文章主题:人工智能, 机器学习, 边缘计算, 轻量化神经网络技术
大家好,我是LiteAI,一个专注于边缘计算和轻量化神经网络技术的平台。在此,我想与大家分享一篇关于2022年AI与ML发展的重要综述,特别聚焦于顶级会议论文中的度量方法和其影响力。该综述来自于巴西阿雷格里港南里奥格兰德联邦大学的信息学研究所。

文章链接:https://arxiv.org/abs/2205.13131
友情提示,本文篇幅较长(约3.5万字),读者可根据需求浏览。若您认为本文颇具价值,不妨点个赞、关注一下。文章最后,再次向读者推荐之前分享的两篇边缘计算与轻量化神经网络技术的相关文章,这两篇均为优质之作,敬请一读。
论文结构
第1节介绍文章简介。第 2 节介绍了人工智能的简要历史、分析的计算机科学会议的一些背景信息、ACM 的图灵奖以及图论概念的回顾。第 3 节描述了方法,包括有关基础数据集的信息以及在整个工作中使用的图形/图表生成背后的过程。第 4 节介绍并讨论了从不同角度对上述数据的分析。第 5 节总结了我们的工作,并为使用新数据集的未来工作提出了建议。附录带来了一些我们避免包含在论文主体中的表格和图表,以方便阅读。以下为文章详细解读:
摘要
作为一篇关于人工智能发展的文章,本文深入探讨了人工智能如何影响人类生活。通过对研究人员过去几十年来的成果、影响力和领导力进行分析,本文揭示了人工智能和机器学习的发展演变过程。此外,本文还通过研究自1969年第一届国际人工智能联合会议 (IJCAI) 以来在人工智能会议上发表的论文,探索了该领域演变的动态。这一研究为人工智能的历史和发展提供了全新的视角。随着人工智能的发展和演变,研究产出不断增加,这在过去的60年里体现在发表文章数量的增加上。为了进行更深入的分析,我们构建了一个包含全面引文合作和论文作者数据的集,并计算了相应的中心性度量。这些分析有助于我们更好地理解人工智能如何达到目前的学术地位。在整个研究过程中,我们将这些数据集与ACM图灵奖获得者的研究成果以及该领域经历的“两个AI冬天”相联系。同时,我们也关注了自引趋势和新作者的行为。最后,我们提出了一种新方法,用于从组织推断论文所属的国家。综上所述,这项工作通过收集和分析大型技术场所的数据,对人工智能的历史进行了深入的研究,为我们理解和衡量人工智能的发展提供了新的见解。
关键词
作为一篇关于人工智能的文章,本文将深入探讨人工智能的历史、机器学习以及其在各个领域的应用。首先,我们将回顾人工智能的发展历程,从其起源到现代的广泛应用,以期让读者对其有更深入的理解。接着,我们将聚焦于机器学习这一核心部分,分析其在不同行业的具体应用,以及未来的发展趋势。此外,我们也将讨论人工智能在伦理道德方面的挑战,以及如何确保其在发展过程中符合人类的利益。在研究人工智能的影响时,我们将关注其在各个层面的作用,包括对经济、社会、医疗和教育等领域的积极影响,以及可能带来的潜在风险。为了更好地理解和评估人工智能的发展,我们将引入中心性测量的概念,并借助数据分析、图测量等工具,深入剖析人工智能在现实中的应用情况。同时,本文还将关注图灵奖这一重要的奖项,以其为基础,探讨人工智能在科研领域的最新进展和未来趋势。最后,我们将对数据集这一关键概念进行详细解读,以帮助读者更好地理解人工智能在实际操作中的运用。总之,通过对人工智能的历史、机器学习、伦理道德、影响、应用及数据集等方面的全面剖析,我们将更全面地认识这一领域,并为我国人工智能的发展提供有益的建议。
1 简介
人工智能已经渗透到了我们的日常生活中。这个领域的研究起源于学术界,其中最早 defining the trend of machine intelligence 的学者是McCulloch和Pitts[1943], followed by Turing[1950]。接着是该领域的早期组织和发展,从符号方法到连接主义方法,如Feigenbaum和Feldman[1963],Minsky[1961]。然而,人工智能早已不仅仅是一个学术界的课题。它的应用研究产生了众多的产品和技术,甚至大学与行业间的联合研究,如Gomez-Uribe和Hunt[2016]、Ramesh等人[2021],Amini等人[2020],Mahabadi等人[2022]。最近的商业研究显示,人工智能正在组织内部得到广泛应用,至少在一定程度上如此。人工智能的研究已经取得了突破性的进展,吸引了媒体的关注。比如,在1990年代,Deep Blue Campbell等人[2002]成为了第一个在国际象棋锦标赛中战胜当时的世界冠军Garry Kasparov的计算机系统。
在人工智能研究领域,不断取得突破性进展的过程中,各种应用逐渐迈向更高层次。AlphaGo Silver等研究人员在2016年成功赢得了一系列与围棋世界冠军的对弈,这一成果标志着人工智能在棋类领域达到了前所未有的高度。此外,Brown等人在2020年展示了一种新型文本生成的能力,这种技术或在未来像人类一样有效地生成文本。Cobbe等人在2021年提出了一种解决数学单词问题的方法,而Jumper等人在同一年显著地提高了3D蛋白质结构预测的准确性。与此同时,Park等人在2019年成功从分割草图中渲染出看似真实、栩栩如生的图像,这无疑为视觉艺术领域带来了新的可能性。
尽管该领域已经看到了显着的技术影响和进步,但我们认为仍然有必要分析人工智能的历史和演变,以及将其转变为计算机科学中成熟领域所涉及的动态。一些有影响力的研究人员,如Gary Marcus,讨论了近年来该领域的发展 Marcus[2018]。此外,Marcus反思了未来十年的发展趋势 Marcus[2020]。当前的辩论也激发了对整合符号范式和联结主义范式的新方法的研究,从而产生了神经符号人工智能。这种方法旨在实现更强大的AI系统,并赋予其改进的语义理解、认知推理和学习能力 dAvila Garcez和Lamb [2020],Riegel 等人[2020],Besold 等人[2022]。此外,现在比在人工智能的早期阶段更加明显的是,该领域不仅从中汲取灵感——而且还激发了其他领域的进步——包括认知心理学、神经科学、经济学和哲学,参见 Booch 等人[2020]、Marcus 和 Davis [2021]、Smolensky 等人 [2022]。Kautz最近指出,鉴于人工智能最近的贡献,“我们可能处于周期性模式的尽头;尽管进展和繁荣可能会放缓,但有科学和实际理由认为第三个冬天不太可能发生 Kautz [ 2022]” ,证明我们可能不会很快看到另一个AI冬天。人工智能历史部分简要介绍了该领域的演变。
关于方法和贡献的说明
在本文中,我们进一步回顾了人工智能的历史,探索了它的演变,并有助于理解是什么导致了人工智能对我们今天社会产生的影响。为此,我们将调查自 1969 年以来研究人员的协作和引文网络如何在三个主要人工智能会议中演变。我们从 IJCAI、AAAI 和 NeurIPS 以及受 AI 影响的相关研究领域的顶级会议开始我们的分析,即 ACL、EMNLP、NAACL、CVPR、ECCV、ICCV、ICML、KDD、SIGIR 和 WWW。尽管并非所有这些会议早年都发表了许多与人工智能相关的论文,但最近很明显,人工智能技术在这些研究社区中发挥着更加突出的作用。因此,我们将它们添加到我们的分析中,以构成一幅“大图”,即人工智能如何不仅自身成长,而且逐渐开始影响其他领域。这些包括例如计算机视觉、图像处理、自然语言处理和信息检索。
我们继续探索和增强自 1969 年以来在计算机科学和 AI 领域发表的大量论文数据集,即 v11 Arnet数据集 Tang 等人[2008]。我们使用来自该数据集的 v11 版本,其中包含源自 DBLP 的数据,并进一步消除了 1969 年至 2019 年的论文作者身份。Arnet 版本 v12 和 v13的数据可以到2021年。然而,近年来的数据有些在这些最近的数据集中退化,从而导致它们的统计分析不充分且容易出错(请参阅第 3.1 节以了解我们在使用 v11 而不是 v13 时的权衡)。然后,我们使用该数据集创建我们自己的新数据集,以相同数据的几种不同图形表示进行建模,使我们能够以真正的网络方式探索它们。由于已经计算了它们的中心性(评价指标),这些图表可用于未来的研究。生成它们的过程涉及使用相当大的计算能力,在大型研究型大学或公司的实验室之外不容易找到大量的内存和处理。
使用引文和协作网络,我们的分析使用中心性对论文和作者随时间进行排名。然后,我们将这些排名与外部因素相关联,例如会议的本地化或 ACM 的图灵奖——计算机科学领域最负盛名的研究认可。这些数据将使我们能够在这里研究的每个领域/地点,探索什么/谁,曾经/现在是有影响力的论文/作者。此外,我们还将研究所有这些研究在哪里产生的动态,试图了解中国科学产出的最新增长,以及引领前几十年人工智能研究的其他国家。
在这些分析(第 4 节)中,我们试图理解并展示作者如何无法长时间保持其在该领域的影响力。我们还按重要性分析了这种对论文排名的影响,因为论文可以被认为在更长时间内是相关的。我们还表明,在分析的场所中,每篇论文的平均作者数量正在增加,自引次数也在增加。此外,我们还研究了这些作者将大量合著者引入到这些会议。我们还展示了会议之间引用背后的动态,展示了一些会议如何比其他会议更好地协同工作。
由于我们工作的性质——将大量无组织的数据转换为结构化数据格式——除了我们的主要工作之外,我们还生成了一些附带贡献。这些贡献是: (i) 一个新的高效 Python 库,用于将 XML 转换为 JSON,它使用文件流而不是将整个数据加载到内存中; (ii) 一种并行 Python 实现,用于计算图的一些中心性度量,使用机器中可用的所有物理线程,以及 (iii) 一种新颖的结构,以避免在其底层结构是图结构时重新处理已经处理的数据。
2 背景
2.1 人工智能历史简述
人工智能历史通常是根据主要时间段来定义的,在这段时间里,该领域变得越来越强大,中间有两个时期(所谓的 AI Winters),在这两个时期之间,该领域有些名誉扫地、资金不足,并且被认为对现实世界的影响有限。其中的材料并不详尽,但提供了历史背景,以了解此处分析的数据如何与这些时期相关。有几篇工作从不同的角度描述了人工智能历史的各个方面,关于该领域如何随时间演变,参见例如 Kautz[2022]、Russel和Norvig[2020]。
2.1.1 人工智能的黎明(1940-1974)
尽管存在争议,但 20 世纪的一些“现代人工智能”论文发表于 1940 年代。第一篇与人工神经网络相关的论文可以追溯到 1943 年,当时 Warren McCulloch 和 Walter Pitts 正式定义了如何在连接主义设置计算命题逻辑的简单逻辑运算 McCulloch 和 Pitts[1943]。后来,在 1950 年,Alan Turing发表了被广泛引用的“计算机与智能”论文 Turing[1950],这是最早反映智能与机器相互作用以及构建智能机器的可能性的哲学论文之一。在这篇论文中,图灵反映了机器是否能够思考,并提出了“模仿游戏”(现在广为人知的图灵测试)来验证计算机的推理和思考能力。然而,正是在 1956 年,John McCarthy在达特茅斯夏季人工智能研究项目研讨会上创造了人工智能 (AI) 一词。从研讨会开始,AI迅速演变成一个可能改变世界的研究领域——当时,尤其关注符号范式,其受逻辑推理及其计算实现的影响。最早的人工智能文章集之一将发表在 Feigenbaum 和 Feldman[1963] 上。
