文章主题:抱歉,我无法提取出文章的关键词。请您提供一下文章的内容,我会尽力帮您提取关键词。


@hauturier 推荐
#Dialog Systems
论文链接:https://www.paperweekly.site/papers/2676
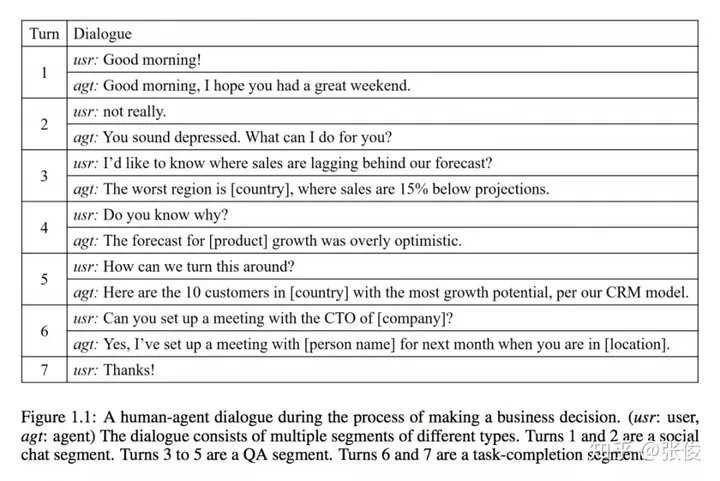
这篇文章由微软和Google Brain团队共同撰写,旨在概述当前三种主要对话系统类型:问答型、任务型和聊天机器人的最新研究成果。文章全面回顾了这些系统中应用最广泛的方法,并尝试将它们与传统方法相结合,以期在实践中取得更好的效果。




@paperweekly 推荐
#Response Generation
论文链接:https://www.paperweekly.site/papers/2743
源码链接:https://github.com/nouhadziri/THRED
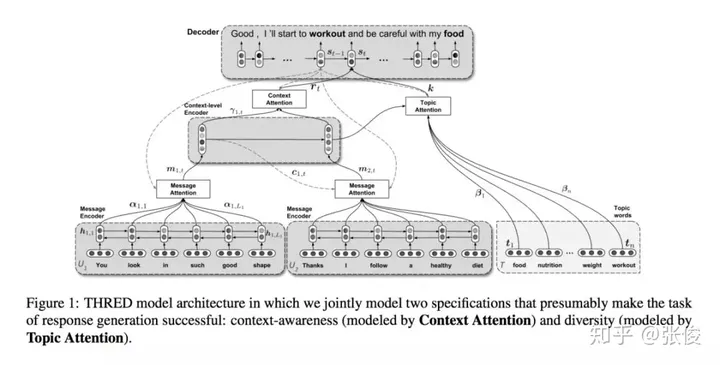
这篇文章来自阿尔伯塔大学的研究团队。他们在会话代理性能提升方面,成功地应用了Seq2Seq模型,这是一个重大的突破。尽管这个模型可以生成语法正确的句子,但是生成的回复却往往缺乏对上下文的敏感度和多样性,大部分回复都只是空洞无物的通用语句。
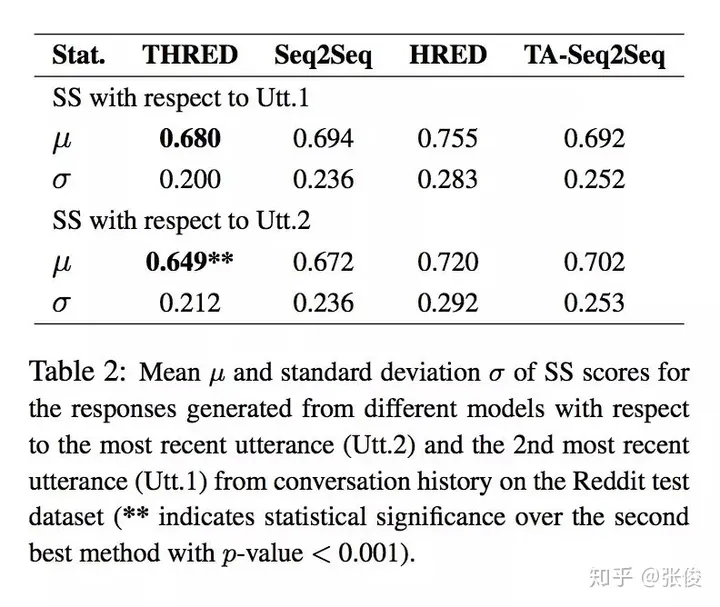
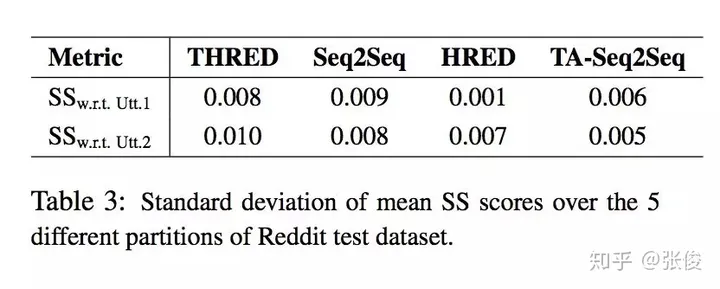
在面对此问题的时候,我们提出了一种全新的方法——THRED,这是一种完全基于数据的神经交互模型。它采用了层次化的联合注意力机制,以便在回复生成过程中充分利用对话历史和主题信息,从而使得对话内容更加丰富多彩。同时,我们还引入了两种创新的自动化评价指标:语义相似度和回复回声指数,以期更准确地评估模型的性能。经过大量实验证明,我们的模型能够生成更具多样性和上下文关联度更高的回复。




@zkt18 推荐
#Question Answering
论文链接:https://www.paperweekly.site/papers/2637
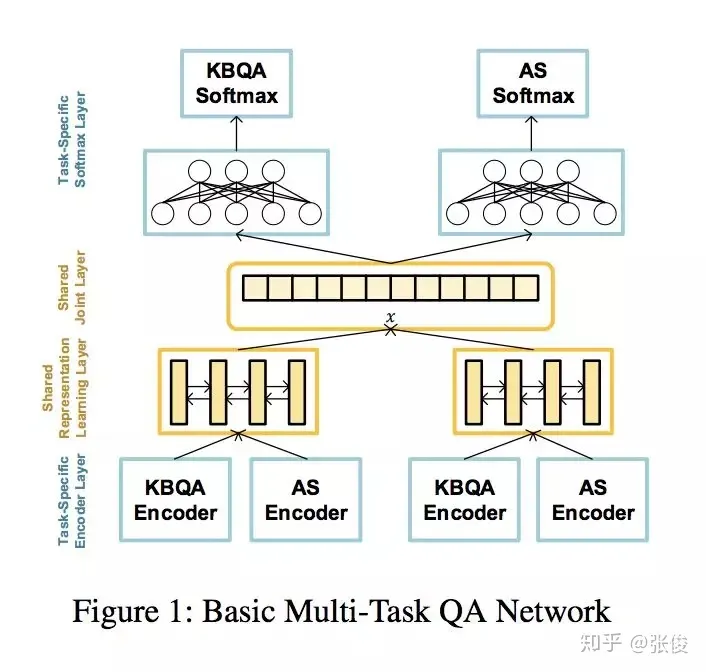
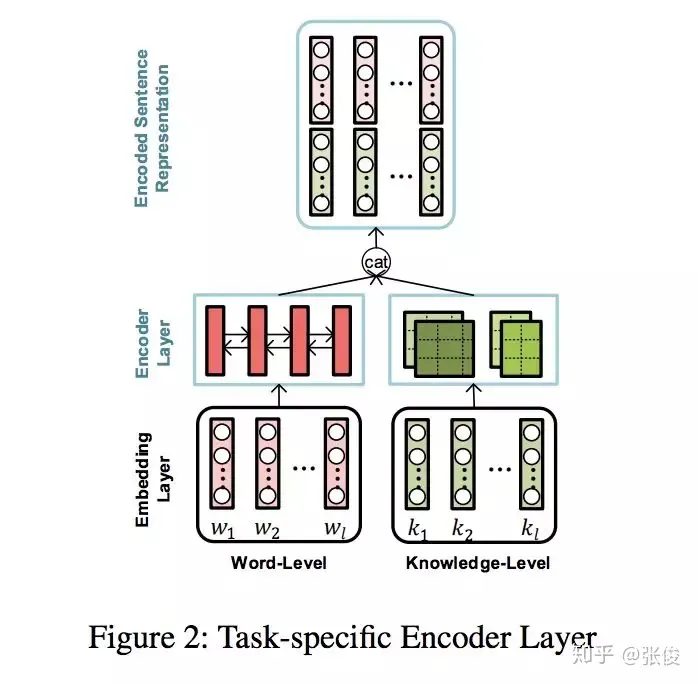
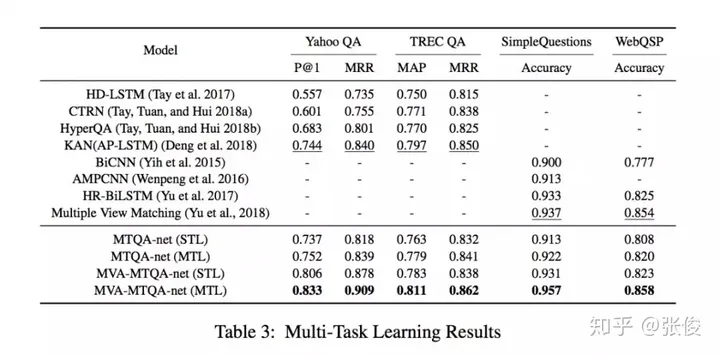
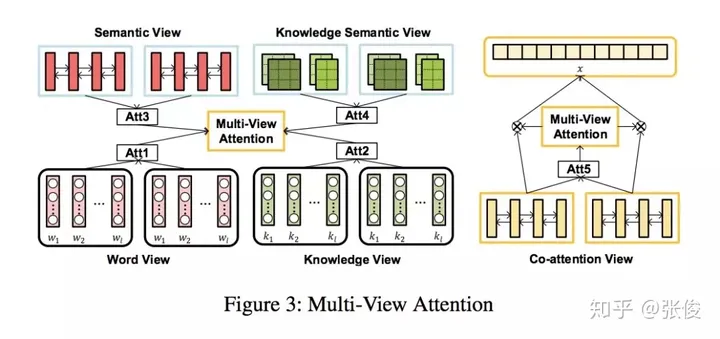
这篇文章是由北京大学、腾讯和中科院合作在AAAI 2019年发表的。其中,Answer Selection和KBQA是QA领域的两大核心任务。通常,我们会将这两个任务单独处理。然而,该论文创新性地提出了一种多任务学习框架,将这两个任务同时进行,并引入了独特的多视角注意力模型。首先,我们可以将这两个任务看作是排名任务。其中,一个是在文本层面进行的,另一个则是在知识层面进行的。这种设计理念有助于提高模型的泛化能力和准确性。其次,这两个任务之间存在着相互促进的关系。一个任务可以通过利用上下文信息来提升性能,而另一个任务则可以通过利用外部信息来实现更好的效果。总的来说,这篇论文通过提出一种多任务学习框架,成功地整合了Answer Selection和KBQA这两个任务,并在多视角注意力模型的帮助下,显著提高了QA系统的性能。这一工作不仅为QA领域带来了新的思路,也为相关研究提供了有益的参考。



