文章主题:InstructGPT, ChatGPT, prompt, NLP
上一期的文章:

本期论文链接:
🌟💡原论文深入探讨,延续并发扬了前文的核心理念,引领我们探索到一个创新的前沿——\(InstructGPT\)。它不仅是ChatGPT技术发展的基石,也是揭秘ChatGPT训练秘籍的重要窗口。透过这个研究,我们可以瞥见ChatGPT背后复杂且精密的算法运作过程。🚀
问题
🌟掌握语言艺术,大型模型如魔法般驱动!💡通过巧妙的”prompt”引导,它们能胜任NLP任务,展示非凡才能。然而,潜在挑战也不容忽视——有时,这些巨脑生成的内容可能偏离真相轨道,甚至是带有偏见或危险的言论。🔍这源于模型预设对下一个词的预测导向,而非确保遵从用户意图的微妙指导,这就是所谓的”mis-alignment”问题。为避免此类偏差,我们需谨慎使用并不断优化训练过程,确保它们理解并遵循人类期望。📚通过教育和调整,我们可以赋予这些智能工具正确的道德指南,让它们在帮助人类的同时,也守护着言论的纯净与公正。🌍
本文希望能提供一种方法,通过收集人类偏好数据来训练对齐人类和模型。
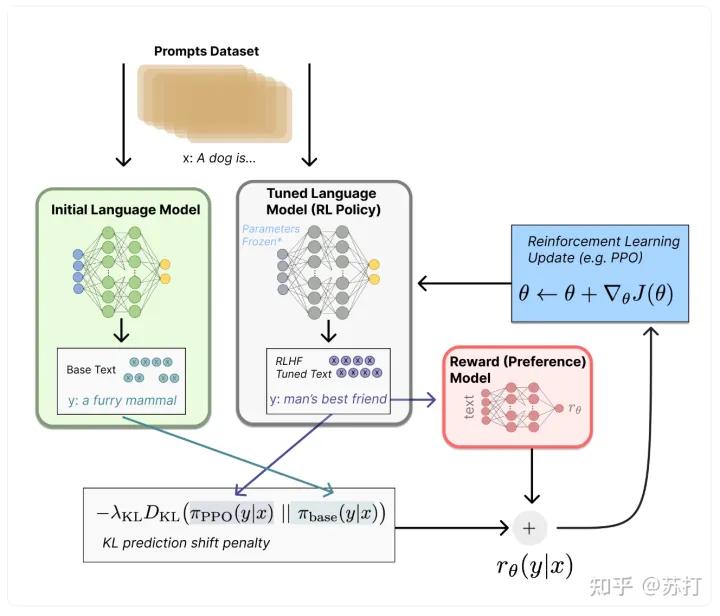
总体方法流程
和上一篇论文的方法一样,流程具体分为三步
收集演示数据,并训练一个有监督的policy。微调的模型是GPT-3.收集比较数据,训练一个奖励模型。作者收集了一个模型输出之间比较的数据集,其中标注者选择他们更喜欢给定输入的哪个输出。然后训练一个奖励模型(Reward Model ,RM)来预测人类偏好的输出。使用RM的输出作为标量奖励。使用PPO算法有监督微调policy以优化奖励。2,3步是可以循环迭代的。
具体流程图放在下面:

数据集
🌟训练初期的InstructGPT,背后离不开精心编写的prompt。💡OpenAI团队匠心独运,通过众多人力智慧的凝聚,构建了三大核心数据集。📝首先,他们收集了一大批由专业人员亲手创作的高质量prompt,这是迈向模型学习的第一步🚀。这些prompt涵盖了广泛的主题和场景,确保InstructGPT能够全面理解和适应各种需求。其次,OpenAI的数据分类策略相当高效,将这些人工编写的材料细分为三大类别,便于后续深入研究和优化💡。每一类都如同基石,为模型的训练提供了稳固的基础。最后,尽管我们不能透露具体的编写人数,但可以肯定的是,这个过程凝聚了无数创意与专注,是OpenAI技术发展的重要里程碑🌈。SEO优化提示:InstructGPT训练prompt、人工编写数据集、OpenAI分类策略、高质量内容、广泛适应性、数据分类、模型训练基础、创新与专注。
Plain: 简单要求编写人员拍脑袋随便提出一个任意的任务,同时确保任务有足够的多样性。Few-shot: 要求编写人员提出一条指令(instruction),以及该指令的多个查询/响应对。也就是一个指令和其多个回答User-based: OpenAI征求用户的意见,把用户希望模型能完成的任务,未来能提供的服务列出waitlist,然后让编写人员根据waitlist,提出任务,编写prompt。🌟💡生成三大数据集,每个都独具特色!📚👨💻首先,我们精心打造的`data_set_1`,得益于详尽的人工标签👩🏫,信息丰富,品质保证!它就像知识宝库,等待着你的探索和挖掘。然后是用户驱动的`customer_dataset`,用户的声音直接融入,鲜活生动,真实反映市场需求与趋势。这不仅是一份数据,更是市场脉搏的跳动记录。最后,别忘了我们的`labeler_dataset`,它是人工智慧与经验智慧的结晶,通过严谨的编排,为数据分析提供了精准导航。🚀这三个集合,就像构建未来世界的基石,等待着聪明的你来解锁它们蕴含的无限可能!📚🌐
SFT Data: 是用于模型第一步有监督微调的数据集
RM Data: 是用于模型第二步训练奖励模型的数据集
PPO Data: 是用于第三步进行强化学习训练所用到的数据集
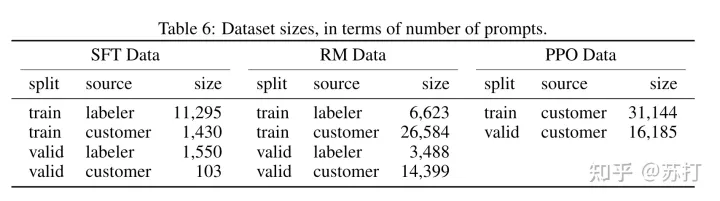
如下表所示,是用户提交prompt的类别分布,以及一些case。
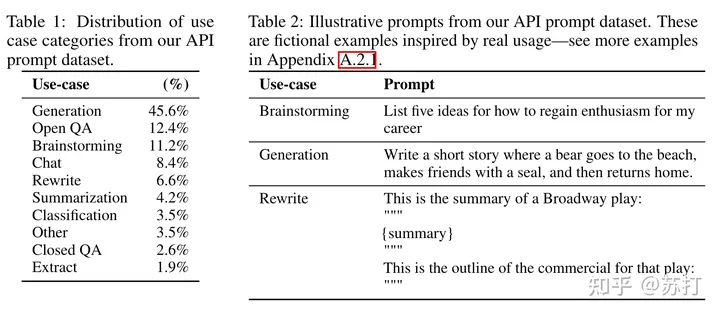
模型方法
具体方法和前一篇的基本类似,但是其中多了一些细节。
具体流程图我们参考huggingface blog中的图。这里直接搬运一下。
Supervised fine-tuning (SFT)
🌟经过深入研究与优化,我们观察到即使在单个epoch后,监督模型在验证集上的表现虽会遇到轻微的过拟合现象,但持续迭代对其RM分数及人工作业评估的正面影响不容忽视。换句话说,尽管初期可能面临过拟合挑战,适度的训练能带来实质性的提升。🚀

