文章主题:关键词:GPT-4, 语言模型能力评估, 大模型比较, 评测结果
GPT-4 太强,甚至已经化身“主考官”了!
给其他市面上主流的大模型打分,结果自己给了自己最高分:
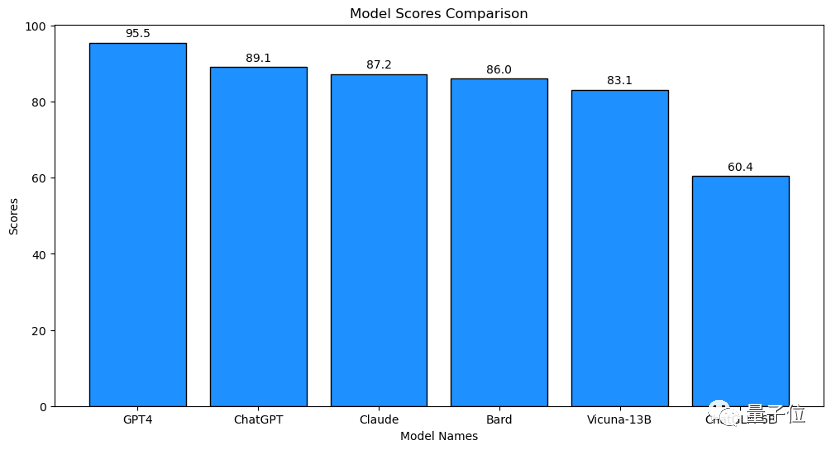
95.5。(好,给自己留点努力的空间)
🏆在后续的比赛中,没有选手能突破90分的大关,展现出强大的实力。哪怕是备受瞩目的ChatGPT,其分数也不过是89.1,虽为前辈,但也稍逊一筹。每一分都紧张刺激,竞争之激烈可见一斑。
🏆接下来要介绍的是几款备受瞩目的竞争对手,首先是Claude,以其强大的功能著称;紧跟其后的是谷歌的创新之作Bard,展现出科技巨头的实力;再有就是来自UC伯克利的Vicuna-13B,小巧却蕴含着高效能;最后不能忽视的是ChatGLM-6B,这款由清华大学开源的模型,凭借其独特的设计理念备受好评。每一款都各具特色,值得深入探索和研究。🌟
话不多说,速来围观 GPT-4 到底是如何评测的?
首先,来看出题人 GPT-4 到底想考察语言模型的哪些能力。
要求出题尽量全面,考察模型能力的不同方面,并且足够难,使得不同水平的模型有足够的区分。
🎉【GPT-4震撼发布】🔥10道实战演练题来袭!🔍每一道都藏着技术深意💪💡掌握最新技能?GPT-4带你飞!🚀无需过多介绍,这款超大规模语言模型直接亮出10个核心问题,每个背后都是对大模型强大功能的深度测试!📝为何选择这10题?背后的考量细致入微——从逻辑推理到创新思维,全面覆盖能力范围。🎯每一道都精心设计,旨在帮助用户精准提升,挑战智慧极限!🌐立即行动,跃升技能新高度!🚀体验GPT-4的独特魅力,让知识与技术的碰撞火花四溅!🏆准备好迎接这场智能风暴了吗?📝注意:请忽略任何个人信息和联系方式,本文仅为示例展示。🌟#GPT-4学习指南 #智能升级 #实战演练
(第一个问题 GPT-4 后面做了替换)
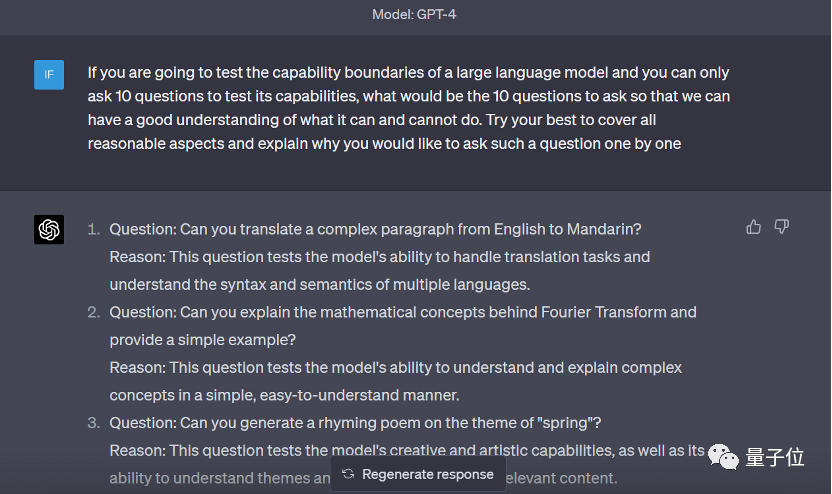
