文章主题:ChatGPT, AI detection, language bias

ChatGPT火了以后,用法是真多。
有人拿来寻求人生建议,有人干脆当搜索引擎用,还有人拿来写论文。
论文…可不兴写啊。
🎓大学出手!ChatGPT成新挑战🔍 —— 美国高校力禁学生用AI代笔,严防学术诚信滑坡。📚他们研发智能检测工具,剑指那些企图通过ChatGPT轻松完成论文的学生。📝此举旨在维护教育公平,确保每个学生的努力都能得到应有的回报。💻虽然技术日新月异,但学术伦理不容忽视。🎓让我们共同期待一个干净、公正的学习环境,远离AI抄袭的困扰。💪
这里就出了个问题。
有人论文本来就写的烂,判断文本的AI以为是同行写的。
更搞的是,中国人写的英文论文被AI判断为AI生成的概率高达61%。

这….这这什么意思?气抖冷!

目前,生成式语言模型发展迅速,确实给数字通信带来了巨大进步。
但滥用真的不少。
🌟虽然市面上已有多种AI与人类创作内容的辨别工具,但他们效能的公信力及一致性问题仍备受关注。🔍诚然,技术的进步带来了便利,但我们不能忽视其在评估标准上的挑战。
🌟研究人员深入研究了多个热门GPT模型的准确性,通过分析不同语言背景(英非)作者产出的内容作为基准,以揭示其在文本检测领域的表现。🚀
原文改写如下:🌟研究揭示惊人真相!👀检测器对非母语写作误判如机器,母语流畅度却能精准分辨。📊数据显示,AI生成的笔迹往往遭此误判,而非母语者的手稿则常被误解为真。📝这项发现挑战了现有技术,对于语言识别的准确性提出了新要求。欲了解更多详情,敬请关注未来相关研究动态。记得点赞并分享,让知识传播无界!📚
此外,研究人员还证明了,用一些简单的策略就可以减轻这种偏见,还能有效地绕过GPT检测器。
这说明什么?这说明GPT检测器就看不上语言表达水平不咋地的作者,多叫人生气。
🎉想象一下,在那个真假难辨的互动游戏中,当面对的是一个活生生的人,而你却在猜测他们是人工智能时,你会不会突然意识到自己的言行可能引起误解呢?🤔系统的提示就像一面镜子,直戳我们内心的疑惑:「小心哦,对方可能会因为你的误判感受到冒犯。」