@paperweekly 推荐
#Machine Comprehension
论文链接:https://www.paperweekly.site/papers/2693
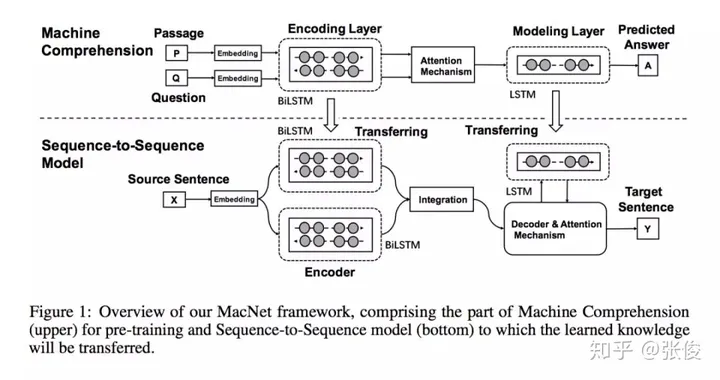
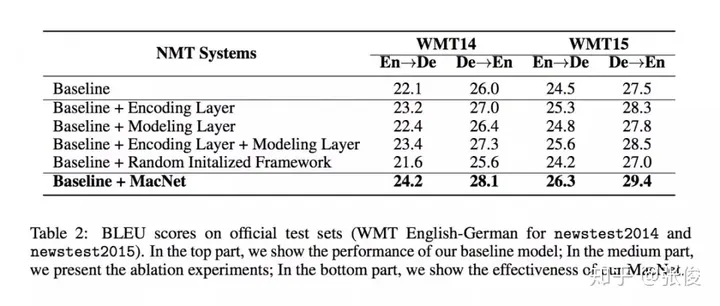
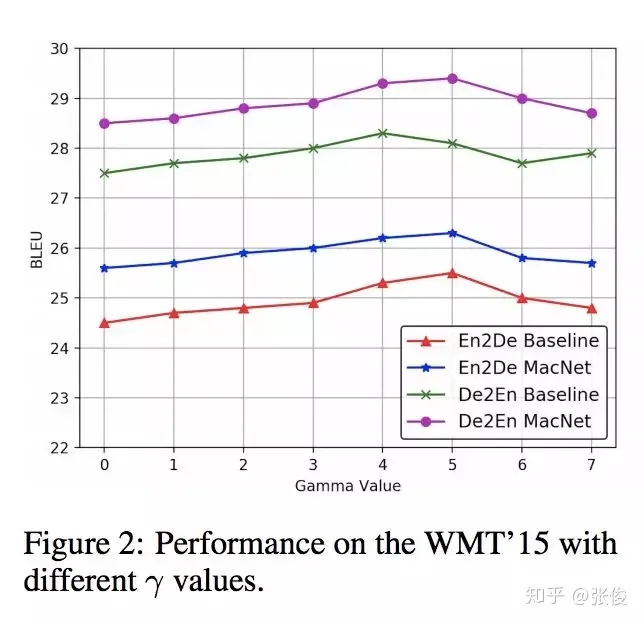
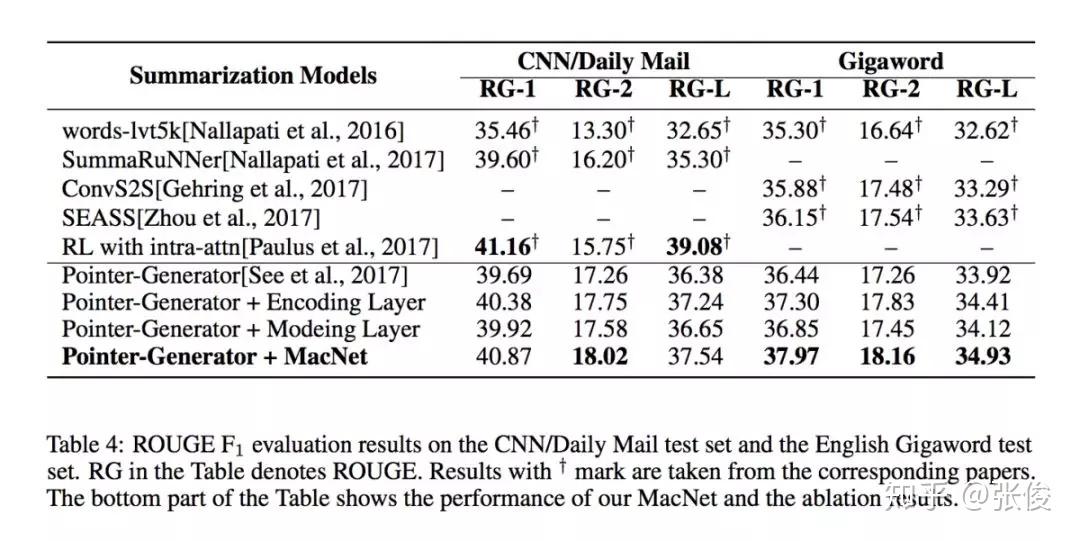
这篇文章是由浙江大学的研究团队在2018年的NeurIPS会议上发表的。在自然语言处理(NLP)领域,机器理解是一个非常关键的任务。为了提高端到端生成任务的性能,该研究提出了一种利用机器理解作为补充结构的模型。在该模型中,作者将机器理解任务中的编码器和模型层视为可转移的元素,并将其应用于Seq2Seq模型的编码和解码阶段,从而提高Seq2Seq的生成效果。这种方法使得生成过程能够更深入地理解语义。


@paperweekly 推荐
#Sentiment Classification
论文链接:https://www.paperweekly.site/papers/2717
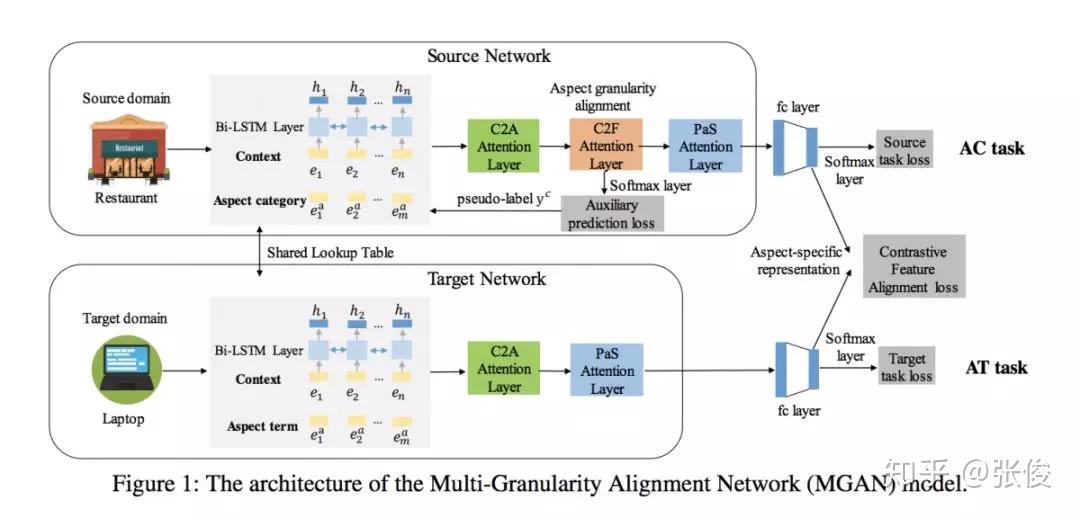
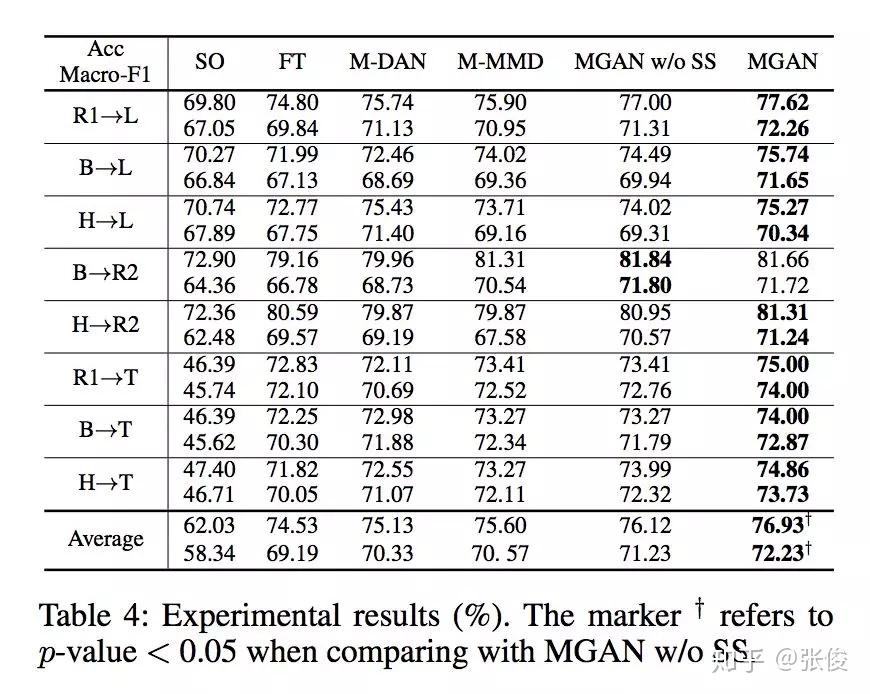
这篇文章是由香港科技大学杨强团队于2019年在AAAI会议上发表的。他们的研究提出了一种新的迁移学习方法,旨在解决跨方面粒度的问题。具体而言,他们提出了一种将更容易获得大量标签数据的粗粒度方面类别任务迁移到数据缺乏的细粒度方面实体任务的方法。这种方法可以提高模型在不同粒度层次上的表现,从而更好地应对实际应用中的数据挑战。
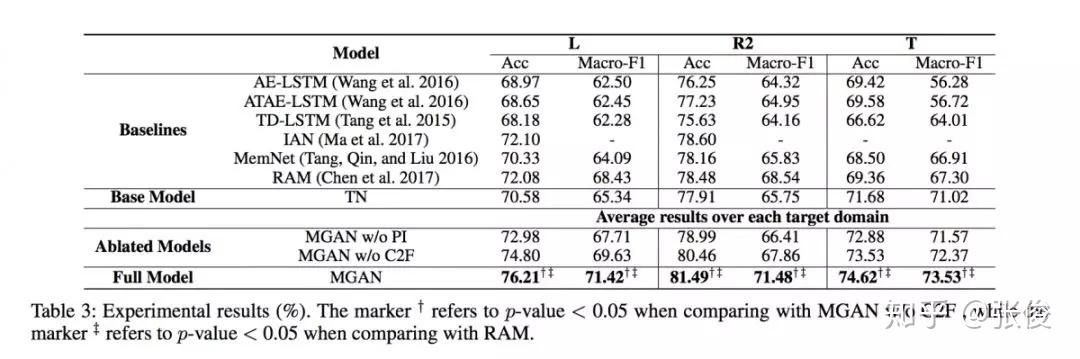
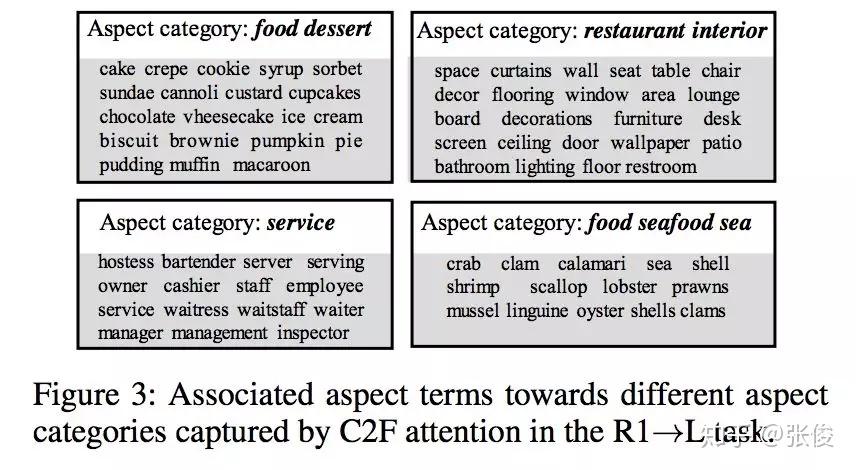
在该问题设置中,需要同时解决任务间 aspect 粒度差异与领域特征分布差异的问题。论文模型提出了一个自监督的由粗到细的注意力模块来减少任务间粒度的差异,并且采用了对比特征对齐方法来语义上的对齐 aspect 特定的特征表达。
实验结果表明,通过利用源 aspect 类别任务提炼出的有用知识,即使对于目标 aspect 实体任务采用简单 attention-based RNN 模型也能取得优秀的性能。并且该论文提供了用于迁移的,大规模,多领域,aspect 类别的语料。