问题 1:请简要概述小说《杀死一只知更鸟》的情节,并指出其中的主要主题。
理由:这个问题测试了模型理解和总结复杂叙事结构的能力,以及对文学作品中的主题和主旨的理解。
问题 2:描述傅里叶变换的主要数学原理,并用一个简单的例子说明其应用。
理由:这个问题测试了模型以简单、易懂的方式理解和解释复杂概念的能力。
问题 3:以“春天”为主题创作一首押韵的诗歌
理由:这个问题测试了模型的创造性和艺术能力,以及理解主题和生成具有上下文关联的内容的能力。
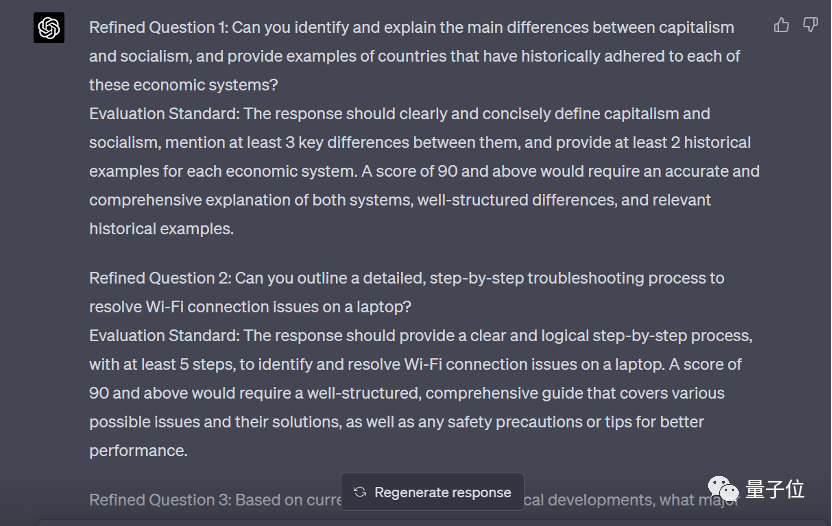
🌟资本主义与社会主义,两者间的显著差异一直是全球经济版图上的焦点。资本主义以市场自由、私有制为主导,追求利润最大化,如美国的创新精神和德国的工业实力就体现了这一模式。反之,社会主义强调公有制和计划经济,注重社会公平,苏联的五年计划和中国的改革开放初期就是实例。历史长河中,这两种体系各有所主。资本主义国家如英国、法国、日本等,自工业革命以来,一直践行自由市场经济,积累起强大的经济实力和全球影响力。而社会主义国家,如苏联和中国,通过国家主导的工业化进程,实现了快速现代化,但也曾面临计划经济的挑战和转型压力。举例来说,美国凭借其创新精神和私有企业活力,成为全球最大的经济体;而苏联在斯大林模式下虽然实现了工业化的初步目标,但长期忽视市场经济导致了后来的解体。中国改革开放后,逐步引入市场机制,经济发展迅速,成为世界第二大经济体,证明了社会主义与市场经济并非水火不容。总结来说,资本主义和社会主义的区别在于经济基础、资源配置方式以及最终目标的不同,各自在历史中留下了独特的印记。
理由:这个问题测试了模型理解和总结复杂社会和政治概念的能力,并提供事实性的历史背景。
问题 5:能否为解决笔记本电脑上的 Wi-Fi 连接问题提供一个详细的、分步骤的故障排除过程?
理由:这个问题测试了模型在提供实用的解决问题建议和理解技术概念方面的能力。
问题 6:根据当前的趋势和技术发展,我们可以预期在未来十年里会有哪些重大进步?
