文章主题:本文介绍了如何使用汇编语言实现移动端AI推理框架的性能优化。文章首先解释了汇编语言在AI推理框架中的定位,并分析了与大学时期学习的汇编语言的区别。接下来,作者汇总了实践过程中积累的常用汇编指令,并对比了在ARMv7和ARMv8模式下的指令形式和用法。此外,文章还提供了安卓和iOS平台下实现各种卷积的底层实现,包括conv3x3s1、conv1x1s1、depthwise、pooling、ReLU、ReLU6等。文章提到推理框架在整个app中属于sdk层次的,为追求高性能一般是使用C语言编写,并通过JNI接口与Java进行交互。最后,文章讨论了为什么使用C语言开发推理框架,以及在核心代码区域使用内联汇编的方式来实现功能体的优势。
一、初衷
在与伙伴们共同开设专栏的过程中,我发现大部分关注者都来自于学生群体以及那些对移动端具有潜在性能需求的开发者。为了能够帮助大家更快地掌握汇编语言,特别是针对ARMv7/ARMv8架构的移动端人工智能推理框架中的常用汇编指令,我专门进行了整理。这些整理的内容不仅能让你们快速熟悉各种指令,还能帮助你们迅速掌握汇编实现的技巧,以便于你们能紧跟在我之后所写的关于汇编极限优化的相关知识(如指令流水线、缓存等)。
本文的行文结构如下:
在开始之前,让我们先来了解一下我们的汇编代码在推理框架中所处的位置。为了更好地理解这一概念,我们需要将其与我们大学时期学习的汇编语言进行对比,明确它们之间的异同点,以便我们在后续的阅读中能够更有针对性地关注到关键的部分。
在实践过程中,我积累了大量的常用指令,并对其进行了详细的分类和整理。接下来,我将对这些指令进行总结,并对比分析它们在ARMv7和ARMv8模式下的指令形式和用法差异。通过对这些指令的深入研究,我们可以更好地理解ARM架构的发展趋势,为未来的开发工作打下坚实的基础。
在接下来的部分,我将展示一些实际的案例,以便让大家更好地理解卷积操作在实际应用中的表现形式。这些案例将覆盖安卓和iOS平台,包括卷积核大小分别为3×3、1×1的s1类型,以及深度卷积(depthwise)和池化(pooling)等操作。对于那些尚未涉猎汇编领域的同学,不必过于担忧,我会提供纯C语言的实现代码,并随后给出相应的汇编代码作为参考。通过对比阅读这两种代码,即使你对汇编语言不甚了解,也能够掌握如何运用这些操作。相信在仔细研读之后,你会逐渐熟悉汇编语言并掌握其使用方法。
在撰写本文时,我注意到最后一部分可能涉及到一个具体的实例。该实例涉及图像处理领域中的一种常见需求,即从RGB格式转换为YUV格式。在此之前,我们通常通过C语言进行实现,然而现在我们可以考虑使用汇编语言进行优化,并关注流水访问内存等相关问题。最后,我们将比较不同方法之间的性能差异,从而展现出完整的实践过程。尽管这一部分可能需要花费较多时间去完成,但相信我们的努力将带来显著的成果。值得一提的是,周末时光原本属于休息和放松,而我们却选择利用这段时间陪伴彼此,共同学习进步。这种坚持和付出,无疑是最美的情感体现。

)
二、汇编在推理框架中的定位
在整个应用开发过程中,推理框架位于软件开发工具包(SDK)层面,为了实现性能优化,通常采用C语言进行编写。同时,通过Java Native Interface(JNI)接口,推理框架能够与Java层进行高效互动。
我们理解,底层的计算库代码也遵循着“二八法则”。其中,真正耗时部分仅占据两成左右(这个比例并非绝对,而是前人经验总结出的一个大致数值)。因此,我们只需针对这两成代码进行优化,就能抓住问题的主要矛盾,从而实现性能的最大化提升。为此,我们将这两成的代码改写为汇编语言,以便更深入地进行性能优化。
有人就问了,既然汇编能提升性能你为啥不将推理框架全部汇编实现呢?