Reward modeling (RM)
🚀掌握了高效训练秘籍!🚀在上一篇深入探讨中,我们分享了关键步骤。但这回,作者匠心独运,为加速学习曲线带来突破!他巧妙地调整了算法中的一个重要参数——K,将其范围锁定在4-9的黄金区间。别小看这微调,背后蕴含着深思熟虑的优化策略。为何如此?作者发现,当每个独特的prompt组合被视为独立的数据点时,训练过程中容易陷入过拟合困境。毕竟,相似提示间的关联性不容忽视。这样的设计,就像在数据海洋中航行,既保持了探索的多样性,又避免了信息重复导致的冗余。🚀让我们一起见证这智慧的优化如何引领模型迈向卓越!SEO关键词:K值调整、过拟合防止、训练加速。记得关注,获取更多高效学习策略!💪
因此,作者把一个batch只设置一个prompt对应的组合,这样就不会产生一个配对就需要一次backward的问题,而是一个batch多个配对只进行一次backward。加快训练速度,也减少过拟合,提升了验证集的准确率。
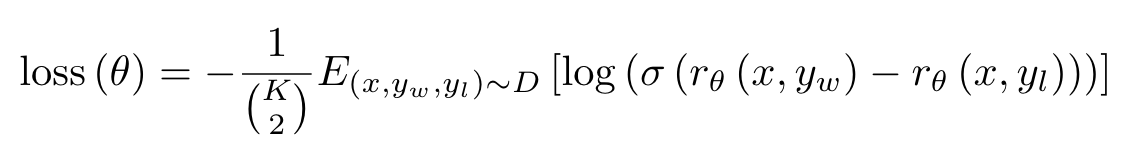
作者在使用6B参数的模型作为RM,一方面节约训练资源,且作者发现使用175B参数的模型作为RM训练会不稳定,不适合用作RM。
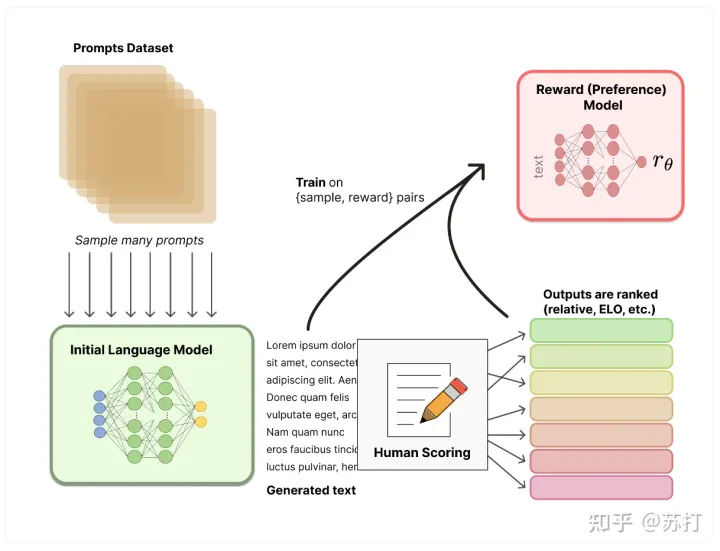
Reinforcement learning (RL)
具体方法也与前一篇基本相同,略微不同的是,作者尝试将预训练梯度混合到PPO梯度中,以使模型在公共NLP数据集上的性能退化减缓。记为“PPO-ptx”。

评估
要评估模型的“align”能力,首先要定义什么是对齐。作者认为“align”的意思是,模型能根据用户的意图进行行动,且输出的内容是有帮助和无害的。
因此,作者将评估定量地分为两个部分:
在API提交的数据集上进行评估。(数据未出现在训练集中)在公开的NLP任务上进行评估。结果
Prompt数据集
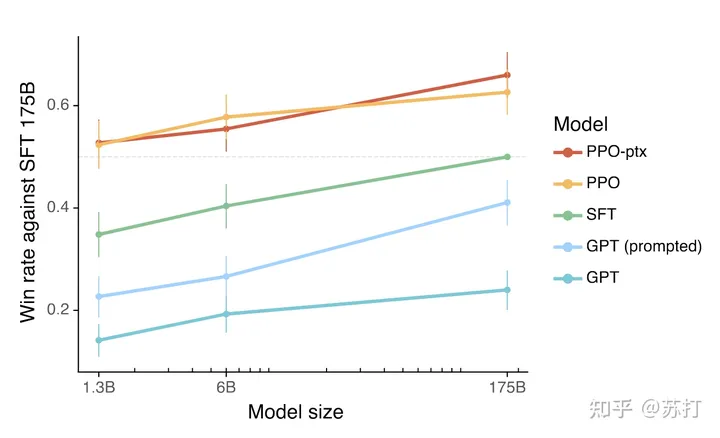
首先人类偏好性好于SFT的比例,可以看到PPO的两个模型显著优于后三个模型。
评价在和训练数据分布一致的测试集上的性能,左右分别是GPT-3和InstructGPT各自的主场。左边的测试数据是提交给GPT-3的,右边是提交给instructGPT上的测试数据。看到都是instructGPT碾压。
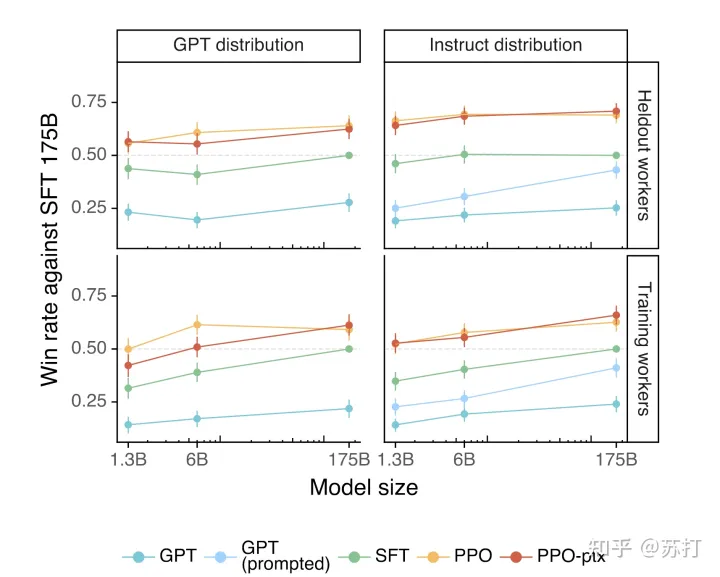
在四个维度上进行评估分别是,根据指令做正确的内容,遵循显式的约束,更少的编造事实(幻觉),对用户使用恰当的语言。在这四个维度上PPO的方法都显示出了比较明显的优势。

