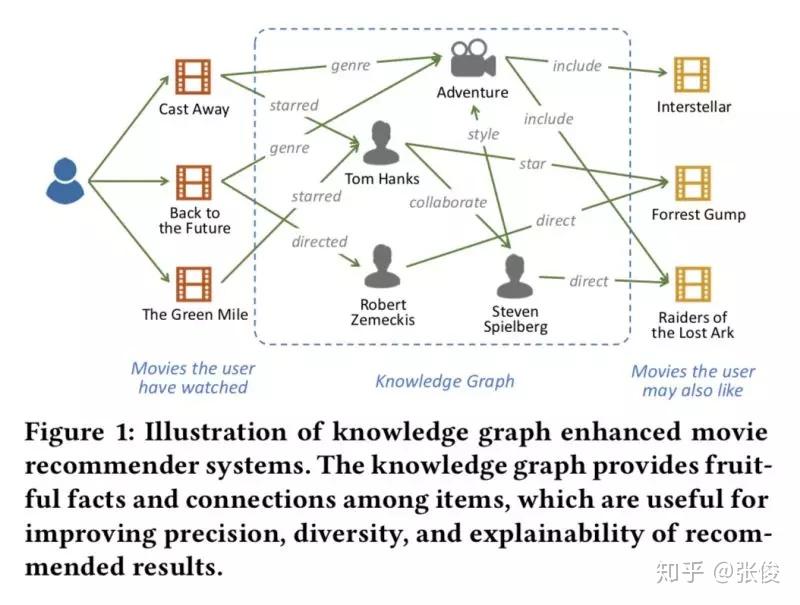
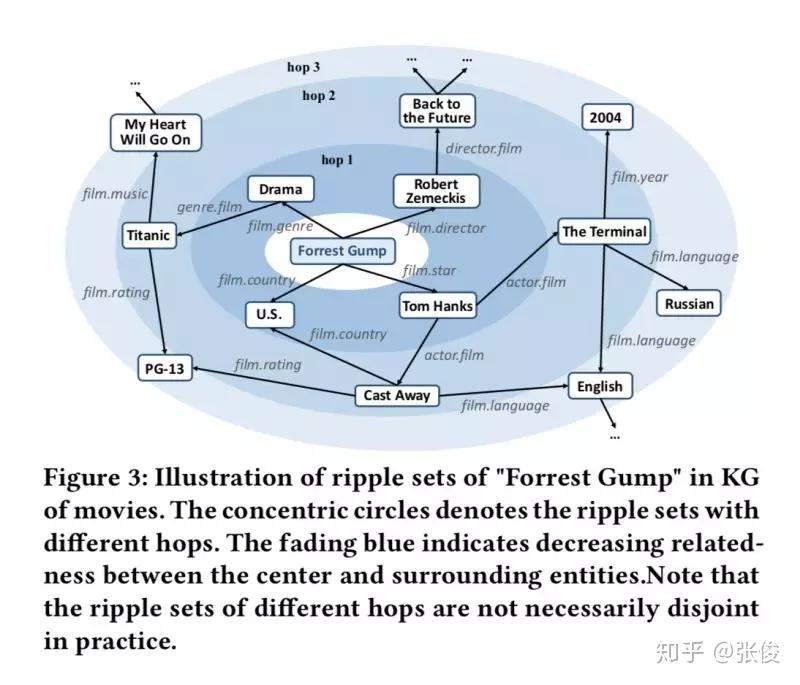

论文链接:https://www.paperweekly.site/papers/2201
源码链接:https://github.com/hwwang55/RippleNet
MojiTalk: Generating Emotional Responses at Scale
@filterc 推荐
#Response Generation
本文是清华大学和 UCSB 发表于 ACL 2018 的工作,论文旨在教会机器生成有情绪的回答,比如当用户伤心的时候,机器回答一定不能很开心。这项工作的难点在于缺少大规模标注好的情感训练集,以及如何控制生成回答的情感。现有的情感数据集对深度模型都太小,并且只有有限的几个分类(生气、开心,或者正面、负面)。
本文解决方案如下:1. 使用含有 emoji(选择了 64 种)的 Twitter 数据来做自动情感标注(规模:600K) 2. 在生成回答时,根据给定的 emoji 来生成不同情感的回答


