《2023国内人工智能大模型评估揭晓:文心一言引领国内是一片new
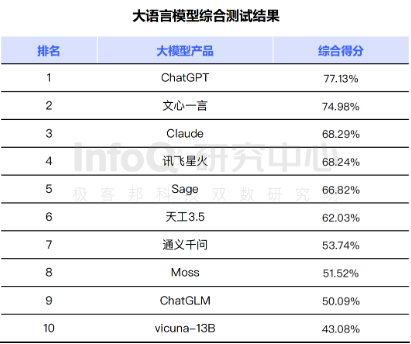
InfoQ研究中心对多款人工智能大模型产品进行了评测,发布的《大语言模型综合能力测评报告2023》中,OpenAI的ChatGPT位居第一,百度文心一言以74.98%的综合得分位列第二名。本次评测涵盖了300多道题目,包括语言模型准确性、数据基础、模型和算法的能力、安全和隐私等多个维度。在国内大模型排位中,文心一言表现优异,尤其在中文语义理解、逻辑推理、代码能力、知识问答等方面超越了ChatGPT,位居全球榜首。然而,总体来说,国内大模型与国际同类产品仍存在一定的差距。