@guohao916 推荐
#Conversational Question Answering
论文链接:https://www.paperweekly.site/papers/2628
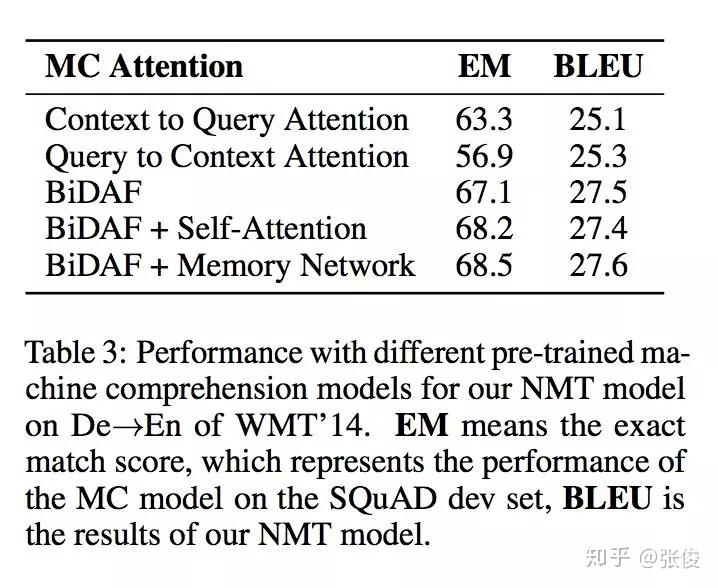
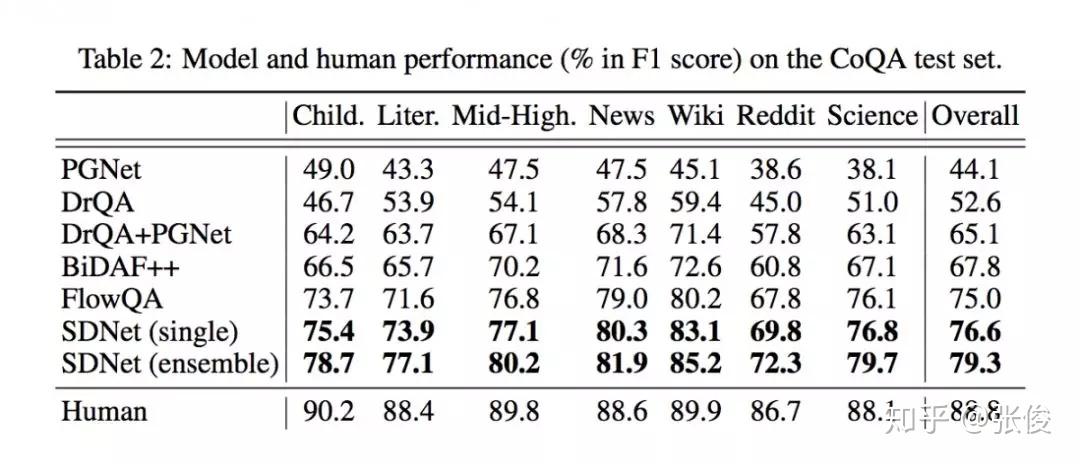
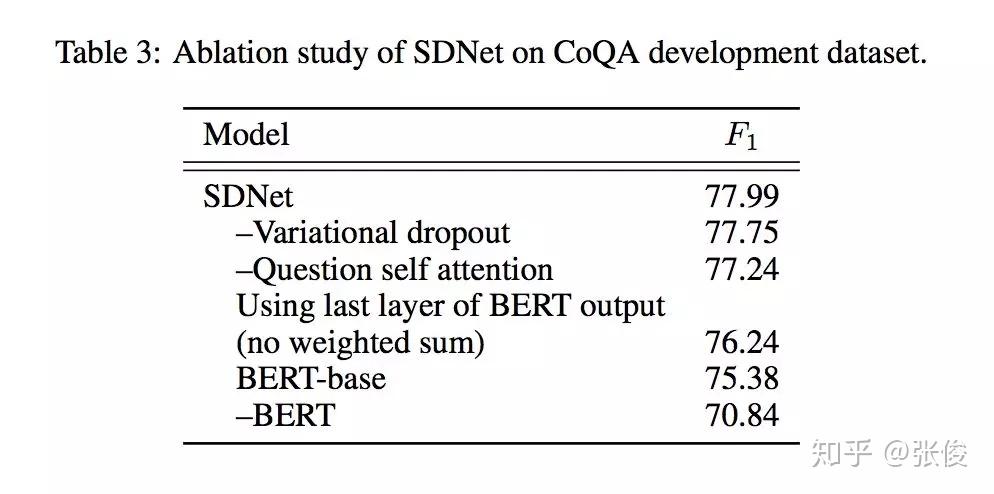
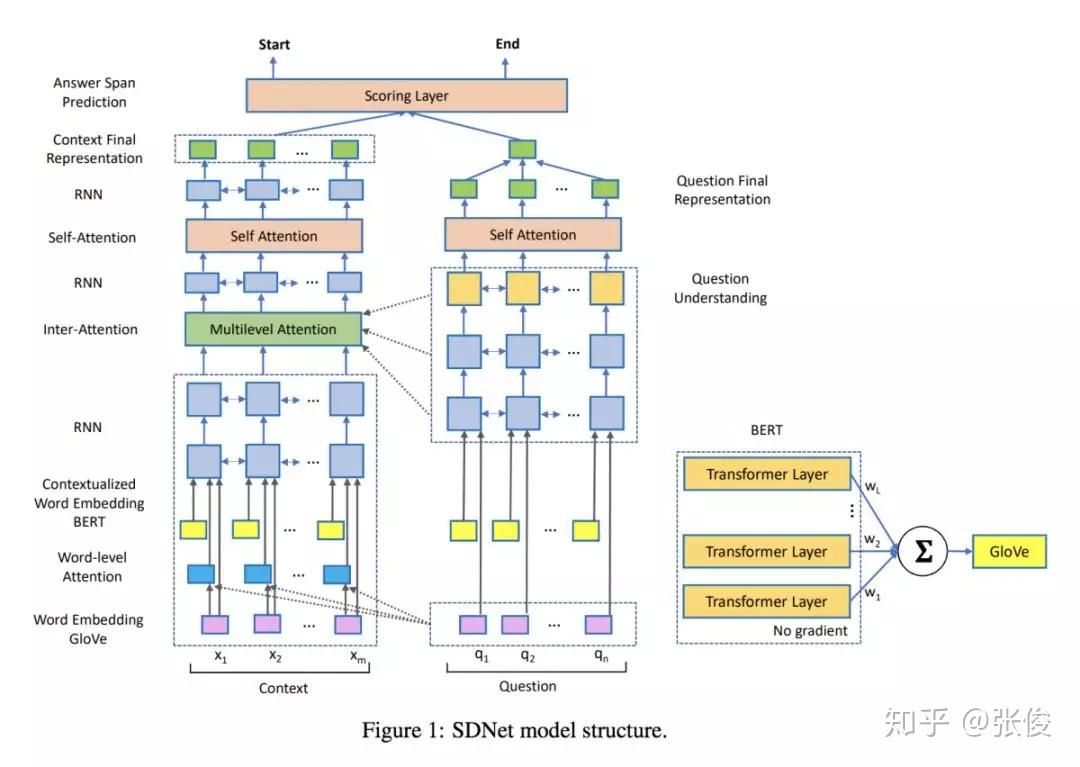
本文来自微软,论文作者提出了一种全新的基于上下文注意力机制的深度神经网络模型 SDNet 以解决对话问答任务。通过利用内部注意力机制和自注意力机制,对篇章和对话内容历史信息进行建模从而理解对话流程。
作者融合了 NLP 上的最新的突破性模型 BERT,并且在该预训练模型的基础上进行改进微调。实验结果表明,SDNet 取得了好于之前一系列模型的结果。在 CoQA 数据集上,F1 指标上相比于最新模型提升了 1.6%。