我必须承认,你是一位英勇无畏的探险家。你的勇气和决心令人钦佩。然而,我必须提醒你,在探索未知领域时,要谨慎行事,尤其是涉及到敏感信息的时候。我想,你可能对网络编程有着浓厚的兴趣,甚至想要亲自动手编写一下NCNN的源代码。这无疑是一个非常具有挑战性的任务,因为那可是一份非常庞大的代码库,用C语言编写就已经足够困难了,更别提使用汇编语言了。一旦出现问题,调试起来将会变得异常艰难,可能会让你感到无所适从。因此,我要建议你在开始之前,先做好充分的准备和学习。尝试理解一些基本的计算机原理和网络协议,掌握一些常用的编程语言和工具,这样在你遇到问题时,才能迅速找到解决办法。同时,也要注意保护自己的个人信息和隐私,避免因为过于冲动而陷入困境。总的来说,你的勇气和决心是非常值得赞扬的,但我希望你能在这个充满挑战和风险的世界中,能够保持谨慎和理智,不断学习和成长。
因此为了框架的易实现性以及可维护性,还是用C++开发吧,在核心代码区域用内联汇编的方式来实现功能体,这样就做到取长补短了啊~在保证性能的同时又保证了工程的可维护性!
?你问我汇编麻烦在哪?我举个实际的例子哈!比如Facebook的QNNPACK就是把卷积算子给写成了单独的汇编文件(.s文件而不是.cpp文件),这么做的理论上是有收益的,但是呢,实际收益并不是很明显啊,没有把握住问题的主要矛盾啊~
同时伴生的问题就是代码维护难度增大,代码逻辑一般coder(没错说的就是我了~)不易读懂,我截取一段,咱们大家来感受感受:
看到没,有前处理后处理入栈出栈操作的呀,一个不小心可是很容易出错的哟~
中间的循环逻辑都排到7层了,我们的C++代码直接一个for套for循环是很直观且易读的吧,汇编可就不一样了呀,特别是过一段时间再来看可能得好一会才能建立脑回路~
因此这就是为什么要推出内联汇编,即抓住主要矛盾,在c++层次尽可能地提高代码性能。
三、AI推理框架中常用的指令汇总
3.1 寄存器差异介绍
我假设你已经知道了ARM后面的版本有37个寄存器,其中我们常用的通用寄存器是r0~r15(在A64指令集里面就是x0~x31或者w0~w31),其中r13、r14、r15不能乱用;
其次A32指令集下NEON寄存器是Q0~Q15共计16个,A64下是V0~V31共计32个,其表现形式以及硬件结构都有所差异,我们直接看图吧!

这是AArch32状态下的NEON寄存器组,Q0~Q15,同时对应D0~D32,一个Q分为两个D,这两个D是可以单独操作的;
其次就是一个D分解为2个S,注意哦只有D0~D15才可分解,共计32个S寄存器;如果要计算浮点值的话你得先把数据搬运到这个寄存器(而不是R0~R15中)才能进行浮点运算。
可以看到特点是寄存器是连续的,Q0等价于D0+D1等价于S0+S1+S2+S3,这在我们做矢量运算的时候是很方便的(实例中可以见到),但是在AArch64状态下的NEON寄存器组可就不一样咯~

你看V0对应AArch32状态下Q0,这里只对应D0,跟AArch32不同的是D1分配到V1中去了,也就是说寄存器不连续了,这里可能有人有疑问,假如我要把数据放到V0的上班部分怎么办呢?这个当然考虑到了比如smlal2指令就是专门处理这类问题的,后面慢慢会接触到的,这里就先不展开说了。
给各位推荐两个文档,里面可以分别查看ARMv7的NEON汇编指令,以及ARMv8的所有指令:
《RealView® 编译工具3.1 版汇编程序指南》
《ARM® Architecture Reference Manual ARMv8, for ARMv8-A architecture profile 》其次在这个网址你可以去看看,Neon Intrinsics Reference:
里面有所有Intrinsics指令以及对应的汇编指令及用法,作为工具临时查询指令的用法还是蛮有用的!后面补个例子就知道如何方便地用了!(写着写着我觉得我自己定会没时间举例子的~huohuohuo~)
Arm的A32/T32指令集跟A64指令集在SIMD汇编指令语法这块的整体区别如下:

3.2 常用指令汇总

注1. A64下不仅仅只有取到L1cache并keep这一种预取方式啊,还有stream模式,取到L2cache的模式啊,具体可取查看上面我给我的那个手册哈;
注2. A64更专注于指令表达意思的本身,数据类型让寄存器来设定;
注3. 与在C层次不一样的是在汇编层次地址单位都是byte;
注4. NCNN的ArmV7参考资料注5. NCNN的ArmV8参考资料3.3 常用指令解析
官网的详细指令解析:





上面的指令里面有较为详细的解释啊,如果不想看的话,看我写的这个精简版可能有点用的(也可能没用~):
3.3.1 预取
v7:
从%3处预取192个byte;v8:
pld1kepp这个参数是可以改的,改为预取到L2中,不keep,而是流式缓存,也就是不会真放进cache中,具体的可以去看芯片手册(看下面的图片)。
3.3.2 内存加载
V7:
带了前缀v的就是Armv7 32bit指令的标志;
ld1表示是顺序读取,还可以取ld2就是跳一个读取,ld3、ld4就是跳3、4个位置读取,这在RGB分解的时候贼方便;
后缀是f32表示单精度浮点,还可以是s32、s16表示有符号的32、16位整型值。(对比后面的ISA64指令集就可以知道它浮点用的是4s,int16是4h)
这里Q寄存器是用q表示,q5对应d10、d11可以分开单独访问(注:v8就没这么方便了。)
大括号里面最多只有两个Q寄存器。
v8:
可以看到指令就是单纯的表达我是个什么样操作而已,具体的什么数据类型啊就全部交给底下的寄存器去表达了。
NEON寄存器用V来表示(后缀为8B/16B/4H/8H/2S/4S/2D);
大括号内最多支持4个V寄存器;
无法直接访问V0 的上半部分的D寄存器,目前的情报是:直接访问D0就是v0.4h,要访问V0的高64bit,可以先V0.8h加载满数据,然后以V0.h[4~7]来访问单独的int16数据;再或者就是像这样来访问:把v5.4s里面的4个32bit整型值压缩进v8.8h高64bit里面的4个int16里面。
3.3.2 以占位符方式访问Q、D寄存器
关于这部分在NCNN github的wiki页面有详细的解释,可以去那看看哟!
V7:
先定义变量,表明_bias0就是一个向量格式了;
然后在占位符那里表明我这个_bias0需要用一个浮点寄存器缓存起来;
然后我们在f32里面用是这样用的:把%23里面加入一个q表明这个是一个Q寄存器,然后按位与,最终输出到Q12向量寄存器里面。
因为q0是按照s16的方式导进来,因此,d0相当于有4个int16,因此能索引到d[3]
首先定义的是int16x4,就是D寄存器,因此在访问的时候就是直接%P14了m,用P指明是D寄存器;
V8:
相对应的V8以占位符方式访问向量寄存器的时候,是直接在后面加后缀来指明立场的;如浮点乘法的时候就是%16.4s指明是单精度浮点(4个single精度浮点值),同样的v21.s[3]是访问4个中的其中一个浮点值。
v8的int16操作:以int16 的方式加载一个D寄存器的_k0出来,然后v0.8h表示加载8个int16,然后v0.h[7]跟%6以4h的方式相乘,最后拓展输出到V4寄存器,以4s的格式,也就是4个32位;