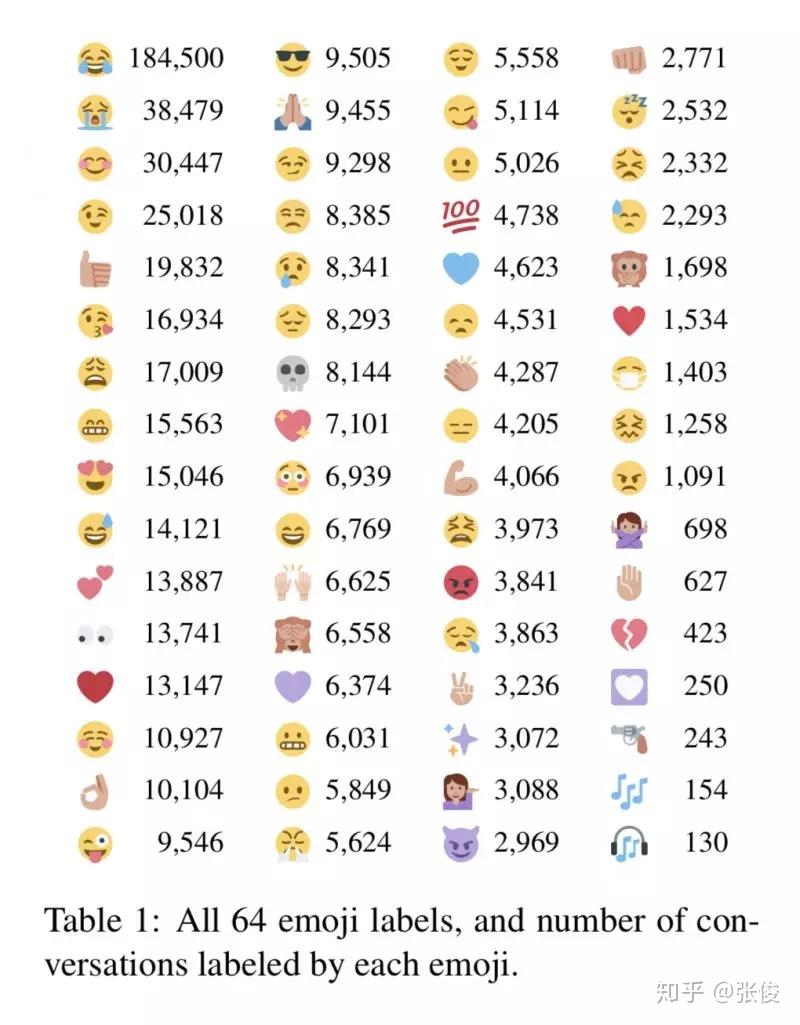
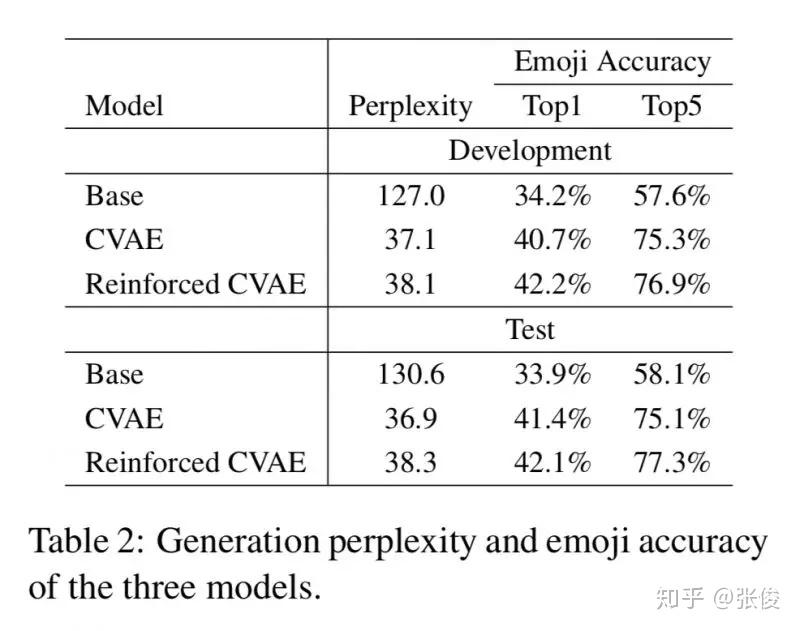
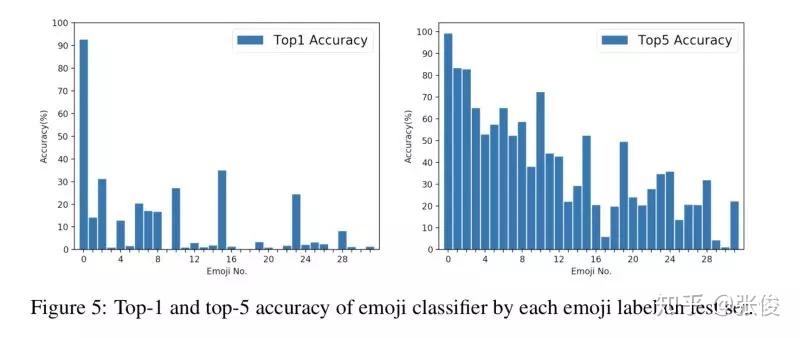
论文链接:https://www.paperweekly.site/papers/2199
源码链接:https://github.com/Claude-Zhou/MojiTalk
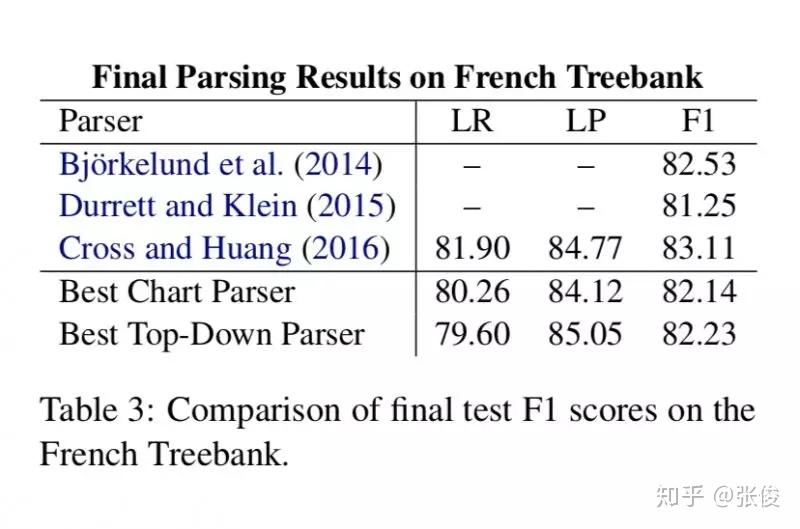
A Minimal Span-Based Neural Constituency Parser
@godweiyang 推荐
#Constituency Parsing
本文提出了一种不同于传统方法的成分句法分析方法。传统的句法分析器需要预处理出语法规则集合,然后利用语法规则来进行各种句法分析,这类方法的弊端有很多,主要有三点:
1. 语法规则集合构造的好坏直接影响到分析效果的好坏;
2. 不仅如此,利用语法规则的方法时间复杂度高,因为每次都要遍历一遍语法规则集合来决定每个短语采用哪一条语法规则;
3. 还有一种弊端就是利用语法规则的方法无法产生新的产生式,也就是说如果测试集中的语法规则没有在训练集中出现过,那么是无法预测出来的。
本文提出的模型不需要预先构造出语法规则集合,只需要预测出每个短语的label和 split 就行了,这样就能构造出一棵完整的句法树。该模型分为编码与解码两部分,其中编码部分就是利用双向 LSTM 将每个词和短语表示成向量,解码部分提出了两种模型,一种是 chart 模型,类似于 CKY 算法,另一种是 top-down 模型,就是自顶向下的贪心算法。
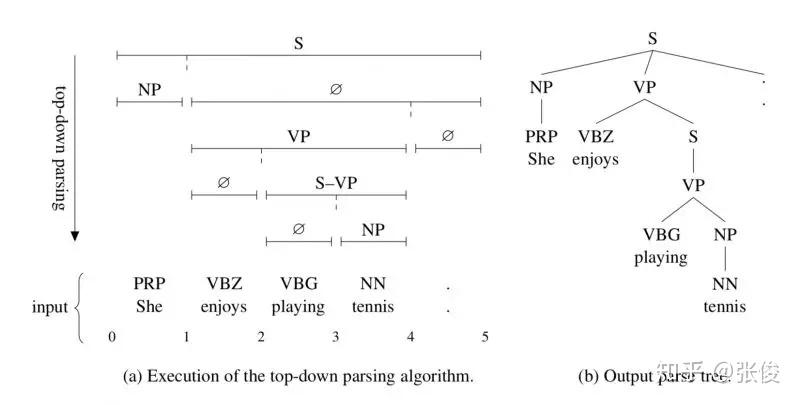
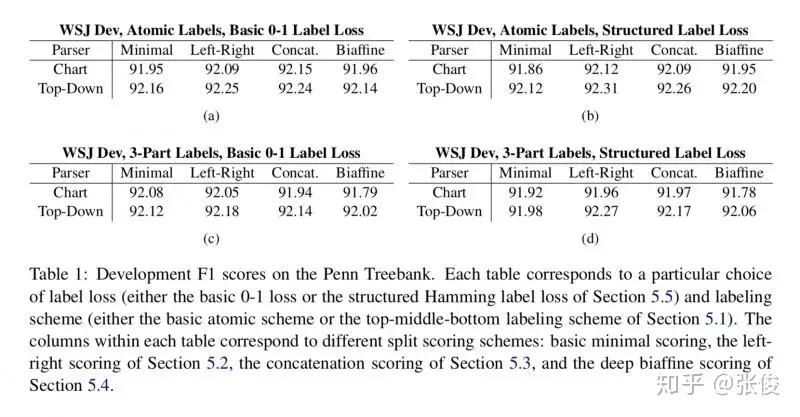
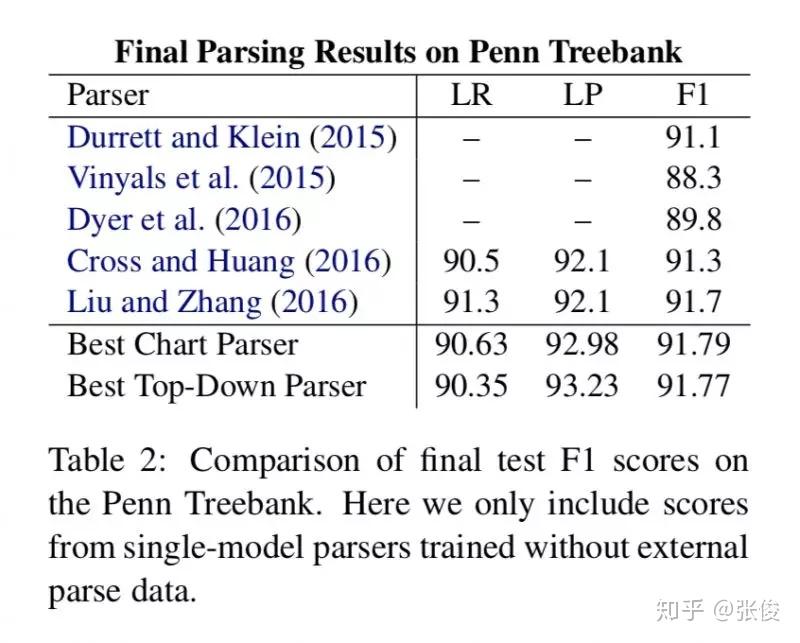