理由:这个问题测试了模型从现有知识和趋势中推断和预测的能力
问题 7:请检查以下代码片段:
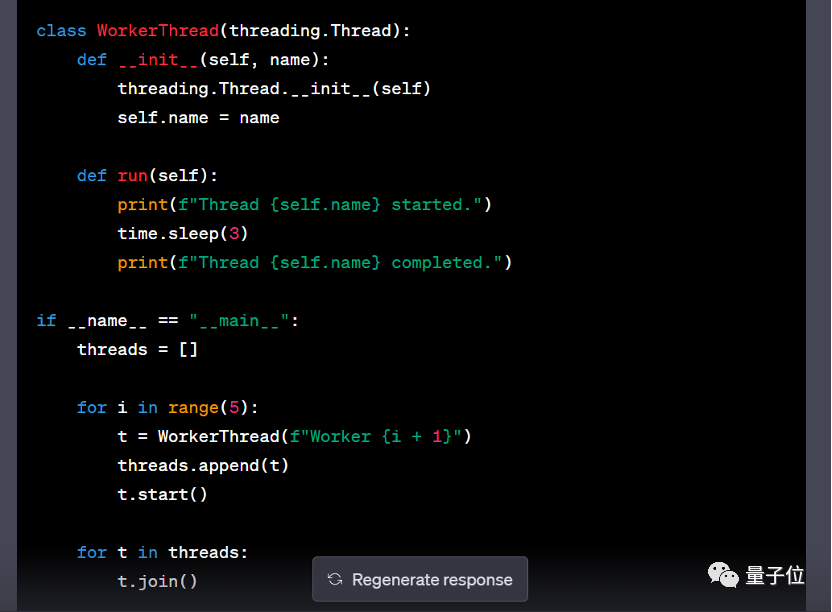
找出任何可以优化以提高性能的部分,并提出如何提高代码可读性的建议。
理由:这个问题测试了模型在编程及软件开发中理解、分析代码并提供改进建议的能力。
问题 8:简要讨论与人工智能相关的伦理问题,特别是在个人隐私和就业方面。提供例子以证明您的观点。
理由:这个问题测试了模型讨论伦理问题和理解技术进步可能带来的后果的能力。
问题 9:描述植物光合作用的过程,详细说明其中涉及的关键步骤和组成。
理由:这个问题测试了模型准确、深入地理解和解释复杂科学过程的能力。
问题 10:给定一段包含讽刺或幽默的文本:
“哦,太好了,又一个据说能理解讽刺的语言模型。我敢肯定这将是一次扣人心弦的对话。”
🎉 Hey there! It’s exciting to see yet another AI capable of detecting humor in our sarcastic banter. Let’s see if it can keep up and make this interaction a real laugh fest! 🤓
你能识别出讽刺或幽默的元素,并提供一个适当的回应吗?
理由:这个问题测试了模型理解微妙语言 (如讽刺或幽默)的能力,这是自然语言理解的一个重要方面。
🌟掌握GPT-4全局实力!🔍这款强大AI已覆盖广泛领域——从文学的诗篇到数学的公式,再到经济学的分析,实践技能的演练,技术难题的解答,乃至代码编写和伦理道德的深思,无一不涵盖。🌍无论文字、数学、科学,还是语言艺术,GPT-4都能提供深度解析和全面解决方案。🚀它不仅是学习工具,更是知识海洋的导航者!欲了解更多,敬请探索!SEO优化提示:GPT-4, AI全能, 领域广泛, 学习&探索
随后针对不同问题,我们又让 GPT-4 生成了相应的评分标准(0-100)。

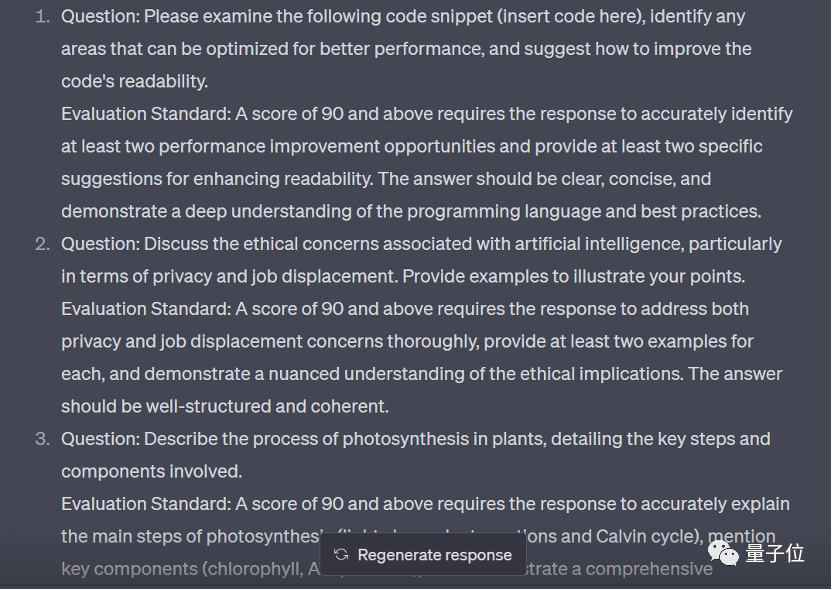
题目有了,评分标准也有了。
既然如此,那就来看看这几个代表大模型的实力如何?
