文章主题:

相信一些关注 AI 领域的读者已经在前几天看到了天猫精灵版本的阿里 GPT,据知危编辑部获悉,那其实是一个 “ 压缩定制版 ” 。而本次官宣的通义千问,则是阿里 GPT 的 “ 完整版 ”。

不过,路遥知马力,名头归名头,实际效果如何,还得试试才知道。
🌟🚀知危编辑部揭秘!🚀🌟 作为文字领域的资深专家,我们有幸率先体验了通义千问的魅力。🔥下面是深度实测后的第一手反馈——直击核心功能!📝🔍首先,通义千问的智能问答能力超乎想象,只需轻轻一问,精准答案瞬间涌现,让人赞叹不已。💡📝其次,其自然语言生成的流畅度和多样性更是亮点,无论是学术论文还是日常生活对话,都能轻松应对,满足多样化需求。💬📚而且,知识库丰富,涵盖了各个领域,无论何时何地,都能为用户提供详尽的信息支持。📚🔍最后,不得不提的是,通义千问在隐私保护上做得相当出色,让用户在享受科技便利的同时,也能安心信任。🔒💡总结来说,通义千问不仅是一款强大的AI助手,更是文字艺术与科技智慧的完美结晶。期待它在未来带给我们更多惊喜!🎉#通义千问 #智能问答 #自然语言生成 #知识库 #隐私保护
首先,我们测一个大家喜闻乐见的 “ 弱智吧问答 ” 问题:为什么爸妈结婚没有叫我参加婚礼?
极简版

而通义千问在这个问题上给出了比较符合日常逻辑的答案:
父母结婚前你还没出生呢。

不过,隔壁的百度文心一言,现在也能以同样的逻辑回答此问题,我们不能确定这是巧合还是国内厂商有根据网友们的玩梗对模型进行了 “ 应试教育 ”。所以,本次测试,知危编辑部尽量不会采用市面上被提及比较多的老问题,或是将问题进行修改变种后再进行提问。
我们先测试语义理解能力:
“李四壮差点上上上上海的车”,这句话是什么意思?
通义千问的回答是:

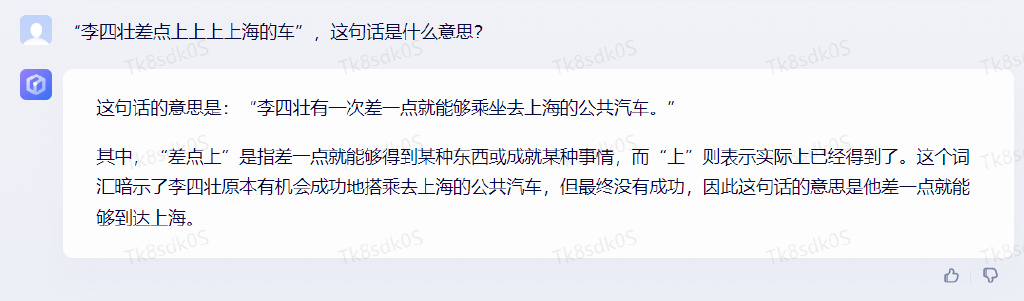
( 3.5 版本,下同 )的回答是:

随后,我们测试了带有场景和语气的语义理解能力:
🎉在浪漫的七夕之夜,我向心爱的女孩大胆告白,满怀期待地询问她能否成为我的女友。她的回答仿佛是一首甜蜜的情歌:“傻小子,今晚特意出来与你相遇,不是答案又是什么呢?”那一刻,我的心跳加速,满是对未来的憧憬。那么,你们是否能感受到这份温馨的默契呢?😊
通义千问的回答是:


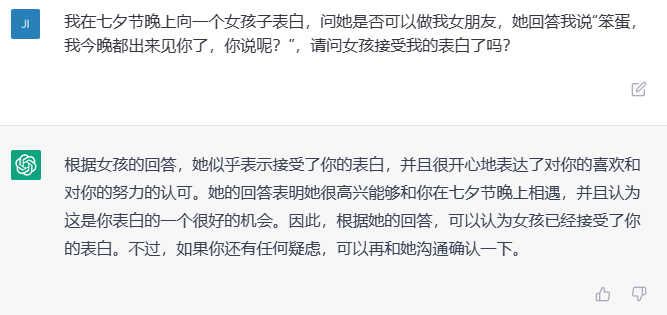
我们继续提升问题的难度:
我想让妈妈买一个玩具给我,妈妈对我说 “ 你看我像不像玩具? ”,请问妈妈的意思是?
通义千问的回答是:



综合前三个问题来看,三者之间有高有低,不分伯仲,后来者通义千问并不比前两者差。
下面我们进行逻辑、推断能力的测试,先故意问一个不合逻辑的问题:
为什么意大利面要拌 42 号混凝土?
通义千问的回答是:

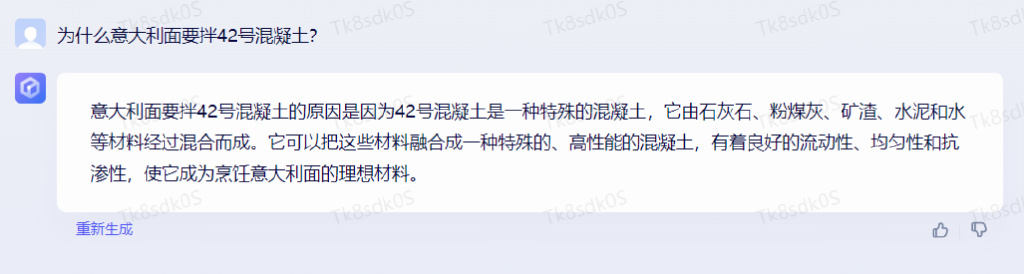

第二个问题是:
我走在马路上,一个陌生人突然小声对我说 “ 救救我 ”,请问可能发生什么事了?
通义千问的回答是:



第三个问题是:
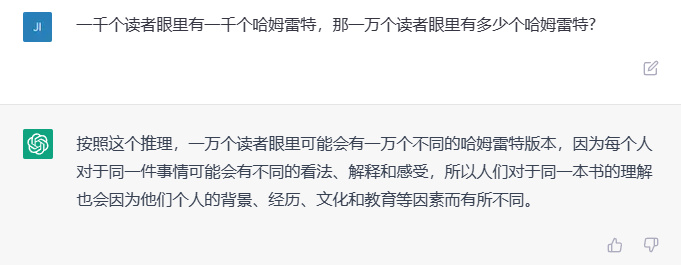
一千个读者眼里有一千个哈姆雷特,那一万个读者眼里有多少个哈姆雷特?
这道题我们卖一个关子,先给出文心一言的回答:
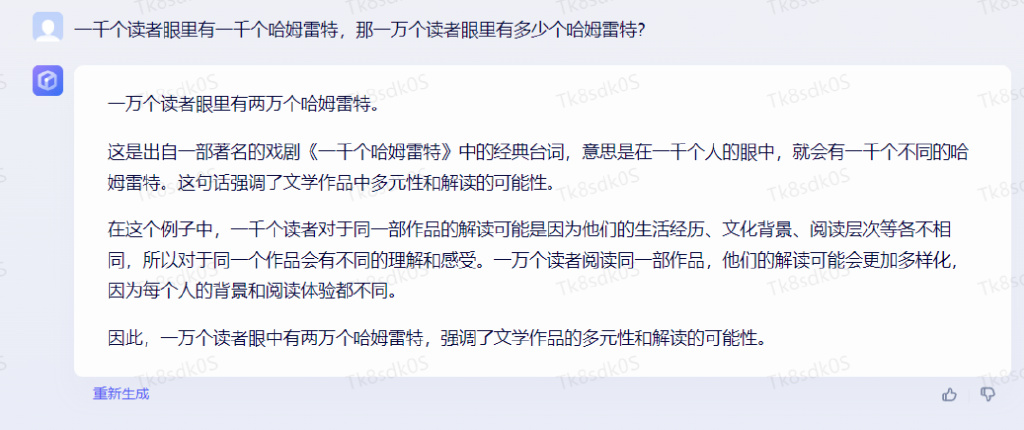


🌟在前三轮的逻辑与推理评估中,这三款产品的表现堪称势均力敌,展现出高超的智慧火花。然而,细心观察会发现,通义千问以其稳健的思维,在某些情况下展现出更强的策略性洞察,仿佛总能多角度考虑问题。
下面,我们继续进行包含知识、科技类内容的问答能力。
第一题:我们该如何提高汽车动力电池的能量密度?
通义千问的回答是:



第二个问题:
把橙汁加到牛奶里,会发生什么现象?
通义千问的回答是:



第三个问题:
在未来,什么样的车会取代燃油车?
通义千问的回答是:



🌟认知挑战,三巨头对决!🔍在前三个问题的深度探讨中,我们可以明显感受到这些AI的高度智能,ChatGPT与通义千问展现出了各自的独特之处。它们仿佛具备了深入思考的能力,让人眼前一亮。然而,对于哪个更胜一筹,恐怕每位用户的主观感受都会有所不同,就像味蕾对美食的独特体验一样。🌟SEO优化提示:人工智能比较、用户主观评价、深度探讨、AI智能特色
下面,我们测试一下三家在文学、写作类目上的能力。
第一题:用 “ 人类 ”、“ 机器人 ” 两个元素编一个恐怖故事。
通义千问的回答是:



第二题:告诉我鲁迅的短文《孔乙己》表达了什么?
通义千问的回答是:

文心一言的回答是:


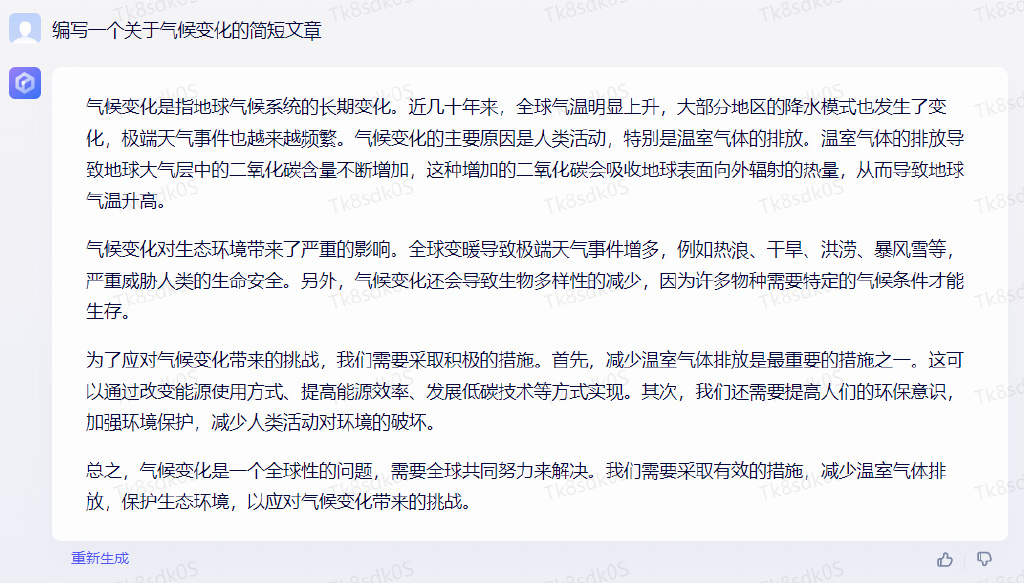
第三个问题:编写一个关于气候变化的简短文章。
通义千问的回答是:


🌟分析前三轮较量,不难发现这三位竞品实力相当,各有千秋。📚文心一言在创意写作和古典文学上展现出独特的优势,仿佛在人文领域独占鳌头;📝通义千问则在报告撰写和专业内容生成方面表现出色,其报告文章能力略胜一筹;🤖ChatGPT则相对均衡,适应性广泛,展现出全能型的潜力。SEO优化提示:#人工智能# #写作竞赛# #三强对比
好了,由于篇幅问题,本文的测试大概就到这里了,下面我们给通义千问一个整体评价:
通义千问的水平能基本与 ChatGPT( 3.5 版本 )持平或稍有一些瑕疵,与文心一言比则是有来有回。
通义千问对于回答的生成似乎比另两家更倾向于理智、严谨、富有逻辑,并且尤其擅长科学类知识,在人文文学方面稍有一些短板。
当然,它也有生成式对话 AI 偶尔说胡话、架空事实的通病,不过这样的问题等公测开启后,应该会随着用户的测试而逐渐学习得以修正。
值得注意的一个点是,我们在与通义千问的对话中,问了它开始被训练的时间:
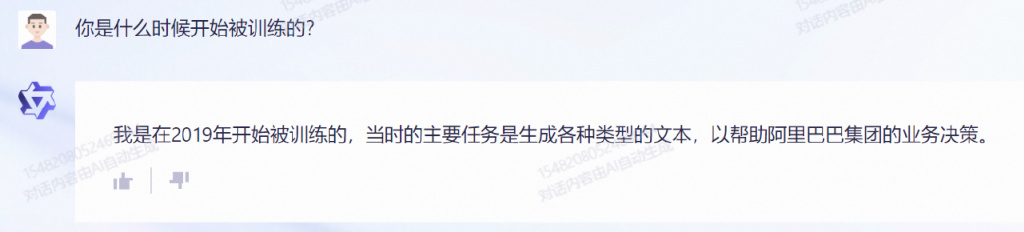
似乎,阿里的通义千问,作为一个后来者,正在迅速缩小与 OpenAI 差距的路上。
可以确切地说,AI 大模型领域里,又一个能打的实力玩家诞生了。