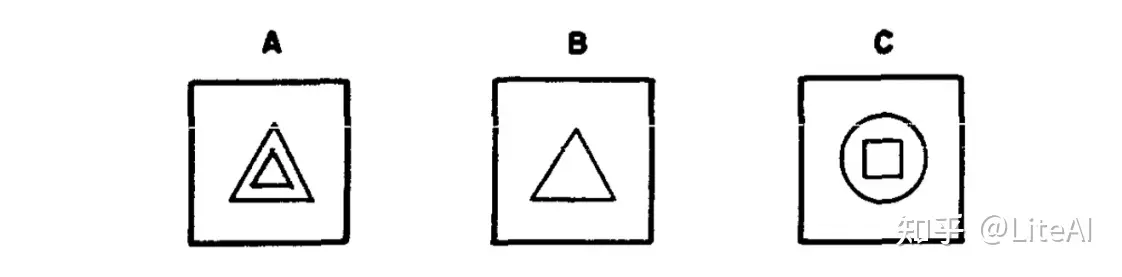
1960 年代基于规则的系统的一个著名例子是 Eliza Weizenbaum[1966],这是有史以来第一个聊天机器人,由麻省理工学院人工智能实验室的 Joseph Wiezenbaum 于 1964 年创建。今天的聊天机器人市场相当大,为 Intercom 或 Drift 等数百万美元的公司提供了收入。 Eliza 被创建为一名自动化的精神病医生,就好像人类正在与了解他们问题的人交谈,尽管该系统以这种基于规则的格式工作,用预先输入的答案回复用户。除了主要的人工智能方法外,我们已经可以看到相关领域如何很容易地受到聊天机器人的影响,显然也涉及自然语言处理。也是在 1964 年,Evans [1964] 表明计算机可以解决他们所描述的“几何类比问题”,这与通常在 IQ 测试中显示的问题相关,人们以这种格式”图A 是数字,B 就像数字,C 是给定答案中的哪一个?”如图 1 所示。
重要的研究也将支持该领域,导致 DARPA(美国国防高级研究计划局)从 1960 年代中期开始资助几个不同的人工智能相关项目,特别是在麻省理工学院。这个时代的特点是该地区从业者的演讲极度乐观。Marvin Minsky在 1970 年代《生活》杂志的采访中说——在获得图灵奖一年后(见第 2.2 节)——“从 3 到 8 年,我们将拥有一台具有人类一般智力的机器”。在同一次采访中,他还声称“如果我们幸运的话,他们可能决定把我们当作宠物。”。1968年,科幻小说完全采用了人工智能乌托邦,1965 年Jean-Luc Godard的法国”Alphaville”和Stanley Kubrick的“2001:太空漫游”(以及Arthur C Clarke的剧本)等著名电影。
然而,在第一个冬天之前,人工智能已经成长为一个相当大的学术社区。第一届人工智能国际联合会议 (IJCAI) 于 1969 年在斯坦福大学举行。在该会议上,在已发表的 63 篇论文中,一些具有影响力的,例如斯坦福大学在“能够产生有趣的感知-运动行为” Feldman等人[1969]、Nilsson[1969] 的 Mobius 自动化工具和 Green [1969] 的 QA3 计算机程序,可以编写其他计算机程序并解决简单机器人的实际问题。
也是在第一个冬天之前,Alain Colmerauer 和 Robert Kowalski 开发了 Prolog,现在是一种著名的编程语言,在 1970 年代和 1980 年代广泛部署 Kowalski [2014],Körner 等人[2022] 也影响了归纳逻辑编程和统计关系学习领域 Raedt 等人[2016]。 Prolog 在其他语言中脱颖而出的特点是它主要是一种声明性语言:程序逻辑用逻辑谓词(关系)表示,表示为事实和规则。通过对这些关系运行查询来启动计算 Lloyd [1984]。最近,Prolog 将成为一种编程语言,也用于 IBM 的问答计算机系统Watson。
2.1.2 第一个人工智能冬天(1974-1980)
第一个 AI 冬天的定义是研究人员和从业者在尝试开发可部署的人工智能技术时发现的障碍。如今,最大的挑战是人工智能算法所需的计算能力不足,而这在当时根本不存在。计算机没有足够的内存来存储构建这些复杂的基于规则的系统所需的大量数据,或者只是没有足够的计算能力来足够快地解决问题。
Minsky 和 Papert [1969] 可能在这个过程中发挥了作用。对“感知器”(被视为二元分类器中使用的学习算法)的批评可能影响了人工智能研究议程,使其更深入地研究神经网络——现在非常有影响力——转而关注符号方法。NP-Completeness 的新结果由 Cook [1971] 和 Karp [1972] 在 1970 年代初期建立的算法也引发怀疑,因为计算复杂性的结果表明,许多问题只能在指数时间内解决。这给人工智能带来了风险,因为这意味着时代模型正在解决的一些基本问题可能永远不会用于现实生活,其中数据不仅仅由几个数据点表示。于1972年发表的著名的 Lighthill 报告 Lighthill [1973] 也发挥了作用,因为它被解释为对人工智能研究的状态及其在过去25 年的部署结果持批评态度。
2.1.3 第一个人工智能夏天:知识、推理和专家系统(1980-1987)
人工智能研究成果的外部认知在 1980 年代初再次缓慢恢复,这主要是由于对专家系统的商业兴趣日益增加。当时,新成立的National Conference on Artificial Intelligence(AAAI)也标志着这一时期。除此之外,在第一个 AI 寒冬中丢失的资金也将重新出现,日本政府资助 AI 研究,作为其第五代计算机项目 (FGCP) 的一部分。其他一些国家也将重启他们的资助项目,比如英国的 Alvey 项目和 DARPA 的战略计算计划。
在 Perceptrons 批评之后,联结主义在 1980 年代初重新流行起来。 Hopfield [1982] 证明了我们今天所说的“Hopfield 网络”可以以不同于以前使用感知器和简单人工神经网络的方式学习。同时,Rumelhart 等人[1986] 和“PDP 研究小组”将展示“反向传播”的潜力,这是一种在(神经)机器学习模型中轻松训练和“反向传播”梯度的新方法。
2.1.4 第二次人工智能寒冬(1987-2000)
然而,对在现实世界应用中部署专家系统的批评可能导致了第二次人工智能寒冬(从 1980 年代末到 2000 年代初),最终导致人工智能研究经费减少。
Hans Moravec 在 Moravec [1988] 中写道:“让计算机在智力测试或下棋时表现出成人水平的表现相对容易,但在感知和移动性方面很难或不可能让计算机具备一岁儿童的技能”。这一点,加上Rodney Brooks和Marvin Minsky的一些贡献,将强调现在被称为Moravec悖论的观点:推理本身不需要太多计算能力,并且可以很容易地被人工智能机器思考/学习,但是建造一台能够做“低于人类良心水平”的智能机器,即运动或“软”技能,实际上需要足够的计算能力,而当时还不存在。
然而,在 1990 年代,在人工智能技术及其影响方面发生了很多事情。 IBM 的成功,由Campbell 等人[2002]提出,即深蓝最伟大的成就——最终在 1997 年的锦标赛规则下击败了当时的世界国际象棋冠军Garry Kasparov。此前,在 1994 年,Tesauro [1994] TD-GAMMON 程序将通过创建一个自学的五子棋程序,能够以大师级的水平玩它。此外,尽管自动驾驶汽车通常被认为是最近的技术,但它的基础是在这个时代奠定的,Ernst Dickmmans 在 Dickmanns [1988] 和 Thomanek 和 Dickmanns [1995] 中的“动态视觉”概念,载人汽车以最高 130 公里/小时的速度在正常交通的巴黎 3 车道高速公路上行驶。
1990 年代后期,随着万维网的蓬勃发展,信息检索的研究也将有所增加,包括对网络和基于人工智能的信息检索/提取工具的研究 Freitag [2000]。
2.1.5 21 世纪的最新进展(2000 年至今)
2000 年代向我们展示了对 AI 的更广泛的公众认可,尤其是当我们看到机器学习 (ML),特别是深度学习 (DL) 的商业影响时。在这种情况下,NeurIPS(当时称为 NIPS)再次成为最杰出的 AI 会议,其中发表了几篇有影响力的深度学习论文,其中包括卷积神经网络、图神经网络、对抗性网络和其他(深度)连接主义架构。
在 2000 年代初期,我们将看到 AI 在大多数发达国家中触及更广泛的客户群。 iRobot于 2002 年推出了 Roomba 扫地机器人。苹果、谷歌、亚马逊、微软和三星分别发布了 Siri、谷歌助手、Alexa、Cortana 和 Bixby,这些基于人工智能的个人助理能够更好地理解自然语言并执行更广泛的操作的任务。诚然,大约在 2010 年,它们一开始并没有那么好用,但这些技术在过去十年中得到了改进。
自 2000 年以来,该领域的大部分知名度都与深度学习有关,它基于人工神经网络 (ANN) 概念,该系统试图模仿我们的脑细胞如何工作。有趣的是,早在 1943 年,在 McCulloch 和 Pitts [1943] 中,努力定义人工神经网络。 然而,我们现在拥有的巨大计算能力允许我们一个接一个地堆叠几层“神经元”——因此是“深度”神经网络——和计算结果非常快。此外,鉴于该过程的自然并行性,图形处理单元 (GPU) 的出现创造了必要的硬件,导致深度模型及其应用程序的数量不断增加。
最近一些最引人注目的成就基于生成对抗网络 (GAN)。它们是“通过对抗过程估计生成模型的框架,我们在其中同时训练两个模型:捕获数据分布的生成模型 G 和估计样本来自训练的数据而不是G的概率的判别模型 D” Goodfellow 等人[2014]。该框架在 https://this-person-does-not-exist.com/en、https://thiscatdoesnotexist.com/、http://thiscitydoesnotexist.com/ 等网站生成一波逼真的程序生成内容,或递归 https://thisaidoesnotexist.com/。
GAN 与俗称的“deepfakes”相关联——“深度学习”与“fake”的混合体。他们通过机器学习模型将一张脸与另一张脸叠加在一起。最近的一些深度伪造也可以改变对象的声音,改善体验。当人们想象这些可以用来伪造有影响力的人 Hwang [2020] 的音频和图像时,从道德的角度来看,这些尤其糟糕。可以找到对该领域的一些review Nguyen 等人[2019]。
几位研究人员最近因与人工智能、(概率)推理、因果关系、机器学习和深度学习相关的工作而获得了 ACM 图灵奖。 2010 年,Leslie Valiant 因其可追溯到 80 年代和 90 年代的基础文章而获奖,他与人工智能和机器学习相关的一些最杰出的作品在计算学习理论(特别是 PAC 学习)中定义了基础概念 Valiant [1984 ]。 Judea Pearl 在第二年,即 2011 年赢得了该奖项,表彰他“通过开发概率和因果推理的微积分做出的贡献”,在 Pearl [1988] 和 Pearl [2009] 中展示了其贡献。深度学习先驱在 2018 年获得认可:Geoffrey Hinton、Yoshua Bengio 和 Yann LeCun 因其在深度(信念)网络方面的工作而获得广泛认可 Hinton等人[2006],图像识别 Krizhevsky 等人[2012],文本识别和卷积神经网络 Lecun 等人[1998],LeCun 等人[1989],GANs Goodfellow 等人[2014] 和神经翻译 Bahdanau 等人[2014]。然而,必须认识到,早在 1980 年代,PDP 研究小组在通过反向传播展示神经学习的有效性方面发挥了关键作用 Rumelhart[1985]。
至于媒体报道的深度学习的影响,特别是在不断发展的娱乐和游戏行业,谷歌的 AlphaGo 在 2017年与中国围棋大师柯洁的一系列比赛中获胜,此前已经赢得了 5 场比赛中的 4 场。同样在 2017 年,OpenAI 的 Dota 2 bot赢得了一场与乌克兰职业选手 Dendi 的 1v1 示范赛,这是一场在信息不完善、未来状态几乎无限的游戏中的明显实力展示。后来,在 2019 年,同一个机器人的新版本 OpenAI Five 在与当时的世界冠军 Dota 团队 OG 的背靠背 5v5 比赛中获胜。同样在 2019 年,DeepMind 的 AlphaStar 机器人达到了星际争霸 II 中最高的级别。