四、AI底层常见算子汇编实现
4.1 移动端内嵌汇编语法
如何在C或C++代码中嵌入ARM汇编代码?
注:这小节的内容来自下面的链接,别人写的足够好了,咱们直接学习就好了哈,推荐大家去下面的链接看细节:
1) 汇编代码模板
所有的汇编代码必须用双引号括起来。如果有多行汇编代码的话,每一条语句都要用双引号括起来,并且在代码后面要加上换行符(“\n”或者“\n\t”)。这样做是因为GCC会将汇编代码部分作为字符串形式直接传给汇编器,加上换行符后,汇编器就能准确知道哪些字符串表示的是一条汇编语句。同时,为了增加可读性,每条汇编语句都可以换行。
其具体形式如下:
因为汇编代码部分是必需的,所以即使一行汇编代码也没有,也需要传入空字符串(””),否则会报错。
2) 输出操作数列表和输入操作数列表
这部分需要注意的是GCC跟clang编译器的差异:GCC支持的参数总共不得超过30个,而clang则无此限制,如不加注意,则在写汇编写的欢时可能会碰上莫名其妙的异常的呀~
输入操作数表示要作为汇编代码输入的C表达式,而输出操作数刚好相反,表示汇编代码处理完后要输出结果的C表达式。如果有多个输出或输入表达式,需要用逗号(“,”)将它们分隔开来。
可以再前面的汇编代码模板中直接应用定义的输出操作数和输入操作数,其用法是使用百分号(“%”)后面接一个数字,0表示定义的第一个操作数,1表示定义的第二个操作数,依次类推。
这里%0代表后面定义的第一个操作数,即输出操作数,代表C语言中的result变量。%1代表定义的第二个操作数,即输入操作数,代表C语言中的value变量。
每一个操作数由三部分组成,分别是修改符(Modifier),限定符(Constraint)和C表达式,其中修改符是可选的。具体形式如下:
修改符和限定符要用双引号括起来,而C表达式要用括号括起来。操作数在这里的作用是将C语言定义的变量与汇编语言中要使用到的变量进行一一对应。
但并不是所有的汇编指令都可以接受任何类型的变量作为输入或输出变量的,因此汇编器需要知道这些变量到底用在什么地方,从而帮助在传递之前做一些转换。常用的限定符主要有以下一些,而且汇编语句到底是ARM的还是Thumb的,对限定符的定义也会不同:
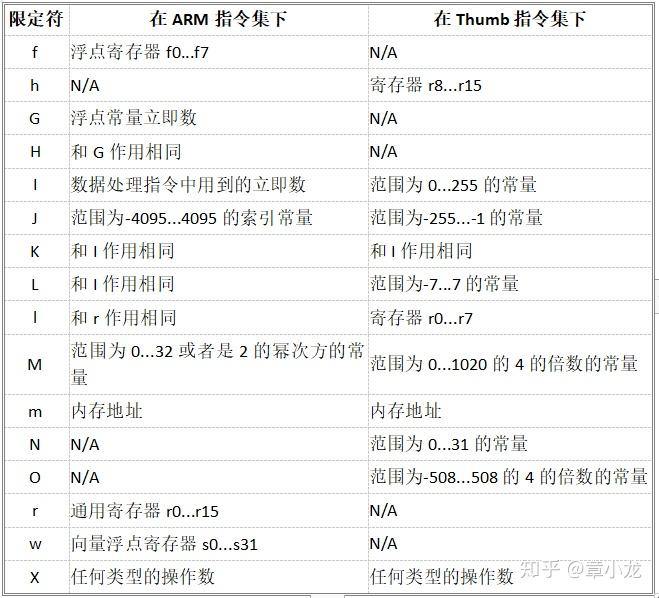
常用的也就是r,f和m等几个。
修改符是加在限定符之前的,并且是可选的,如果没有修改符的话,则表明这个操作数是只读的。这个对输入操作数没有问题,但是对输出操作数来说,肯定是需要被修改的。
GCC中定义了三个修改符,分别是:

所以,作为输出操作数,只需要在限定符前加上“=”就可以了。
在汇编代码中,请绝对不要修改输入操作数的值。
如果想让一个C变量既作为输入操作数,也作为输出操作数的话,可以使用“+”限定符,并且这个操作数只需要在输出操作数列表中列出就行了。例如:
但是GCC的老版本不一定支持“+”修改符,如果也想达到前面的这种输入和输出操作数是一个的目的,可以用一种变通的做法,并且这种变通的做法GCC的新版本也是支持的。其实,在限定符中,也可以使用数字,其作用是指代前面定义的操作数,0代表第一个,1代表第二个,以此类推。例如:
如果GCC编译器支持的话,这个例子的效果和前面的例子是相同的。本例不同的是,先定义了一个可写的输出变量,同时在输入变量列表中,明确用数字0指出了前面定义的第一个操作数同时也要用来作为输入操作数。
前面的例子是明确要求输出操作数和输入操作数使用同一个寄存器,但有时候刚好相反,输出操作数使用的寄存器一定不能和输入操作数使用的寄存器一样。但是,由于编译器的优化,是完全有可能出现同一个寄存器既用作输入操作数也用作输出操作数的情况的。这时,可以在输出操作数中使用“&”修改符,明确告诉编译器,代表输出操作数的寄存器一定不能使用输入操作数已经使用过的寄存器。下面举个例子:
本例中,将操作一个table数组,读出它的第一个数存放到rdv中,然后修改第二个数为wdv中存放的值。乍看一下没什么问题,但是如果编译器用同一个寄存器来表示输入操作数&table(%1)和输出操作数rdv(%0)怎么办呢?执行完第一条语句之后,table数组的地址就被修改掉了。所以,可以在输出操作数中加上一个“&”修改符,强制保证输出操作数不能和输入操作数复用同一个寄存器,这个问题就解决了。如果汇编代码中有输入寄存器还没有使用完毕,就对输出操作数进行修改的情况,则特别需要用“&”修改符,保证不复用。
3) 修改寄存器列表
在汇编指令中,有可能会用到一些指定的寄存器,但是在执行你定义的汇编程序时,那个指定的寄存器有可能另有别的用途,存放了非常重要的数据。等你的程序执行完成后,那个寄存器的值已经被你修改过了,肯定会造成执行错误。因此,在执行你的程序之前必须要做必要的备份和恢复的动作。但是,编译器并不会分析你的汇编代码,找出这种被你修改过,需要恢复的寄存器,因此你必须显式的告诉编译器,被你修改过的寄存器有哪些。这就是修改寄存器列表所起到的作用。
对于嵌入内联ARM汇编来说,此列表中的值有下面三种类型:

对于“memory”来说,它并不是表示寄存器被读取或修改了,而是表示内存中的值被修改了。出于优化的目的,在执行你的汇编代码之前,编译器将某些变量的值还保存在寄存器中,并没有被写到实际的内存中。但是,如果你的汇编代码会读取内存中的值,则很有可能新的值还在寄存器中,而内存中存放的还是老的值,这样就会造成错误。添加了“memory”之后,编译器会在执行你的代码之前,保证将保存在寄存器中,没有更新到内存中的值全部都写入到内存中。
此列表中的每一项都要用双引号(””)括起来,每项之间要用逗号(“,”)分割。
4.2 conv1x1s1
我假设大家已经知道1x1s1卷积的的原理了哈,网上有很多图例的呀,我这里就展示一个三维版的哈:如下图所示,输入是CHW=(32,16,16)的数据,输出是(8,16,16),weights是NCHW排布的,size为(8,32,1,1);
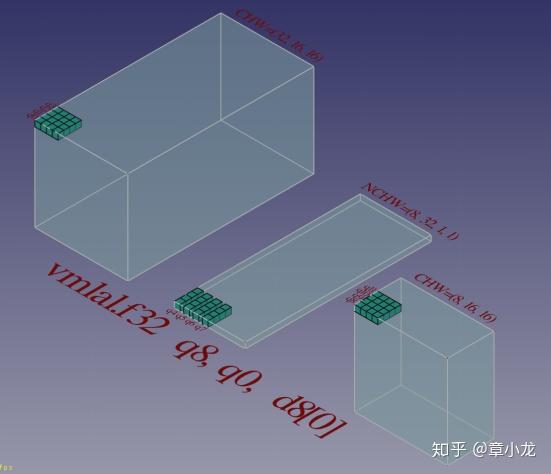
俯视图如下,我们看到具体的size值:
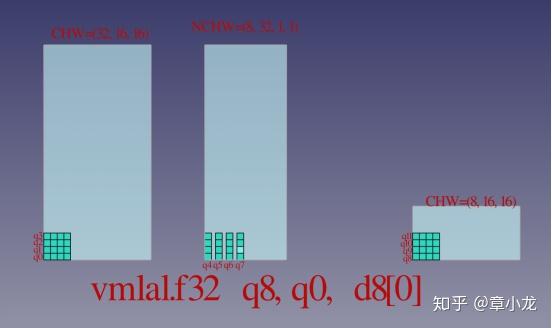
我们再看下卷积核心中的核心的动态图(浪费了我的周末时间啊,建模、配色玩的不亦乐乎~要是大家喜欢的话这个可以gayhub一下啊~):

好了,言归正传,我们如何实现这个卷积,老规矩,先实现纯C++板,分析下性能,然后再写NEON版再分析下性能,不行的话接着优化:
我们首先实现一版纯C++的:
直接获取性能数据如下:
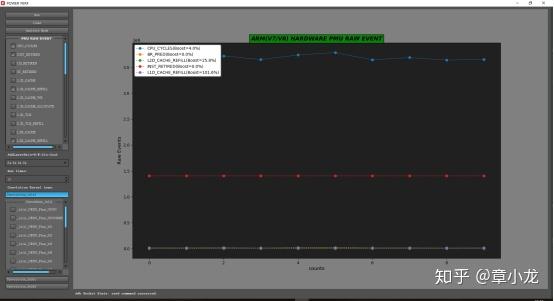
label@perf,CPU_CYCLES=365336032
E/perf@perf: label@perf,SW_INCR=0
label@perf,L1I_CACHE_REFILL=1592
label@perf,L1D_CACHE_REFILL=1249195
label@perf,INST_RETIRED=140567376
label@perf,BR_PRED=1182428
label@perf,L2D_CACHE_REFILL=286768可以看到IPC仅达到140/356=0.39,低的可怜啊,可见我们这里用纯C++实现的版本效率是很低的!