论文链接:https://www.paperweekly.site/papers/2098
源码链接:https://github.com/mitchellstern/minimal-span-parser
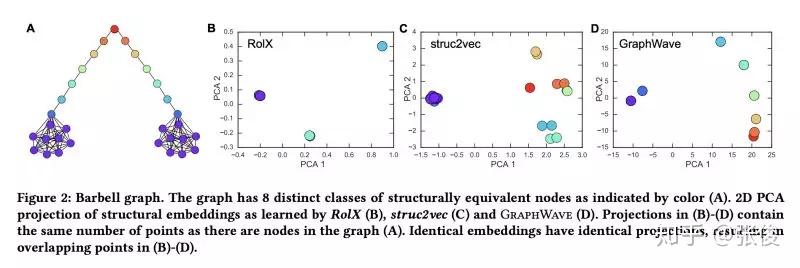
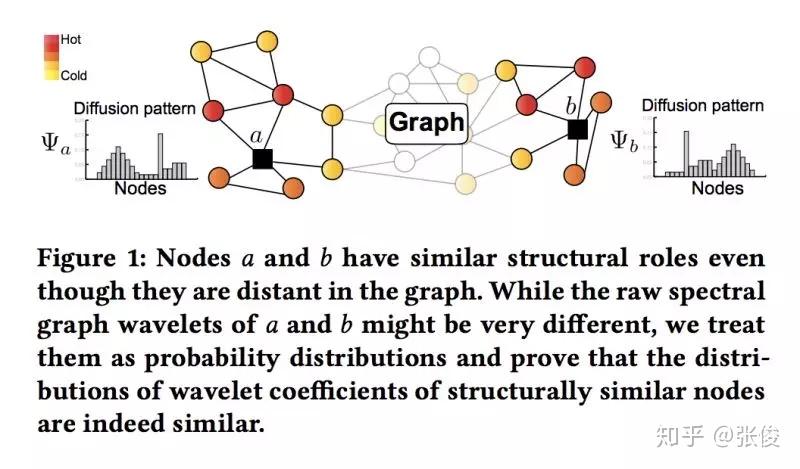
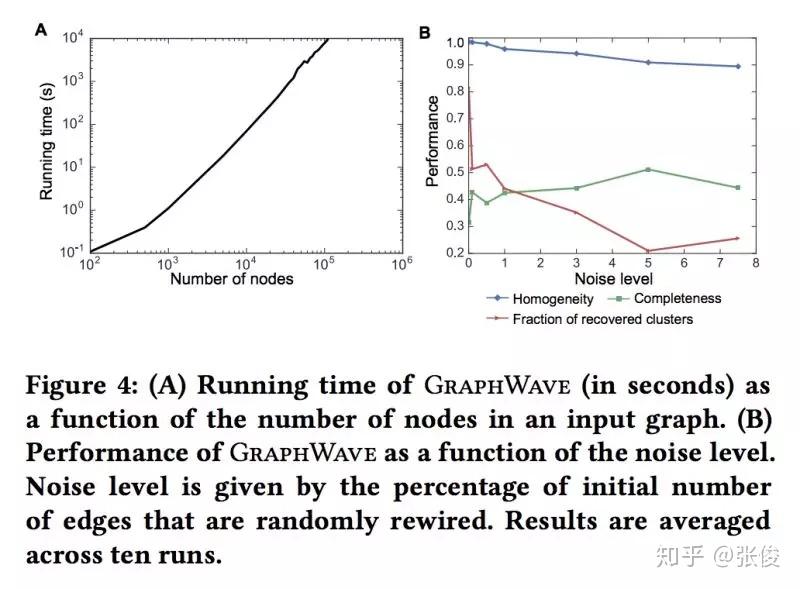
Learning Structural Node Embeddings via Diffusion Wavelets
@xuehansheng 推荐
#Network Embedding
本文是斯坦福大学发表于 KDD18 的工作,论文提出了一种通过利用热小波扩散模式通过低维嵌入来表示每个节点的网络邻域的方法——GraphWave。 GraphWave 不是在手工选择的特征上进行训练,而是以无人监督的方式学习这些嵌入。文章在数学上证明具有相似网络邻域的节点将具有类似的 GraphWave 嵌入,即使这些节点可能驻留在网络的非常不同的部分中。