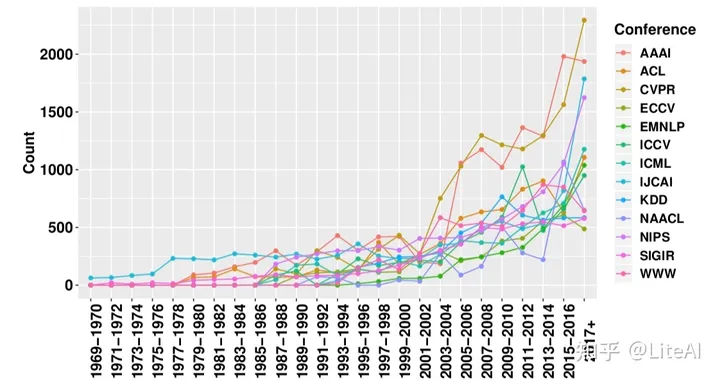
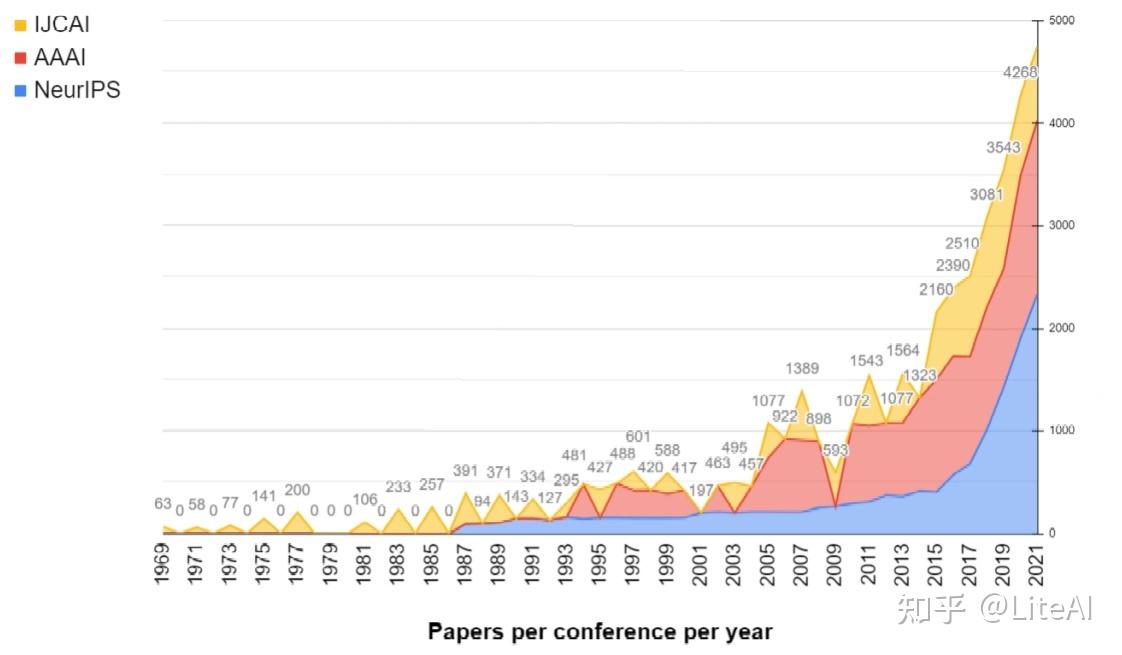
近年来,人工智能研究取得显着增长的另一个迹象是,在三大人工智能相关领域提交(和发表)的论文数量不断增加。图 6 显示,近年来我们在这些会议上发表了 1500 多篇论文。有关确切数字,请查看表 8。通过查看该图,同样重要的是,要注意计算机视觉如何成为相关领域中最引人注目的领域,其中 CVPR 的论文数量最多,这要归功于图像识别和自动驾驶汽车的应用。我们在第 4 节中提供了与 AI 相关的出版物的更多细节。
2.1.6 超越深度学习:最近关于鲁棒和神经符号人工智能的争论
人工智能的影响超越了深度学习所取得的成果。最近,AI 社区见证了一场关于如何构建可解释、可描述、合乎道德和值得信赖的技术的辩论 Rossi 和 Mattei [2019]。这些导致对其他领域的关注增加,这些领域导致构建鲁棒的人工智能技术的挑战。特别是,以原则性的方式结合学习和推理的研究,例如神经符号 AI 和混合模型,已经成为学术界和工业界日益增长的研究兴趣的主题 dAvila Garcez 等人[2009]、Marcus [2020]、Riegel 等人[2020],Besold 等人[2022]。此外,在最近的 ACM 通讯文章 Hochreiter [2022] 中,Sepp Hochreiter – 深度学习先驱和长期短期记忆 (LSTM) 的支持者,这是部署最广泛的深度学习模型之一 – 反映了更广泛的人工智能“是一个复杂且适应性强的系统,它凭借其感官知觉、先前的经验和习得的技能成功地执行任何认知任务。” Hochreiter 指出,图神经网络 (GNN) 可以在构建神经符号 AI 技术中发挥关键作用:“GNN 是一个非常有前途的研究方向,因为它们在图结构上运行,其中节点和边与标签和特征相关联。GNN 是主要的神经符号计算模型” Lamb等人[2020]。此外,Hochreiter 辩称,“最有希望的广义 AI 方法是神经符号 AI,即结合符号 AI 和亚符号 AI 方法的双边 AI”Hochreiter [2022]。他还指出,对神经符号 AI 的贡献可能来自欧洲,欧洲“在符号和亚符号 AI 方面拥有强大的研究小组,因此有前所未有的机会为下一个 AI 水平——广泛的 AI 做出根本性贡献”Hochreiter [2022]。尽管 AI 研究人员和专业人士还有很多工作要做并展示出来,但很明显,该领域在过去几十年中已经发展壮大。此外,AI 影响的见证是 AI 伦理、政策和法规领域的突出和增长,以及几个领先的研究机构进行的年度 AI 全球影响分析 Mishra[2020],张等人[2021]。
2.2 美国计算机协会 Alan M. Turing 奖
年度 ACM A.M.图灵奖被认为是计算机科学中最重要的认可。它由计算机协会 (ACM) 授予对计算机科学做出杰出和持久贡献的人们。
该奖项于 1966 年推出,以英国数学家和计算机科学先驱 Alan M. Turing 的名字命名。图灵影响了几个不同的科学分支,通过有影响力的出版物 Turing [1936] 形式化了导致通用计算机(今天的“图灵机”)概念的计算概念。在设计了图灵测试以确定机器是否“智能”之后,图灵也被大多数人视为现代人工智能先驱。他还因在第二次世界大战中的工作而闻名,帮助英国人用他的 Bombe 机器对纳粹德国 Enigma 机器进行解码,该机器以波兰 bomba kryptologiczna 解码机命名。自 2014 年以来,获奖者将获得 100 万美元,由 Google CACM [2014] 资助,以表彰他们的杰出成就。
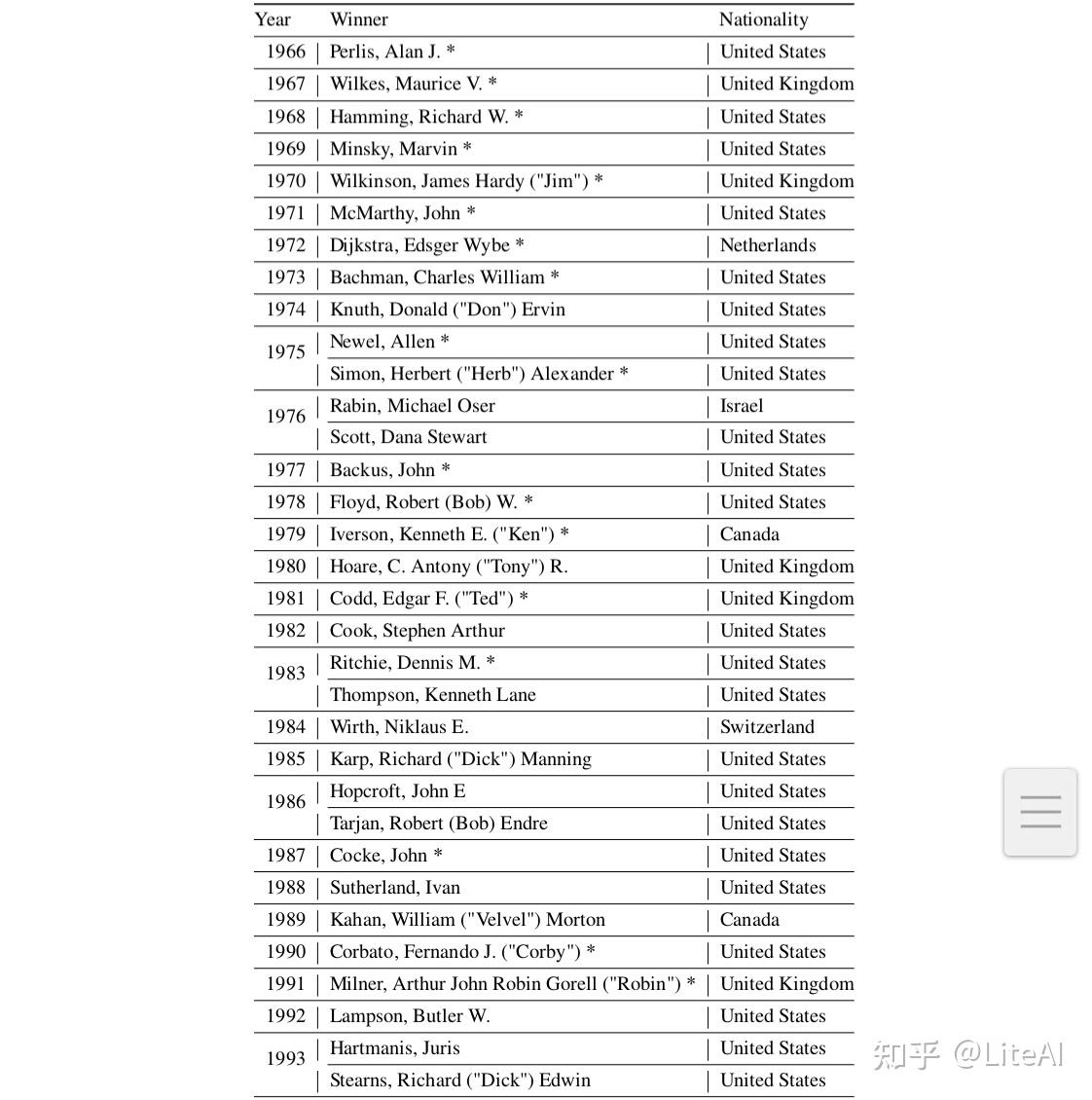
该奖项已授予计算机科学研究不同领域的 62 名研究人员。 37%的获奖者不是在美国出生(有些出生地没有在表格中列出)——只有 27%的获奖者将美国以外的国家列为他们做出主要贡献的国家。第一位获得该奖项的女性 Frances “Fran” Allen 仅在 2006 年因其在优化编译器技术的理论和实践方面的工作而获奖。
对于我们的 AI 进化分析,相关的图灵奖获得者是那些对该领域做出重要贡献的人。自 1966 年以来,图灵奖已经表彰了七位研究人员对人工智能的贡献。以下信息由 ACM https://amturing.acm.org/byyear.cfm 提供:
• Marvin Minsky (1969):表彰他在创造、塑造、促进和推进人工智能领域的核心作用;
• John McCarthy (1971):麦卡锡博士的讲座“人工智能研究的现状”涵盖了他的工作已获得相当认可的领域;
• Herbert Simon 和 Allen Newell(1975 年):在长达 20 年的联合科学努力中,他们最初与兰德公司的 J. C. Shaw 合作,随后与卡内基梅隆大学的众多教职员工和学生同事合作,为人工智能、人类认知心理学和列表处理做出重要贡献;
• Edward Feigenbaum 和 Raj Reddy(1994 年):开创了大规模人工智能系统的设计和构建,展示了人工智能技术的实际重要性和潜在的商业影响;
• Leslie Valiant (2010):对计算理论的变革性贡献,包括可能近似正确 (PAC) 学习理论、枚举和代数计算的复杂性,以及并行和分布式计算理论;
• Judea Pearl(2011 年):通过开发用于概率和因果推理的微积分对人工智能做出根本性贡献;
• Geoffrey Hinton、Yann LeCun 和 Yoshua Bengio(2018 年):用于使深度神经网络成为计算的关键组成部分的概念和工程突破。
2.3 计算机科学与人工智能会议
今天,有成千上万的计算机科学会议。在我们的分析中,我们显然必须将它们缩小到被认为是顶级会议,以便正确分析其核心。 CSRankings 是一个基于指标的顶级计算机科学研究机构排名,它确定了每个机构在每个领域的工作。它们包括一小部分被认为是计算子领域中顶级会议的会议:在这项工作中,我们将只关注 CSRankings“AI”类别中可用的机构,这些机构将在下面简要描述。一些会议是从同名科学协会(如 AAAI)借用的首字母缩略词。
2.3.1 IJCAI
国际人工智能联合会议(IJCAI)于 1969 年首次在加利福尼亚州召开,是第一个与人工智能相关的综合性会议。该会议在奇数年举行,但自 2016 年以来每年举行一次。它已经在 15 个不同的国家/地区举行,而 COVID19 大流行的 2 年是在日本和加拿大远程举行。下一届会议将在奥地利(2022 年)、南非(2023 年)和中国(2024 年)举行,将主办会议的国家数量增加到 17 个——中国之前已经主办过。与 AAAI 类似,IJCAI 是一个综合性的 AI 会议,其中一些出版物从 AI 哲学到符号 AI,以及机器学习和应用。 IJCAI 多年来发表了图灵奖获得者的重要论文,例如Avin等人[2005]、Feigenbaum [1977]、McCarthy [1977]、Valiant [1985]、Verma 等人 [2019]。
2.3.2 AAAI
人工智能促进协会(AAAI – 发音为“Triple AI”)成立于 1979 年,前身是美国人工智能协会。自 1980 年以来,该协会负责推动一些著名的人工智能会议,包括 AAAI 人工智能会议(前身为全国人工智能会议)。该会议过去每隔一两年举行一次(取决于是否在北美组织 IJCAI)。 AAAI 从 2010 年开始每年举行一次。值得注意的是,虽然会议更名了,但实际上只在北美举行(由于 COVID19 大流行,2021 年远程举行)。该会议作为其姊妹会议 IJCAI 全面涵盖了 AI。与 IJCAI 类似,AAAI 发表了几篇来自有影响力的研究人员和图灵奖获得者的论文,参见例如Hinton [2000],de Mori 等人 [1988]、Pearl[1982]、Valiant [2006]。
2.3.3 NeurIPS(以前称为 NIPS)
神经信息处理系统会议和研讨会 (NeurIPS) 是自 1987 年以来每年 12 月举行的机器学习和计算神经科学会议。它已在美国、加拿大和西班牙举行。 NeurIPS 多年来发表了数百篇有影响力的论文,涉及多种学习模型和架构,从 Long Short-Term Memories Hochreiter 和 Schmidhuber [1996] 到 Transformer 架构 Vaswani 等人[2017]。会议委员会决定在 2018 年将会议名称更改为 NeurIPS。
CSRankings 将其定义为“机器学习和数据挖掘”会议,发表重要论文,最近采用如 GPT-3的技术 Brown等人[2020] 和 PyTorch 的技术论文 Paszke 等人[2019],分别有 31 位和 21 位作者。会场的规模之大令人瞩目,2021 年接受了 2334 篇论文,超过了这项工作中研究的所有其他会议。 “近年来最有影响力的论文”片段,归功于 https://www.paperdigest.org/。
2.3.4 CVPR
计算机视觉和模式识别会议(CVPR)是计算机视觉和模式识别的年度会议,被认为是该领域最重要的会议之一,2019 年有 1294 篇被接受的论文。它将在 2023 年首次在美国以外的加拿大温哥华举办。它于 1983 年首次举办,自 1985 年起由 IEEE 赞助,自 2012 年起由计算机视觉基金会赞助,负责提供对会议上发表的每篇论文的开放访问。 CVPR 是计算机视觉的顶级会议,过去见证了开创性的工作,包括 Siamese Representation Learning Chen and He [2020]、GANs Karras 等人[2018] 和双注意网络 Fu 等人[2018]。图灵奖获得者 Yann LeCun 曾多次在该会议上发表文章,例如Boureau等人[2010],LeCun 等人[2004]。
2.3.5 ECCV
ECCV 代表欧洲计算机视觉会议,是 CVPR 的欧洲分支机构——尽管 ECCV 2022 将在以色列特拉维夫举行。自 1990 年在法国昂蒂布举行以来,它每两年在偶数年举行一次。尽管它被认为是 CVPR 的小妹妹,但它在 2019 年有 1360 篇被接受的论文,还主要关注计算机视觉,并发表了一些著名的出版物,例如 RAFT Teed 和 Deng [2020],该模型能够以高精度分割和预测图像深度.
2.3.6 ICCV
与 ECCV 类似,计算机视觉国际会议是 CVPR 的国际分支机构,自 1987 年在英国伦敦举行以来,每奇数年举行一次,此后在其他 14 个国家举行。 2019 年有 1077 篇论文入选,例如 Shaham 等人[2019] 获得2019年度最佳论文奖。
2.3.7 ACL