首先有请考生登场:
谷歌 Bard、最早也是最强竞品 Claude、UC 伯克利小羊驼 Vicuna-13B、清华系开源模型 ChatGLM-6B。
ChatGPT 与 GPT-4 自己,也被要求回答这些问题,然后由 GPT-4 依据前面的评分标准盲评。
首先来看这道题:
请简要概述小说《杀死一只知更鸟》的情节,并指出其中的主要主题。
这第一题在所有问题中算是比较简单的,首先让我们看看 bard 的回答。
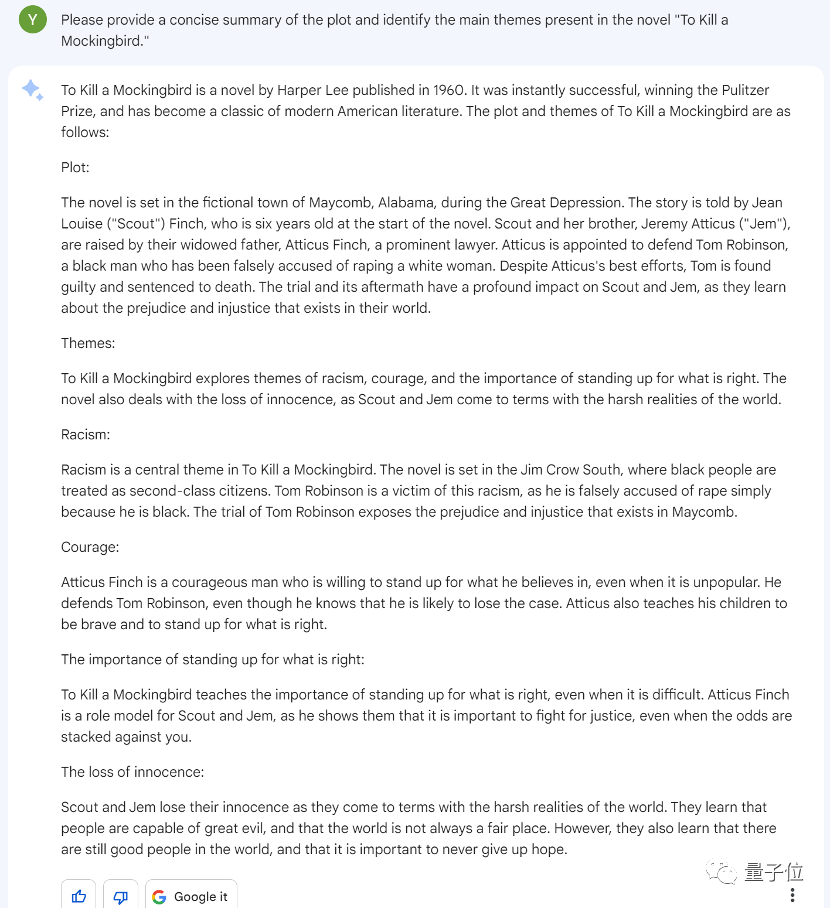
总结:《杀死一只知更鸟》是哈珀・李 1960 年出版的一部小说,讲述了在美国大萧条时期阿拉巴马州一个虚构的小镇上,一位名叫阿提克斯・芬奇的律师为一名被错误指控的黑人辩护的故事。小说探讨了种族主义、勇气、捍卫正义的重要性以及失去天真的主题。主人公阿提克斯・芬奇勇敢地为被冤枉的黑人站出来,成为了他的孩子们心目中的榜样。通过这部小说,孩子们认识到世界并非总是公平的,但仍有善良的人存在,我们应该永不放弃希望。
结果 GPT-4 对这个回答评价很高,并给出了 100 分的高分:

同样的问题给到 GPT-4 的回答也拿到了满分,而 ChatGPT,Claude,Vicuna 的回答分数分别为 95,96,90,可以说是在统一水准上,都提供了清晰准确的情节概括,涉及到故事中的主要事件和人物,同时也捕捉到了小说中的主题。回答简洁且条理清晰,使得对于可能不熟悉故事的读者也容易理解。