论文链接:https://www.paperweekly.site/papers/2204
源码链接:https://github.com/snap-stanford/graphwave
Adversarial Network Embedding
@xuzhou 推荐
#Network Embedding
ANE 是发表在 AAAI 2018 上的用对抗生成网络学习网络表示的文章。现有的网络表示方法 Deep Walk、LINE、node2vec 等保留了网络的一阶、二阶或者更高阶的相似性,但这些方法都缺少增加 embedding 鲁棒性的限制。本文通过对抗训练的规则来正则化表示学习过程。
ANE 包含两个部分:结构保留、对抗学习。在结构保留部分,本文实验中分别使用了 Inductive DeepWalk 和 Denoising Auto encoder 两种模型;对抗学习部分主要是学习稳定、鲁棒的网络表示,使结构保留部分生成的网络表示服从先验(prior)分布。

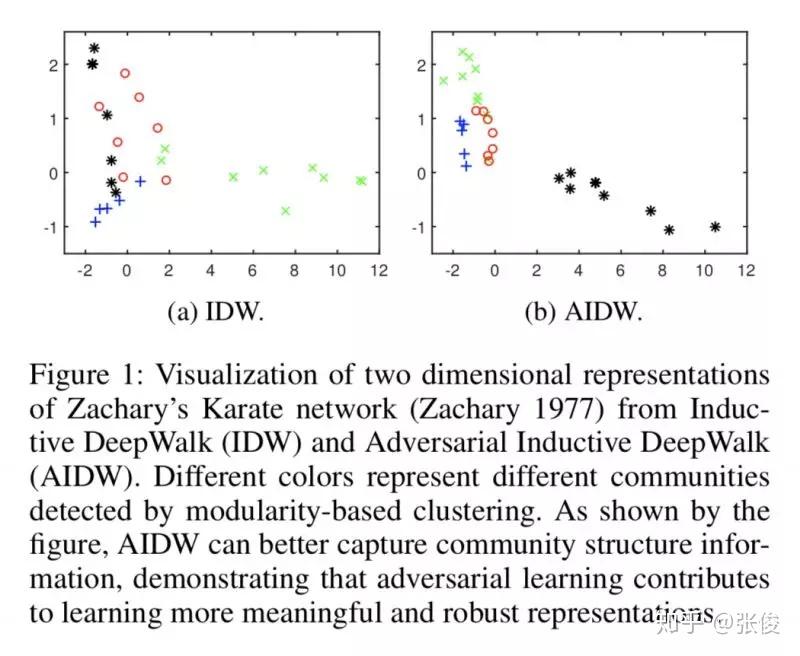
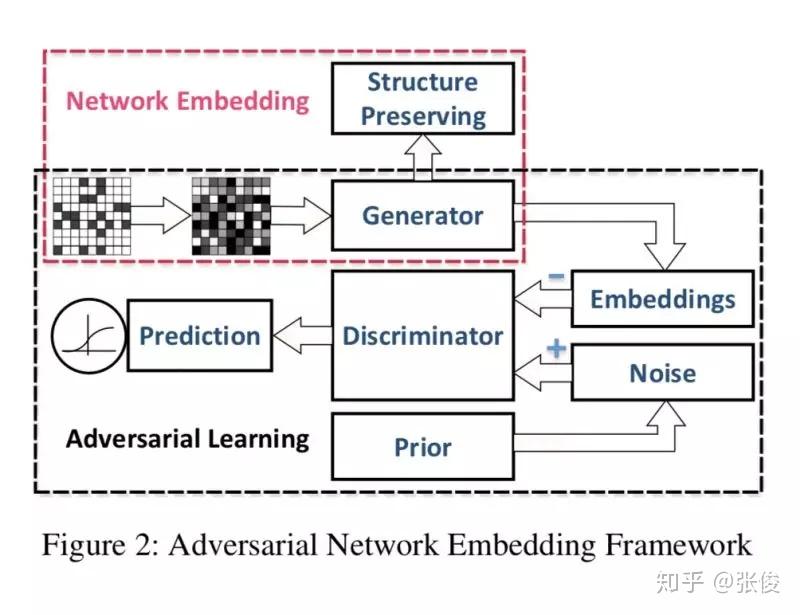
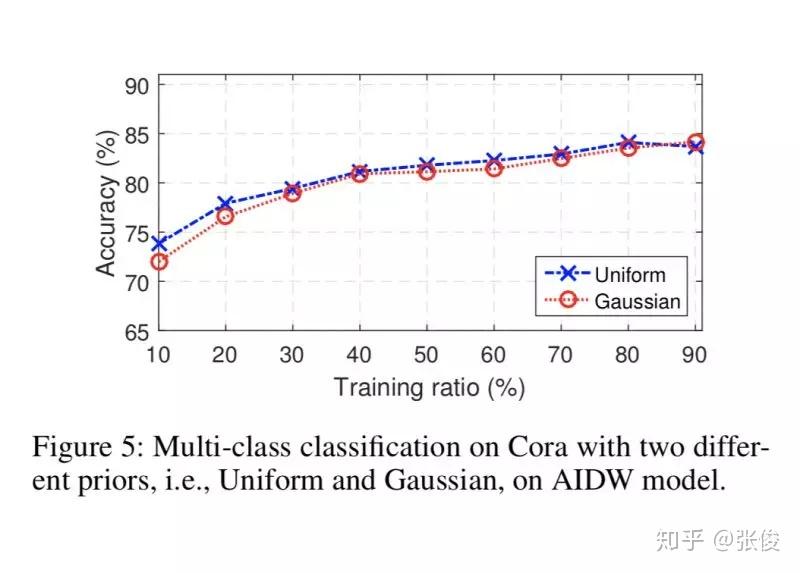
论文链接:https://www.paperweekly.site/papers/2164
Deep Spatial Feature Reconstruction for Partial Person Re-identification: Alignment-Free Approach
@Molly 推荐
#Person Re-identification
本文是中国科学院大学发表于 CVPR 2018 的工作,论文介绍了一种行人遮挡情况下的重识别方法。在实际应用中,行人互相遮挡或者被画面中其他物体遮挡,往往会导致模型表现下降。这篇文章提出的方法在消耗较少计算资源的情况下,可以得到更好的结果。
