深度学习、AI人工智能等技术正在成为各大处理器的热点,虽然目前的主流是通过专用的NPU单元来加速AI指令,但在CPU中集成相应的指令集也会带来很大的改变,Intel在Cascade Lake及10nm Ice Lake处理器中就加入了BFlota16指令集(简称BF16),AI性能达到了前代的2.5倍以上。
ARM今天也宣布了类似的动作,将在下一版ARMv8架构中加入新的Non及SVE指令,以便支持BFloat16运算。
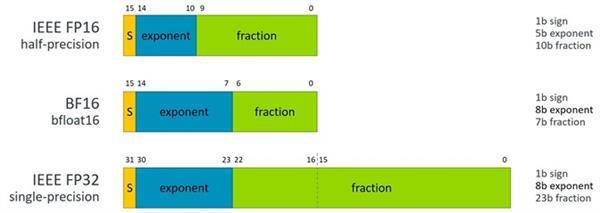
BF16运算还不是IEEE的标准,但与标准的FP32浮点、FP16半精度相比,BF16运算优点多多,它可以轻松取代FP32,而且还能保持正确的NN神经网络操作,这点是FP16做不到的,而且它占用的内存及带宽只有FP32一半,所以性能更高,而且不需要复杂的架构改变。
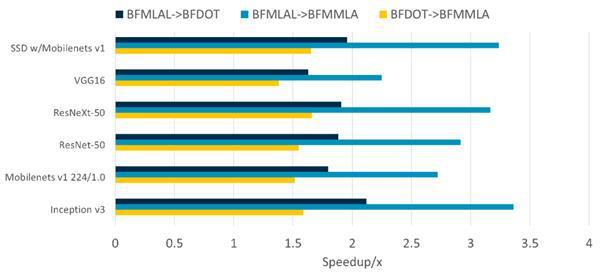
总之,支持BF16运算优点多多,根据ARM做的模拟,不同类型的运算中BF16带来的性能提升不等,少的有1.6倍性能,多的可达4倍性能,所以在AI方面性能变化是非常大的,是前代的数倍之多。

举报/反馈
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。