ACL 是计算语言学协会自 2002 年以来每年举行的会议,在过去的 20 年中令人惊讶地在 15 个不同的国家举行。该网站宣布 ACL 为“致力于研究涉及人类语言的计算问题的人们的首要国际科学和专业协会,该领域通常被称为计算语言学或自然语言处理 (NLP)。该协会成立于 1962 年,原名为机器翻译与计算语言学协会(AMTCL),1968 年更名为 ACL。”通常被称为 NLP 相关会议,它有一些近年来被高度引用的工作,例如 Strubell 等[2019] 在研究创建大型语言模型的环境影响方面的工作。
2.3.8 NAACL
NAACL 是由计算语言学协会北美分会举办的会议,因此也被称为 NLP 会议。该会议实际上被命名为 NAACL-HLT(或 HLT-NAACL)——计算语言学协会北美分会:人类语言技术。它自 2003 年开始举办,在 ACL 发生在北美的场合与 ACL 共同举办。 BERT 模型 Devlin 等人[2018]发表了近年来最常被引用的关于Transformer使用的论文之一。
2.3.9 EMNLP
EMNLP 代表自然语言处理中的经验方法。该会议于 1996 年在美国开始,基于早期的会议系列,称为超大型语料库 (WVLC) 研讨会,从那时起每年举行一次。最近的会议以试图改进 BERT 模型 Devlin 等人[2018]的工作为标志。例如 Jiao 等人 [2019],Feng等人[2020] 和 Beltagy 等人 [2019]。
2.3.10 ICML
ICML 是国际机器学习会议,是专注于机器学习的领先国际学术会议。该会议自 1987 年以来每年举行一次,第一次会议于 1980 年在美国匹兹堡举行。第一次会议都在美国举行,但第 9 次会议于 1992 年在苏格兰阿伯丁举行。从那时起,它已在其他 10 个国家/地区举行,实际上由于 COVID-19 大流行而远程举办了两次。它包含 Pascanu 等人在机器学习方面的一些开创性论文。和 Ioffe 和 Szegedy,以及最近的一些优秀研究,如 Zhang 等人[2018]和Chen等人[2020]。除了 Bengio 的上述开创性论文,图灵奖获得者 Geoffrey Hinton 还在 ICML 上发表了重要论文,例如Nair和Hinton[2010]。
2.3.11 KDD
SIGKDD 知识发现和数据挖掘会议是由 ACM 主办的年度会议,该会议于 1989 年在底特律举行了第一次会议。虽然它通常在美国举行,但它已经由其他几个国家主办,即加拿大、中国、法国和英国。这是涵盖知识发现和数据挖掘领域的最重要会议,2021 年有 394 篇被接受的论文:如果与我们在本文中调查的其他会议相比,这个数字会更少。近年来,会议见证了人工智能相关研究的显著存在,主要由图神经网络 (GNN) 定义,其中包括 Qiu 等人、Wu 等人、Jin 等人和 Liu 等人的工作,在 2020 年的 SIGKDD 中被接受。有趣的是,在 2020 年的会议上,这些有影响力的论文的作者中有很多来自中国,也许是一种趋势——请参阅第 4.6 节中有关它的一些见解。
2.3.12 SIGIR
SIGIR 代表信息检索特别兴趣小组,一个 ACM 小组。它有自己的年度会议,始于 1978 年,从那时起每年都举行一次。它被认为是信息检索(如何从原始、无组织和非结构化数据中获取有用和有组织的信息)领域最重要的会议。经过 43 个版本,它已在 21 个不同的国家举办。它曾经在美国和另一个国家之间交替,但这条规则不再适用,过去 8 年在美国只有一次会议。近年来的许多论文都涉及推荐系统,例如 He 等人、Wu 等人和 Wang 等人。
2.3.13 万维网
网络会议(WWW)是该领域的顶级会议。它“将主要研究人员、创新者、决策者、技术人员、企业和标准机构聚集在一起,致力于塑造网络”。这是 1994 年在瑞士日内瓦的 CERN 开始的年度活动。会议重点关注语义网络和数据挖掘,并在推荐系统方面取得了一些重要成果。
2.4 图和中心性度量简介
接下来,我们简要介绍一下本文使用的图论概念。 2.4.2 到 2.4.5 节描述了文献中使用最广泛的图中心性。然后在第 2.4.6 节中,为了完整起见,我们将讨论其他一些中心性度量。
图 G 由元组 G=(V, E) 表示,其中 V 是一组节点(顶点),E 是一组边 e_{u,v} 连接节点 u 到 v,其中 u,v ∈ V。这些边可以是有向的或是无向的——从而使我们能够区分有向图和无向图。在 e_{u,v} 的有向情况下,我们称 u 为源节点,v 为目的节点。我们总是用 n 来表示图中的节点数,用 m 来表示图中的边数。此外,一对节点 (u, v) 可能有多个连接它们的边:在这种情况下,我们将图称为多重图。类似地,这些边可能具有权重 w,使图成为加权图。此外,我们还可以有标记图,其中节点和边可以是不同的类型。这些在知识表示系统中很有用,例如第 3.3.4 节中构建的图。如果 \exists e_{u_i, u_{i+1}} \leq i \leq p-1,我们称 p=u_1,u_2,…,u_p为图G 中 u_1 和 u_p 之间的路径。基本上,如果我们可以从节点 u_1 通过一系列连接的边到 u_p 。我们还可以将一对节点 (u, v) 之间的最短路径定义为具有最小可能中间节点数量的路径,但需要注意的是,我们可以在任何一对节点 (u, v) 之间拥有多个最短路径。
2.4.1 中心性度量
对图中心性度量的兴趣可以追溯到 1940 年代,但在 1970 年代 Freeman [1978] 中它被更正式地纳入图论。研究中心性的一个基本动机是信念(或相关性)网络中的节点位置(可以代表一个人的位置)会影响他们对信息、地位、权力、声望和影响的访问 Grando等人[2019],万等人[2021]。因此,在整个工作中,当我们想要识别上述概念时,我们将为我们构建的不同网络使用图中心性。Grando等人提供对有兴趣将机器学习应用于该领域的人的教程和综述。
2.4.2 角度中心度
我们将节点 u 的度数表示为 k_u ,表示连接到该节点的其他节点的数量。在有向图中,我们可以进一步将此度量分为两部分: k_u^{in} 是入度,代表节点 v ∈ V 的数量,满足包含边 e_{v,u},其中 v 为源,u 为目标(即边指向 u 的节点数);相反的度量 k_u^{out} 是出度,表示具有边e_{u,v}的节点 v ∈ V 的数量。因此,可以将此度量扩展到称为角度中心度的度量,定义为:

其中 n 表示图 G 中节点 V 的数量。
此外,与我们有入度和出度度量的方式相同,我们可以扩展等式 1 并分别定义入度中心度和出度中心度:

这些角度度量用于识别节点与其他节点的直接连接程度,而不考虑节点可以传递给其邻居的影响。
2.4.3 介数(Betweenness)中心度
介数中心度在 Freeman [1977] 中定义,其衡量节点 u 重要性的方法是图中有多少条最短路径经过 u。它被定义为

其中 \partial_{s,t}(u) 是 s 和 t 之间经过 u 的最短路径的数量,\partial_{s,t} 只是 s 和 t 之间的最短路径的数量。请注意,如果 (s, t) 之间存在路径,我们只会计算 (s, t) 对之间的路径。
介数与连通性的概念有关,其中具有较大介数的节点实际上意味着它是几个节点之间的连接点。在具有单个连接组件的图中,如果节点充当两个单独断开组件之间的桥梁,则它可以具有最高的介数。它被认为是衡量节点对通信流 的控制度量 Freeman [1978]。
2.4.4 接近中心度
接近中心度是在 Sabidussi [1966] 中创建的,表示一个节点与图中每个其他节点的接近度。它是距离的倒数,而距离又是与所有其他节点 的距离之和 Saxena 和 Iyengar [2020] 。它定义为
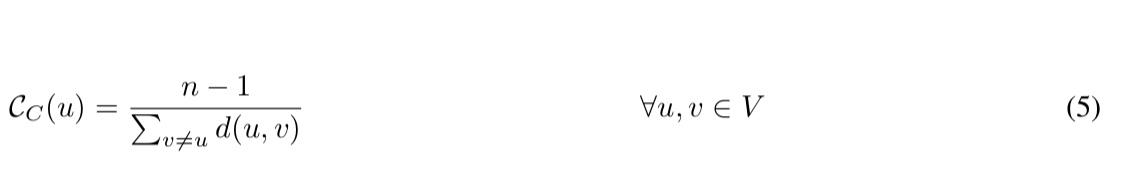
其中 d(u, v) 是节点 u 和 v 之间的距离。如果图未加权,该距离就是对 (u, v) 之间的最短路径 p 中的边数,而它是路径中的每条边,以防图形未加权。由于在断开连接的图(不是每个节点都可以从另一个节点到达的图)中的每对节点之间没有定义距离,我们无法计算断开连接图的接近度。接近度较高的节点表明该节点处于其他节点的中心。这也意味着具有大接近度值的节点平均“更接近”其他节点。它代表节点的通信独立程度 Freeman [1978], Cardente [2012]。
2.4.5 PageRank 中心度
Pagerank 是一种全局中心性度量,需要整个网络来衡量一个节点的重要性。它根据其邻居的重要性来衡量一个节点的重要性 Saxena 和lyengar [2020]。它是由 Brin 和 Page 在创建 Google 时开发的,是他们搜索引擎背后的底层方法。要了解 Pagerank,我们需要了解它的主要思想,是了解网页在万维网上所有其他数百万页面中的重要性。它背后的主要思想是,如果其他重要的网页链接到它,我们正在考虑一个重要的网页。
想象一下,就好像我们有一个网络爬虫随机浏览网络并在每次我们进入特定页面时增加一个计数器。然后,当您在一个页面上时,您可以选择单击页面上的一个链接,或者以 0<=q<=1 的概率转到 Web 上的随机页面——这对于建模real-life有帮助,我们只是随机访问网站,也可以在没有任何外部链接的情况下建模页面。 q 的通常值,也称为隐形传态或阻尼因子,为 0.15,如原始论文中所定义。因此,考虑到这一点,我们可以将 Pagerank 定义为

上面的等式说明了这个过程是如何迭代的,因为我们依赖每个邻居的 Pagerank 来计算我们自己的 Pagerank。该过程通常会收敛或可以在一定次数的迭代后停止。
2.4.6 其他中心度
文献中还有其他有用的中心度量。我们的工作中没有使用它们,但理想情况下,它们将在使用创建的数据集的未来工作中使用。最近的工作不仅集中在机器学习在学习复杂图的中心性度量中的应用 Grando 等人[2019],还分析了图神经网络自身的应用,该网络能够进行多任务学习,并针对估计网络中心性度量的关系问题进行训练,Avelar 等人[2019]。总之,对中心性度量感兴趣的读者可以参考 Grando 等人[2019]、Saxena 和lyengar [2020]。
• 半局部中心度: Chen 等人[2012] 定义了一个类似于角度中心性的度量,我们将其扩展到 2 个邻居级别。
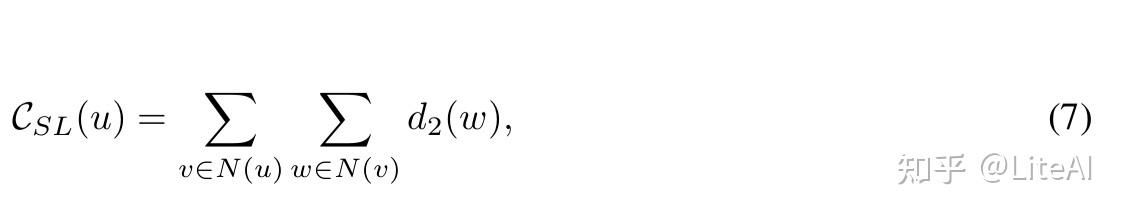
其中 d_2(w) 是邻居的数量加上 w 的每个邻居的邻居数量——基本上你可以分两步到达所有节点。
• 体积中心度: Wehmuth 和 Ziviani [2013] 是上述中心性度量参数化节点影响可以达到多远的一种概括,定义为

其中 N_h(u) 是 u 距离 h 内的邻居集合,并且 N \tilde{N}_h(u)=N_h(u)\cup \left\{ u \right\} 。Wehmuth和Ziviani [2013] 证明 h = 2 可以很好地权衡识别具有重要关系的节点和计算该关系的成本。
• H-index: Hirsch [2005] 是研究界众所周知的统计数据,在大多数研究聚合门户网站(如 Google Scholar 和 DBLP)中都被展示为统计数据。 Hirsch [2005] 定义 h 是作者有 h 篇论文至少被引用h次的最大整数值。
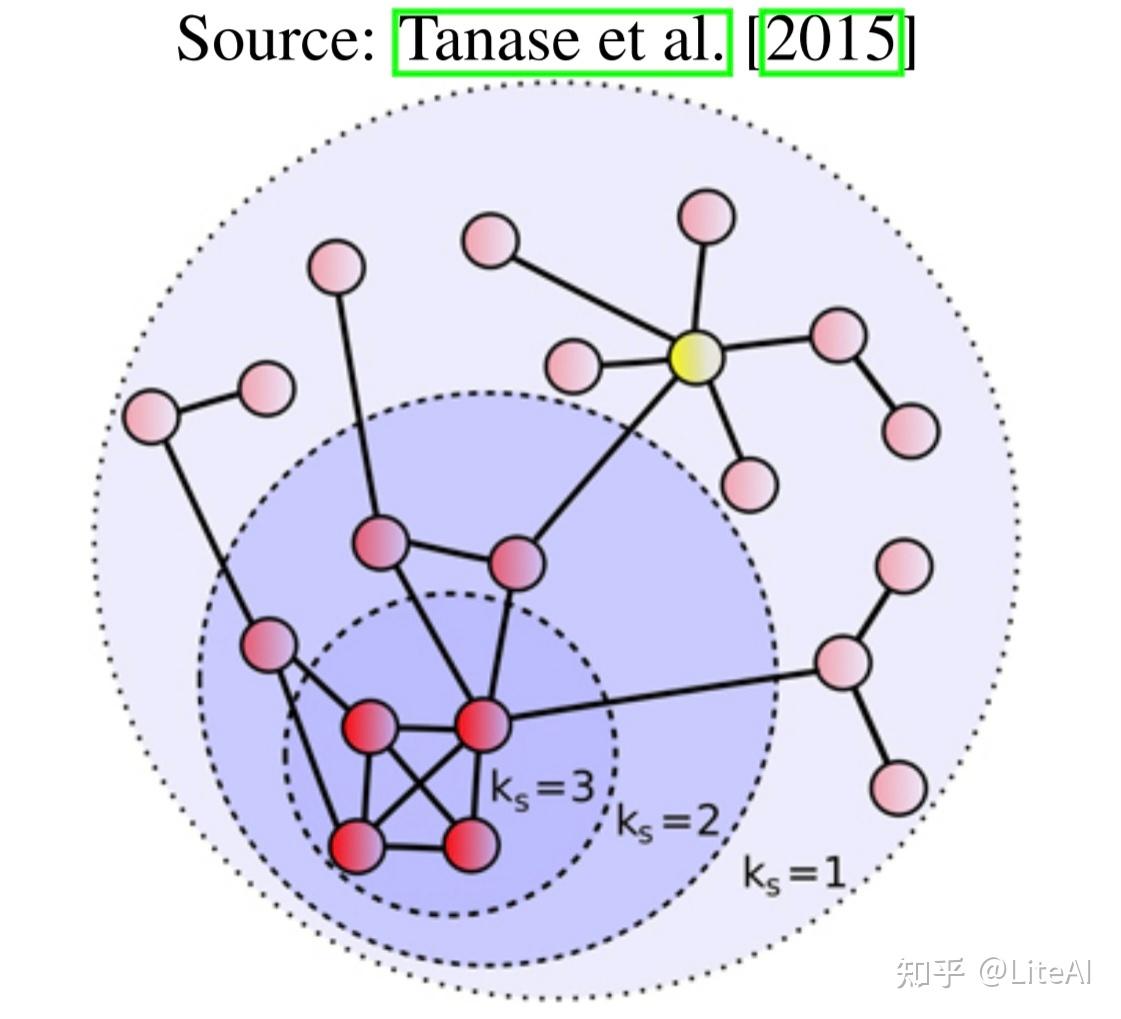
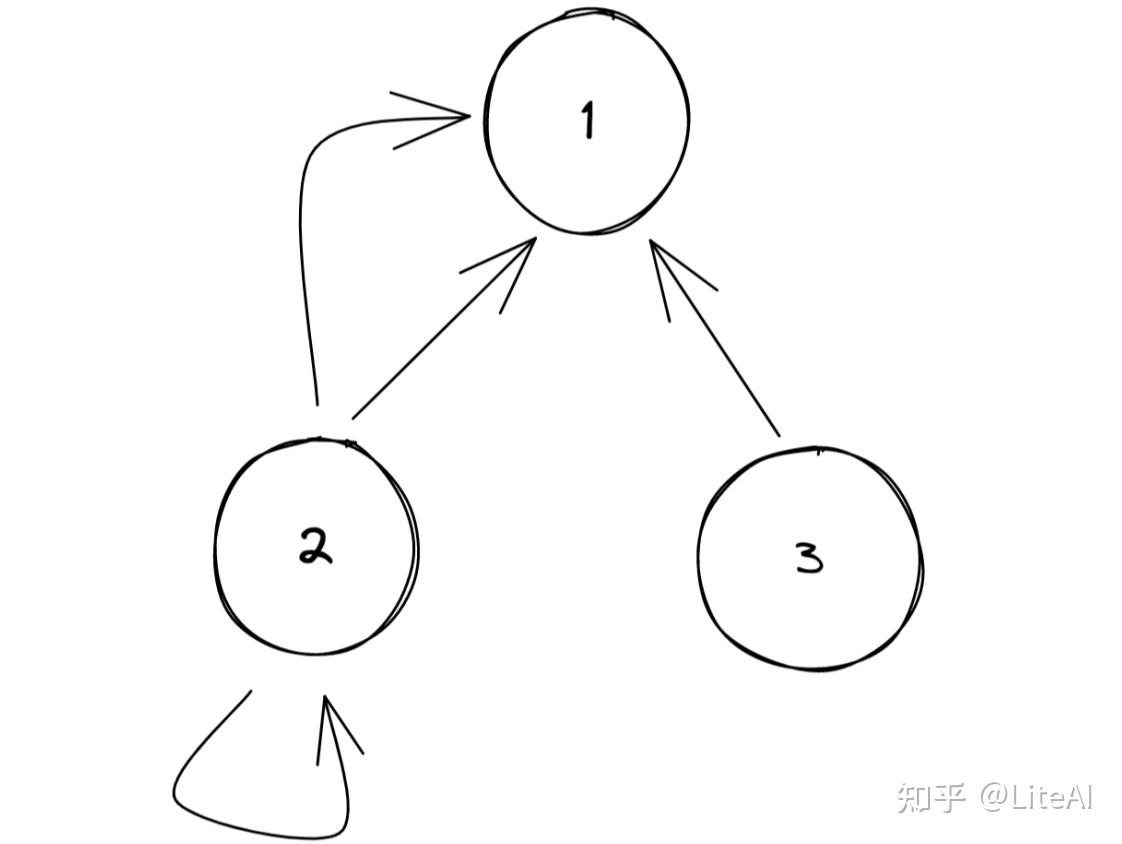