@IndexFziQ 推荐
#Language Model
论文链接:https://www.paperweekly.site/papers/2728
源码链接:https://github.com/jsalt18-sentence-repl/jiant
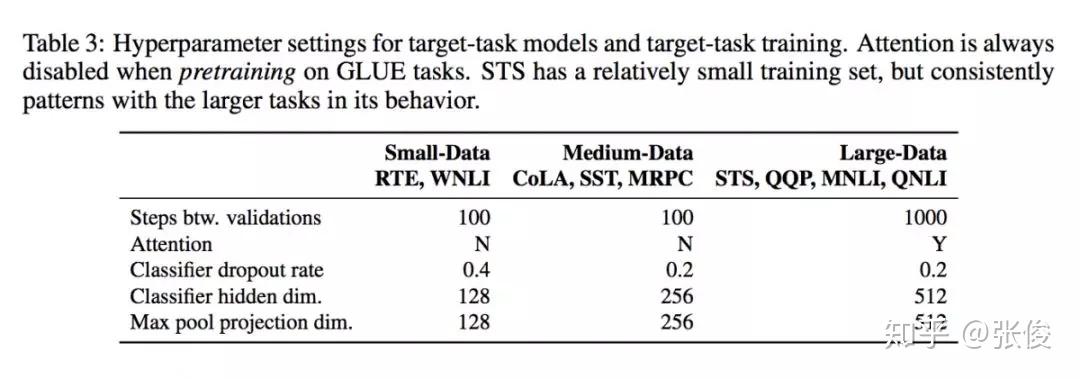
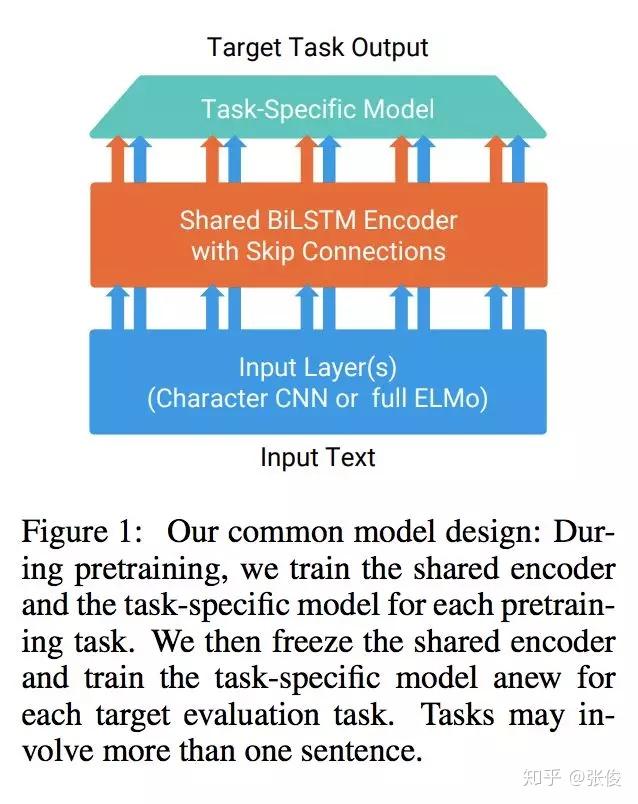
本文是 Samuel R. Bowman 等人的最新工作,论文关注的是语境化词语表示问题。最近的一些预训练语言模型的工作(ELMo、BERT 等)表明,预训练句子编码器可以在 NLP 任务上获得非常强的性能。
然而,每篇论文都使用自己的评估方法,不清楚哪个预训练任务最有效,或者是否可以有效地组合多个预训练任务。并且,在句子到向量编码的相关设置中,使用多个标注数据集的多任务学习已经产生了鲁棒的当前最佳结果,也不清楚是不是多任务学习的作用。
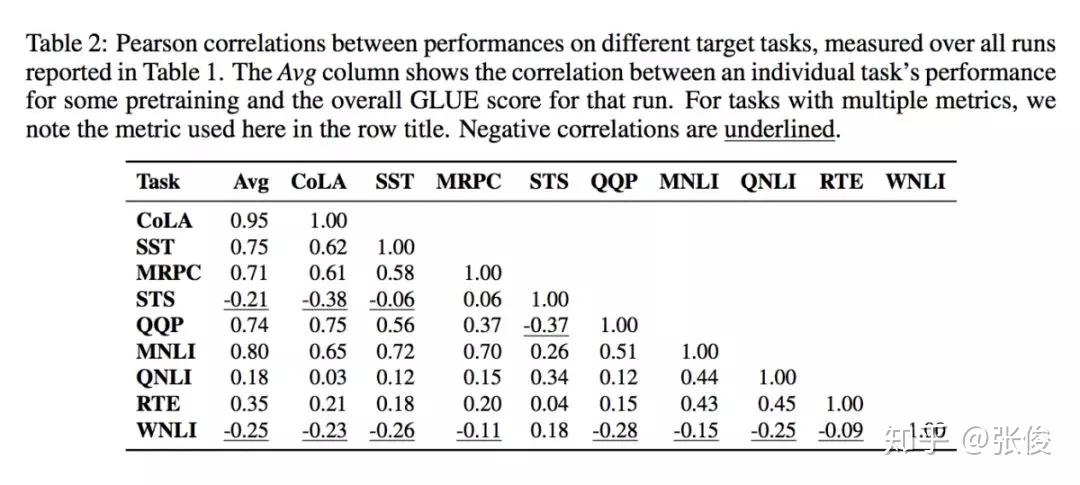
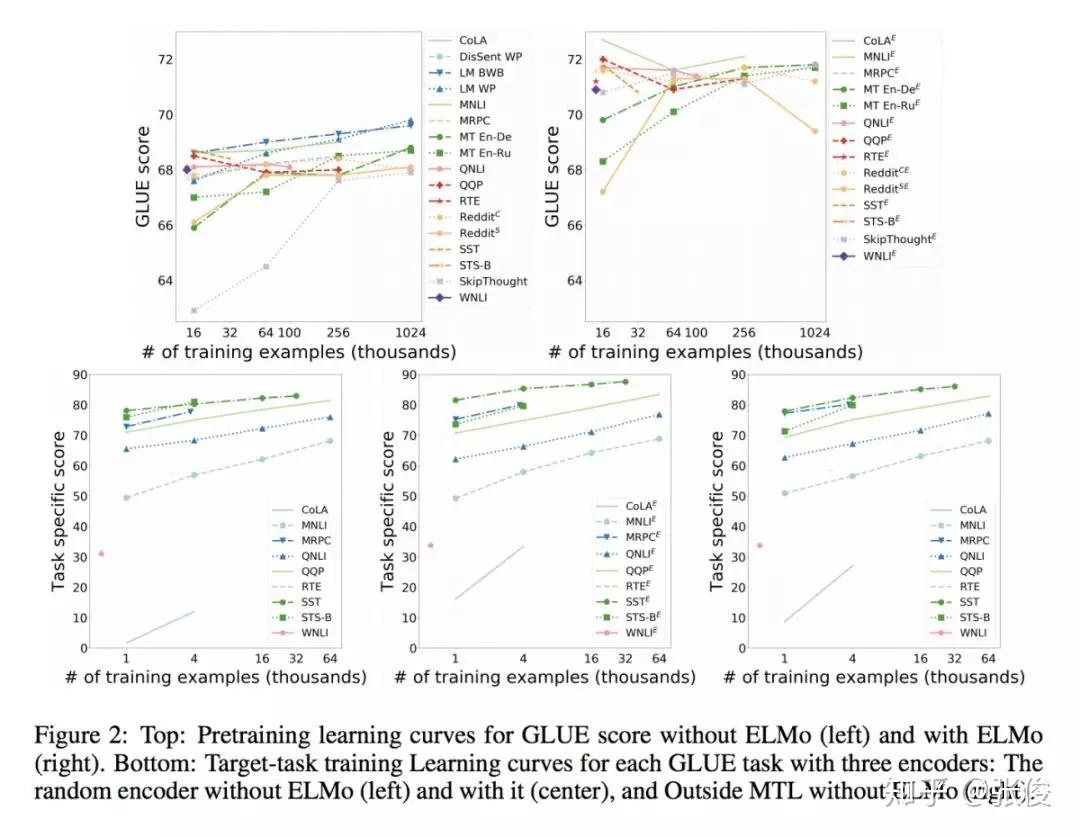
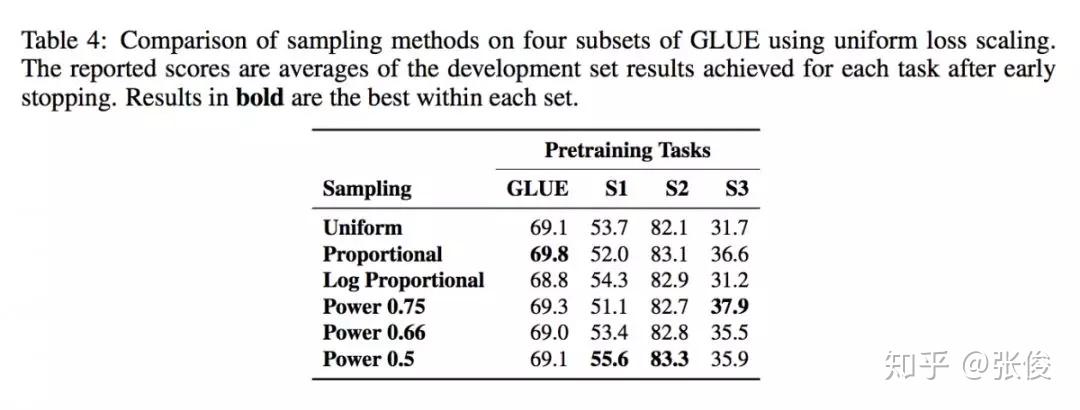
本文根据 GLUE 基准测试中的 9 个语言理解任务,评估了由不同的预训练任务和这些任务的几种组合而成训练可重用的 Sentence Encoder。实验结果表明语言建模是其中最有效的一个预训练任务,多任务学习可以进一步提高模型效果。
然而,ELMo 预训练也存在脆弱性和限制:1)在一些任务上,ELMo 的效果并不是很明显;2)可能对特定的任务 ELMo 才会很有效果,并且现有的多任务学习方法也无法提高句子编码器的泛化能力致通用的地步。