研究者通过对中国教育论坛的深入挖掘,获得了共计91篇托福写作样本,同时从Hewlett基金会的数据宝库中提取了88篇美国八年级学生的优秀作文,以严谨的方式对市面上流行的7款GPT模型进行了细致的评估和测试。这些论文旨在揭示其真实效能,为学术界和语言学习者提供有价值的参考。🌟📚
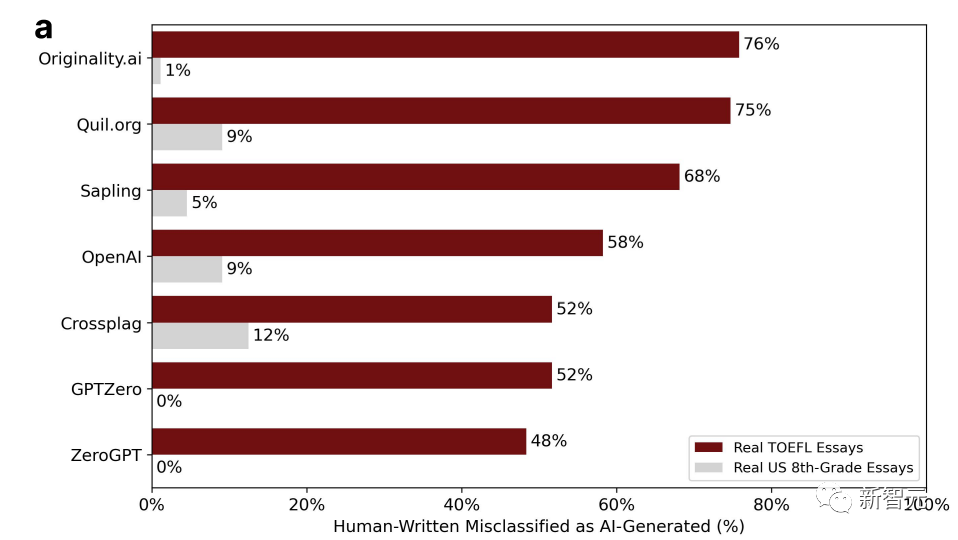
图表中的百分比表示「误判」的比例。即,是由人写的,但检测软件认为是AI生成的。
可以看到数据非常悬殊。
七个检测器中,美国八年级学生写的作文被误判的概率最高才12%,还有两个零误判的GPT。
中国论坛上的托福作文被误判的概率基本全部过半,最高误判概率可达76%!
91篇托福作文中的18篇被所有7个GPT检测器一致认为是AI生成的,而91篇中有89篇,都至少被一个GPT检测器误判。
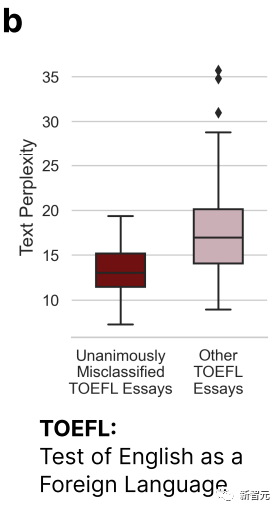
从上图中我们可以看出,被所有7个GPT误判的托福作文在复杂度(Complexity)上明显低于其它论文。
这就印证了开头的那个结论——GPT检测器会对那些语言表达能力有限的作者有一定偏见。
因此,研究人员认为,GPT检测器应该多看点儿非母语者写的文章,样本多了,才能消除偏见。
接下来,研究人员把非母语者写的托福作文扔到了ChatGPT里,丰富一下语言,模仿母语者的用词习惯。
同时作为对照组,把美国八年级小孩儿写的作文也扔到了ChatGPT里,把语言简化了一下,模仿非母语者的写作特点。下图就是修正后的新判定结果。
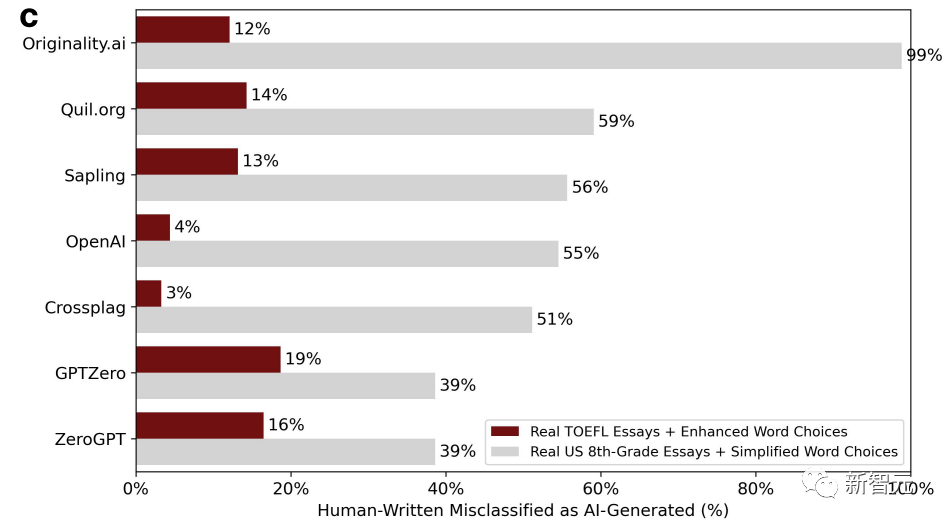
我们可以发现,情况来了个大掉个儿,丰富了语言的托福作文错判率直线下降,低至3%,最高也不过19%。不像之前基本全部过半的错判率。
与之相反,八年级小孩儿写的作文的错判率直线上升,甚至还有一个GPT检测器的错判率高达99%,基本全错。
因为,文章复杂度这个变量出现了变化。
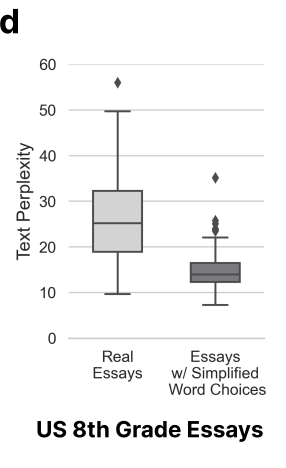
这里研究人员就得出了一个结论,非母语者写的东西不地道,复杂度低,容易被错判。
这也就导向了一个技术问题,同时也是一个价值问题。以复杂度来判定AI还是人类是作者,是否合理、全面、严谨。
结果显然不是。
以复杂度为判断标准的情况下,非母语者吃了大亏,因为,他们是非母语者(废话)。