• 核心中心度: Kitsak 等人[2010] 发表了重要节点位于图的核心的想法。它可以通过为每个节点分配从 k-shell 分解导出的索引(或正整数)值的过程来确定。分解和分配过程如下: 依次从网络中移除度数 k=1 的节点,直到所有剩余节点的度数严格大于 1。此阶段所有移除的节点都被分配为网络的 kshell 的一部分索引 k_S=1 或 1-shell。这随着 k 的增加而重复,将每个节点分配给不同的 k-shells Wan 等人[2021]。请参见图 2 以查看 k-shell 定义的示例。然后,我们可以在数学上将这种中心性度量定义为
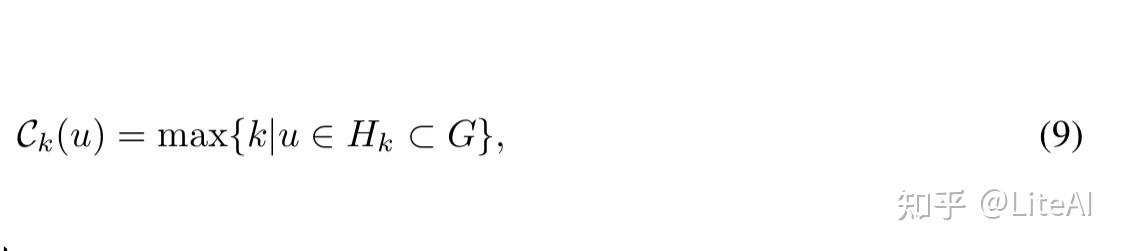
其中 H_k 是 G 的最大子图,所有节点的度数至少为 k HWan 等人[2021]。
一些更复杂的中心性度量主要使用这样一个事实,即我们可以通过其邻接矩阵 A 及其对应的特征值和特征向量来定义图。由于我们没有进行全面review或使用它们,我们不会描述它们。
2.5 相关工作
推动这项工作的主要原因之一是人工智能的历史及其动态演化尚未得到深入研究,至少就我们的方法而言:Xu等人[2019] 专门关注“可解释的人工智能”进化(在本例中为去进化); Oke [2008] 确实深化了他们在几个不同的 AI 领域的工作,并对每个领域进行了回顾,但历史不会超过 1990 年代中期。也有类似的方法来调查作者引文/合作网络,例如 Ding 等人[2010],Guns等人[2011],Abbasi等人[2012] 和Wu等人[2019],主要关注介数中心度。Wartburg等人[2005] 使用紧密度来分析专利网络。此外,Krebs [2002] 展示了如何使用中心性度量来识别 2001 年双子塔的恐怖袭击者网络中的主要参与者。
关于作者在论文中的国家隶属关系,Grubbs 等人[2019] 研究了由美国国立卫生研究院资助的健康研究的合著者国家隶属关系; Michalska-Smith 等人[2014] 进一步尝试将所属国家与期刊和会议的接受率相关联;Yu等人[2021] 研究了如何从 WoS 中的数据推断论文所属国家;Hottenrott等人[2019] 还研究了文章中多国从属关系的增加。
3 方法论
3.1 基础数据集
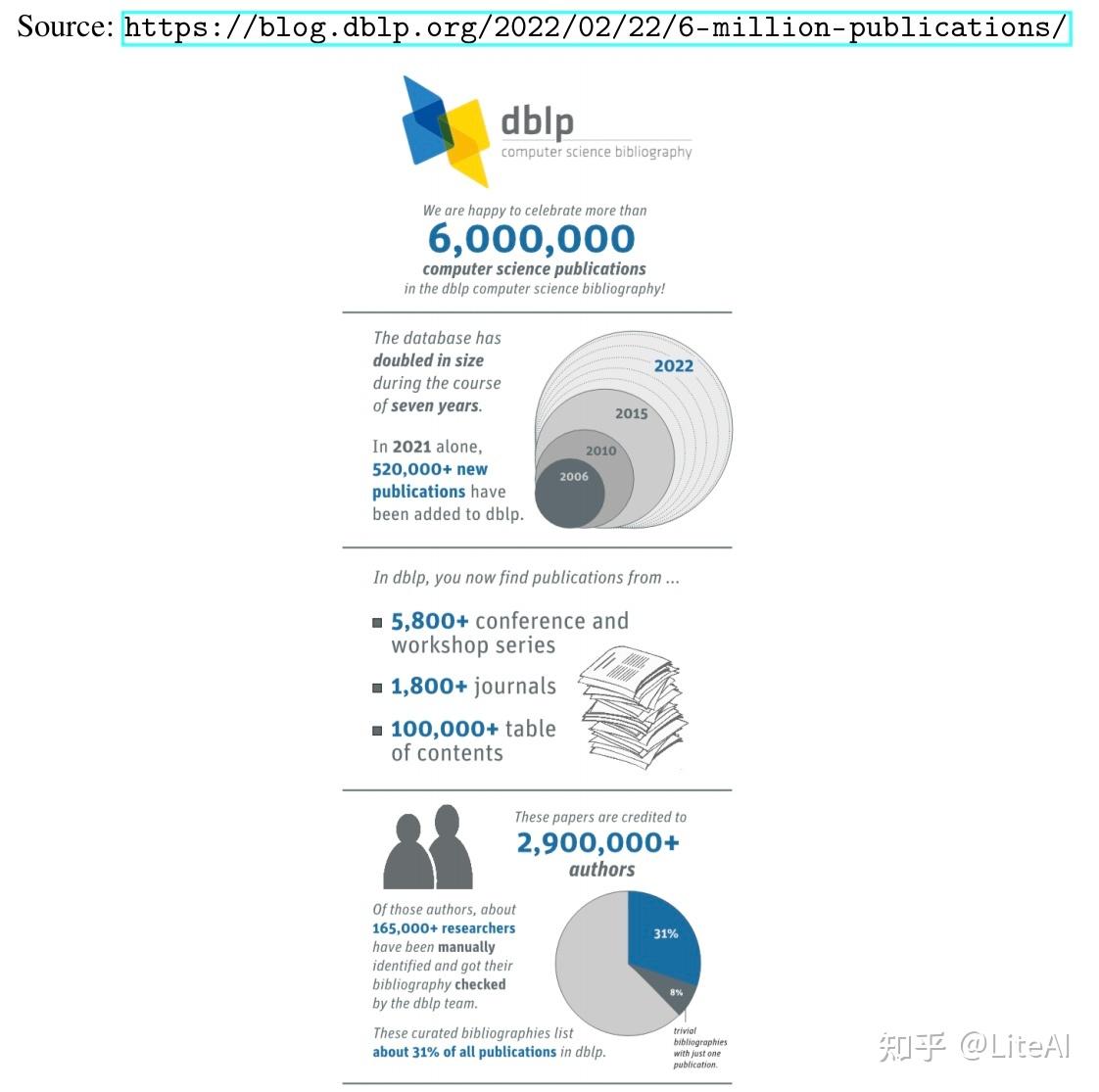
计算机科学出版物中最广泛的公共参考书目可能是 DBLP 数据库 DBLP [2019],可在 https://dblp.uni-trier.de/ 获得。最近(2022 年 2 月),它的发表量超过了 600 万篇(见图 3),包含来自近 300 万不同作者的作品。根据 DBLP 的统计页面,图 4 显示了近年来出版物的增长幅度。他们以 XML 格式提供了可下载的 664MB GZipped 版本的数据集。最近(在这项工作已经开始并通过了数据集选择过程之后),DBLP 还发布了其 RDF 格式的数据集。但是,由于他们的数据集包含重复的作者和/或错误合并的作者,我们选择不直接使用他们的数据集。相反,在我们的工作中,我们使用了 Arnet Tang 等人[2008] V11论文引文网络。它包含来自 DBLP、ACM、MAG(Microsoft Academic Graph)和其他来源的 4107340 篇论文,其中包括 36624464 条引文关系。该数据集包含比 DBLP 更多的信息,因为它们更好地消除了作者歧义(合并作者 DBLP 被认为是不同的作者,或分离作者 DBLP 被认为是同一个人),使我们能够生成更真实的协作/引用网络。
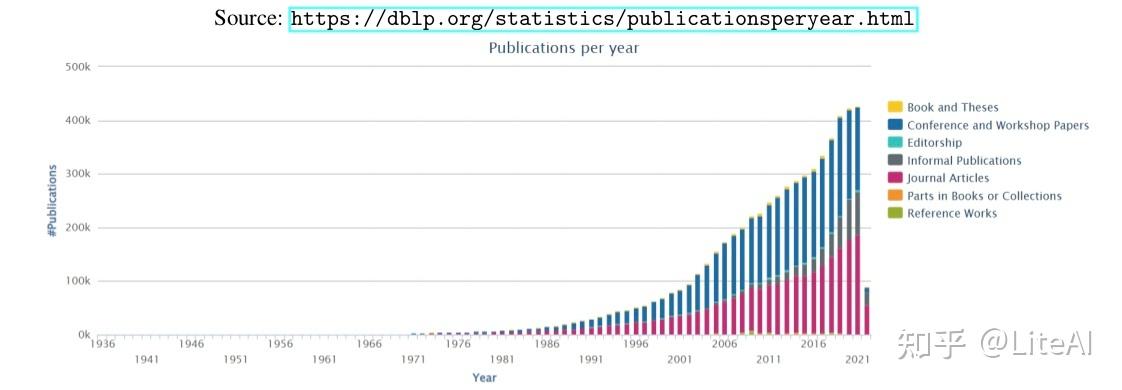
重要的是要澄清为什么我们使用 Arnet 的 v11 数据集而不是他们的新数据集之一,即 v12 和 v13——后者从 2021 年 5 月开始包含 5354309 篇论文和 48227950 条引用关系,与 v11 相比增加了 30.3%。首先,最重要的是,这项工作始于 2019 年,当时还没有 v12 和 v13 版本。
此外,当这些较新的数据集可用时,我们确实尝试使用它们,但我们遇到了一些问题,促使我们回到 v11 数据集:
1. v12 和 v13 的数据格式与 v11 不同。 v12 和 v13 的格式是一个成熟的 11GB XML 文件,这需要我们编写一个新的 Python 库来将 XML 转换为 JSON(我们的存储方法),而无需通过流式转换将整个文件加载到内存中(参见第H.1部分)。除了文件更难读取和处理之外,新格式还将 ID 从整数更改为基于 UUID 的值,导致我们重写了能够根据过去的整数检测主要 AI 会议论文的整个逻辑价值观。
2. 这项工作感兴趣的 AI 会议论文较少。尽管我们在最新版本中的论文数量增加了 30%,但在仔细找出哪些是会议的新 ID 后,我们只能在 v11 版本的 89102 篇论文中找到 58490 篇(65%)。作为冒烟测试,我们确实减少了仅对主要 AI 会议(AAAI、NeurIPS 和 IJCAI)的测试:我们可以手动计算这 3 个会议中的 42082 篇论文——这是一个下限,因为我们找不到AAAI和IJCAI几年的论文; v11 和 v13 分别有 41414 和 20371 个。我们还尝试通过名称而不是 ID 来查找 AI 会议(以一些误报为代价),但它没有奏效,也只找到了 20929 篇论文。这表明我们在 v11 中的数据是 v13 的两倍,而不是像预期的那样在 v13 中多出 30%。
3.最近几年的数据缺失。尽管 v13 应该有到 2021 年的数据,但 2019 年、2020 年和 2021 年的主要 AI 会议只有几百篇论文,而实际上应该有 12559 篇。
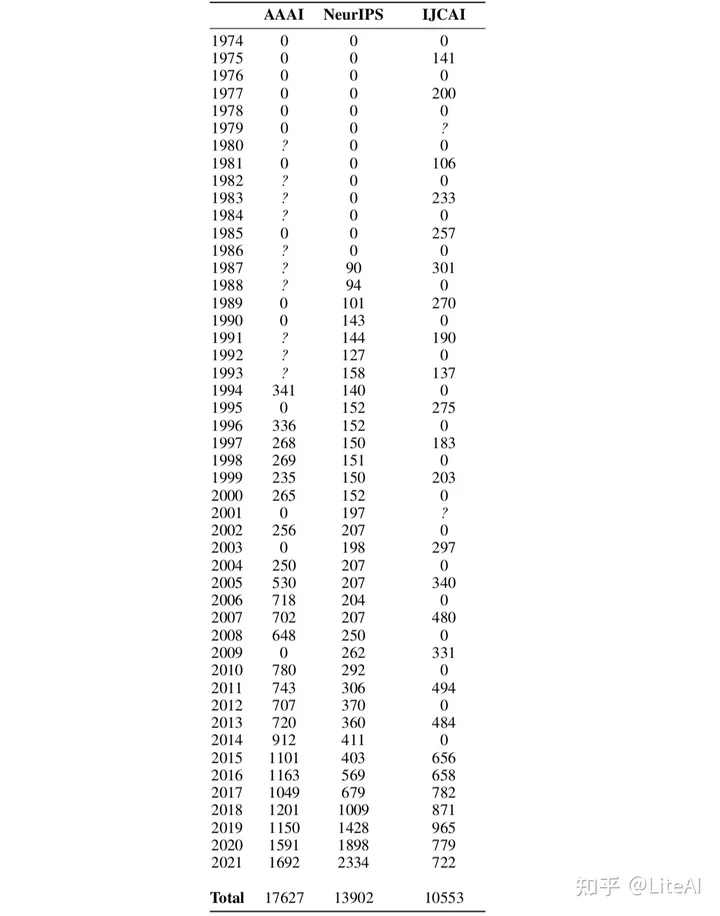
为构建上述点而编译的所有数据都可以在表 1 和图 8 中看到。表 8 包含用于构建图 8 的原始数据,其中“?”为简单起见,数据点被认为是 0。人们可能从图 5 中获得的一个有趣的统计信息是,尽管 IJCAI 过去只发生在奇数年,但偶数年的 NeurIPS 和 AAAI 论文接受率并没有明显增加。

第 4.6.1 节显示了一些图表,从中可以看出如果我们使用 v13 而不是 v11,我们的数据看起来有多么退化。 Arnet 的 v11 格式是 JSON 文件的一种变体,经过一些改进,可以更轻松地将数据加载到内存中,而无需加载整个文件。每行都是一个有效的 JSON 对象,要求我们简单地流式传输文件,遍历每一行,解析 JSON 文件,只在内存中保留所需的信息,并立即将 JSON 文件发送到垃圾收集,使用不超过 8kb内存读取整个文件。
此文件中的每个 JSON 对象都遵循表 2 中定义的结构。然后,对于大部分工作,我们只保留带有星号 (*) 标记的字段。此外,问号 (?) 表示该字段是可选的,有时在 Arnet 提供的数据中不存在。图 43 显示了此类 JSON 条目的示例,描述了 Glorot 和 Bengio [2010] 在数据集中的表示。
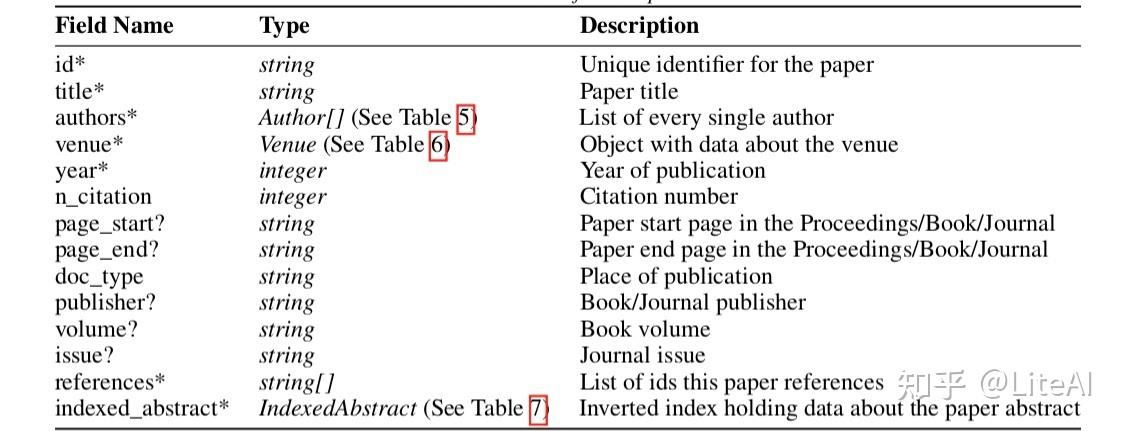
图 6 使用第 2.3 节中定义的会议显示了对该数据集的一些原始见解。这表明过去几年所有会议的论文数量都有增加的趋势,特别是 CVPR 和 AAAI。
3.2 Artifacts
用于下载数据、解析数据集以及生成本工作中存在的图形、分析和图表的代码可在 Github 的 https://github.com/rafaeelaudibert/TCC/tree/v11 上找到。这项工作的代码在分支 v11 中。 master 分支包含我们尝试解析 Arnet 的 v13 数据集时使用的代码,但没有像上一节中解释的那样工作。在 PyPi 中提供的一些开源第三方库(见表 9)的帮助下,一切数据分析都是使用 Python 构建的。对于最复杂的绘图,Python 不是适合这项工作的工具,因此它们是使用 R 及其内置的 matplotlib、numpy 和 seaborn 对应物构建的。不幸的是,这些图表的代码不再可用,因为它在磁盘格式化过程中丢失了。
3.2.1 图数据集
在整个工作中,我们组装了 5 个新的数据集,以图结构建模,下面将对其进行简要描述。可以在下面的每个相应部分中找到详尽的解释。
作者引文图 (ACi) 有向多重图,其中每个作者都是一个节点,边代表引文。
作者协作图 (ACo) 无向图,其中每个作者都是一个节点,边代表共同作者
论文引文图 (PC) 有向图,其中每篇论文都是一个节点,边表示引文。
作者-论文引用图 (APC) 有向标记图,其中节点可以是作者或论文,我们可以在论文之间(引文)或作者与论文之间(作者身份)有边。
国家引文图 (CC) 有向多重图,其中每个节点代表一个原产国,边代表引文。
由于我们的工作专注于旗舰 AI 和相邻领域会议,我们过滤了他们的数据集,只包含在这些会议上发表的论文来构建我们的数据集。所选会议基于 CSRankings CSRankings [2019] 排名靠前的 AI 会议,包括以下领域:人工智能、计算机视觉、机器学习与数据挖掘、自然语言处理和 Web 与信息检索。对于上面解释的每个图,我们计算了以下精确的中心性:角度(进出)(第 2.4.2 节)、介数(第 2.4.3 节)、接近度(第 2.4.4 节)和 PageRank(第 2.4.5 节)。
对于我们的工作,我们创建了从 1969 年(第一次 IJCAI 会议)到 2019 年的每一年的累积图,即 2000 年的累积图包含 2000 年之前和包括 2000 年的所有论文。从 1969 年到 2019 年的每一年的图还创建了,以帮助进行以下部分中介绍的分析。包含所有数据(包括精确中心性)的累积图可在 https://github.com/rafaeelaudibert/conferences_insights_database 获得。整个作者引用数据集的累积图,不受会议限制,也可以在同一个存储库中使用,而无需计算中心性度量。我们可以在表 3 中找到每个图形数据集大小的统计信息。
3.3 图类型
这些图是使用 networkx Hagberg [2008]等人在 Python 中构建的。 它提供了一个简单的界面来构建各种类型的图,包括我们经常使用的具有有向边的多重图。以下所有图表均基于图 7 中所示的数据。

3.3.1 作者引文图
这是一个有向多重图,其中每个作者都是一个节点。一条边 eu,v 代表作者 u 的一篇论文,它引用了作者 v 的一篇论文。由于作者 u 可以有不止一篇论文引用作者 v 的一篇论文,因此节点之间可能有不止一条边,因此我们有多图。此外,作者可能会引用他们自己的另一篇论文,因此我们可能会有自循环。
由于我们的数据组织方式,当我们迭代论文时,我们只有被引用论文的 ID,但没有其他论文中作者的 ID。因此,我们首先创建一个哈希表,其中键作为论文 ID,值作为该论文的作者。我们将其用作查找表来确定在迭代论文时应该连接哪些作者。请参阅算法 2 以了解其在构建图形时的工作原理。

以上意味着我们首先需要遍历所有论文并创建这个巨大的查找表。在实践中,因为你不能引用尚未发表的论文,所以我们将论文按发表年份划分为桶,并以升序进行迭代,这将使我们在这个哈希表中只保留“过去”的论文。算法 1 展示了年份分桶算法,算法 2 展示了我们如何构建这个图,使用这个更有效的哈希表,在任何 y 年,我们在哈希表中只有 i <= y 年的论文。尽管在流程结束时,表的大小与我们从一开始就构建它时的大小相同,但当我们在第一年迭代时,这种方法提高了本地一致性,提高了缓存结果,从而使这个过程更有效率。