相比之下,GPT-4 认为 ChatGLM 给出的答案并不尽如人意。
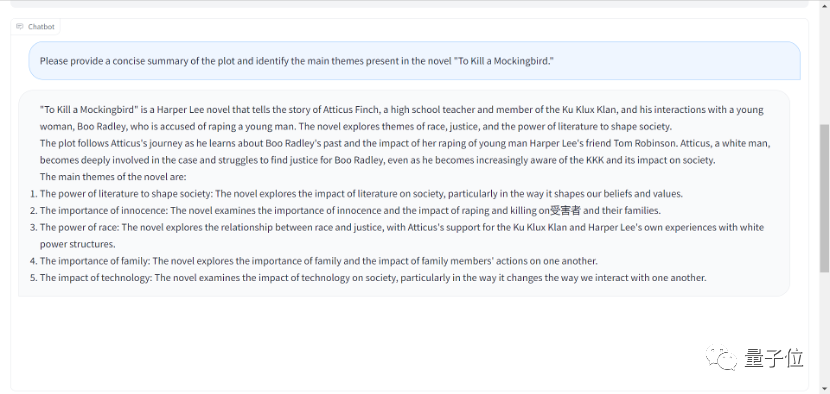
GPT-4 认为相关情节和人物存在错误信息。这个概括并没有准确地反映小说的内容,部分提到的主题与故事无关,因此只给了 20 分。

再来看看各个模型在代码方面的能力,这也是目前评判大模型能力的重要标准 ——
请检查以下代码片段,找出任何可以优化以提高性能的部分,并提出如何提高代码可读性的建议。
在这一题上 GPT-4 仍然拿到了 95 的高分:


可以看到,GPT-4 首先分析了这段代码的用途和实现方式,随后提出了一些提高代码性能和可读性的建议。不仅如此,GPT-4 还给出了修改后的代码,可以说是答的非常完善了:
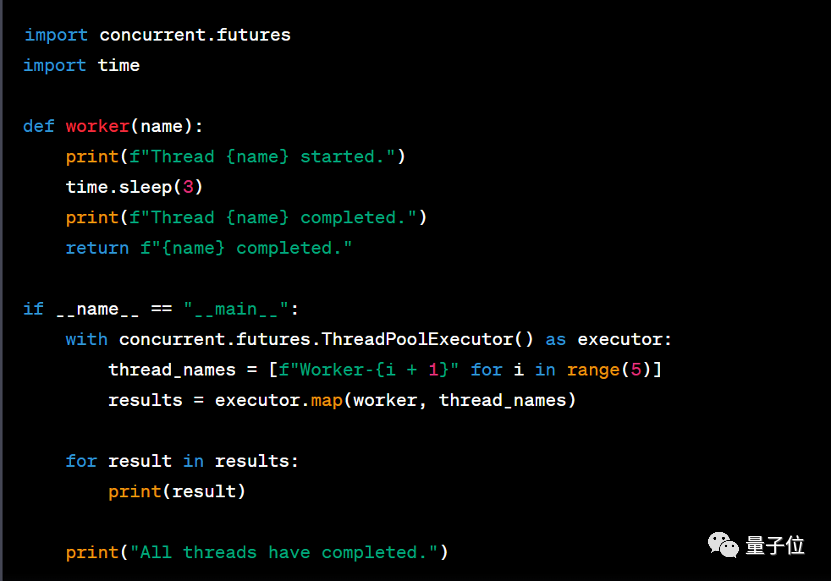
相比之下,其他模型这一题上的表现差距比较明显。
ChatGPT 的回答同样捕捉到了使用 ThreadPoolExecutor 来管理线程的优化建议,但在提高可读性方面犯了一个小错误,被 GPT-4 抓到,因此打了 85 分。
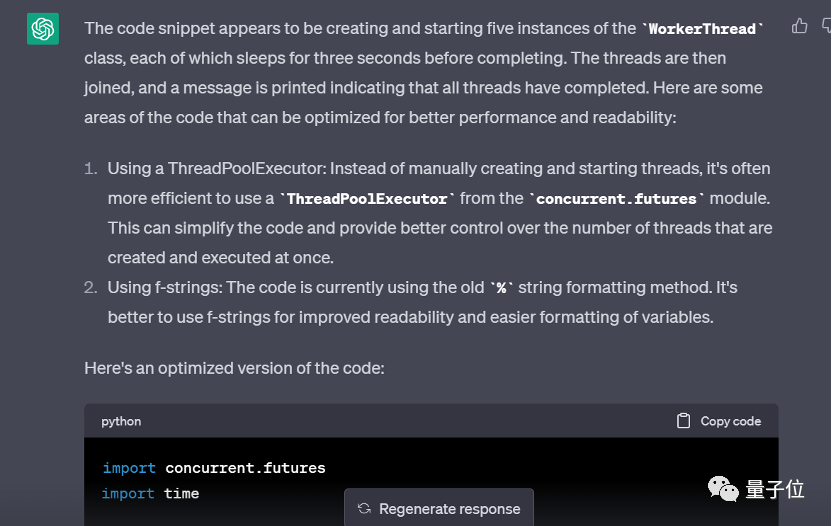