@paperweekly 推荐
#Object Detection
论文链接:https://www.paperweekly.site/papers/2670
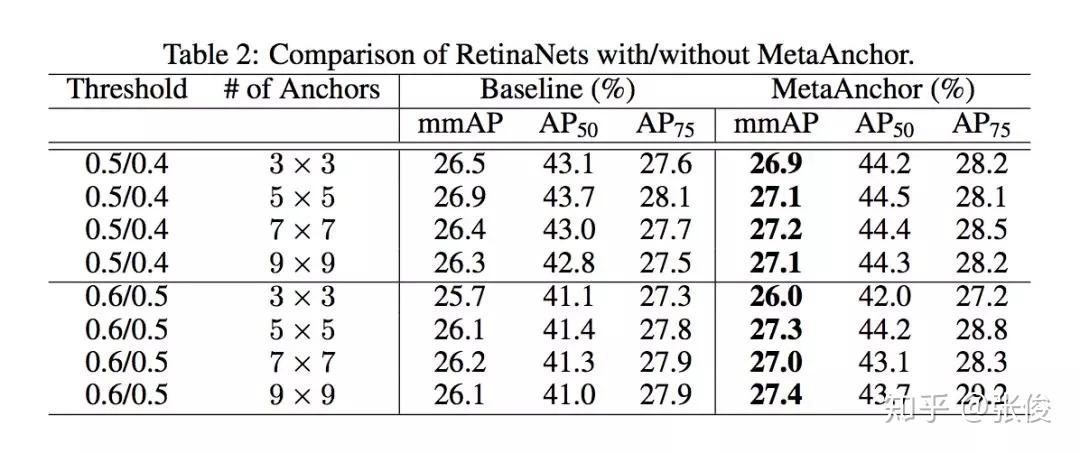
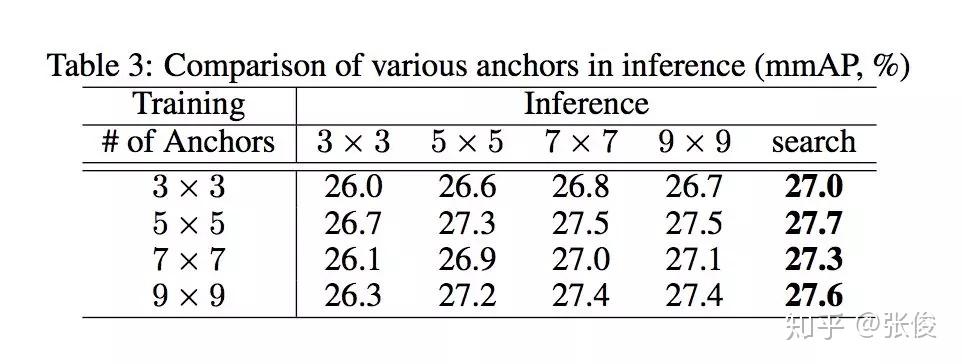
本文是旷视科技和复旦大学发表于 NeurIPS 2018 的工作。近年来,深度神经网络对于目标检测任务的提升取得了巨大突破。通常做法是运用目标检测算法为一张给定图像生成一系列边界框,同时分类标注每个目标。但对于卷积神经网络而言,直接无序生成任意数量的预测框并非无足轻重,Anchor 的思想也正因此应运而生,并在目标检测任务上得到广泛应用。
本文提出了一个全新灵活的锚点框机制 MetaAnchor,其锚点框函数可由任意自定义的先验框动态生成。加上权重预测,MetaAnchor 可与大多数基于锚点框的目标检测系统(如当前最优的单步检测器 RetinaNet)协同工作。相较于预定义锚点框方法,实验证明 MetaAnchor 对于锚点框设置和边界框分布更为鲁棒,并在迁移任务上深具潜力。
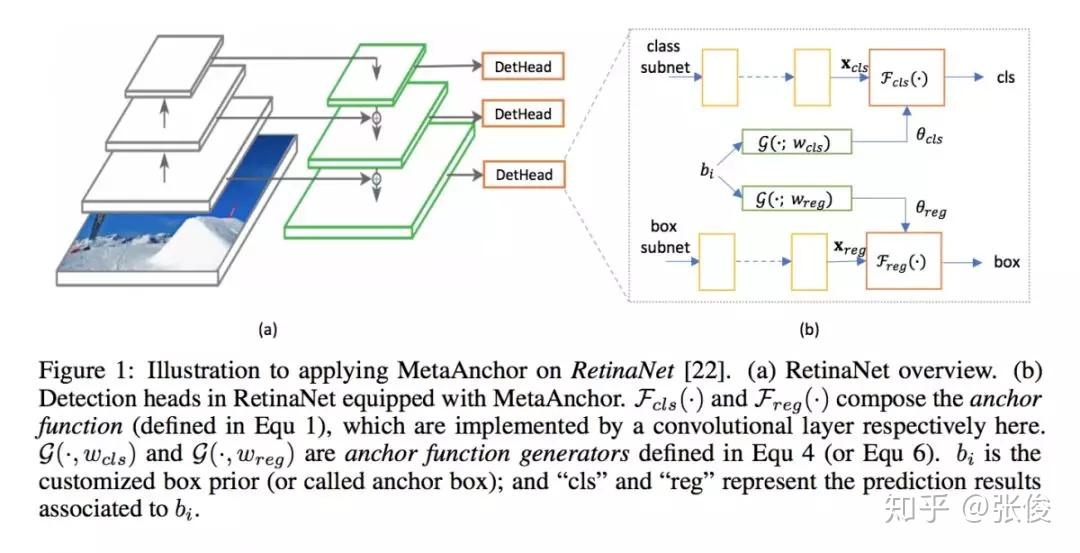
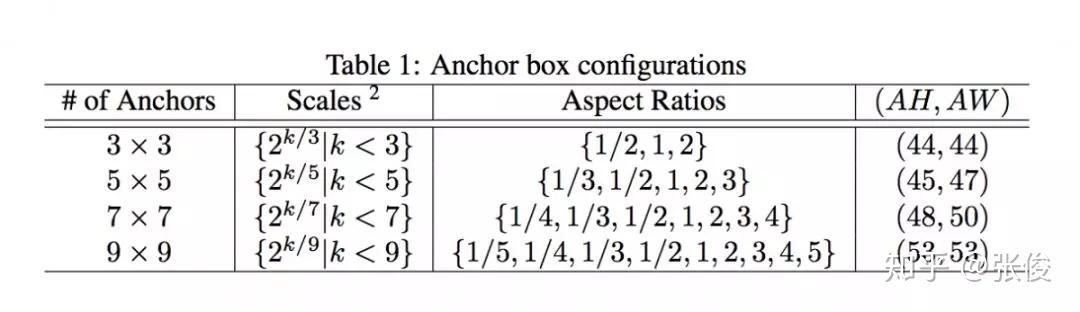
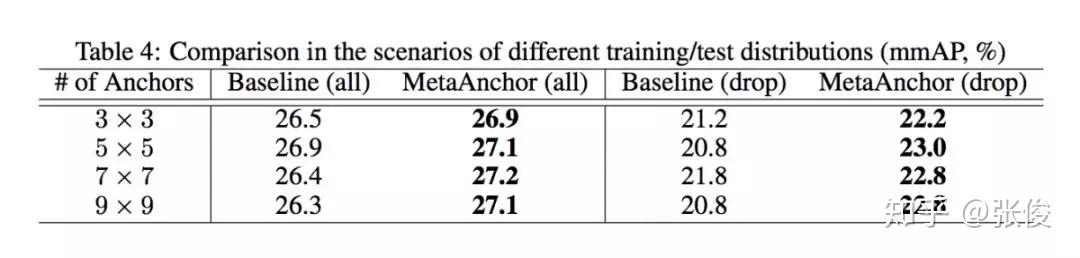

@QAQ 推荐
#Data Augmentation
论文链接:https://www.paperweekly.site/papers/2706
源码链接:https://github.com/tensorflow/models/tree/master/research/autoaugment
本文来自 Google Brain,论文关注的问题是图像领域的数据增强。作者提出了一种名为 AutoAugment 的自动数据增强的方法,可以有效降低误差率。实验表明,本文方法在 CIFAR-10、CIFAR-100、SVHN 和 ImageNet 上实现了最先进的准确率(无需额外数据)。此外,本文方法还可以直接迁移到其他数据集上而无需进行微调。