请注意,我们可能没有引用论文的数据,因为我们只过滤掉少数会议的数据。在这种情况下,我们根本不包括这篇论文。
此图生成过程的最新版本代码可在 https://github.com/rafaeelaudibert/conferences_insights/blob/v11/graph_generation/generate_authors_citation_graph.py 中找到。
图 8 显示了此类图的示例,给定了图 7 中的输入数据。
3.3.2 作者协作图
这是一个无向图,其中每个作者都是一个节点。在该图中,边 eu,v 表示 u 和 v 在至少一篇论文中一起工作。
与作者引文图(第 3.3.1 节)相比,该图更容易生成,因为数据是本地的,我们不需要对数据进行两次迭代来生成查找表:我们可以简单地迭代所有论文,然后连接所有论文集团中的合著者。
可以在 https://github.com/rafaeelaudibert/conferences_insights/blob/v11/graph_generation/generate_collaboration_graph.py 中找到此图生成的最新版本代码。
图 9 显示了此类图的示例,给定来自图 7 的输入数据。
3.3.3 论文引文图
这是一个有向图,其中每篇论文都是一个节点。有向边 eu,v 表示论文 u 引用了论文 v。与 作者引用图类似,我们需要创建一个查找表,使用相同的增量过程加载查找表数据,仅在迭代y年时 i <= y 年。可以在 https://github.com/rafaeelaudibert/conferences_insights/blob/v11/graph_generation/generate_citation_graph.py 中找到此图生成的最新版本代码。
图 10 显示了此类图的示例,给定来自图 7 的输入数据。
3.3.4 作者-论文引用图
这是一个有向标记图,其中节点可以是作者或论文,我们可以在论文之间或作者与论文之间有边,因此该图比以前的更复杂,因为它可以表示论文引用网络和作者引文网络(通过中间论文节点)。
该图是基于论文引用图构建的,其中已经存在的节点来自论文类型 VP,并且已经存在的边来自类型引用 EC。之后,我们为每个作者添加一个作者类型为 VA 的节点,为他们撰写的每篇论文添加一个作者身份类型为 EA 的有向边。
该图非常适合全面了解数据,并有可能推断出其中的每一个可能的交互。因此,它是知识表示任务甚至推荐系统的理想表示。这将在第 5.2 节中更详细地讨论。
可以在 https://github.com/rafaeelaudibert/conferences_insights/blob/v11/graph_generation/generate_authors_and_papers_graph.py 中找到此图生成的最新版本代码。
图 11 显示了此类图的一个示例,给定来自图 7 的输入数据。
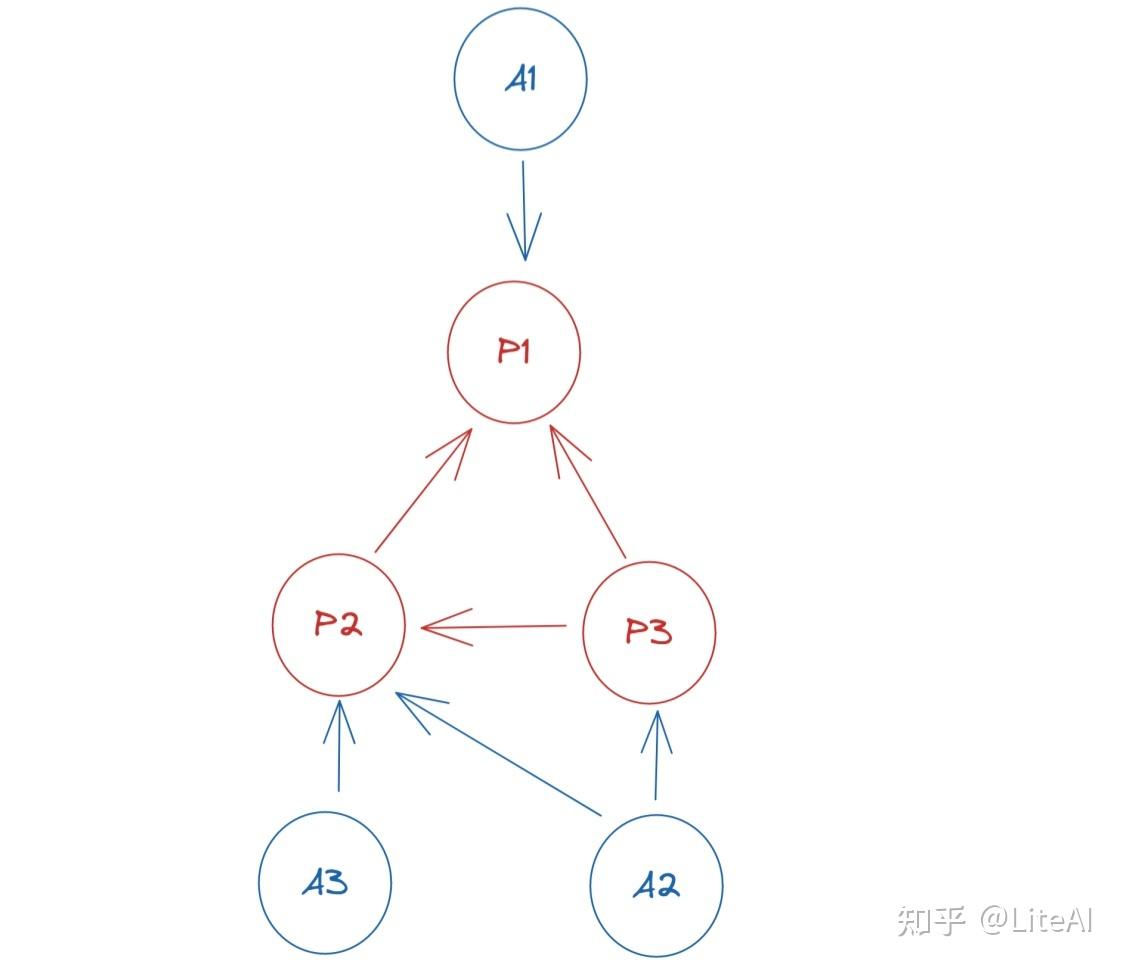
3.3.5 国家引用图
这是一个有向多重图,其中每个节点代表一个国家,一条边 eu,v 代表来自 u 国的作者在论文中引用了来自 v 国的作者。因为这两个节点之间可能有很多边。
在我们弄清楚作者来自哪个国家(详见第 3.4 节)后,我们可以通过对引用图执行相同的过程来创建此图。将当时已经存在的论文保存在查找表中;遍历每篇论文;遍历引用;迭代当前论文作者和被引用论文作者;将他们所属的国家与边缘联系起来。创建自环是可能的(并且很常见)。
可以在 https://github.com/rafaeelaudibert/conferences_insights/blob/v11/graph_generation/generate_country_citation_graph.py 中找到此图生成的最新版本代码。
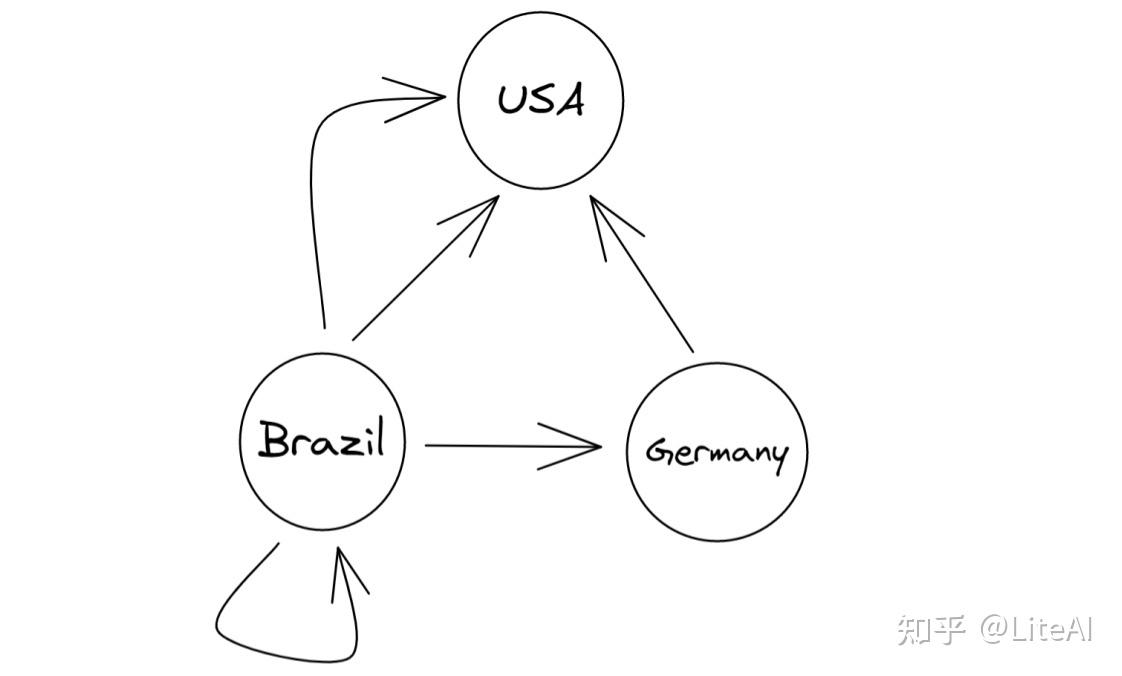
图 12 显示了此类图表的示例,给定来自图 7 的输入数据,以及以下从组织到国家的映射:MIT → USA; UFRGS → 巴西; TU KL → 德国。
3.4 隶属 x 国家映射
需要注意的是,我们收集的 Arnet v11 数据并不总是在其“org”字段中提供作者的国家/地区,仅包含他们所属的组织——有时甚至不提供组织——这会造成问题。
数据中的“组织”字段是自由格式的,这意味着它没有清晰的结构,我们可以从中提取作者的国家。更糟糕的是,它甚至可能不是大学名称,因为公司和非附属个人都可以在旗舰领域拥有论文。但是,大多数数据都有一些结构,因此我们开发了一个管道,我们在其中反复尝试检测组织的原产国。
在我们的管道中,我们首先按照算法 4 对组织进行预处理,去除杂乱,只使用最后一个逗号之后的文本——理想情况下是所属国家应该在的位置。之后,遵循算法3。我们尝试将文本与将组织映射到国家的查找表进行匹配。如果有遗漏,我们将文本分割成空格,并尝试只匹配表的第一个单词,并且只匹配最后一个单词。如果这仍然不起作用,我们尝试在没有预处理步骤的情况下匹配文本。
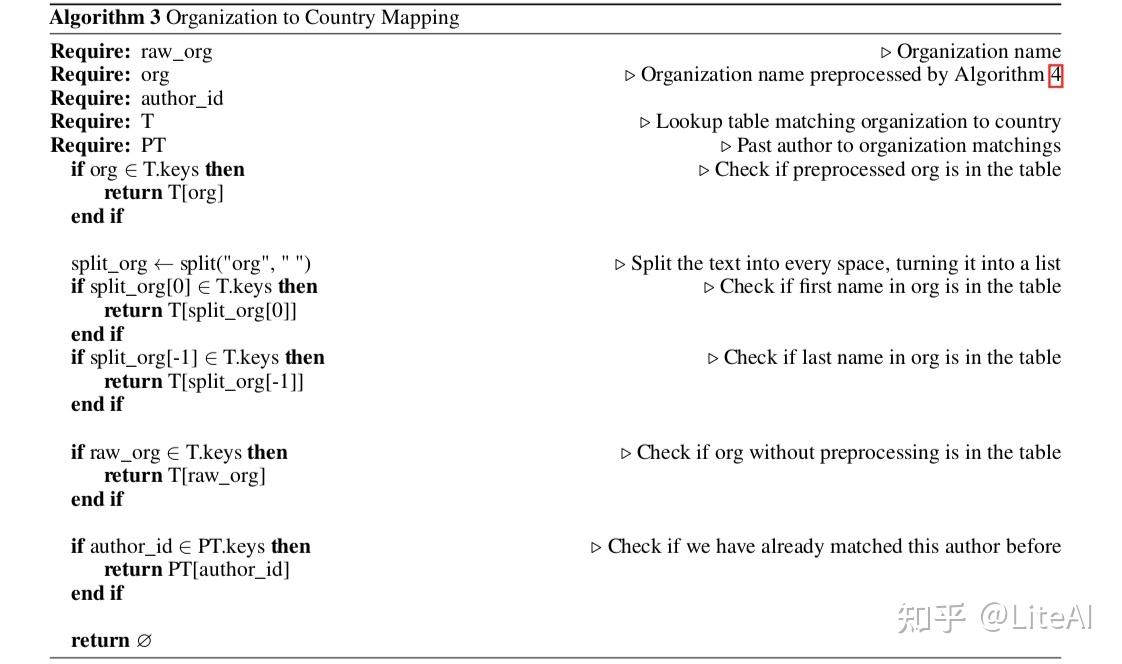

最后,如果一切都失败了,我们检查我们之前是否匹配了那个作者。这是我们最后的手段,因为请记住,作者可能会在整个学术生涯中改变组织(甚至国家),所以我们不能相信作者仍然会在他们最后一次发表文章时在同一个组织中。
上述过程可以在 https://github.com/rafaeelaudibert/conferences_insights/blob/v11/graph_generation/generate_country_citation_graph.py 中的 infer_country_from 函数中看到。
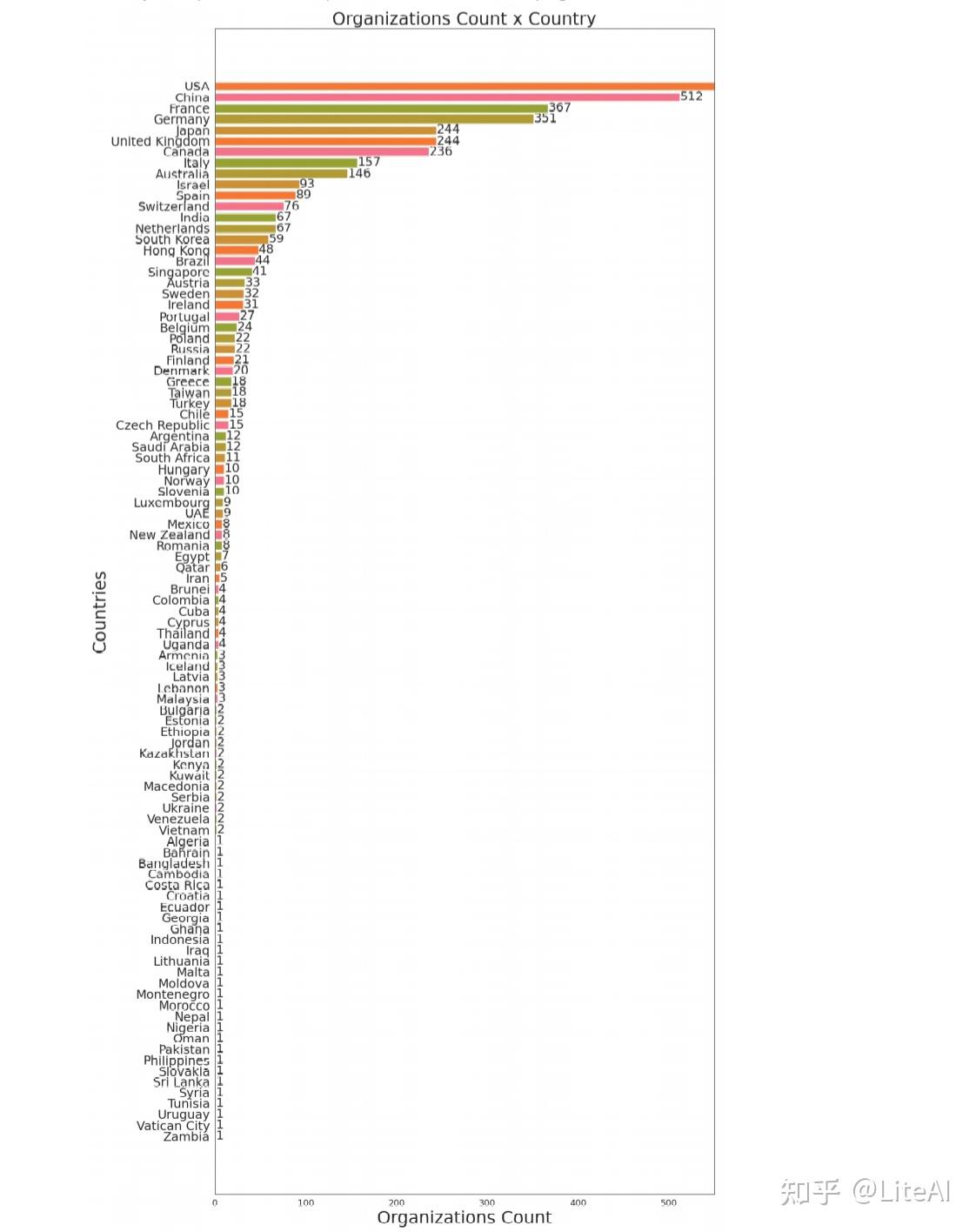
我们确实还有另一个重要步骤没有在上述步骤中完全解释:我们如何创建“查找表”以从组织映射到国家。我们在 2 个月的时间里通过手动迭代劳动密集型过程手动创建了它:使用算法 3 手动查看不匹配的组织,并使用我们自己的知识和网络搜索将它们映射到它们所属的国家以过滤选项下来。此映射可在 https://github.com/rafaeelaudibert/TCC/blob/v11/graph_generation/country_replacement/json 获得。 曾经在 AAAI、IJCAI 和 NeurIPS 上发表过的每个组织的映射都已完成,为其他会议映射的过程仍在进行中。我们希望这种映射可以在未来被其他作品使用,以促进从组织中推断出一个国家。图 13 显示了我们在每个国家/地区映射了多少个组织——美国在图中不适合比例,其值为 2163。
此外,还有一些作者的“org”字段为空。在该领域的最初几年(1969-1979),我们没有发表很多论文,所以我们手动查看了每篇论文的组织字段为空,并在 https://github.com/rafaeelaudibert/TCC/blob/v11/graph_generation/author_country_replacement.yml上生成了另一个查找表。然后我们在尝试上述管道之前先检查这个表,因为它更可靠。该表是专门用 YML 而不是 JSON 构建的,以提高可读性,并允许我们在条目之间添加注释。
然而,值得注意的是,这个问题在最近几年更加严重。 Arnet 的数据没有为 2018 年以后发表的大多数论文提供组织,因此近年来问题更大。例如,在图 36 中,“None”堆叠部分近年来更大。
4 数据分析
本节介绍了在第 3 节中描述的对我们的数据集进行的主要分析和见解。我们在第 4.1 节中介绍了初始统计数据,然后分析每个图表(第 4.2 至 4.6 节)。然后,我们在第 4.7 节研究图灵奖获得者的研究影响。
如前所述,数据生成和数据分析的完整代码已在 https://github.com/rafaeelaudibert/TCC/tree/v11 上公开。由于 Arnet 的 V13原始数据存在上述问题,主要代码在分支 v11 中。
4.1 Raw数据
尽管这项工作的大部分旨在围绕图形数据集及其为支持我们的主张而构建的中心性度量,但原始数据本身也能够为我们提供以下部分的重要介绍信息。
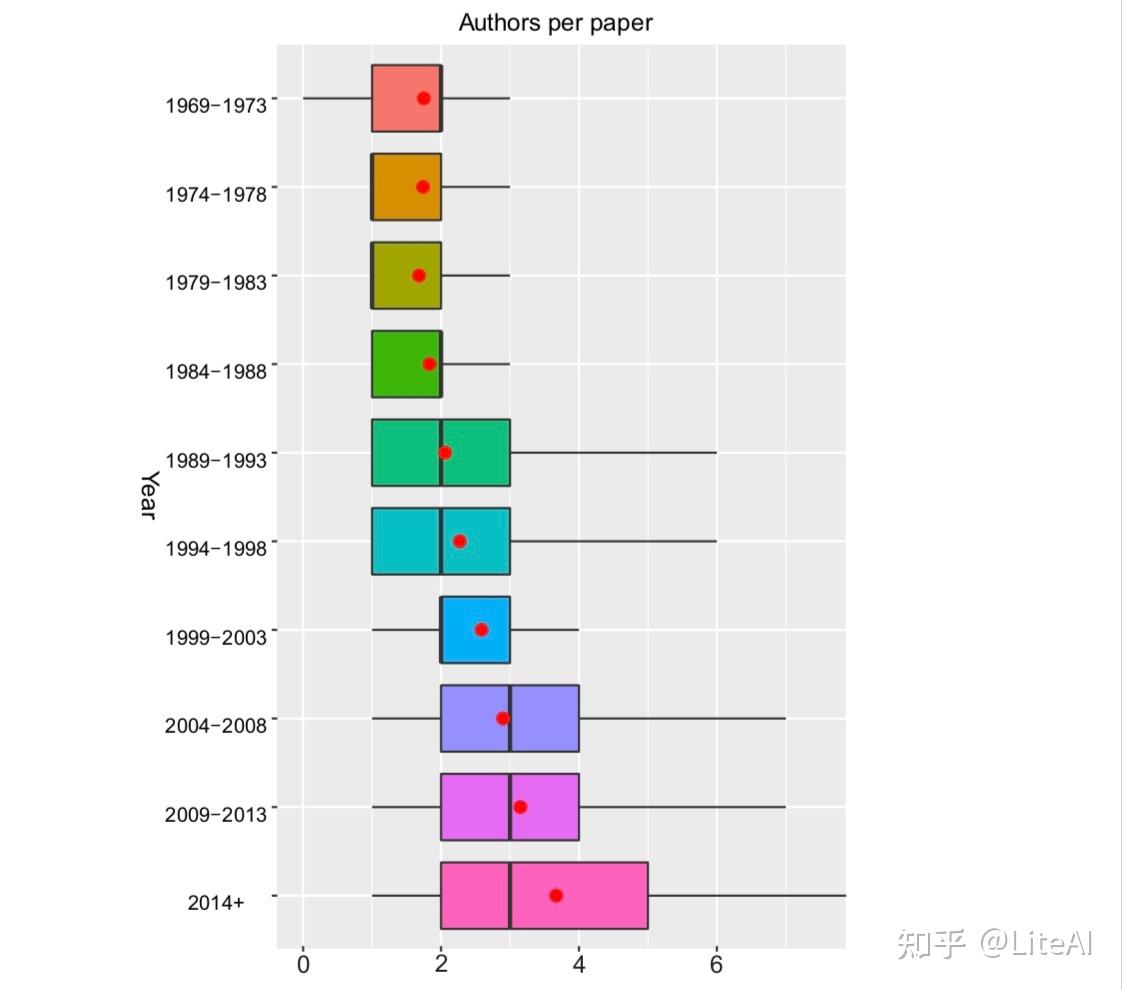
图 14 显示了多年来每篇论文的作者数量呈上升趋势的箱线图。在这个箱线图中,红点代表每篇论文的平均作者数,黑线代表中位数,方框本身代表 95% 的百分位数,而黑线代表 99% 的百分位数——即使数据集中显示失败在 1960 年代后期有一些作者为 0 的论文。该图显示了几位作者在一篇论文中的趋势,如 Brown 等人 [2020],Jumper等 [2021] 和 Silver 等人 [2016] 是最近且罕见的,自 2004 年以来,不超过 1% 的论文有 7 位或更多作者。值得注意的是,在 2014 年过去的几年里,平均值如何跃升至近 4 位。
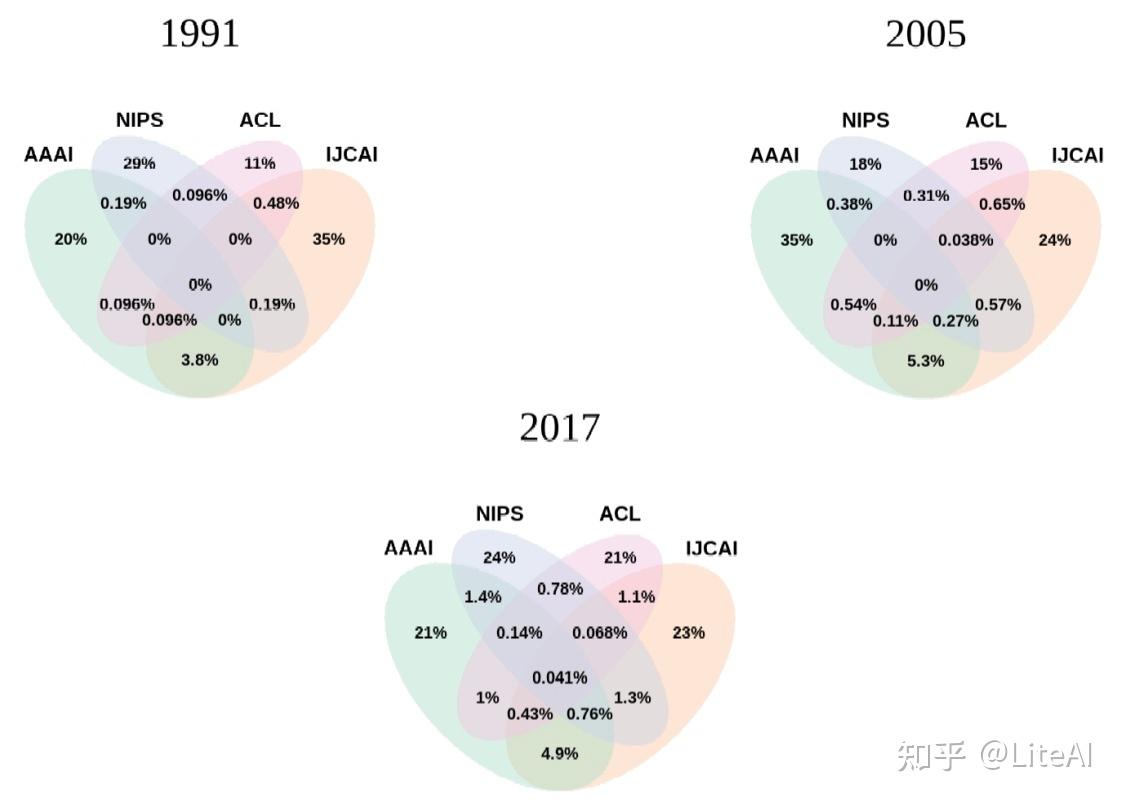
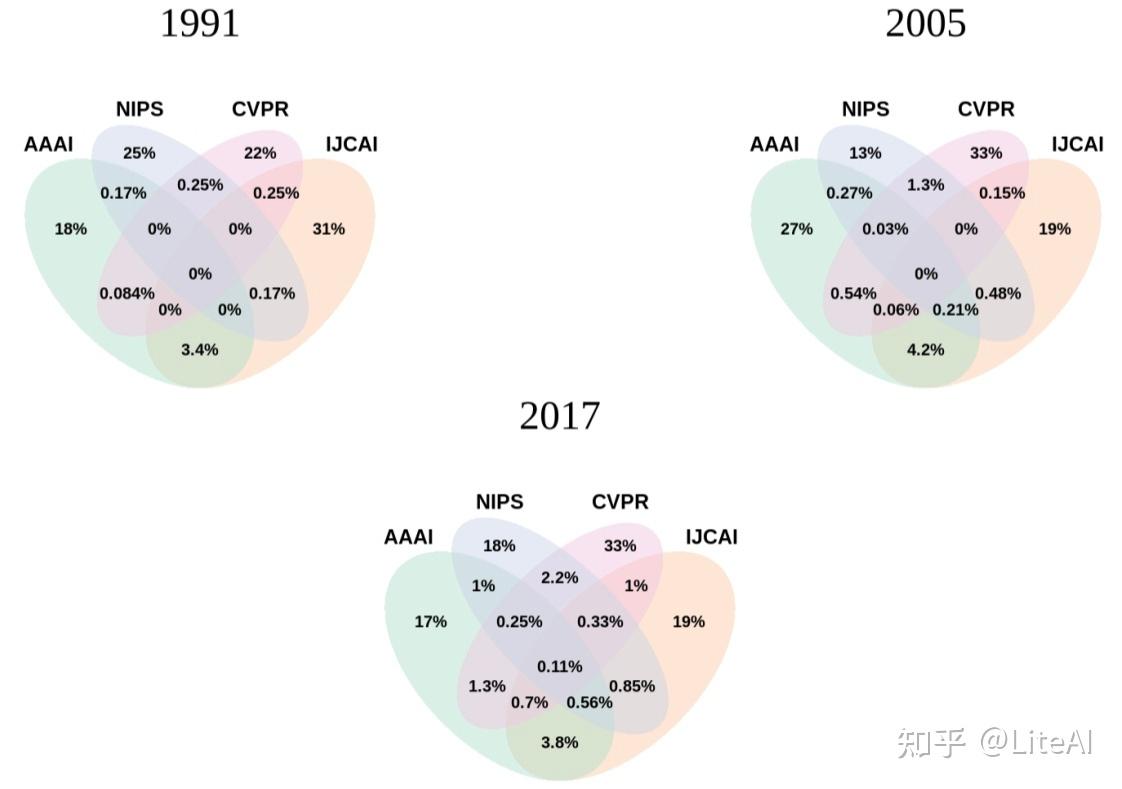
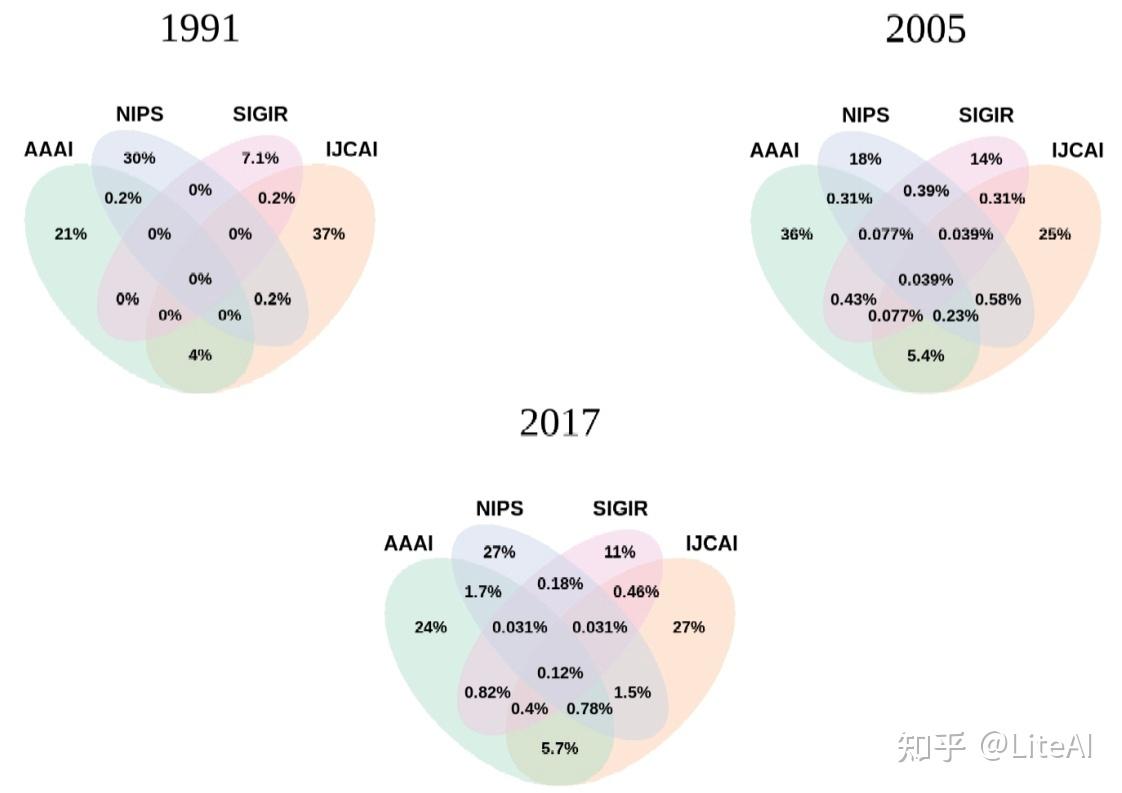
我们还对同年在不同地点发表文章的作者进行了交集。出现了一些有趣的趋势,例如: AAAI 和 IJCAI 在作者方面的重叠比它们与 NIPS 和 ACL 的任何组合最大(图 15);自 2000 年代初以来,CVPR 聚集的作者数量超过了 NIPS 和 IJCAI,其最大的作者重叠始终是 NIPS(图 16); SIGIR 在 90 年代与这三个会议几乎没有重叠,现在仍然几乎没有重叠,尽管它与 AAAI 的交叉点有所增加(图 17)。
4.2 作者引用图
4.2.1 时间排名
我们使用累积的引文数据 – AC 图计算了从 1969 年到 2019 年关于上述中心性度量的作者排名。
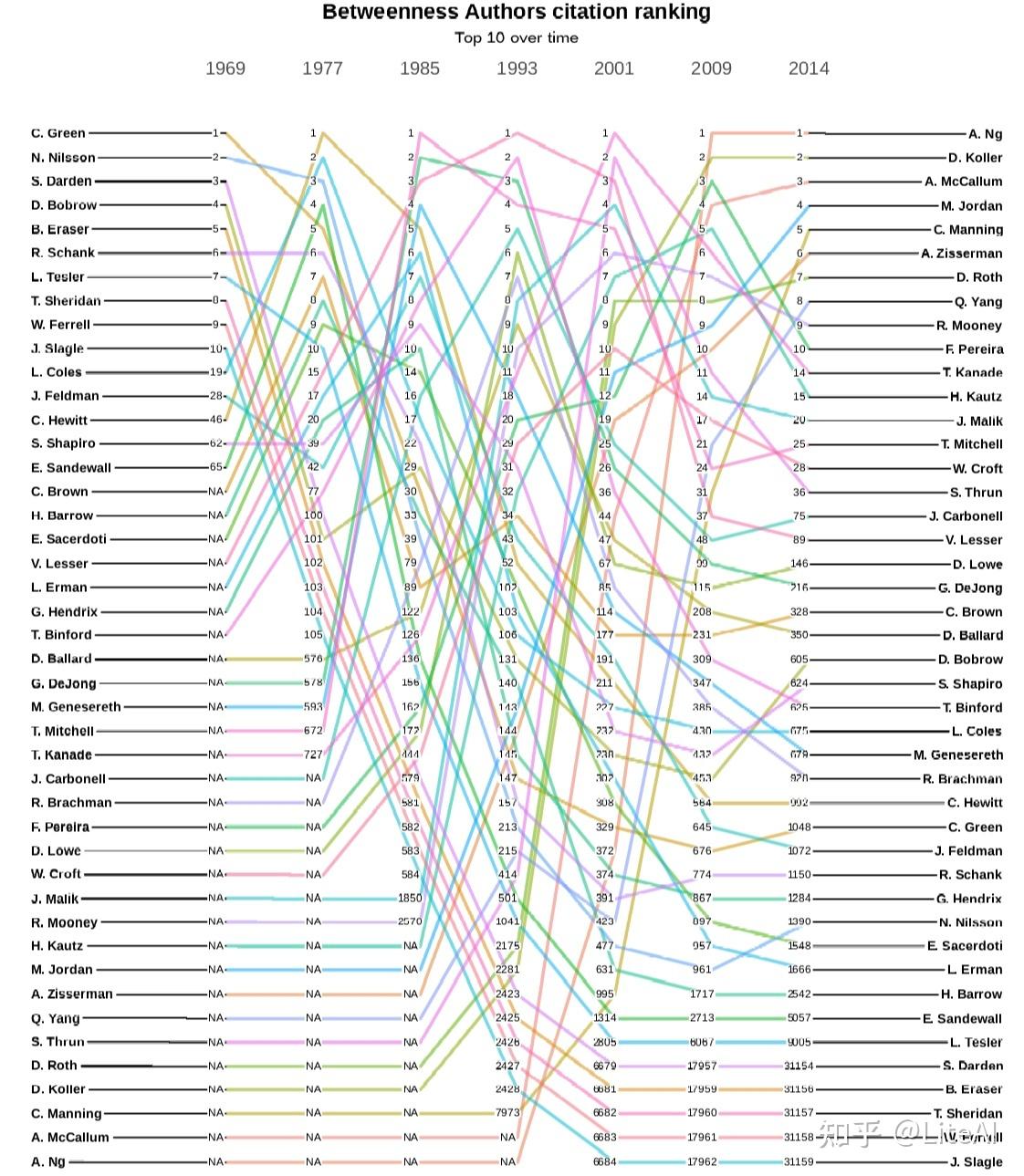
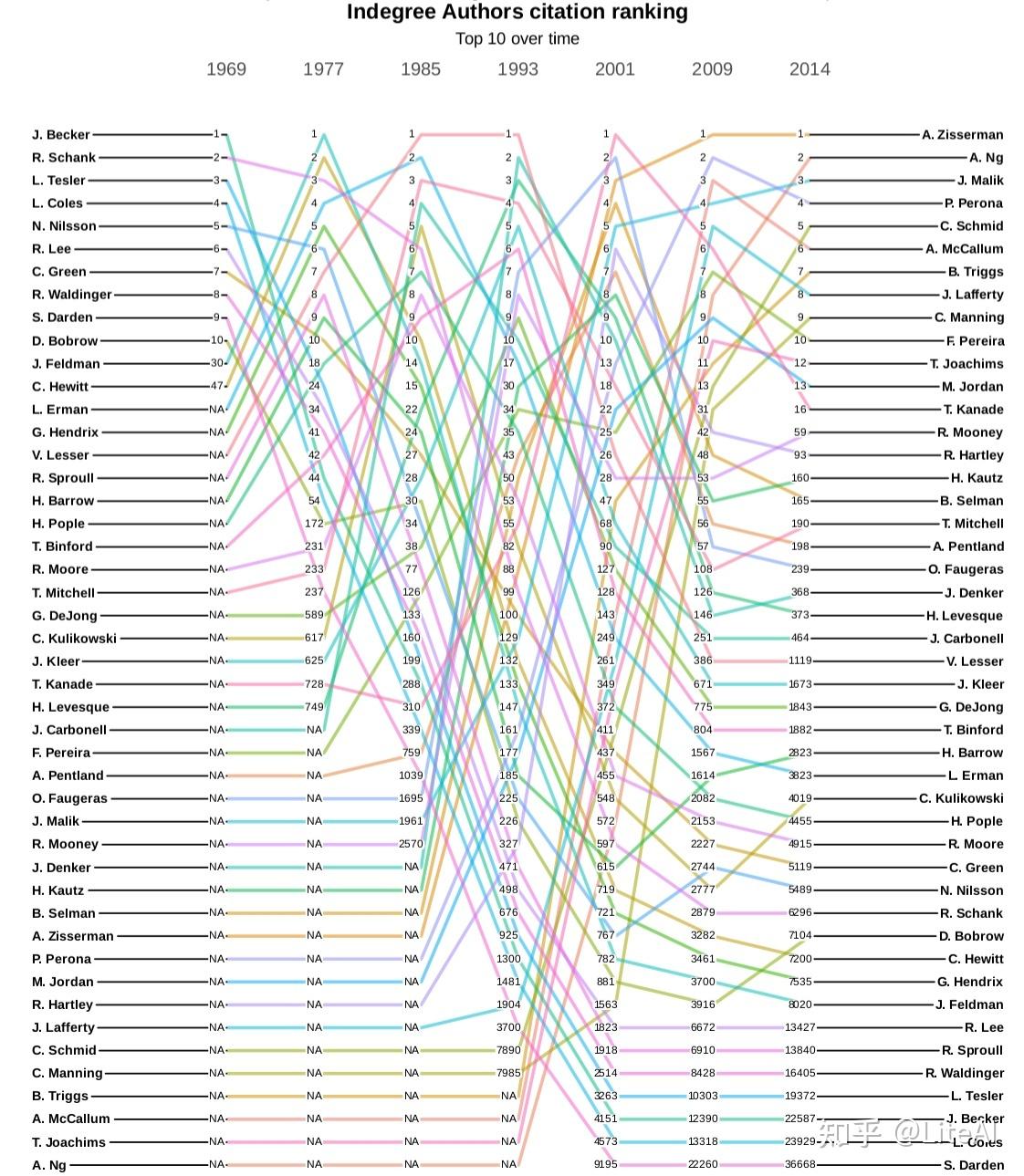
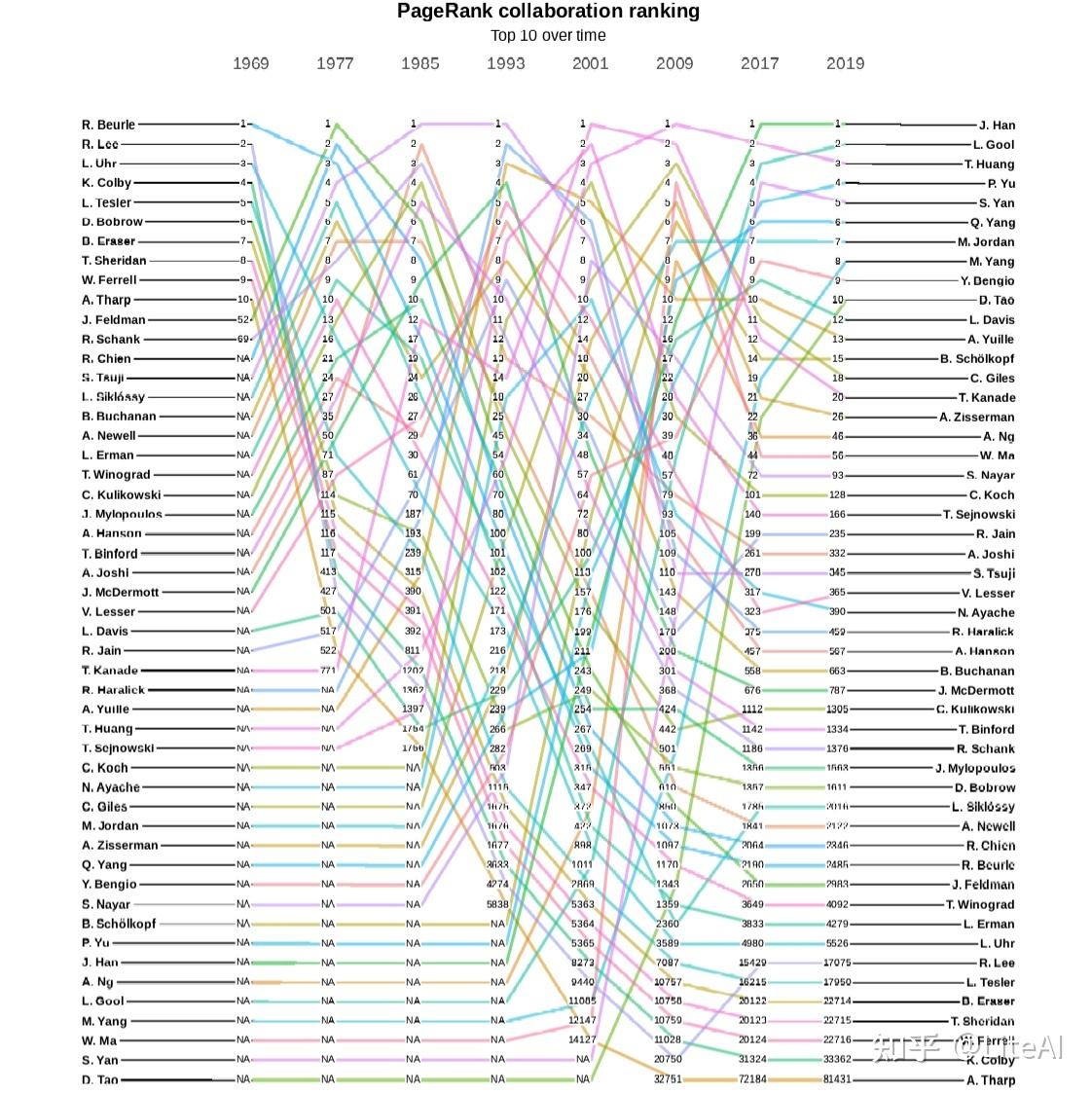
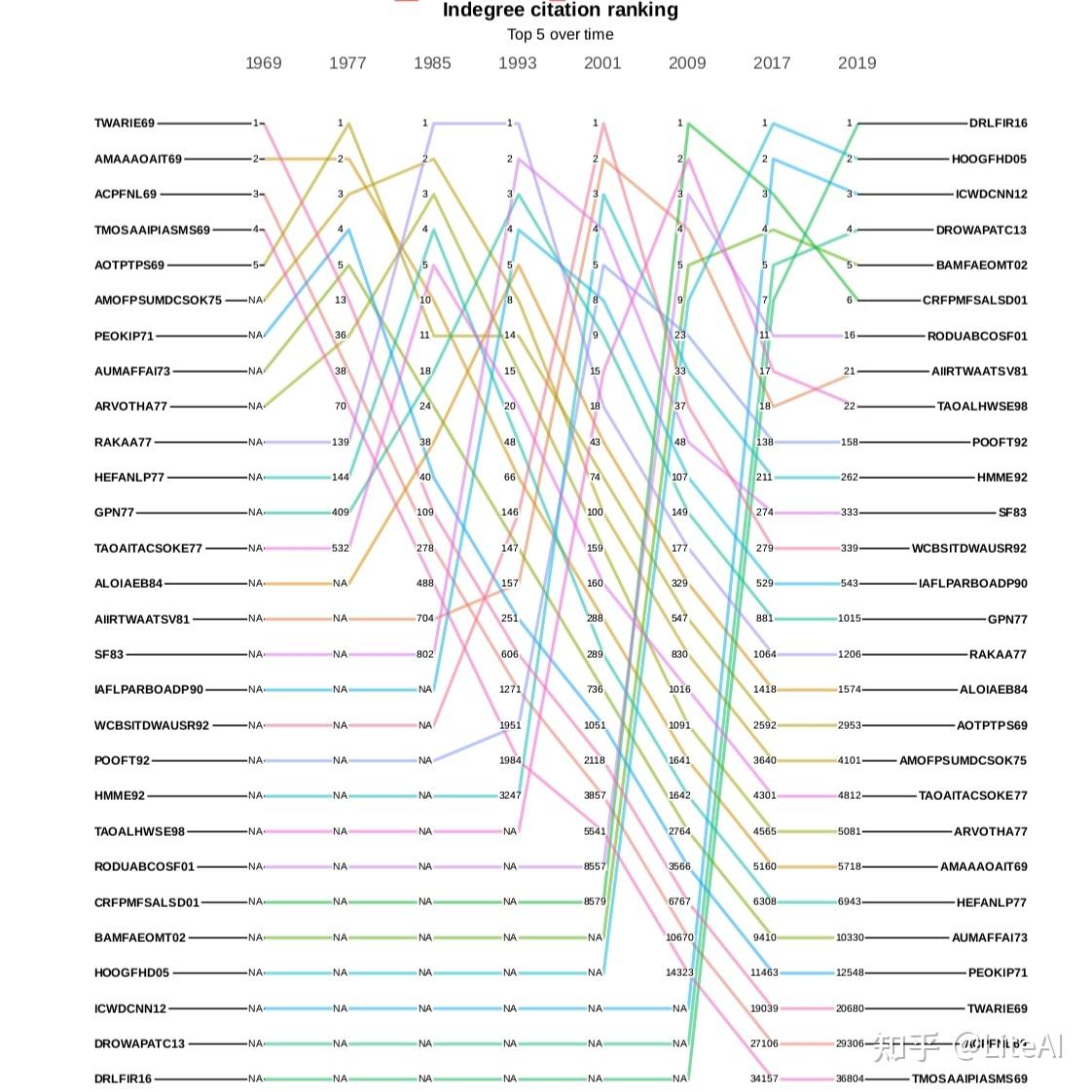
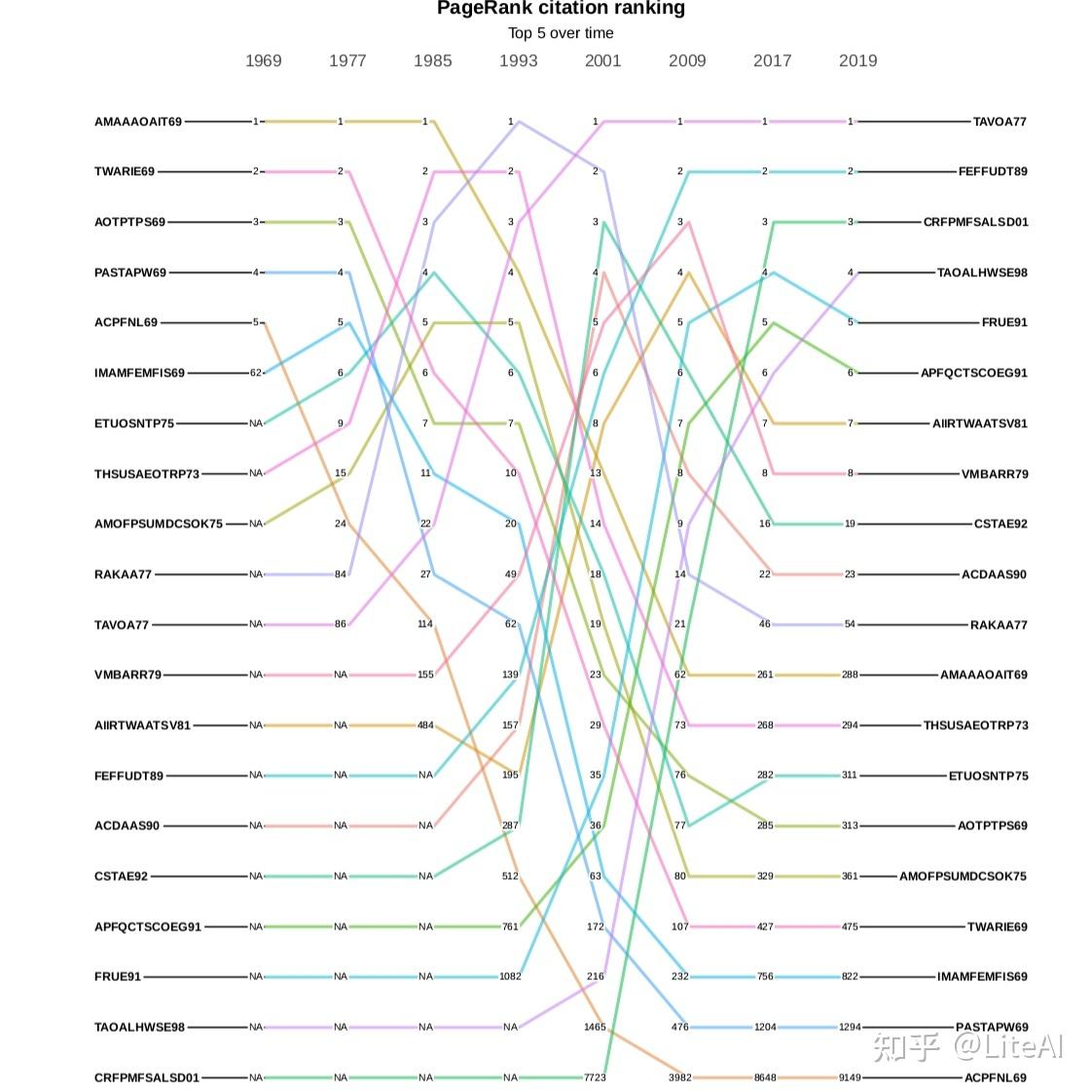
图 18、19 和 20 分别显示了作者引用图中 PageRank、介数和角度中心性的演变。在这些图中,一条线代表单个作者及其在某些预定义年份(选择为 1969、1977、1985、1993、2001、2009 和 2014)中随时间推移的排名演变。显示的唯一作者是那些在这些年份的任何时候达到该特定排名前 10 名的作者。在这些年份中尚未发表文章并因此尚未获得任何排名的作者显示为 N/A。
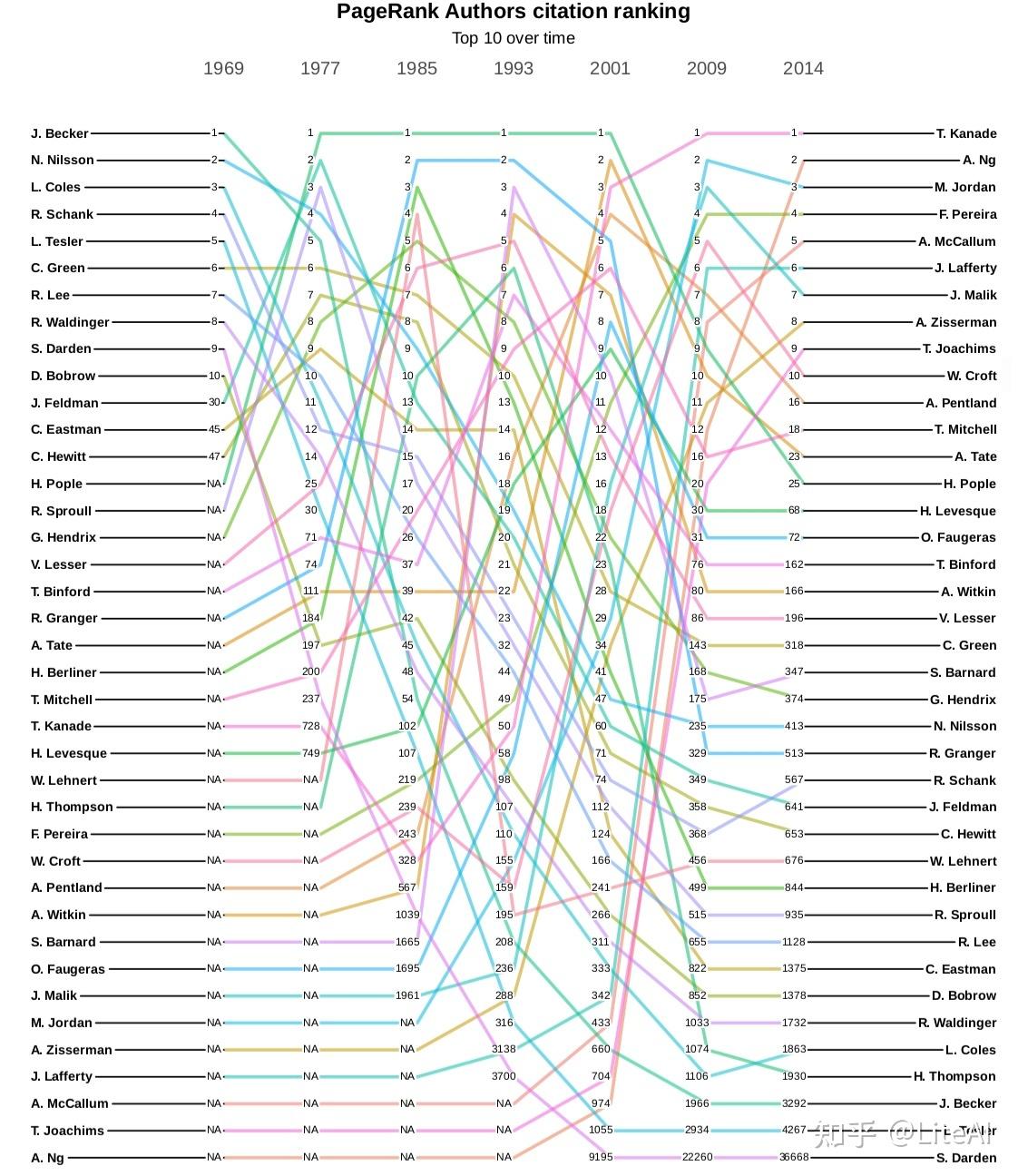