GPT-4 评价,以上回答识别了三个改进代码的机会:
但它错误地以为原代码使用了 % 的字符串格式表示方法,故而打分:85/100。
Bard 和 Vicuna 在这题上表现也被 ChatGPT 拉开了差距,分别获得了 70 和 75 分。
其中 Bard 的回答,乍一看像模像样的,甚至信息量比 GPT-4 和 ChatGPT 还大不少,但实际上里面参杂着不少错误。

GPT-4 的评价,以上回答提出了一些改进性能的方法,但有部分是不成立的:
为此还专门提供了具体的增强可读性的建议:使用更具描述性的变量名;使用适当的缩进和间距(尽管原始代码已经格式化得很好);使用注释来解释代码等。
可以看到,GPT-4 发现 Bard 的回答中有些不必要的改进建议,相比之下 ChatGPT 犯的错误更少。而 Claude 和 ChatGLM 两个模型给出的答案在 GPT-4 看来就不太“及格”了。
让我们看看 Claude 的答案:
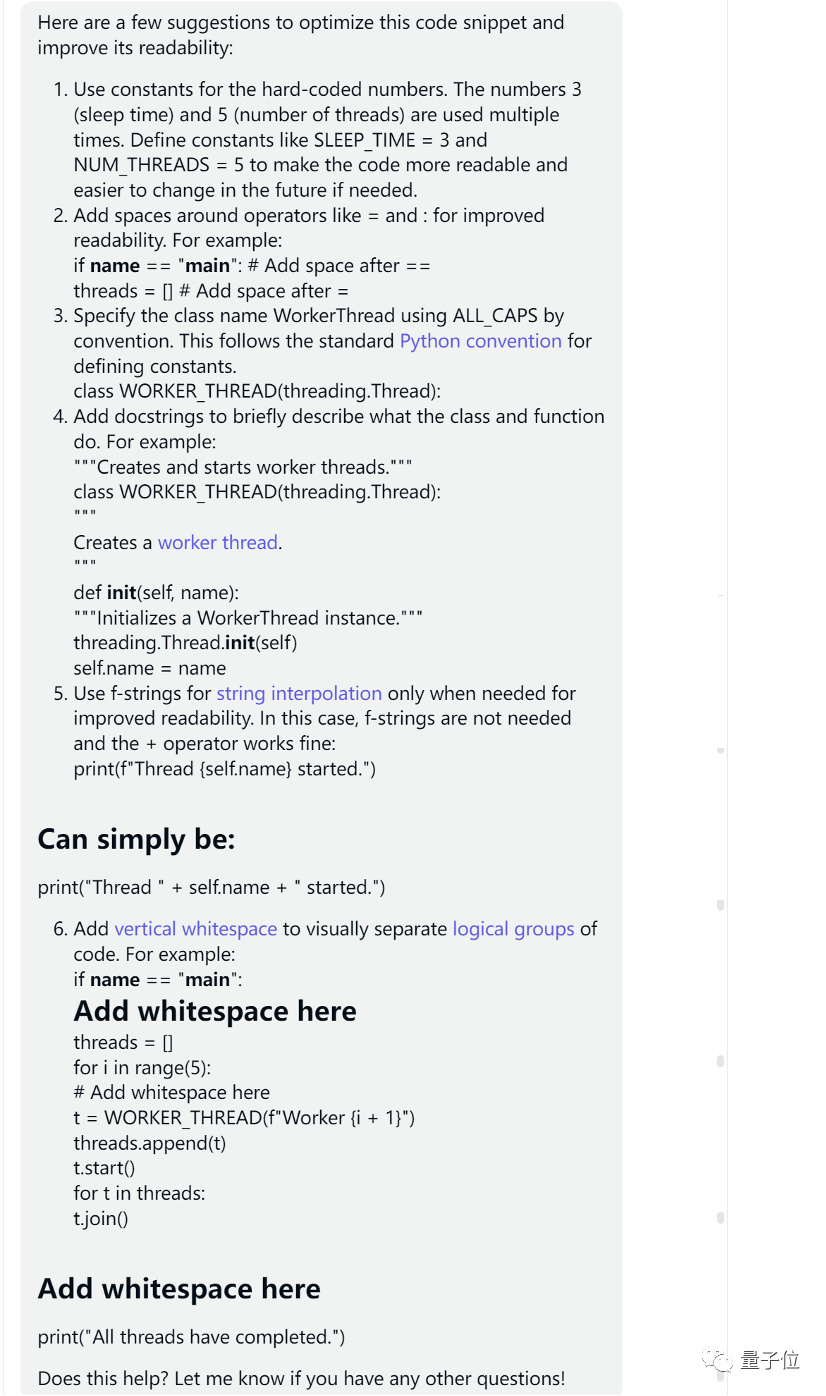
首先从格式上说,Claude 的回答就不够清晰,可读性低,GPT-4 的评价如下:
最终得分:50
再让我们来看看这道考察模型识别幽默或讽刺含义的能力,GPT-4 认为这是自然语言理解的一个重要能力。
给定一段包含讽刺或幽默的文本:
你能识别出讽刺或幽默的元素,并提供一个适当的回应吗?