文章提出了一种框架,先使用 FCN 提取特征,再使用 Deep Spatial Feature Reconstruction 方法计算特征的相似度。即使用完整行人的特征的线性组合来表示部分行人的线性特征,如果误差很小,则认为是同一个人。否则不是同一个人。
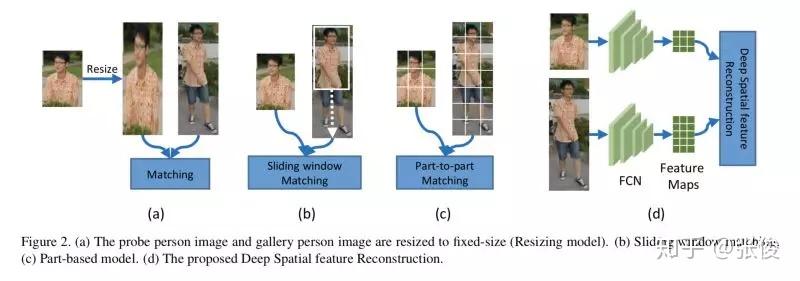


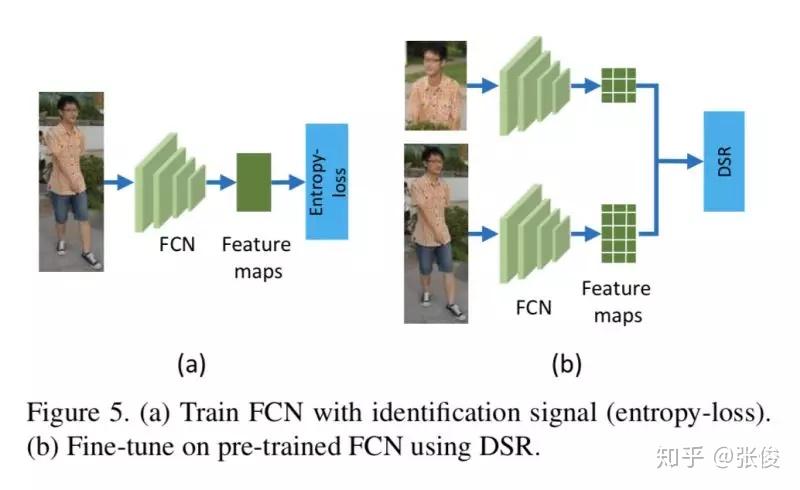
论文链接:https://www.paperweekly.site/papers/2183
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
加入社区:http://paperweek.ly
微信公众号:PaperWeekly
新浪微博:@PaperWeekly

AI时代,拥有个人微信机器人AI助手!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
搜索微信号aigc666aigc999或上边扫码,即可拥有个人AI助手!