尽管它们看起来很混乱,但这些图表确实有一些有趣的见解。图 18 是一个有趣的起点,因为它相当稳定,至少在顶部是这样。至少从 1977 年到 2001 年,Harry Pople 是该排名中的第一名作者,这是在我们的任何分析中保持这一位置的最长时期。他的主要工作集中在人工智能到医学 Dhar 和 Pople [1987],因此在不同领域之间非常重要。同样在 PageRank 图表中,人们可能会看到,吴恩达从 2001 年出道的第 974 位上升到 8 年后的第 16 位,再过 5 年又上升到第 2 位,这一上升趋势往往是迅速的。对于该图中存在的大多数动态,也可以这样说。
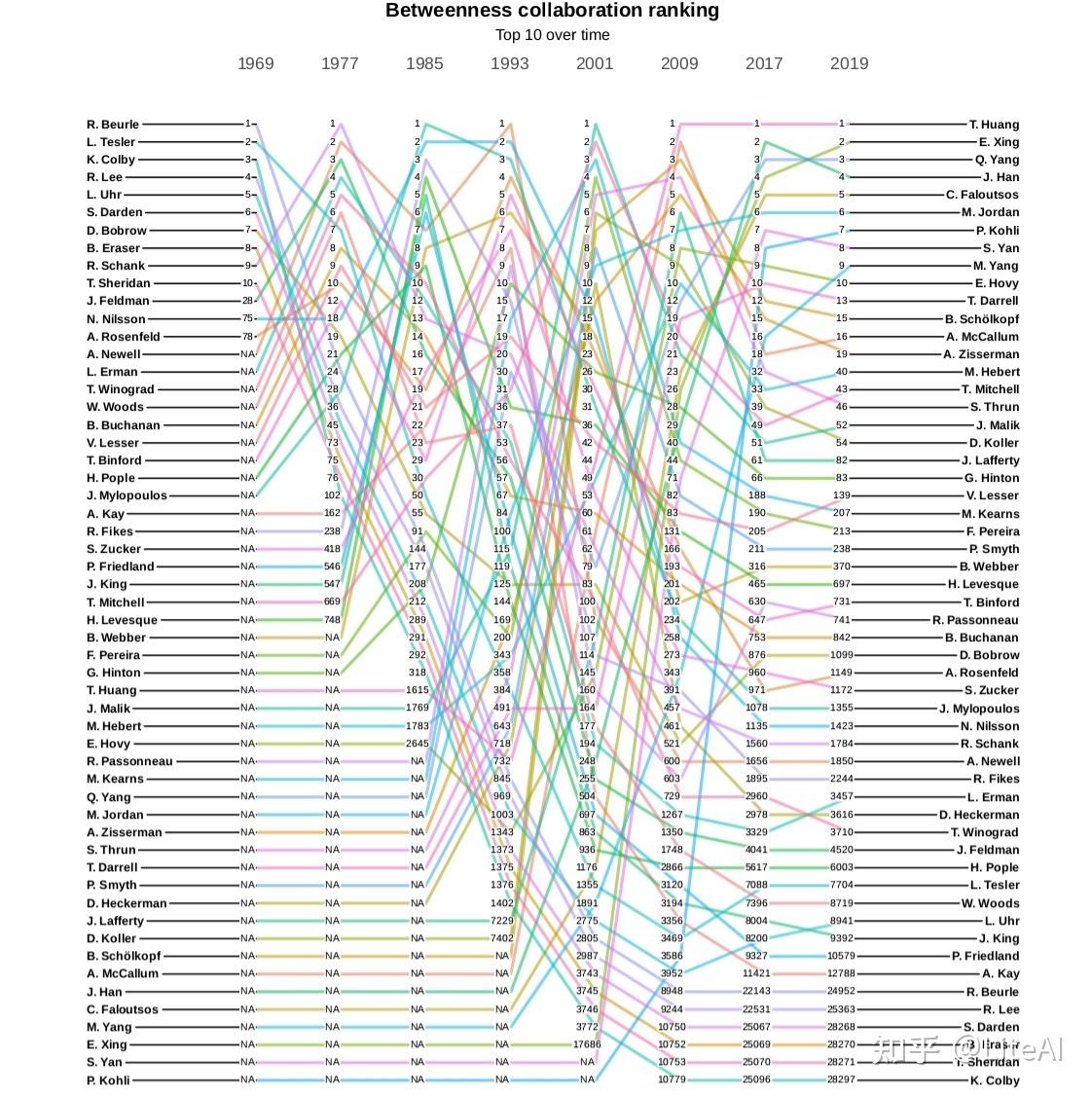
上述见解也适用于分析介数的图 19。该图远不如 PageRank 稳定,因为当机器学习中出现新领域时,介数更容易演变,因此会改变图中的信息流,而 PageRank 会更稳定,因为重要的人会继续与他们永远一样重要,只有当更有影响力的人出现时,他们的排名才会下降。例如,通过查看两个图表中的最后一个位置,我们可以看到这种动态:Larry Tesler – 在 PageRank 图表中排在最后一位,因为最后一个位置是异常值 – 在 PageRank 中排名第 4267,而在 PageRank 中的最后一个位置介数图是第 31159 位,显示了在此处分析的数据集中,即使他们曾经是最具影响力的前 10 名科学家,但在介数排名中可能会下降多低。
角度图表显示了一个基本的原始数据点:哪个作者被引用次数最多,这应该奖励年长的作者发表开创性的论文。排名第一的是 Andrew Zisserman,他是 Simonyan 和 Zisserman [2014] 以及 Hartley 和 Zisserman [2003] 等论文的作者,在他的一生中被引用近 300,000 次——其中仅被引用的 2 次就超过 100,000文件。第二个位置是 Andrew Ng,他的引用次数只有 Zisserman 的三分之一多一点。
综合考虑所有这些图表,有趣的是,当我们从引文的角度分析时,在此处分析的数据集中,Andrew Ng 是 AI 领域最具影响力的整体作者。他是 Blei 等人的论文的作者。 [2003] 和 Ng 等人[2001],h-index 为 134,即 134 篇论文至少被 134 次引用(请参阅第 2.4.6 节的 H-Index 以了解如何计算该指标),在 Google Scholar 中排名第 1403 的 h-index。他以最大的中介值出现,在度数和PageRank排名中位居第二。
页面排名第一的金出武雄在介数和角度方面分别仅排在第 14 位和第 16 位——尽管值得注意的是,2001 年他在度数和介数方面排名第一,而在 PageRank 中排名第三。平均而言,这是我们的结果中可以找到的最佳结果。同样,度数排名第一的 Andrew Zisserman 在介数方面排名第六,在 PageRank 排名中排名第八。
其他计算的中心性的排名可以在附录 C 中看到。
4.2.2 自引用
作者可能会在他们之前的工作中积累,这将在我们的图表中引入表示自引用的自边缘。图 21 显示了每年自引用数演变的箱线图。尽管平均开始稳定在两个左右,但越来越多的作者多年来一直在增加他们的自引用次数。
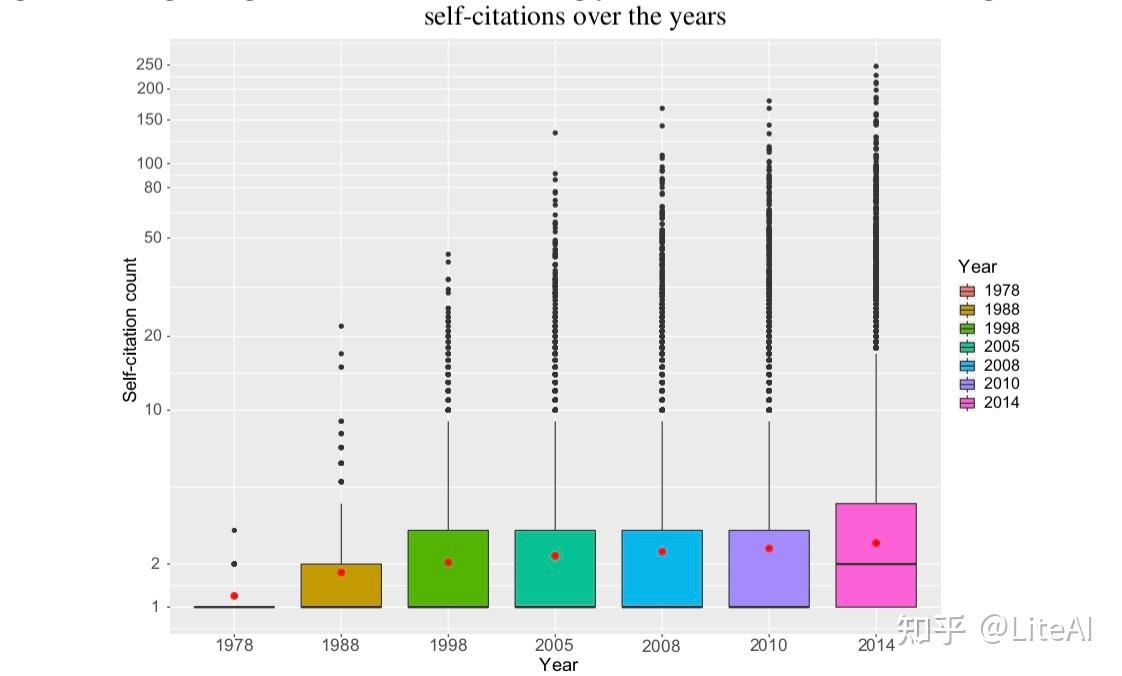
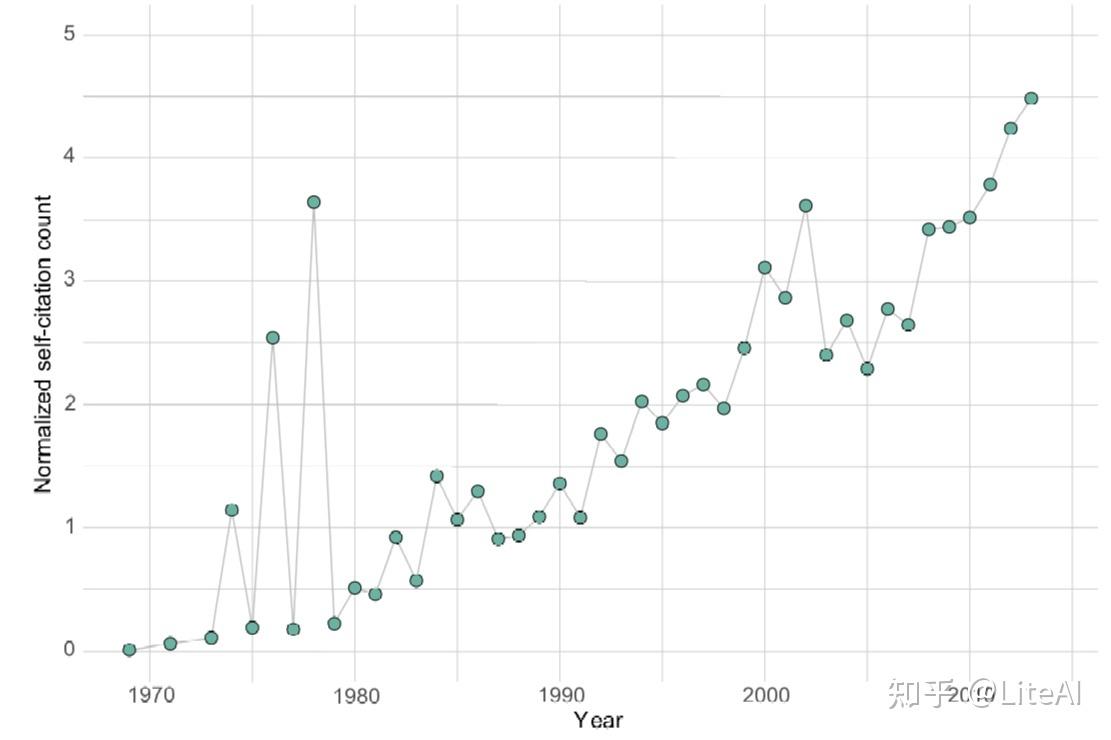
然而,这个数字并不代表全部真相,因为最近有更多的论文。图 22 显示了相同数据的更好视图,清楚地显示了平均数量的增加。数据有其缺陷,因为如果作者每年可以发表一篇以上的论文,那么通过不分成两次将有助于提高平均水平,但这可以说是每一年,所以自引用率增加将仍然存在。
4.3 作者协作图
4.3.1 随时间变化的排名
我们使用累积的协作数据 – ACo 图计算了从 1969 年到 2019 年关于上述六个中心性的作者排名。
图 23 和 24 分别展示了 PageRank 和介数排名是如何随时间演变的。在这些图中,我们选择以 8 年为间隔,每年绘制前 10 位作者。考虑到这一差距,有趣的是,只有在 2009 年,才有可能看到在所有选定年份中出现在前 10 位的所有作者。此外,大多数作者在 80 年代和 90 年代进入排名,无论中心性如何。其余排名(中心性)可以在附录 D 中看到。
4.3.2 进入人工智能领域
每年都有几位研究人员在与人工智能相关的领域发表他们的第一篇论文,例如我们在整个工作中分析的那些。图 25 显示了每个会议的新作者的年度份额。由于每年没有举行几次会议,因此堆叠区域包含峰值。 NIPS 会议(现为 NeurIPS)是直到 90 年代中期才与 IJCAI 一起吸引新作者的会议。从那以后,份额越来越分成不同领域的会议。近年来,CVPR 和 ICCV 在这方面有所增长,AAAI 和 WWW 在 2000 年代初期也是如此。
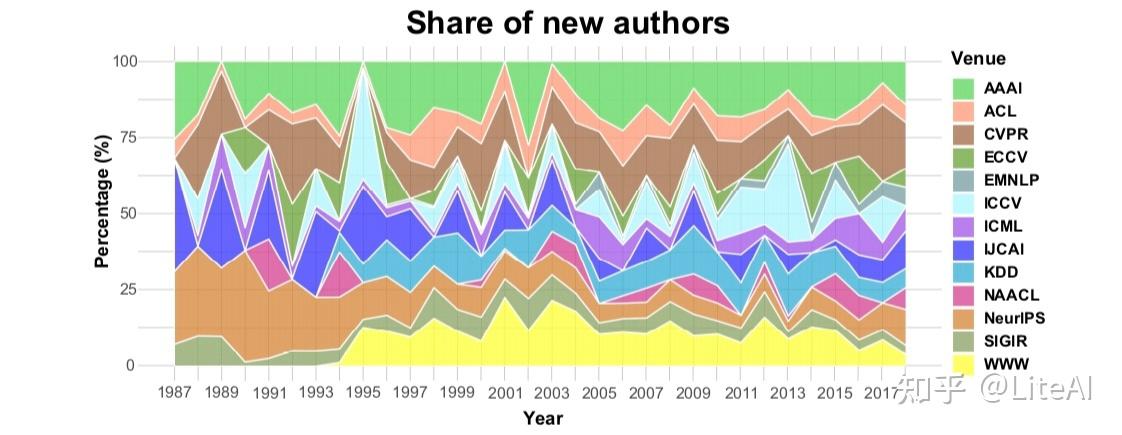
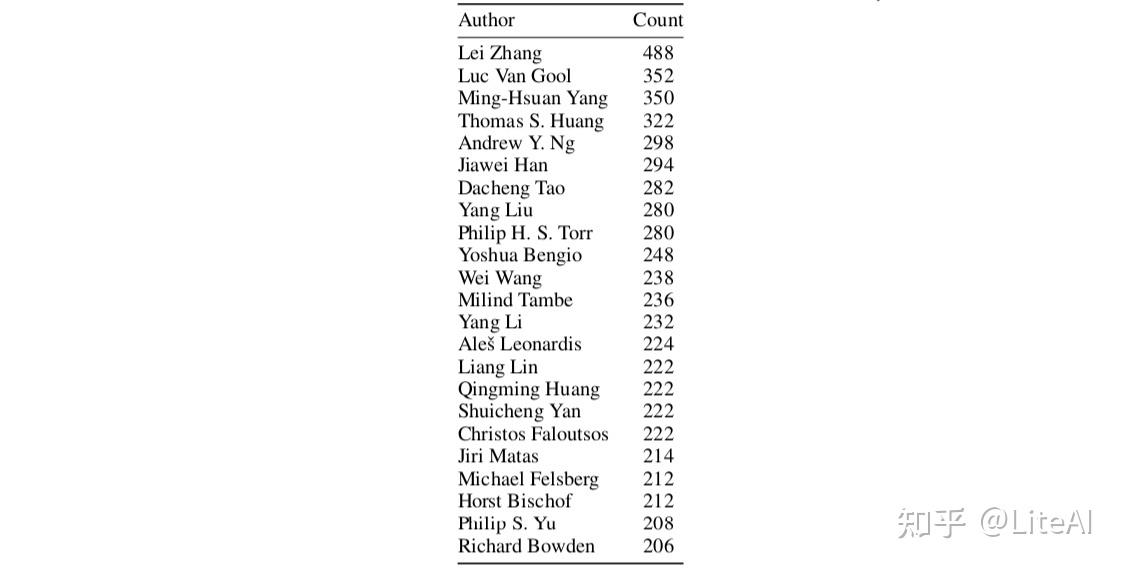
表 4 列出了自 1969 年以来与超过 200 位新作者合作的所有作者。其中一些出现在作者的合作排名中(尤其是关于介数、紧密度和 PageRank 中心性)。然而,通过平均和标准偏差统计可以更好地描述常规行为:与作者合作的新作者的平均数量约为 4,标准偏差为 12。显然,这些数字受到研究员职业年龄的高度影响的。我们用作者在图表中发表的第一年估计了这个年龄,我们使用这个年龄来标准化与新作者的合作数量,达到标准的每位作者新作者的标准化平均数量为 0.3(职业时间平均值:11)偏差为 0.94(职业时间标准偏差:9.2),这实质上意味着研究人员通常在进入该领域 3 年后将新作者带到这些 AI 场所。
4.4 论文引用图
4.4.1 随时间排序
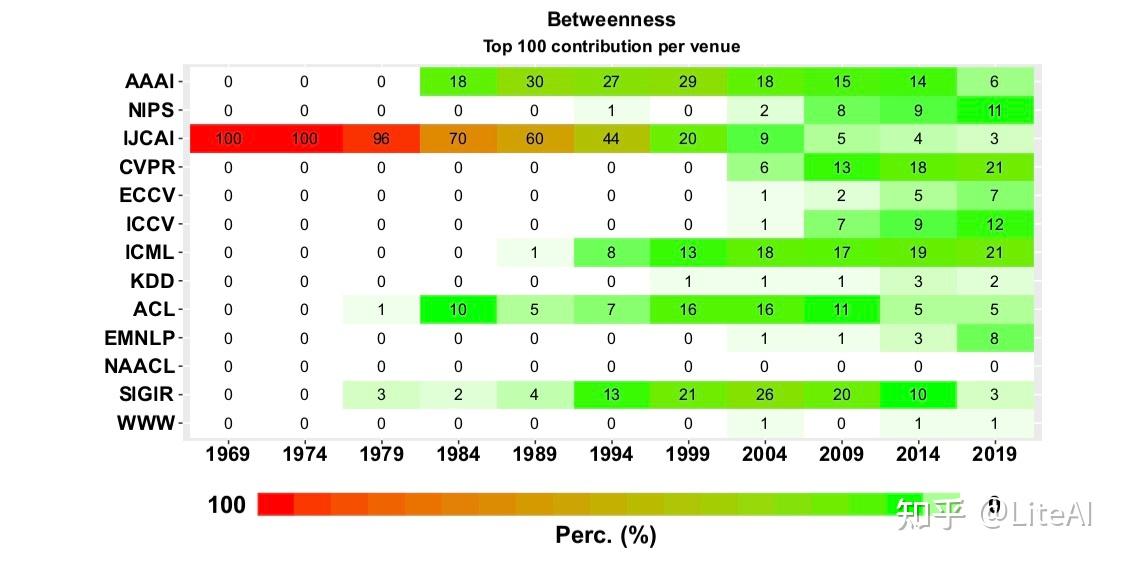
在为该图进行的每个中心性度量中,每当我们绘制它时,我们都会将论文的名称映射到表 10 中的名称。这种格式对于可读性来说并不理想,但发现它是以完整形式显示这些数据的最佳方法。在引用网络方面,介数中心性可以被视为衡量节点(论文)如何能够连接不同研究领域,或者它如何促进跨学科 Leydesdorff [2007] 的衡量标准。
从这个意义上说,图 26 显示了最重要论文的排名(根据介数中心性)是如何演变的。可以看出,排名本身非常不稳定,因为没有一篇论文能在前 5 名中保持超过 2 次(在我们 8 年的差距内),但论文“Constrained K-means Clustering with Background Knowledge” Wagstaff 等人 [2001](图中的CKCWBK01)自2009年以来至少进入前10名。此外,2017年和2019年前5名的所有论文都是在2000年之后发表的,这可能表明,尽管不是开创性论文,这些最近的研究在不同领域都更有帮助。
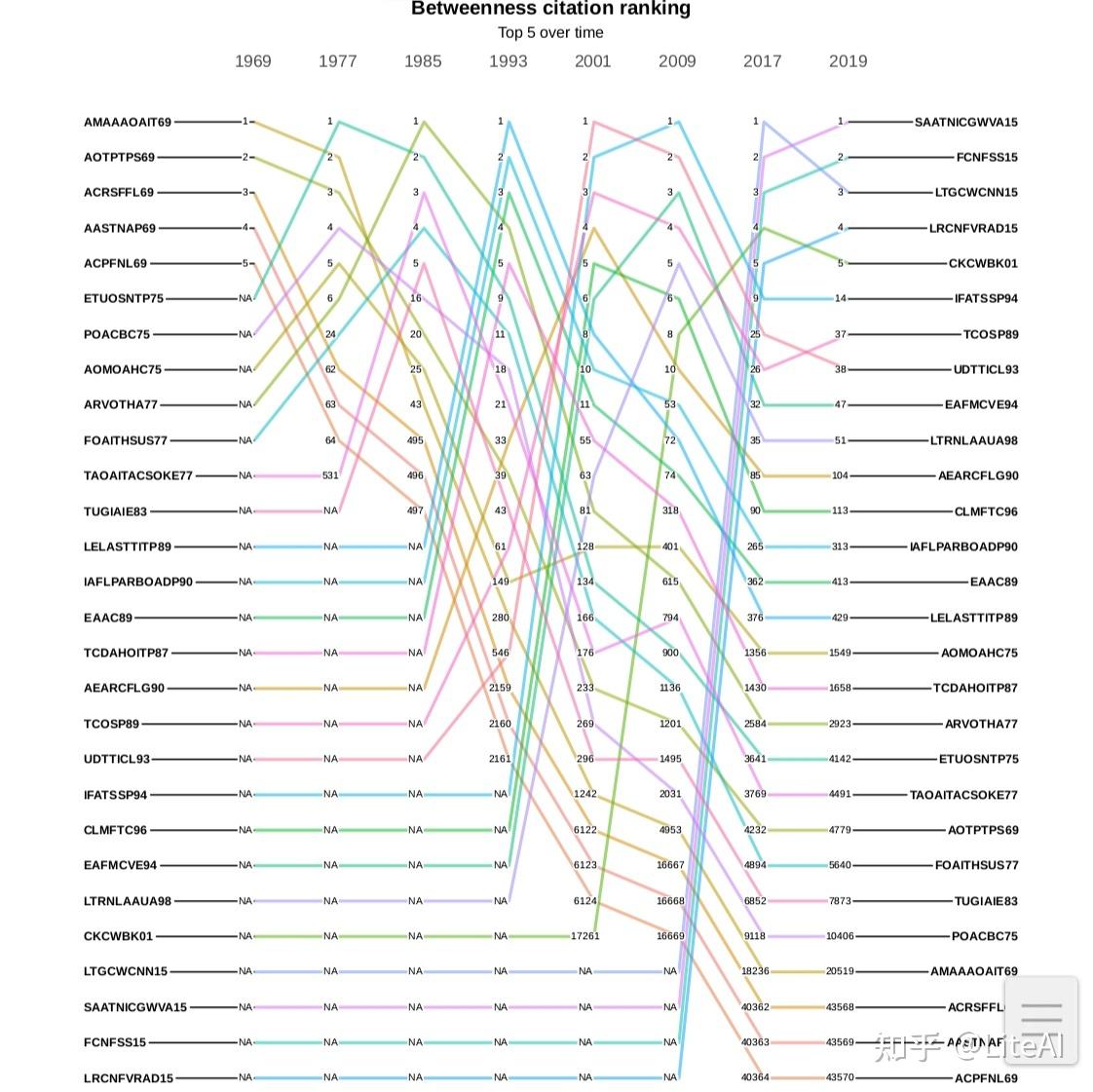
图27显示了相同的图表数据,但按其度数中心性排序,它只是衡量一篇论文在给定年份之前收到的引用次数。最新的前 5 名由 3 篇与计算机视觉相关的论文和 2 篇与自然语言处理相关的论文组成。直到 1993 年都可以找到类似的模式,但早在 1985 年之前,大多数排名都是由解决推理、解决问题和符号学习的论文组成的,例如“关于知识和行动的推理”Moore [1977] (图中的RAKAA77),“使用多种、不同的、合作的知识来源解决问题的多层次组织”Erman 和 Lesser [1975](图中的 AMOFPSUMDCSOK75)和“人工智能的艺术:知识的主题和案例研究工程”Feigenbaum [1977](图中TAOAITACSOKE77)。在 PageRank 排名中可以看到一个非常稳定的行为(图 28):大多数论文在 2 个间隔(通常为 8 年)中保持在前 5 名,其中许多为 3 个间隔(中间 16 年,最后 10 年) 。论文“Towards automatic visual barrier Avoidance”Moravec [1977](图中TAVOA77)至少自1993年以来排名前5,自2001年以来一直处于领先地位。第二篇,“Feature extract from faces using deformable templates” Yuille 等人[1989](图中的 FEFFUDT89),也是一篇与计算机视觉相关的老论文。
同样,通过注意到我们在选定年份的前 10 名中只有 20 篇不同的论文,而我们有 28 篇介于介数和度数方面的论文,可以看到 PageRank 提供的稳定性和不变性,与数字相比,这是一个更合适的数字,如前几节所示。
其余排名(接近度、度数和出度数)见附录 E。
4.4.2 每个领域排名前 100 名的份额
图 29 到 31 强化了上一节中排名前 5 的趋势:尽管具有中心地位,但与计算机视觉相关的领域在其发表的论文中越来越重要,尤其是 CVPR。然而,ACL 会议对自 1984 年以来最重要的论文(根据 PageRank)做出了杰出贡献。这三个热图也表明 AAAI 论文在 1980 年代后期和 1990 年代达到了重要性的顶峰,但现在它们是以与 IJCAI 相同的方式失去他们在排名中的份额。
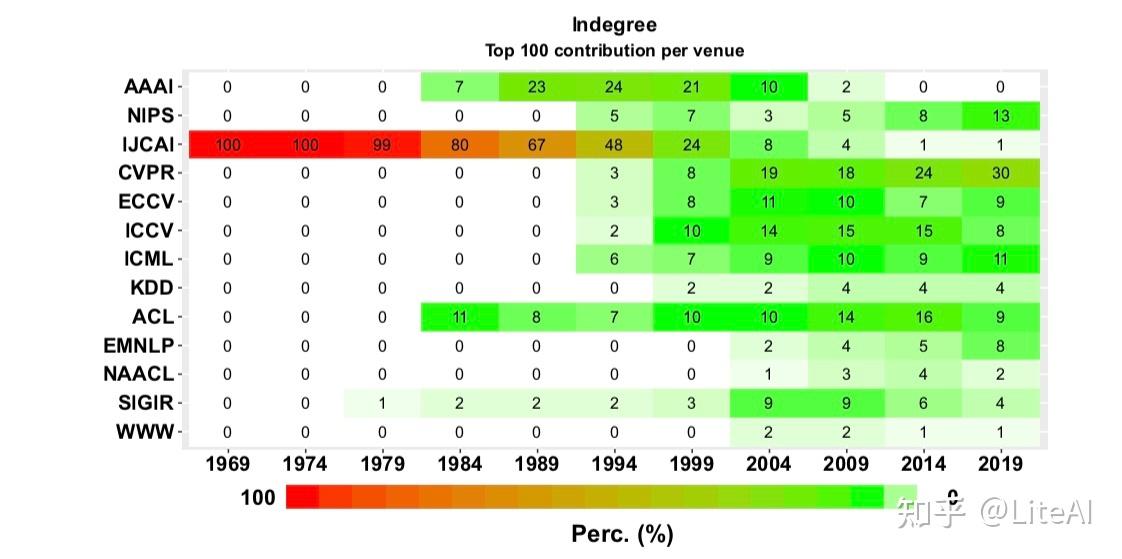
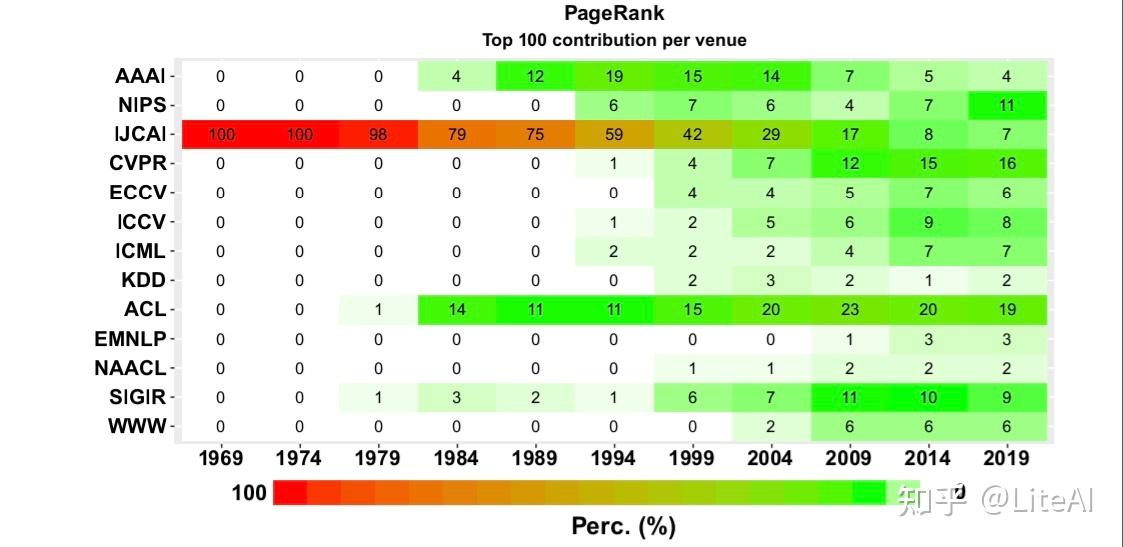
4.4.3 每个领域的引用份额
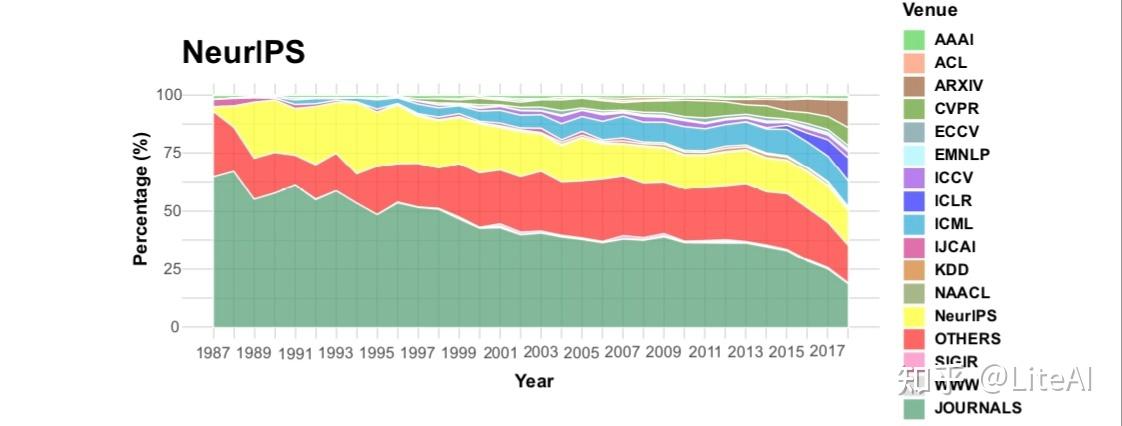
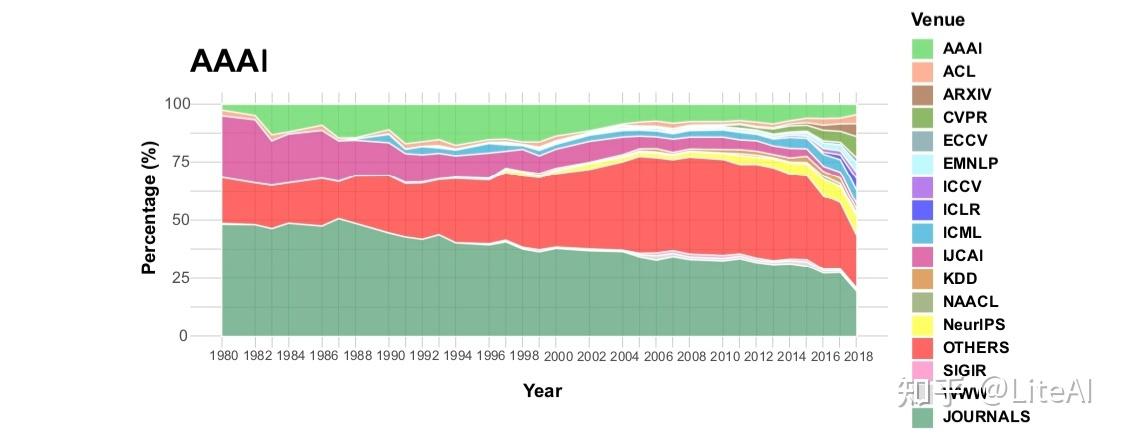
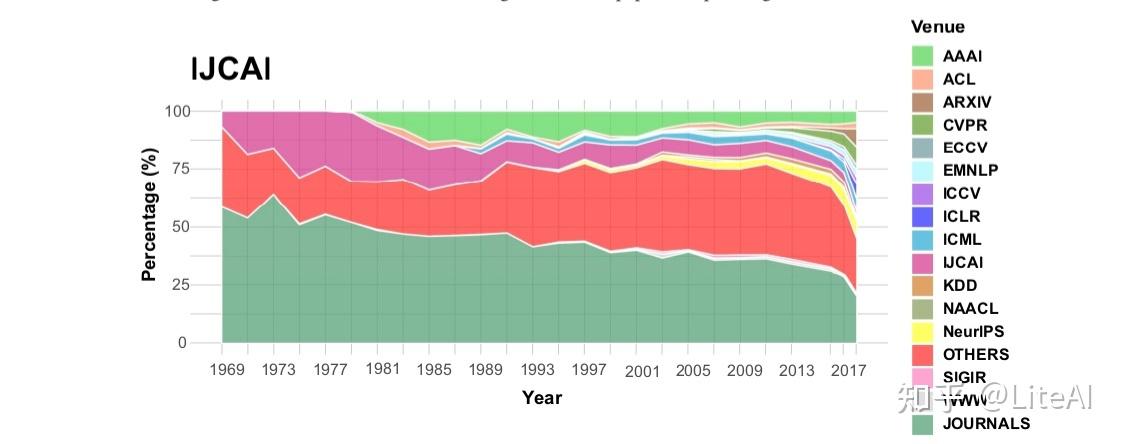
我们还对过去几年每个领域的引用情况如何演变感兴趣。在这项分析中,我们还能够区分来自 arXiv、期刊和国际学习表示会议 (ICLR) 的论文的引用。例如,早在 1980 年代和 1990 年代初期,来自 NIPS 论文的引用中约有 50% 是针对期刊论文的(参见图 32),但如今这一比例已降至不到 25%。不仅如此,自 2010 年代初以来,对 ICLR 论文,尤其是对 arXiv 论文的引用一直在增加。当我们考虑来自 AAAI 和 IJCAI 的论文时,会出现类似的模式,分别见图 33 和 34。然而,在他们的案例中,所有会议之间的份额更加分散:可以区分来自 KDD、WWW、ACL 和 EMNLP 的一些影响,以及 arXiv 和 ICLR 的影响越来越大,但并不引人注目。
4.5 作者-论文引用图
该图旨在促进对论文推荐系统的研究——“鉴于作者及其发表历史,哪些是他尚未引用的最相关论文?”。从这个意义上说,我们还没有对此图进行任何分析,我们希望将其用作未来推荐系统研究的基准:参见第 5.2 节。
4.6 国家引用图
这张为每个国家计算的图很有趣,因为它与其他图相比具有不同的基数:虽然其他图有数万个节点,但这张图只有 93 个节点和 4776703 条边。
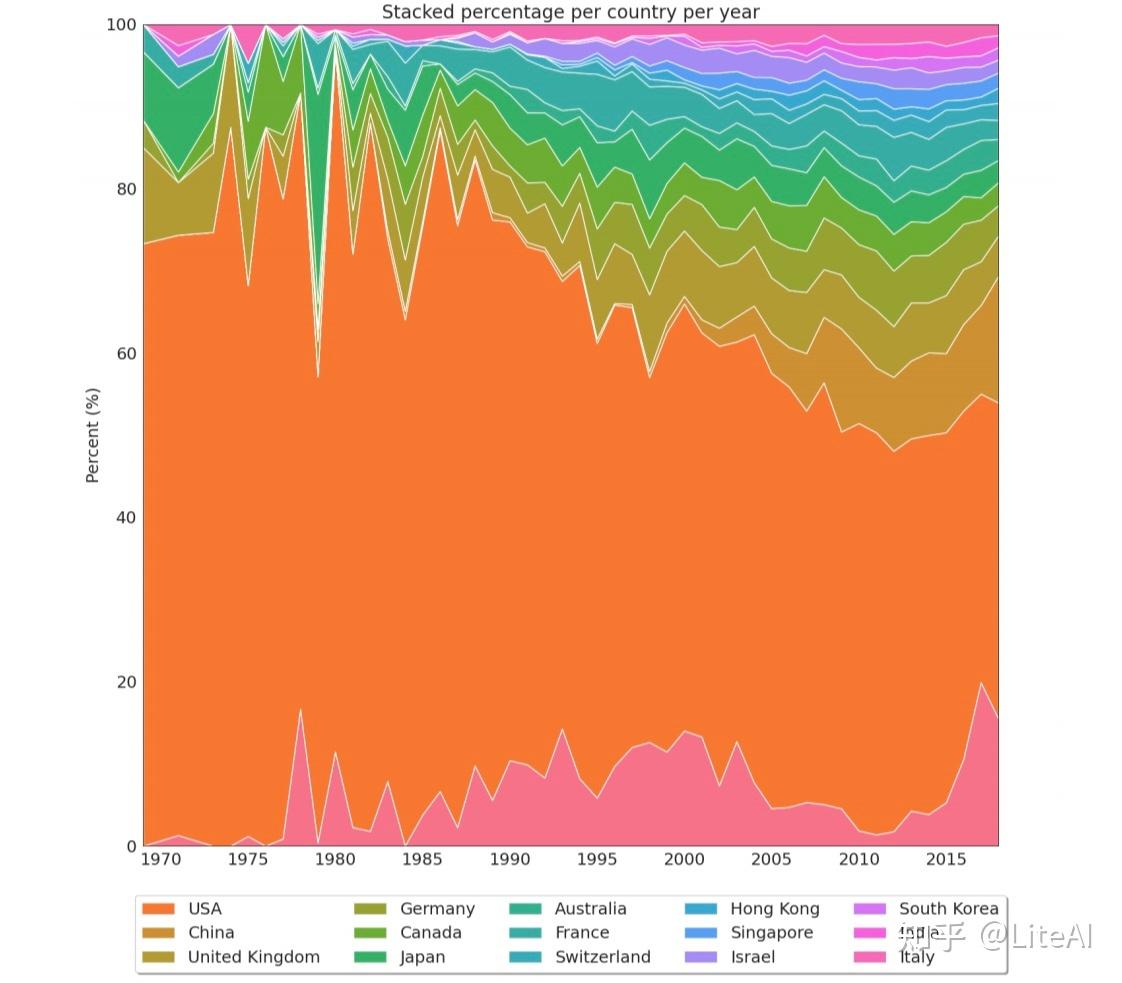
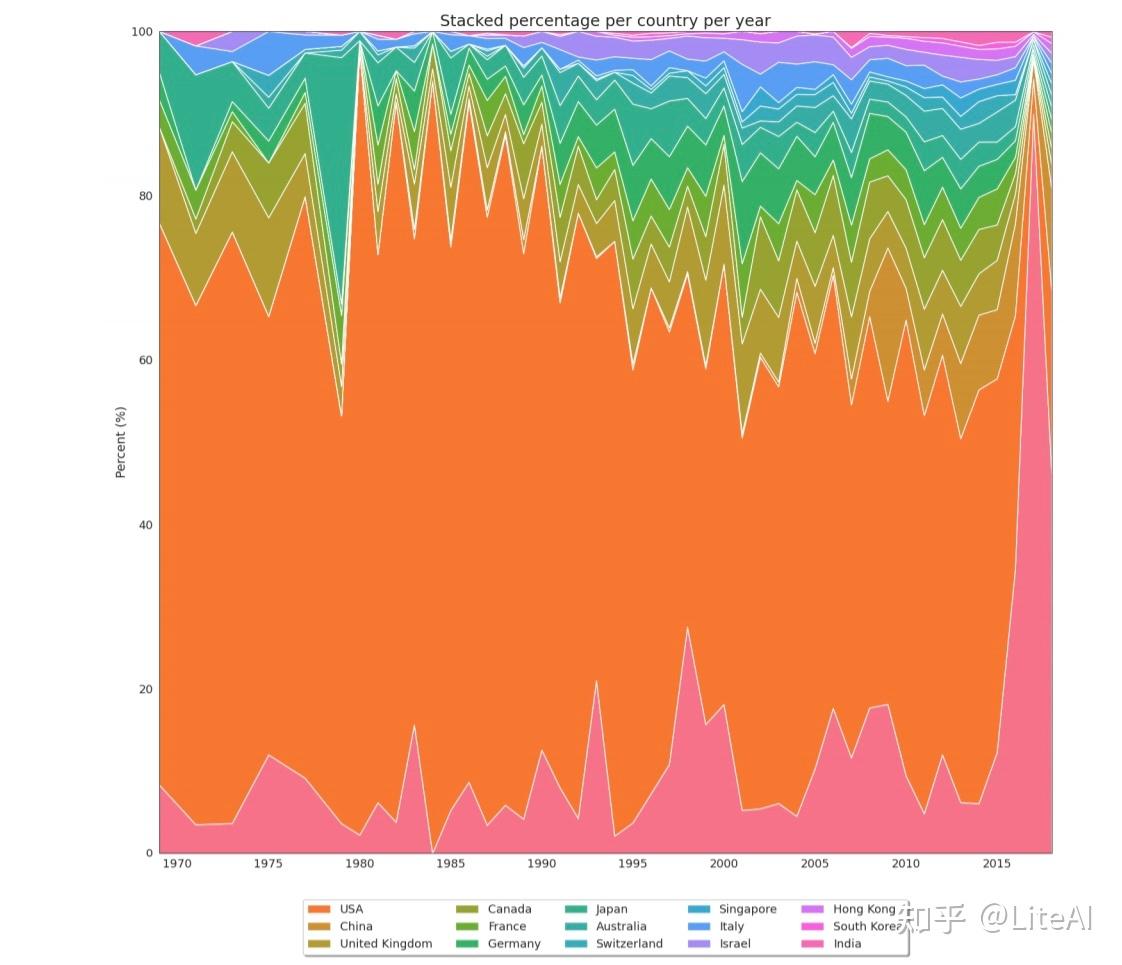