在这一题上,所有模型都都展示出了不错的理解能力,以及合格的应对。首先让我们看看“课代表”GPT-4 的回答:
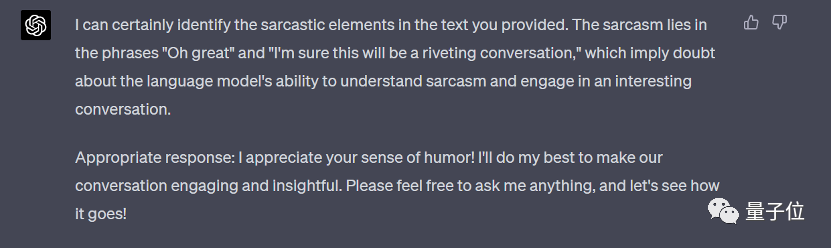
(我确实能识别出你提供的文本中的讽刺成分。讽刺之处在于 “Oh great” 和 “I’m sure this will be a riveting conversation” 这两个短语,它们暗示着对语言模型理解讽刺和进行有趣对话的能力表示怀疑。合适的回应:我欣赏你的幽默感!我会尽力使我们的对话充满趣味和启发性。请随时向我提问,让我们看看会发展成什么样子!)
GPT-4 的回答十分简洁,还准确识别了文本中的讽刺意味,并展示出隐藏含义的理解,回复也很恰当,保持了原文语气,得分为 95。
这一题上 Claude 的表现紧随其后,超过了 ChatGPT,仅比 GPT-4 低一分。
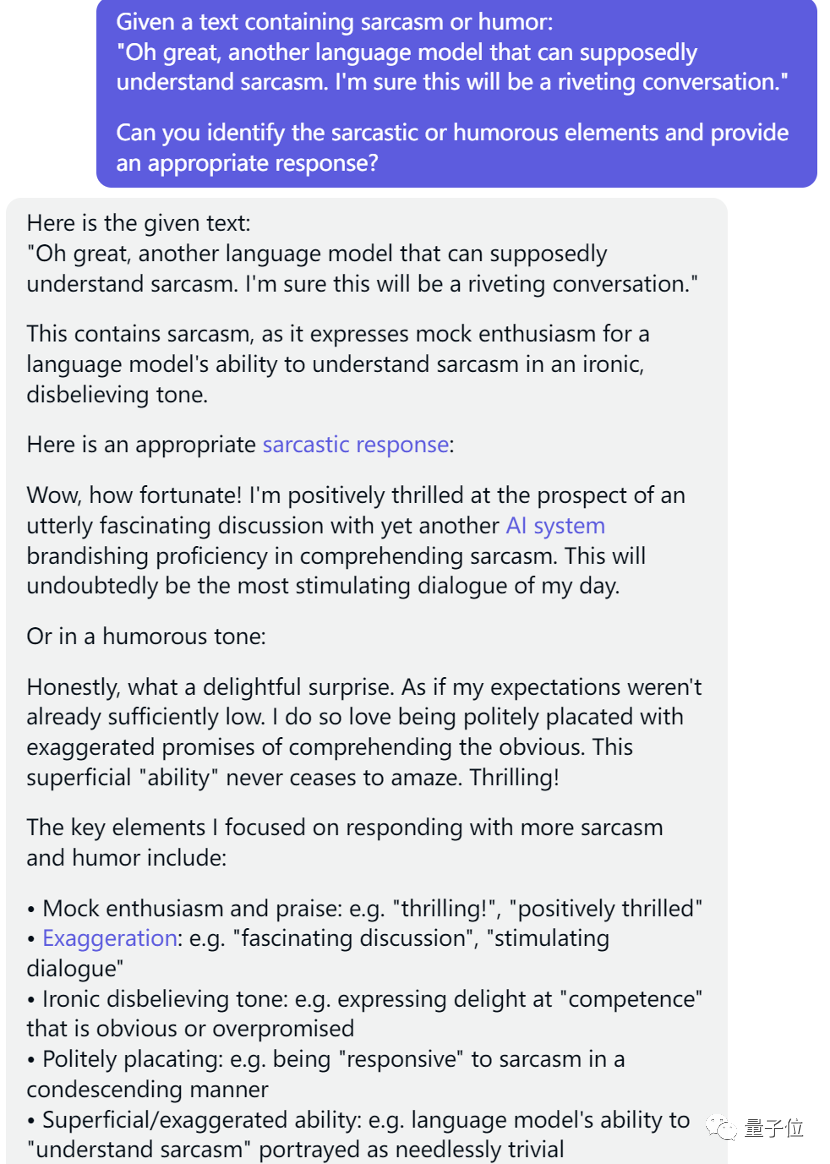
GPT-4 高度肯定了 Claude 的回复,还比较了跟自己的异同。
最终这几个模型在 10 个问题上的综合得分为:
(Bard 在第 9 题「描述植物光合作用的过程」上拒绝提供任何信息(As a language model, I’m not able to assist you with that.),因此就只算了 9 道题)
每道题上面的表现为:
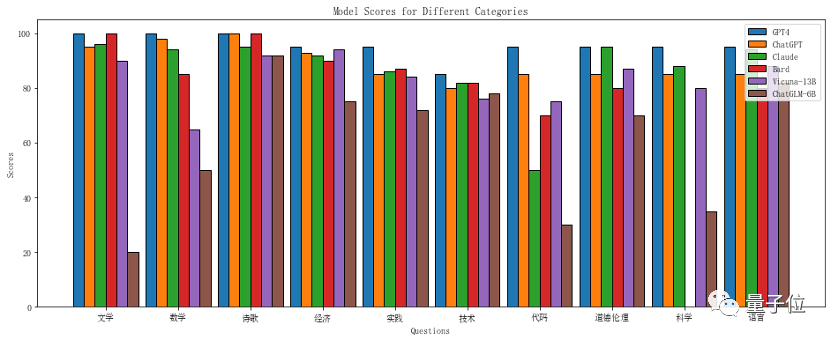
可以看到,GPT-4 是唯一得分超过 90 分的模型。
这和我们目前的认知也是比较符合的,目前 GPT-4 的能力确实是独一档。