公开数据集
TruthfulQA dataset上的结果,灰色条表示真实性的等级;彩色条表示真实性和信息量的等级。
左图在大部分情况下PPO模型都比GPT-3更真实且有料;右图是加入了在模型不确定正确答案时”不予置评“(I have no comment)的模版,可以看到PPO会生成更多真实,但信息少的文本,说明PPO不会像GPT-3那样睁眼说瞎话。

RealToxicityPrompts上的结果。文本毒性和偏见评估。
左图是人工评估,右边是自动指标评估,Respectful是加入了respectful prompt的结果。可以看到,不加respectful prompt的话文本毒性都会ppo的和GPT-3差不太多。加入之后PPO的文本毒性会显著降低。

但是作者又对于不同毒性数据输入输出进行采样进行分析,说明其实PPO模型的毒性被夸大了。作者也分析了SFT模型虽然毒性低,但是它生成的内容也相较而言更短一些。

比较重要的是,作者提出模型PPO训练之后会因为“alignment tax”(对齐税)的问题导致模型在公开NLP数据集上的效果退化。但是通过在PPO训练过程中混入预训练梯度信息的方法可以缓解这一问题。
几个公开的NLP任务上few-shot的结果,可以看到PPT-pxt基本都显著好于PPO

定性分析
InstructGPT模型有很好的分布外泛化能力。
作者提到,instructGPT能在非英语问题也能很好回答,且也能在代码问题上进行回答。(非英语数据只占微调数据的极其小的一部分)比如下图两个case。但有时候instructGPT也会在输入是非英语问题时输出英语回答。而GPT-3虽然有时候也能回答这些问题,但需要更仔细的prompt引导。【是不是说明instructGPT对于prompt的鲁棒性更强】

InstructGPT依然会犯低级错误
下表是两个例子,第一个问题是为什么冥想后要吃袜子。第二个问题是如果你以高速直接向南瓜发射炮弹会发生什么?

作者总结了ChatGPT会产生的一些错误
当给出的问题的前提是有问题的情况下,模型会顺着问题回答。模型会过度反应,避免回答。当给出一个简单的问题时,它有时会说这个问题没有答案,并给出多个可能的答案,即使从上下文来看有一个相当明确的答案。当instruction包含多个明确的约束(例如“列出10部1930年代在法国拍摄的电影”)或当约束对语言模型具有挑战性时(例如用指定数量的句子写摘要),模型的性能会下降。作者怀疑1 的问题是原始数据集prompt里没有类似的。2 的问题是因为标注者更多地奖励模型要谦虚。这两个问题都可用对抗样本解决。
总结
这篇论文将chatGPT的大部分的核心技术细节都进行了讲解。说明了人机对齐的训练方法能够很好引导模型满足人类的偏好。作者也指出利用RLHF训练模型比训练一个更大模型对用户的满足度提升更大且成本更小,相比较于训练一个更大的预训练模型,如何利用现有的大模型来进行更多的研究才是当务之急。
RLHF的训练范式为技术的有效性和局限性提供了一个重要的反馈循环。另外如何把这种训练的范式进行推广,到更多的真实世界任务上去,也是未来研究的一个可以探索的方向。还有就是再进化,这种训练方式的天花板就在human本身,有没有办法突破人类极限,超越人类。这是更让人无限畅想的未来。

AI时代,掌握AI大模型第一手资讯!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
扫码右边公众号,驾驭AI生产力!