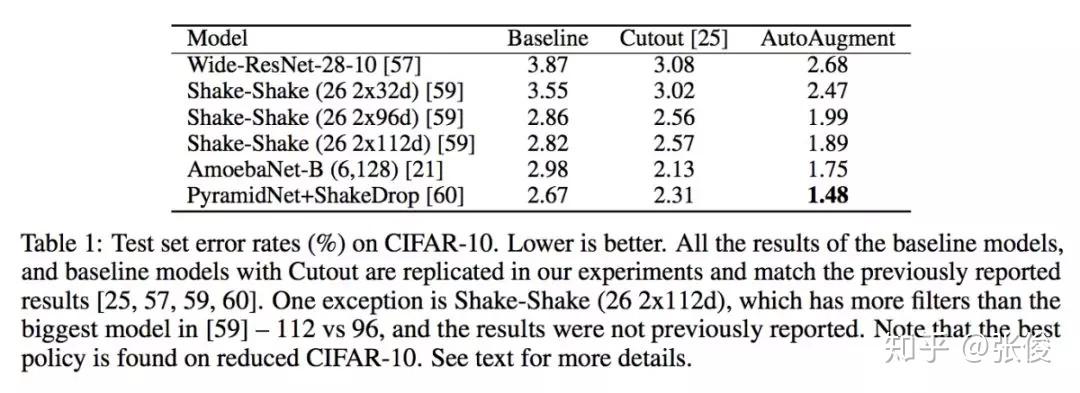


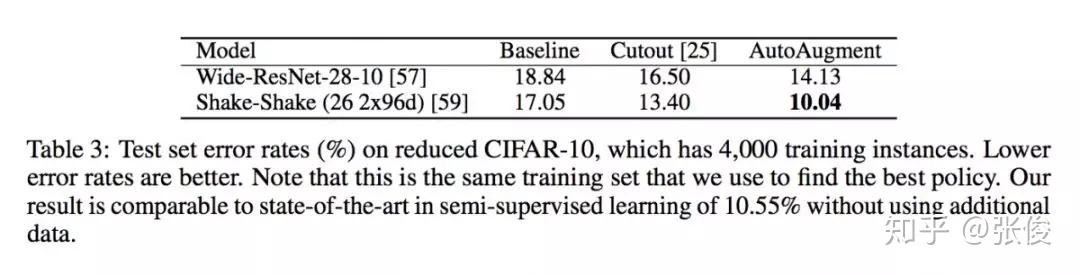

@zl1994 推荐
#Object Detection
论文链接:https://www.paperweekly.site/papers/2688
源码链接:https://github.com/bowenc0221/Decoupled-Classification-Refinement
本文来自 UIUC 和 IBM,论文重点解决目标检测中分类错误的问题。作者指出了当前目标检测框架对于目标分类任务存在的三个问题:1. 分类分支和回归分支共享特征不是最优的;2.多任务训练也不是最优的;3.对于小目标来说,大的感受野会导致小目标冗余的 context。论文主要思路是对分类和回归这两大任务解耦,并借鉴 R-CNN 中的机制使得不同大小的目标有自适应的 context 信息。
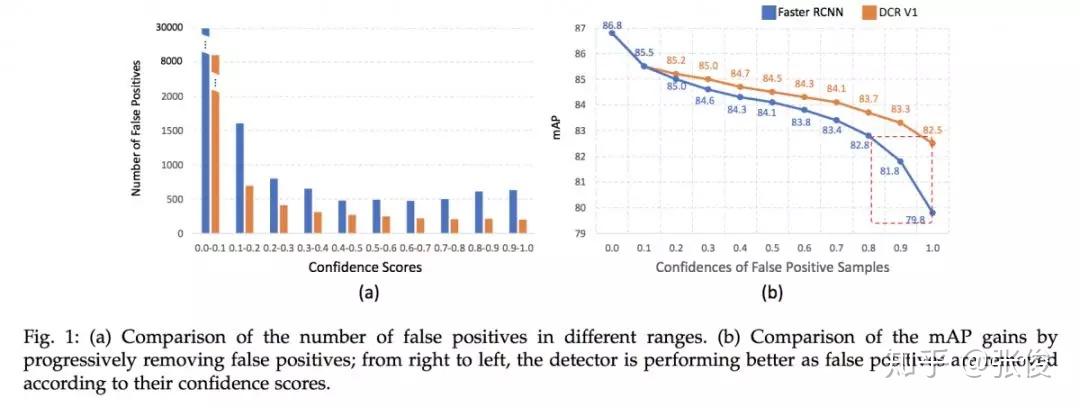
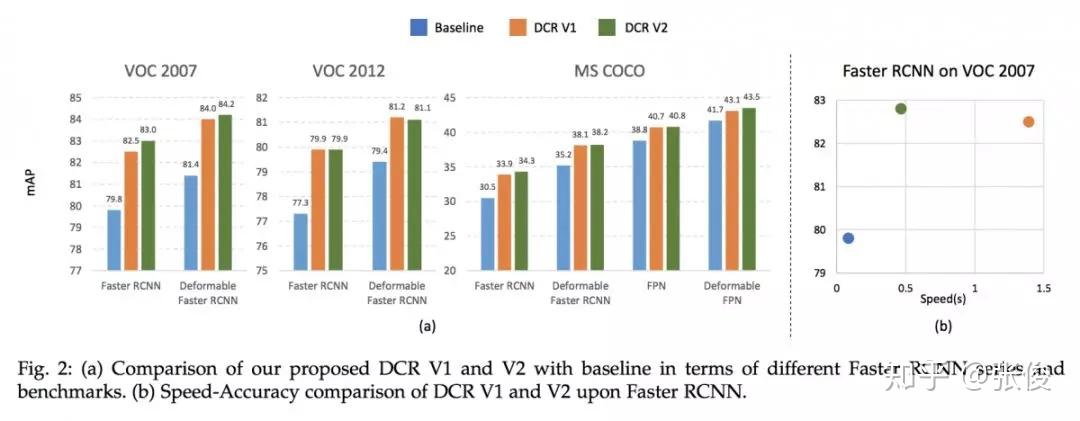
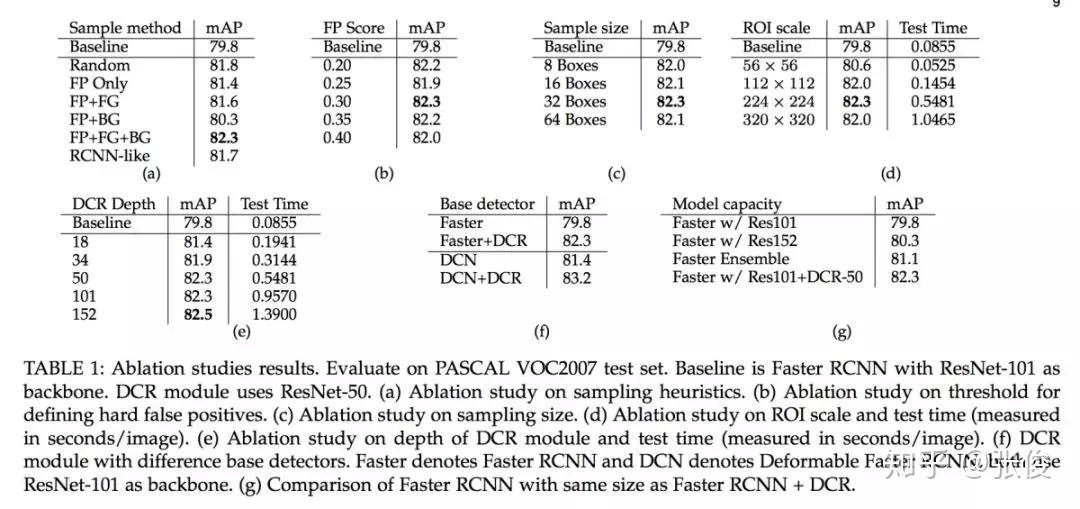

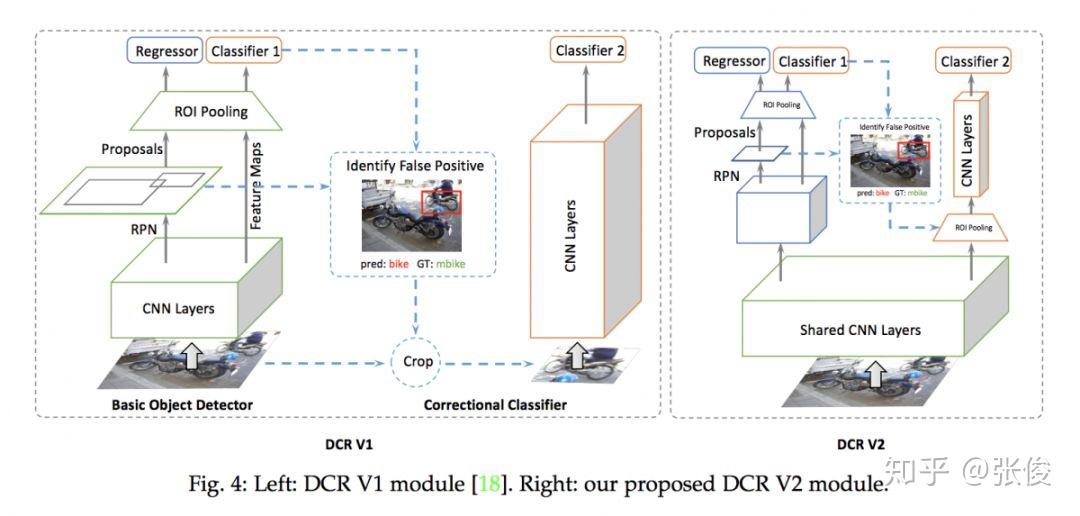

@paperweekly 推荐
#Image Classification
论文链接:https://www.paperweekly.site/papers/2687
源码链接:https://github.com/mil-tokyo/bc_learning_image/
本文是东京大学发表于 CVPR 2018 的工作,论文尝试将在音频上的方法应用于图像领域,并提出了一种将图像作为波形处理的混合方法。具体来说,作者认为人类无法识别图形波长融合,但这些信息对机器而言却是有意义的。CNN 有将输入数据作为波形处理的操作,作者提出的 BC Learning 方法是将两个不同类的图像进行混合,然后训练模型输出混合比,靠近哪个就分为哪类。