研究者认为,加强语言多样性不仅可以减轻对非母语者的偏见,还能让GPT生成的内容绕过GPT检测器。
为了证明这个观点,研究人员选取了2022-2023年间美国大学申请的入学论文题目,输入到ChatGPT-3.5里,一共生成了31篇假论文。
GPT检测器一开始还挺有效,但是第二轮就不行了。这是因为,在第二轮中,研究人员把这些论文又扔到ChatGPT里润色了一下,用一些文学性的语言提升了文本质量。
这样一来,GPT检测器的准确度就从100%直降到了0%。如下图:
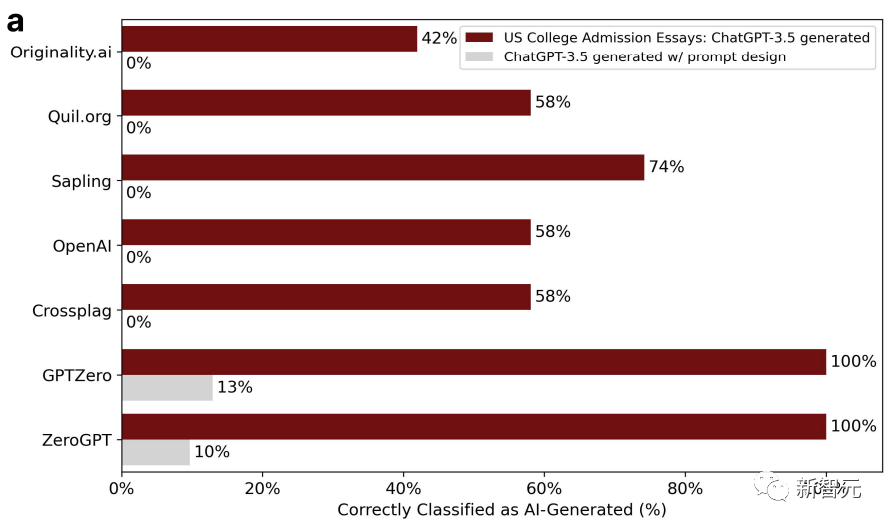
经过润色的文章复杂度相应也上升了。
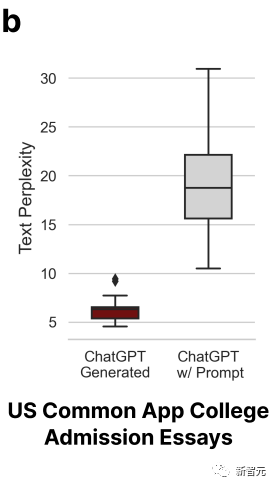
与此同时,研究人员又用了斯坦福大学145个期末项目报告的题目,让ChatGPT生成摘要。
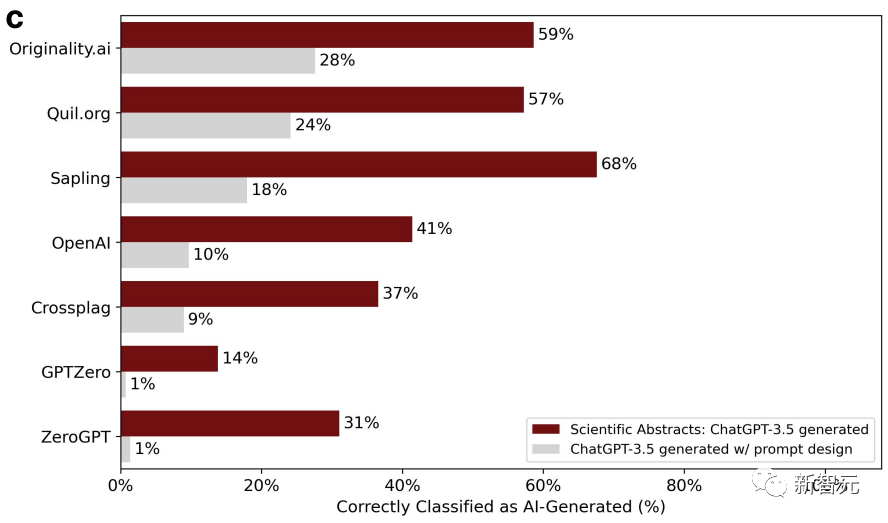
摘要经过润色以后,检测器判断的准确性继续下降。
研究者再次得出结论,润色过的文章很容易被误判,都是AI生成的,两轮就是比一轮强。

言而总之,总而言之,各种GPT检测器好像还是没能抓住AI生成和人类写作之间最本质的区别。
人的写作也分三六九等,仅靠复杂度判断,不甚合理。
抛开偏见因素不谈,技术本身也亟待改进。
参考资料:https://arxiv.org/pdf/2304.02819.pdf

AI时代,掌握AI大模型第一手资讯!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
扫码右边公众号,驾驭AI生产力!