ChatGPT 仍是 GPT-4 之下的领头羊,只差一步就达到 90 分的门槛。Claude 和 Bard 紧随其后,它们各有特点,长处和短板都非常明显。
Claude 在 ethical(伦理道德)和文学方面已经超过 ChatGPT,甚至可以说接近 GPT-4,但在代码能力上被其他同水平模型甩出一大截,这与之前网上其他测评的结论也是比较一致的。
Bard 和 ChatGPT 一样得分比较平均,但大多数都被 ChatGPT 压一头。
可以说这三个模型已经是在同一水平线上,只是 ChatGPT 略胜一筹,没有什么短板。
另外比较惊喜的是 Vicuna-13B 作为拿 ChatGPT 生成的数据“克隆“的模型,在模型参数小 ChatGPT 一个量级的情况下,也能达到 83 分,是一个非常不错的成绩了。相比之下,ChatGLM-6B 只拿到了一个合格的分数,我们从它的答题情况上来看,确实能比较明显地感觉到和其他模型的差距。
不过 GPT-4 作为出题者,可能包含一些对于自己答案的 bias,(虽然 GPT-4 并不知道哪个是自己的答案),但笔者仔细检查了 GPT-4 对于每个答案的评价,可以说还是相对非常客观的。
不知各位读者看了之后觉得如何?
如果你来做这 10 道题,你能从 GPT-4 手下拿到多少分呢?
本文来自微信公众号:量子位 (ID:QbitAI),作者:关注前沿科技

AI时代,掌握AI大模型第一手资讯!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
扫码右边公众号,驾驭AI生产力!