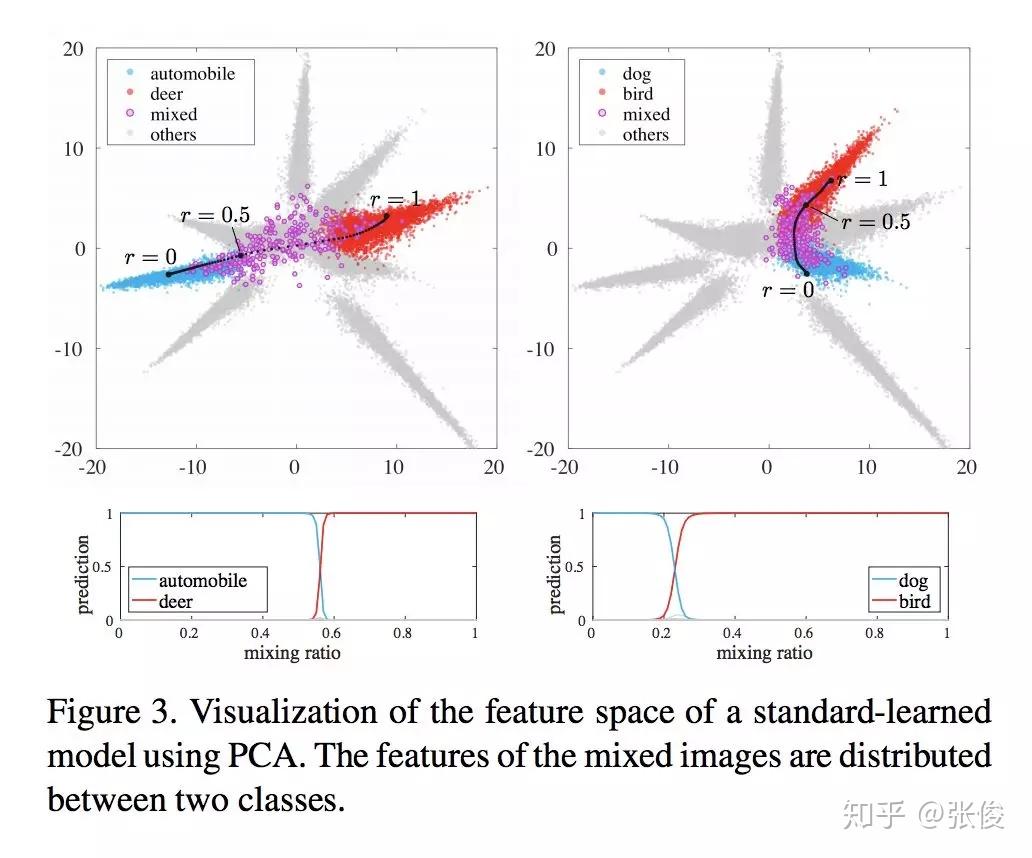
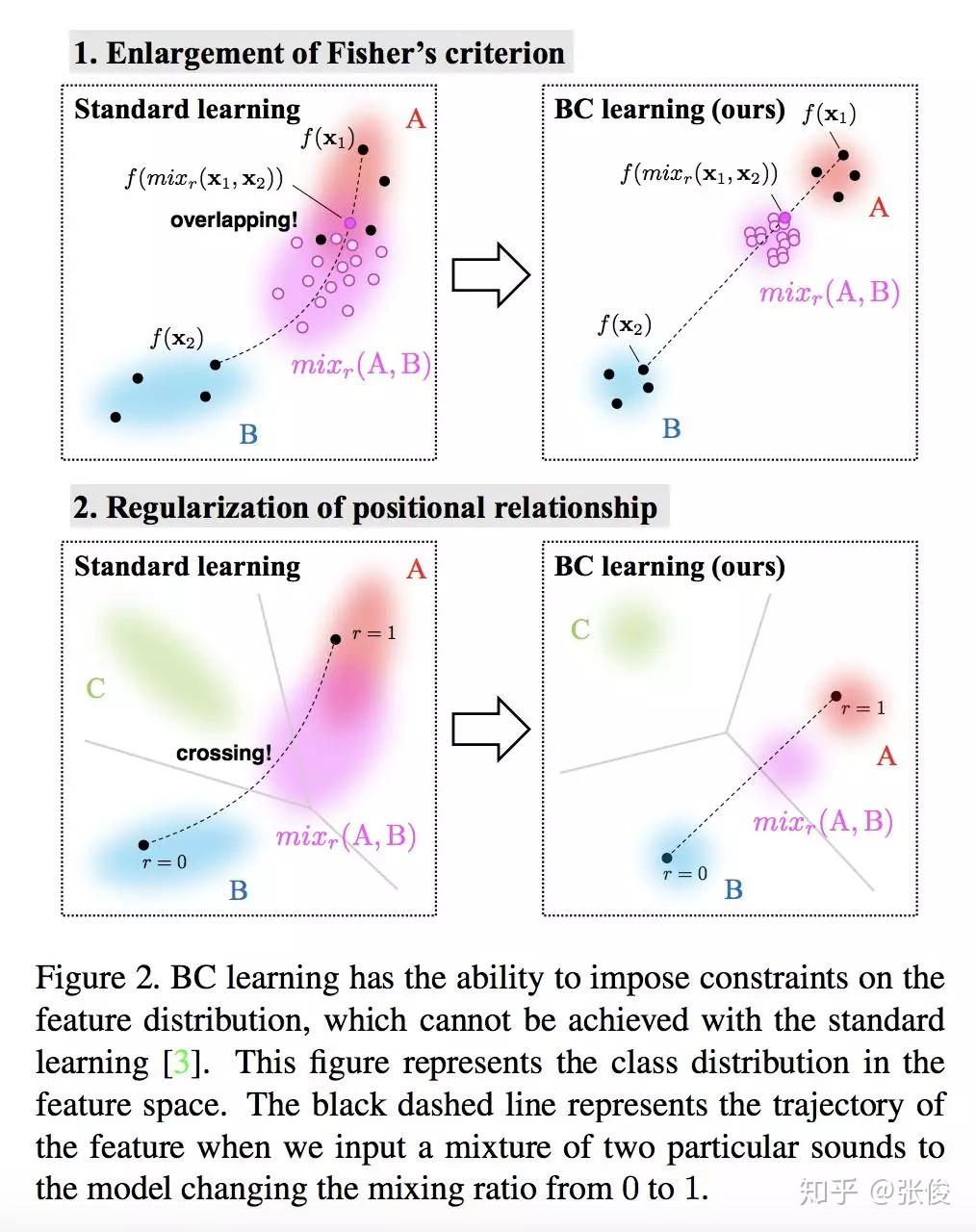
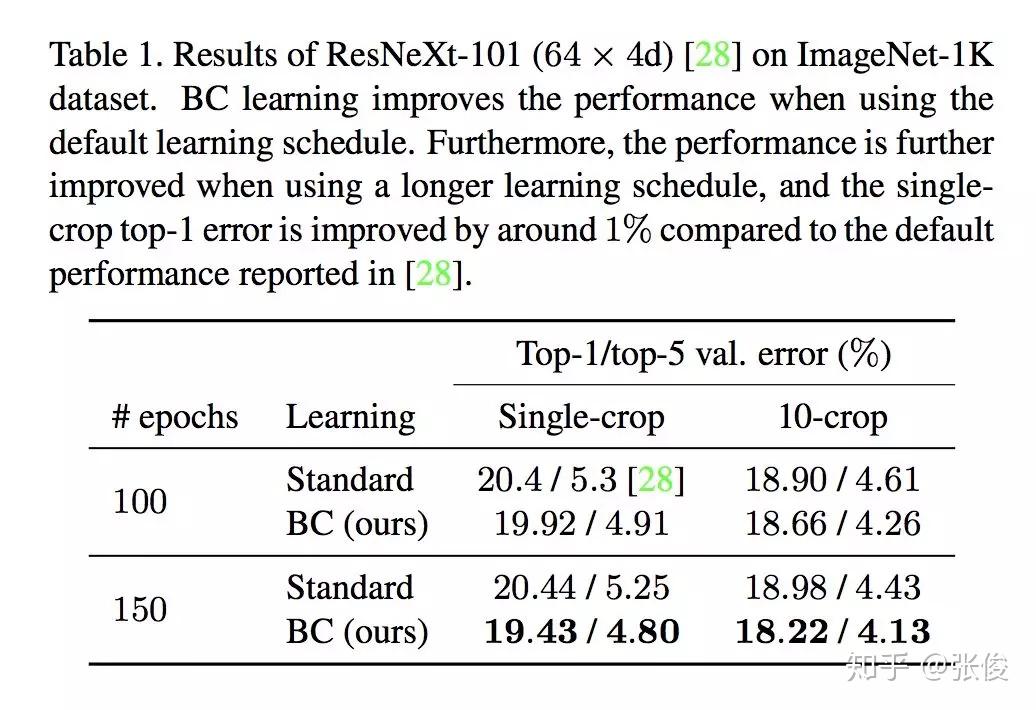
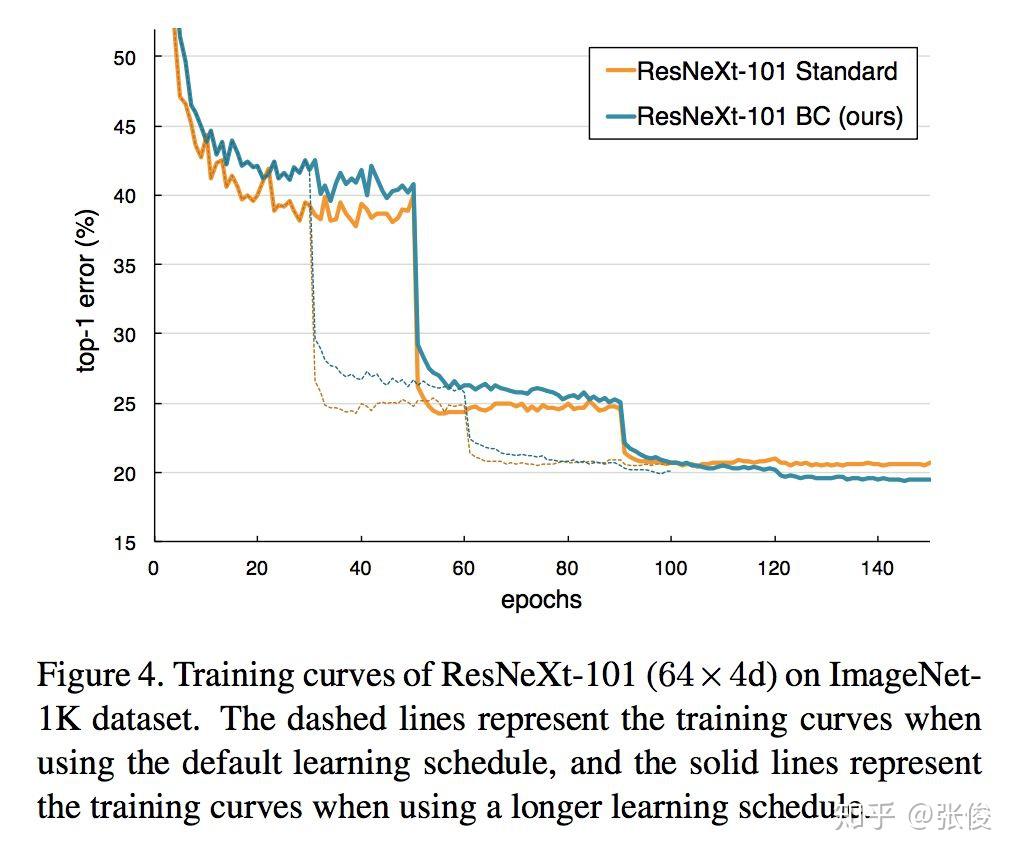