其次通过cache的一些性能参数也可看出访存性能也很糟糕,因此我们接着进行下一步的优化。
我们自然想到用汇编、用SIMD NEON指令集、调整指令流水线、调整访存方案来达到极致的性能。
Todo~
(当然写这些东西很费时间的呀,我只能有时间慢慢写了~由于只是个人兴趣,不定期更新哈~)
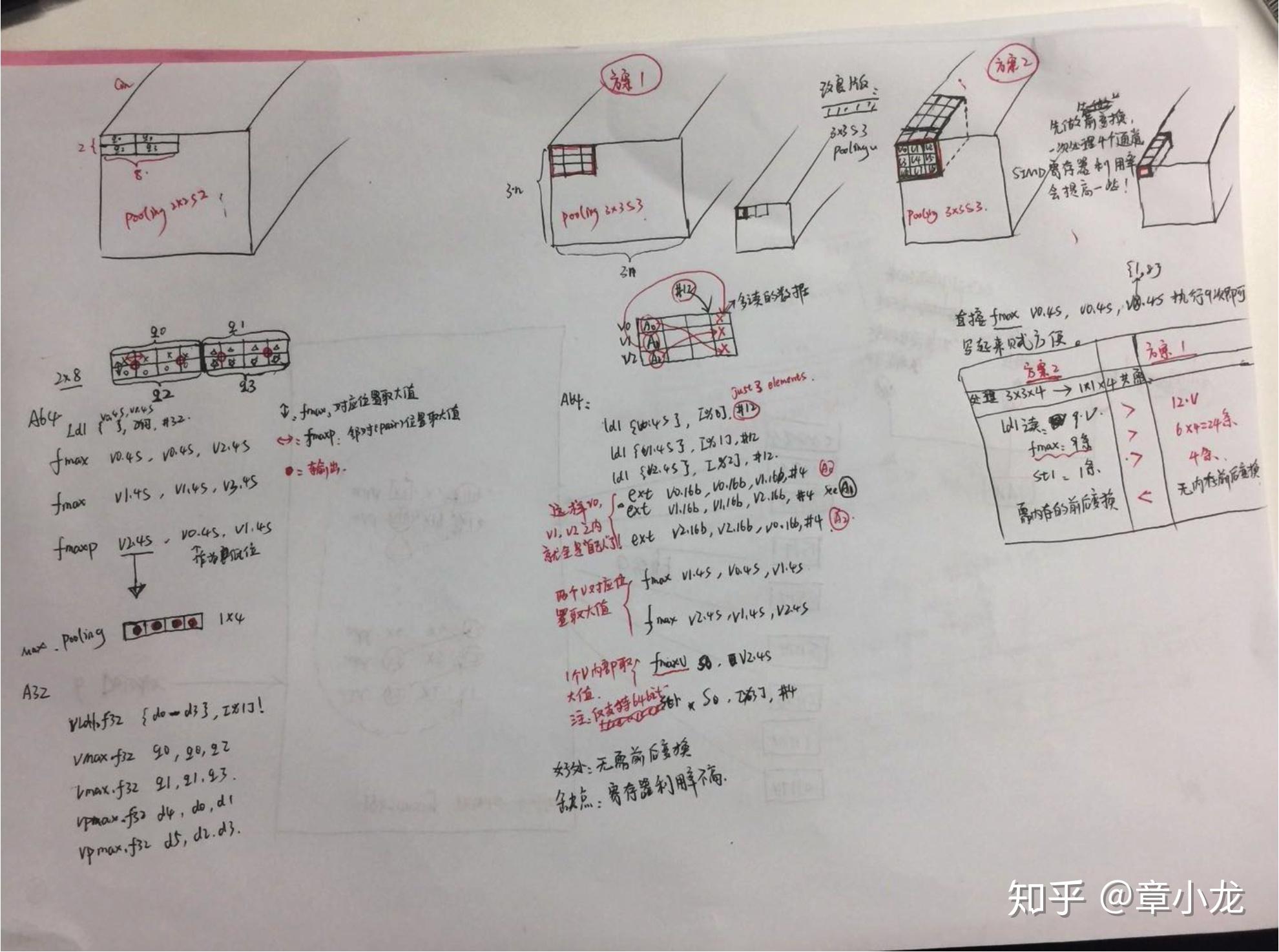
4.2 pooling (图纸only, now)
4.3 to be continue……

AI时代,拥有个人微信机器人AI助手!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
搜索微信号aigc666aigc999或上边扫码,即可拥有个人AI助手!