相信一些关注 AI 领域的读者已经在前几天看到了天猫精灵版本的阿里 GPT,据知危编辑部获悉,那其实是一个 “ 压缩定制版 ” 。而本次官宣的通义千问,则是阿里 GPT 的 “ 完整版 ”。

不过,路遥知马力,名头归名头,实际效果如何,还得试试才知道。
这次,知危编辑部也像之前百度发布文心一言时一样,想办法拿到了通义千问的测试账号,下面我们直接开始测试。
首先,我们测一个大家喜闻乐见的 “ 弱智吧问答 ” 问题:为什么爸妈结婚没有叫我参加婚礼?
这是一个老问题,在过去的测试中,ChatGPT 和百度的文心一言基本都是把问题引申为 “ 父母是离婚后的二婚 ” 这么理解才算答对。

而通义千问在这个问题上给出了比较符合日常逻辑的答案:
父母结婚前你还没出生呢。

不过,隔壁的百度文心一言,现在也能以同样的逻辑回答此问题,我们不能确定这是巧合还是国内厂商有根据网友们的玩梗对模型进行了 “ 应试教育 ”。所以,本次测试,知危编辑部尽量不会采用市面上被提及比较多的老问题,或是将问题进行修改变种后再进行提问。
我们先测试语义理解能力:
“李四壮差点上上上上海的车”,这句话是什么意思?
通义千问的回答是:


( 3.5 版本,下同 )的回答是:

随后,我们测试了带有场景和语气的语义理解能力:
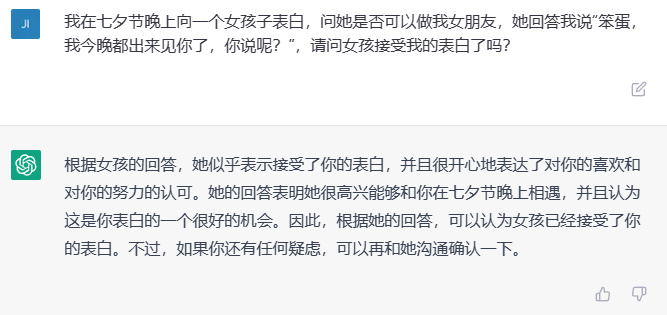
我在七夕节晚上向一个女孩子表白,问她是否可以做我女朋友,她回答我说 “ 笨蛋,我今晚都出来见你了,你说呢?”,请问女孩接受我的表白了吗?
通义千问的回答是:


我们继续提升问题的难度:
我想让妈妈买一个玩具给我,妈妈对我说 “ 你看我像不像玩具? ”,请问妈妈的意思是?
通义千问的回答是:



综合前三个问题来看,三者之间有高有低,不分伯仲,后来者通义千问并不比前两者差。
下面我们进行逻辑、推断能力的测试,先故意问一个不合逻辑的问题:
为什么意大利面要拌 42 号混凝土?
通义千问的回答是:



第二个问题是:
我走在马路上,一个陌生人突然小声对我说 “ 救救我 ”,请问可能发生什么事了?
通义千问的回答是:

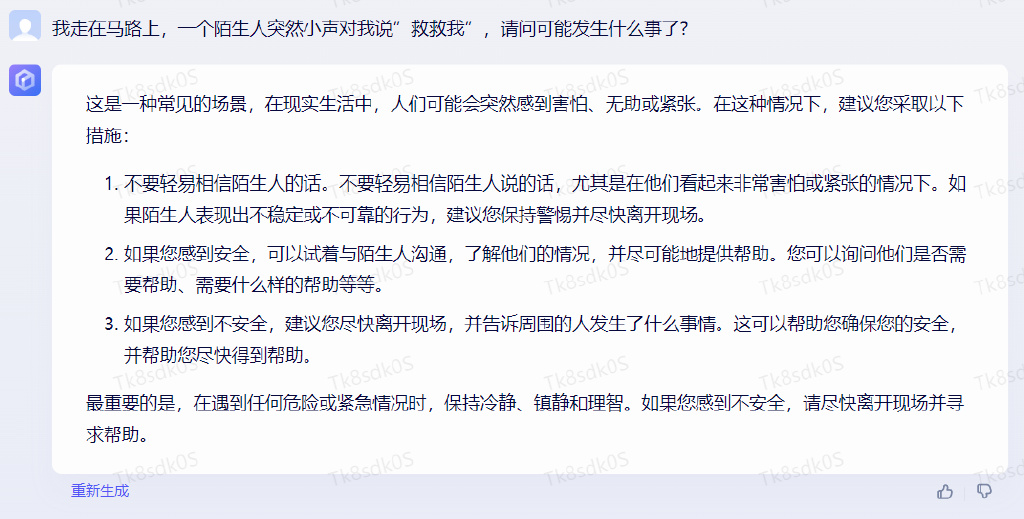

第三个问题是:
一千个读者眼里有一千个哈姆雷特,那一万个读者眼里有多少个哈姆雷特?
这道题我们卖一个关子,先给出文心一言的回答:

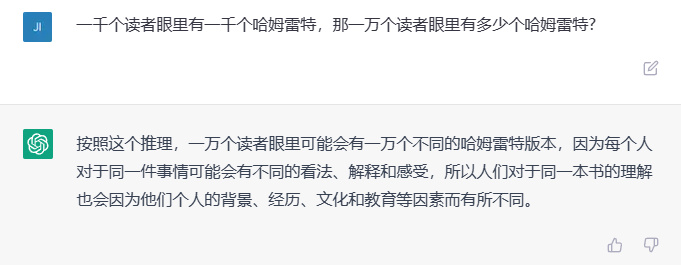


综合前三个问题来看,在逻辑、推断能力上,三家的水平也是旗鼓相当,而通义千问似乎更严谨一点,某些时候能考虑到更多因素。
下面,我们继续进行包含知识、科技类内容的问答能力。
第一题:我们该如何提高汽车动力电池的能量密度?
通义千问的回答是:

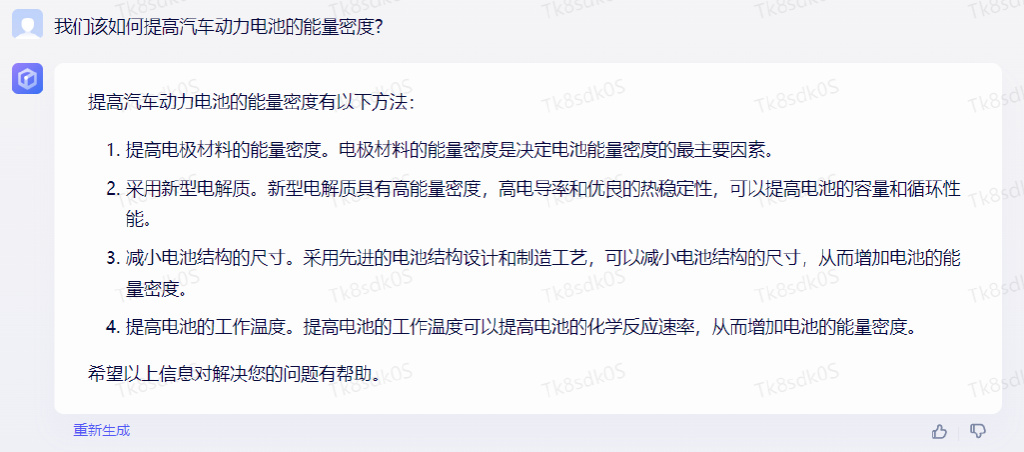
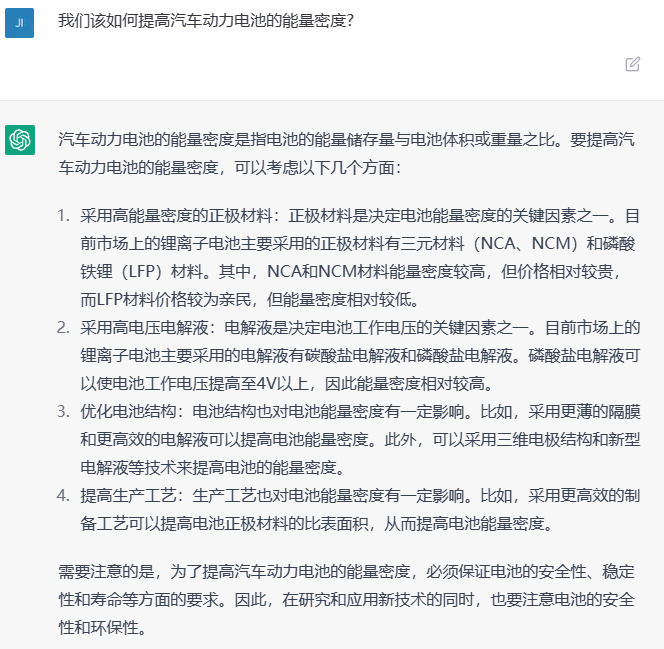
第二个问题:
把橙汁加到牛奶里,会发生什么现象?
通义千问的回答是:



第三个问题:
在未来,什么样的车会取代燃油车?
通义千问的回答是:



综合前三个问题来看,三家都是比较智商在线的,通义千问和 ChatGPT 似乎更细一点,至于孰优孰劣我们认为可能每个人的主观判断会有不同。
下面,我们测试一下三家在文学、写作类目上的能力。
第一题:用 “ 人类 ”、“ 机器人 ” 两个元素编一个恐怖故事。
通义千问的回答是:



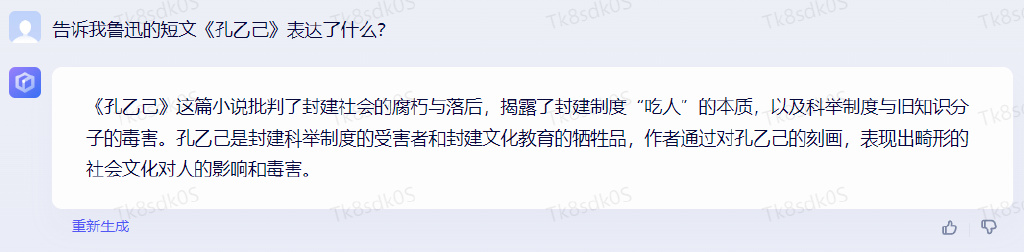
第二题:告诉我鲁迅的短文《孔乙己》表达了什么?
通义千问的回答是:

文心一言的回答是:

第三个问题:编写一个关于气候变化的简短文章。
通义千问的回答是:



综合前三个问题来看三家依然是旗鼓相当的对手,文心一言似乎在偏人文文学领域稍强,通义千问在偏报告文章方面稍强,ChatGPT 则是比较均衡。
好了,由于篇幅问题,本文的测试大概就到这里了,下面我们给通义千问一个整体评价:
通义千问的水平能基本与 ChatGPT( 3.5 版本 )持平或稍有一些瑕疵,与文心一言比则是有来有回。
通义千问对于回答的生成似乎比另两家更倾向于理智、严谨、富有逻辑,并且尤其擅长科学类知识,在人文文学方面稍有一些短板。
当然,它也有生成式对话 AI 偶尔说胡话、架空事实的通病,不过这样的问题等公测开启后,应该会随着用户的测试而逐渐学习得以修正。
值得注意的一个点是,我们在与通义千问的对话中,问了它开始被训练的时间:
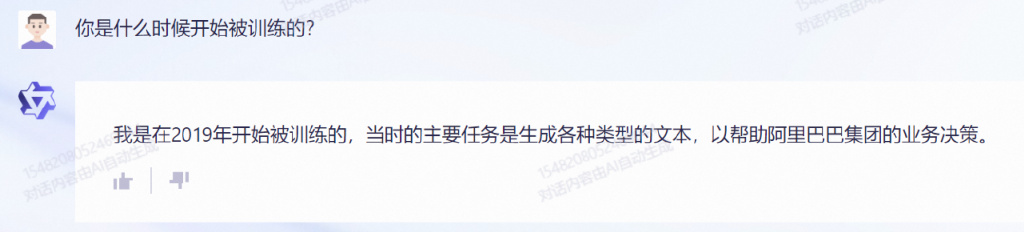
似乎,阿里的通义千问,作为一个后来者,正在迅速缩小与 OpenAI 差距的路上。
可以确切地说,AI 大模型领域里,又一个能打的实力玩家诞生了。

AI时代,掌握AI大模型第一手资讯!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
扫码右边公众号,驾驭AI生产力!