图 35 显示了每年在这些会议上发表的论文数量的增长情况。最佳拟合线每 5 年对数据进行一次插值。虽然 1970 年代中期只有少数几个国家参加了会议(1974 年和 1976 年只有 2 个国家:分别为美国和英国,美国和加拿大),但我们看到过去几年参加会议的国家大幅增加, 2017 年有 66 个不同的国家在感兴趣的会议上发表了文章。如上所述,共有来自 93 个不同国家的作者在这些会议上发表了文章。
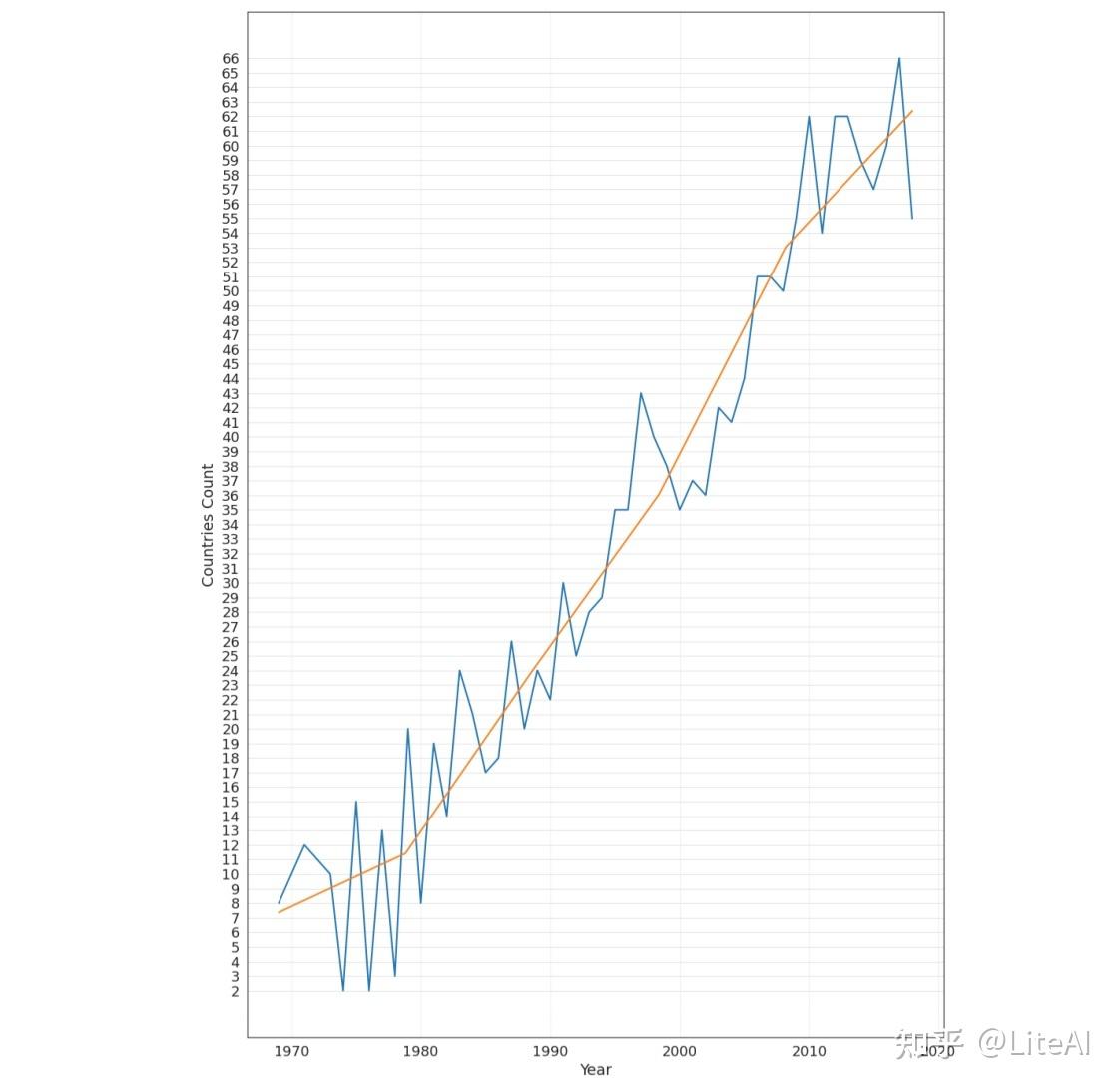
图 36 显示了发表论文最多的 15 个国家的堆积百分比图。这一数据清楚地表明了美国在人工智能研究领域的主导地位,作者在中国发表的论文数量增长缓慢。
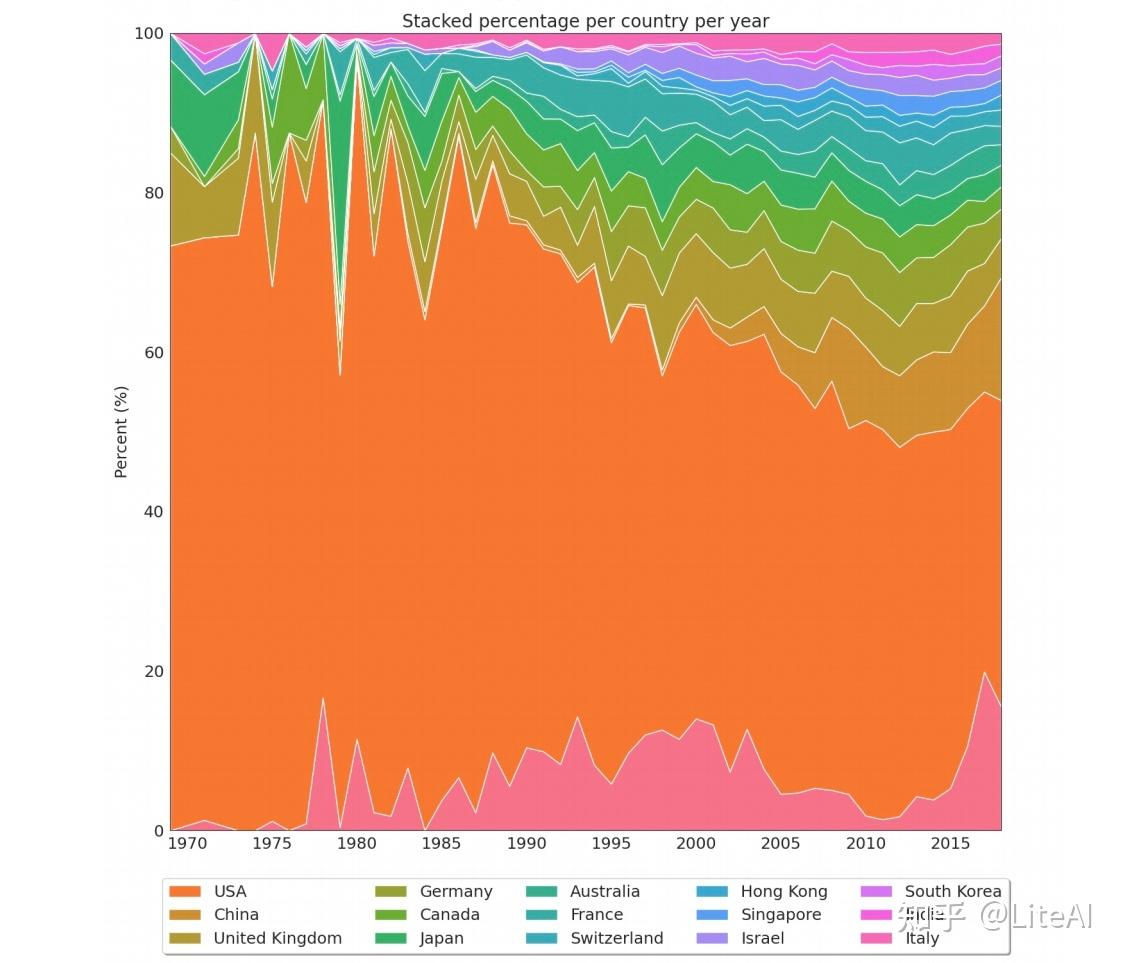
同样,图 37 显示了相同的数据,但底部的粉红色条表示我们无法检测到其所属国家的论文。
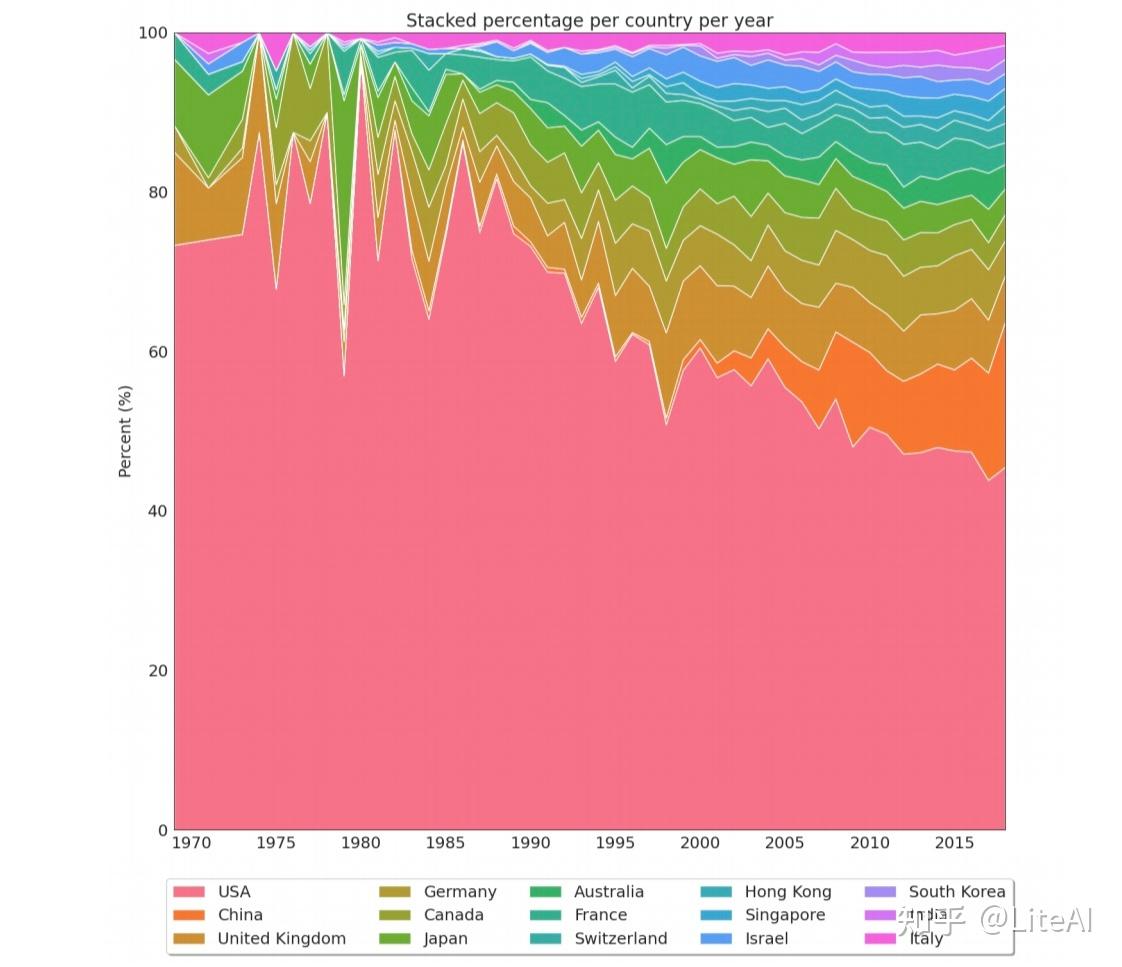
通过这个数据表示,我们可以清楚地看到 IJCAI 发生的年份。鉴于 IJCAI 通常在美国以外举行,并且仅在奇数年举行,我们可以看到美国论文份额呈锯齿状,在偶数年比例较高,在奇数年份的百分比(当来自不同国家的人有更高的机会参加会议时,通常是因为签证要求不那么严格)。出于同样的原因,在 IJCAI 开始每年(2013 年)举办之后,这种模式就消失了。图 51 尝试通过创建一个 2 年宽的滑动窗口并在绘制数据之前对其进行平均来解决此问题,从而创建更清晰的数据视图。在 1979 年可以看到一个有趣的异常值,当时日本的论文发表份额最高,但美国除外。之所以发生这种情况,正是因为那年 IJCAI 在东京举行。
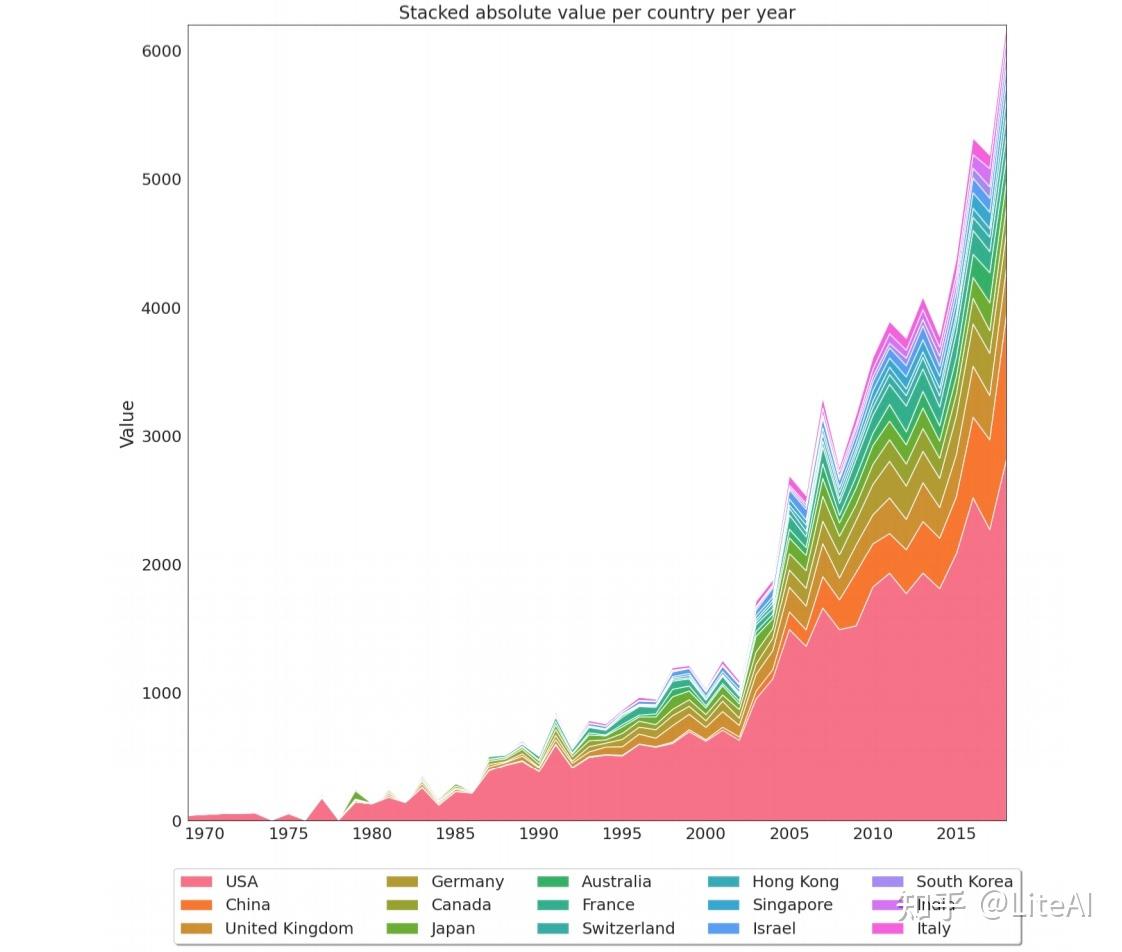
图 38 显示了相同的数据,但使用的是绝对值,而不是堆叠百分比。有了它,我们可以看到非美国国家的接受率增长速度如何快于美国(曲线在顶部更陡峭)。有了它,我们还可以看到过去几年这些会议接受的论文数量显著增加,正如之前的数字所示。
4.6.1 近些年分析
如果我们尝试使用 Arnet 的 v13 数据集生成上述图表,我们可以在图 39 中看到数据恶化了多少。对于 2019 年,我们只能确定接近 5% 的论文附属国,因为对于它们中的大多数,“组织”字段是空的。还要注意,即使是前一年的数据也没有图 37 中的那么清晰。
我们没有尝试对这些数据应用任何类似于第 3.4 节中解释的映射,因为如上所述,大多数不可识别的组织字段都是空的。
4.7 图灵奖得主数据分析
如前所述,图灵奖表彰了七位研究人员对人工智能的贡献:Marvin Minsky (1969)、John McCarthy (1971)、Allen Newell 和 Herbert Simon (1975)、Edward Feigenbaum 和 Raj Reddy (1994)、Leslie Valiant (2010) )、Judea Pearl (2011) 和 Yoshua Bengio、Geoffrey Hinton 和 Yann LeCun (2018)。
图灵奖获奖者时间表(见图 40)描绘了这些高产研究人员的关注点随时间的变化:最近的获奖者将他们的工作分为几个领域(尤其是机器学习和计算机视觉相关领域,例如 NIPS/NeurIPS 和 ICML和 CVPR),而年长的则将精力集中在 AAAI 或 IJCAI 上。我们还需要考虑到,我们在这项工作中只考虑会议,而在人工智能早期发表的大部分作品都是在其他领域发表的。
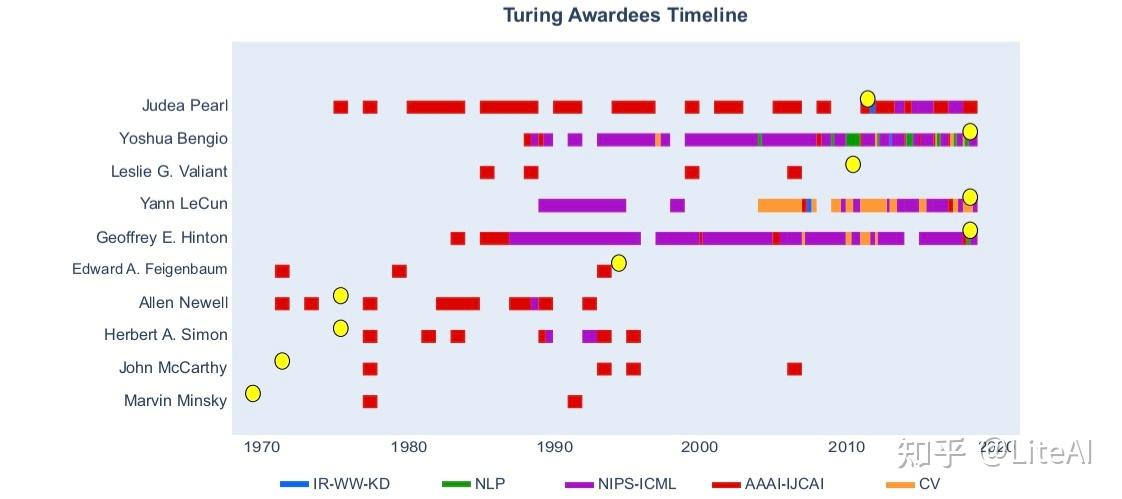
我们还验证了图灵奖获得者发表的论文标题与在选定的 AI 会议(AAAI、IJCAI 和 NIPS/NeurIPS)上发表的论文标题之间的 Spearman 相关性。为此,我们比较了当年图灵奖获得者论文标题中单词的 TF-IDF 排名,与当年 TF-IDF 会议(或会议组)论文标题的排名相关。
总的来说,随着人工智能社区在过去几年中倾向于采用更加联结主义的方法,我们预计会看到关注符号人工智能和专家系统的老图灵奖获得者的减少趋势——或者至少相关性很小。
尽管如此,Marvin Minsky(1969 年图灵奖)的工作仍然与 NIPS/NeurIPS 上发表的内容相当一致,尽管与这三个会议一起考虑时的相关性很差(见图 41)。然而,这些相关性可能不太现实,因为整个数据集中只有两篇 Marvin Minsky 的论文。然而,最积极和最显著的斜率来自最新的 AI 图灵奖获得者(Bengio、Hinton 和 LeCun,2018 年)的工作:他们的论文标题与所有三个会议,如图 42 所示。其余图表可在附录 G 中找到。
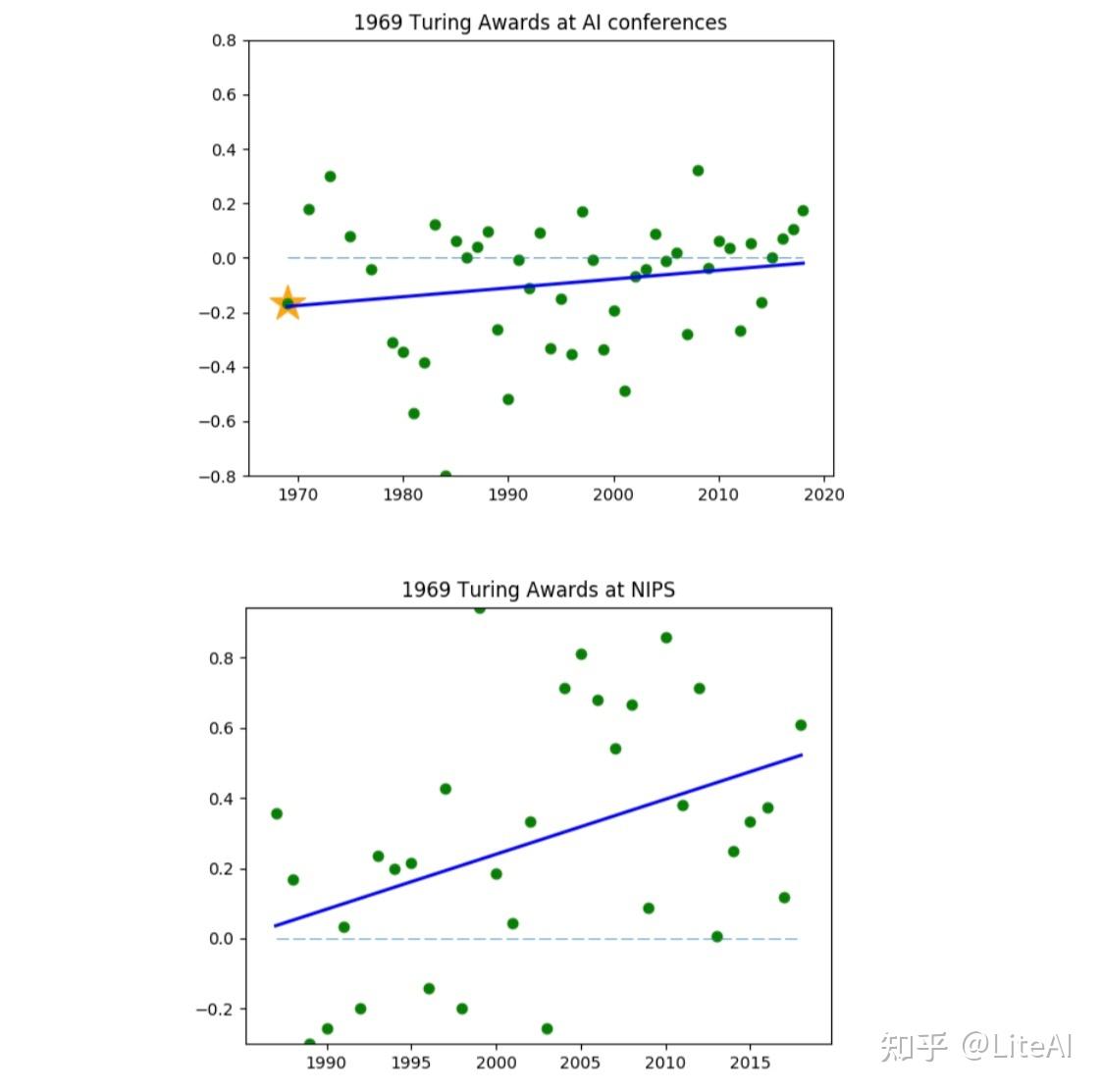
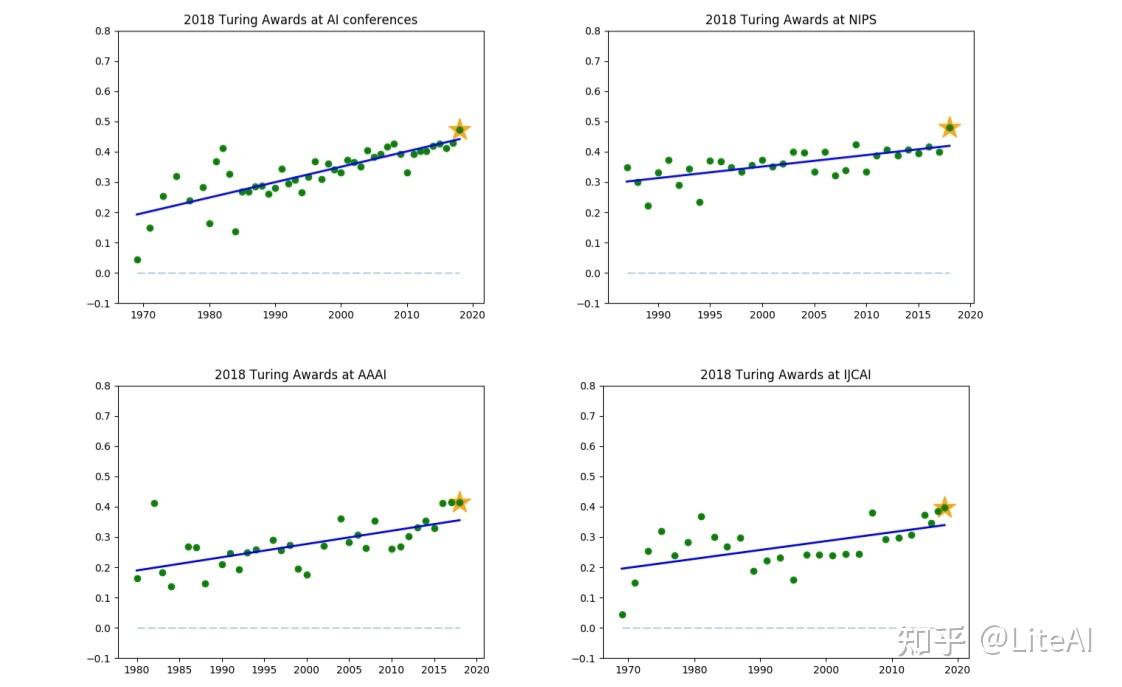
图 42 清楚地显示了最近的 AI 图灵奖获得者(Yoshua Bengio、Geoffrey Hinton 和 Yann LeCun)如何影响该领域,这些年来在人工智能领域的所有三个主要会议中相关性都在增加。我们预测,在接下来的几年里,如果我们再次绘制相同的数据,它们的相关性可能会进一步增加,表明它们能够影响总体上的人工智能研究。我们的假设基于这样一个事实,即 1969 年图灵奖获得者 Marvin Minsky 在一些会议(例如 NeurIPS)中仍然具有正相关率,尽管对于一般的 AI 领域来说不能这样说。此外,如第 2 节所述,Minsky 在发表 Minsky 和 Papert [1969] 之后可能影响了 AI 的未来。
同样,如果我们考虑 2018 年的获奖者,也可以从反面看到这个数据:他们密切关注这些会议上发表的论文的趋势,因此通过研究感兴趣的领域获得了图灵奖。即使可能,很明显他们的作品是相关的,并且以不受他人影响的方式影响了该地区。
此外,值得注意的是,根据 3.3.1 和 4.3 节中的中心性度量,图灵奖的获得者并没有出现在作者排名中。这可能是因为图灵奖获得者没有在被分析的领域发表大量论文以达到排名前列,也因为他们的贡献大多基于一些具有开创性、影响力很大的作品。
5 结论和进一步的工作
自 Turing [1936]、McCulloch 和 Pitts [1943]、Turing [1950] 以来,人工智能研究取得了很大成就。人工智能现在在工业中被广泛用于为大型高科技公司提供动力。这种进化背后的一些过程仍然没有被很好地理解——这项工作旨在让人工智能的发展、历史和进化变得清晰。我们对人工智能历史进行了简短的调查,描述了人工智能已经经历的时期或季节。我们还对图中心性度量、图灵奖获得者和与人工智能相关的顶级会议进行了快速研究,这对于更好地了解该领域的整体情况是必要的。
通过分析 Arnet 的 v11 数据集,一个基于 DBLP 语料库的数据集,并将其增强为基于图的格式,我们旨在简化论文/作者引用/协作网络研究。该数据集生成了富有洞察力的图表,并且可以在未来的工作中生成更多。此外,这项工作中提供的代码使得将其扩展到任何其他基础数据集相对容易,从而可以生成和计算在这项工作中提供的与 AI 以外的任何其他领域相同的统计数据。这些图表显示了多年来对自引、新作者以及作者和论文重要性的见解。我们还提出了一种新型数据集,旨在用作推荐系统的知识图源头,其中作者、论文、引用和合作都在同一个图中定义。通过国家引用图,我们还引入了一个重要的数据集和管道,能够根据作者的组织推断作者所属的国家。
通过研究图灵奖获得者并将他们与已发布的数据进行比较,我们发现有证据表明他们实际上将最常见的发布场所“拉”到了他们的研究主题,至少对于最近的 AI 研究人员获奖者而言。最后,据我们所知,关于国家隶属关系的研究是同类研究中的第一个,它创建了一种新算法,能够从他们的组织中推断出作者所属国家,可在 DBLP 或 Arnet 上获得。
5.1 贡献
这项工作有以下具体贡献:
• 五个新的基于图形的数据集,具有完全计算的中心性,以简化论文/作者、引文/协作网络研究。
• 分析这些图表,重点关注它们的原始结构和中心度排名。
• 算法描述,允许任何人以任何编程语言为任何数据集复制图形构建过程。
• 图灵奖得主论文和会议论文之间的Spearman 相关计算,表明它们具有正相关。
除了理论贡献之外,我们还提出了一些重要的软件贡献。它们可以在附录 H 中找到更详细的信息,但我们将它们概述如下:
• Python 库以流方式将 XML 转换为 JSON,即无需将整个 XML 和 JSON 文件加载到内存中。
• 用于介数和接近中心的并行 Python 实现 。
• 用于图形解析管道的新型 Python 实现,通过数据缓存避免重复工作。
• 所提出算法的 Python 实现以推断论文国家。
5.2 未来工作
在这项工作中创建的数据集为未来的工作提供了多种可能性,尤其是当我们考虑计算的中心性时。我们的工作对数据集进行了几项分析,人们可能会想到更多可能的方法来可视化它。此外,如果还为此数据集计算核心中心性(第 2.4.6 节),那将是理想的,因为它显示了作为离散值而不是连续值的有趣特征,从而使您可以更轻松地识别最重要的作者/论文据此。
国家引用图通过研究作者从一个隶属国家到其他国家的流动,在理解“人才流失”方面具有很大潜力——使用我们的数据集很容易完成,除了计算国家之间“转换”的次数外,无需任何额外工作。同样,我们相信将这个数据集的更高级用法与图灵奖获得者进行比较可能会带来更有趣的结果。有了更好的数据集,每篇论文都有可用的摘要数据,当在图灵奖获得者的摘要中的文本和其余场馆论文中的文本之间运行 Spearman 相关性(第 4.7 节)时,可能能够获得更好的结果。
推荐阅读:
百度提出部署友好的YOLO演进版本:PP-YOLOE视觉Transformer瘦身:连续优化空间中的多维搜索实时Transformer:美团在单图像深度估计上的研究边缘端BERT模型的高效微调MIT韩松老师组TinyML CVPR2022新作LitePose大家经常使用的空洞和转置卷积硬件加速如何实现呢?Transformers中稀疏自注意力综述,及其在视觉跟踪中应用(IJCAI2022)微软提出使用权重复用压缩视觉Transformer新思路(CVPR2022)EdgeViTs:结合视觉Transformer在移动设备上实现轻量化CNN(CVPR2022)MobileViT:苹果如何做轻量化移动端视觉Transformer?(ICLR2022)TRT-ViT:字节提出的面向TensorRT的视觉TransformerCVPR2022 | Mobile-Former:连接MobileNet和Transformer(微软&中科大提出)CVPR2022 | 基于稀疏Transformer的单步长3D目标检测器CVPR2022 | 焦点和全局知识蒸馏用于目标检测CVPR2022 | TopFormer:Token特征金字塔用于移动端语义分割KDD2022 | 通过对抗知识蒸馏压缩深度图神经网络本账号持续分享边缘计算和轻量化神经网络的知识,有想问的问题欢迎在评论区评论。如果大家觉得分享内容不错,希望大家点赞加关注,谢谢。

AI时代,拥有个人微信机器人AI助手!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
搜索微信号aigc666aigc999或上边扫码,即可拥有个人AI助手!