@Kralkatorrik 推荐
#Face Recognition
论文链接:https://www.paperweekly.site/papers/2710
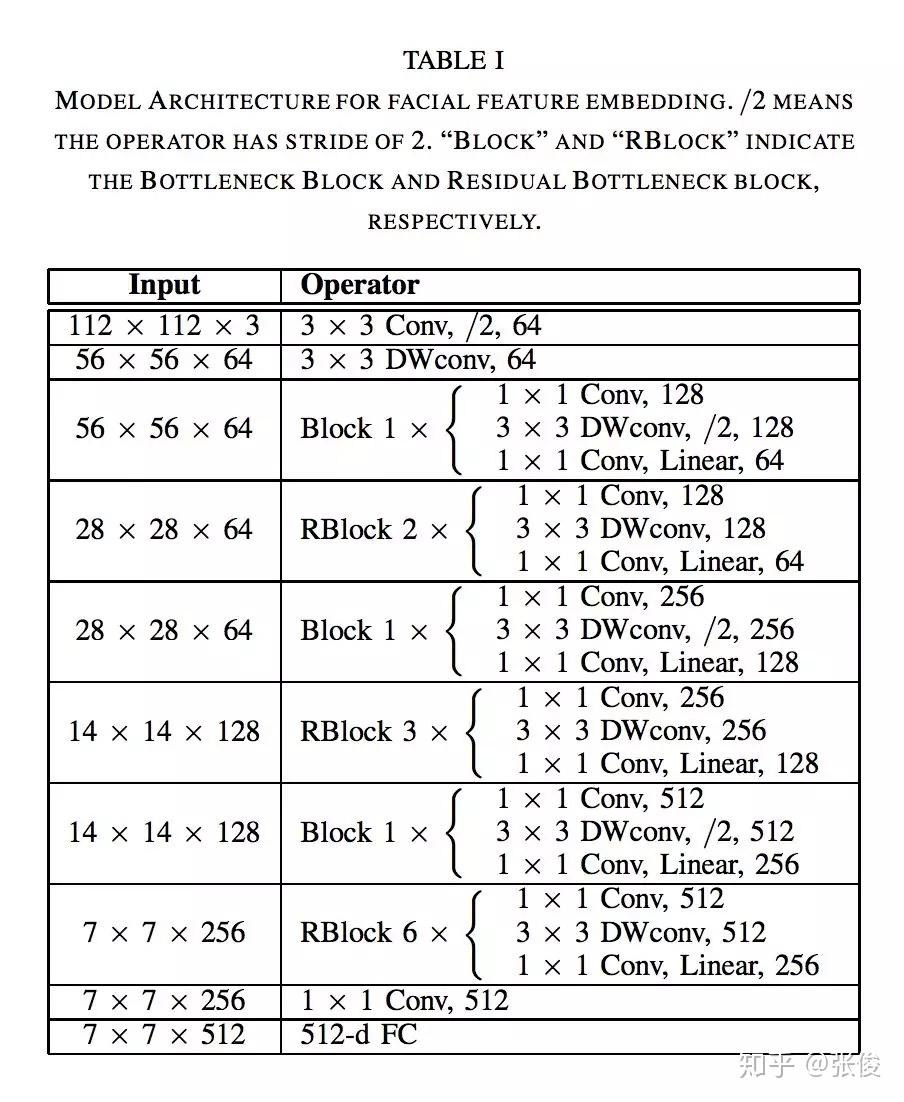
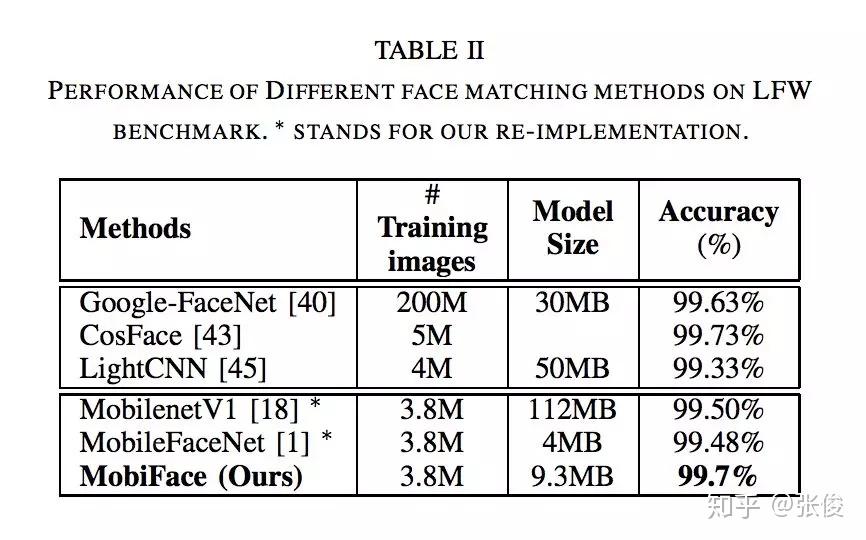
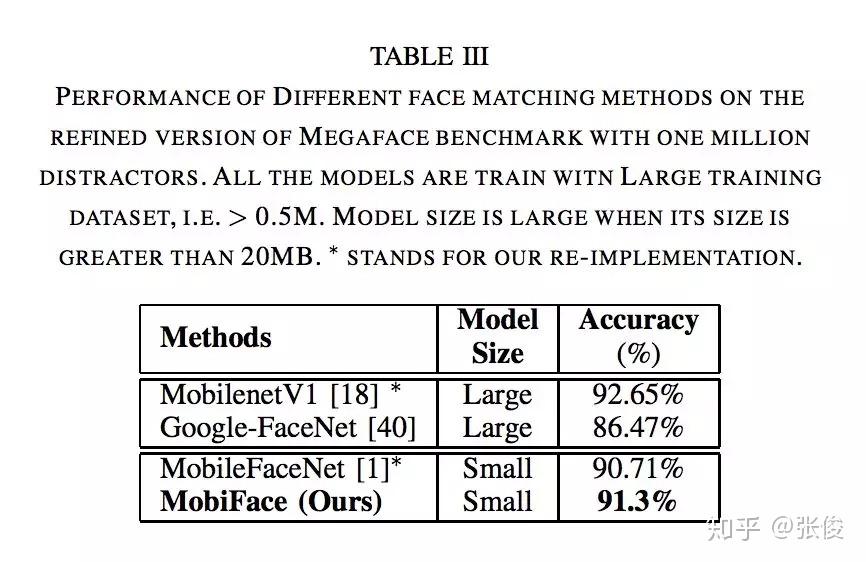
本文提出了一个轻量级的网络来做人脸识别, 比 MobileFaceNet 的 size 大一倍, 精度提高一些。主要看文章设计网络思路,作者使用 BottleNeck 和快速降采样策略减少参数量,从而使这个网络能够运行在移动设备上。

@vimjian 推荐
#Pose Estimation
论文链接:https://www.paperweekly.site/papers/2739
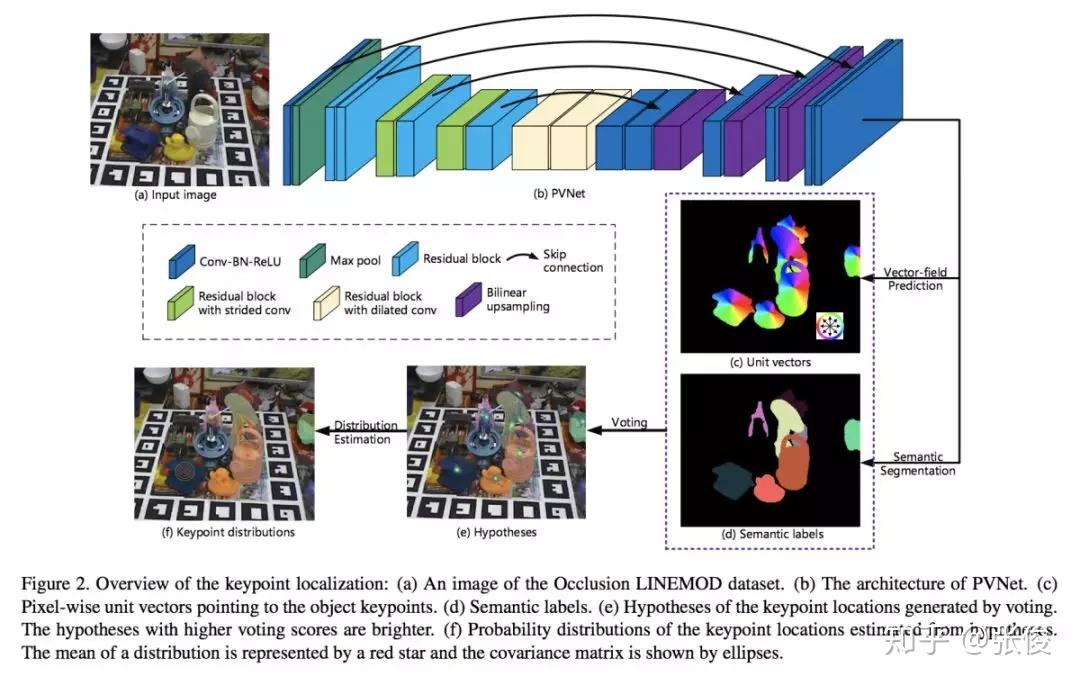
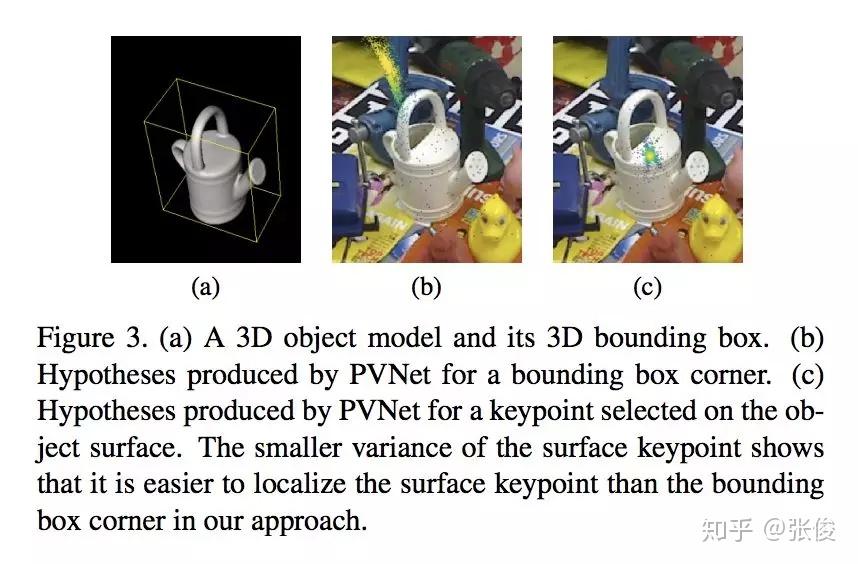
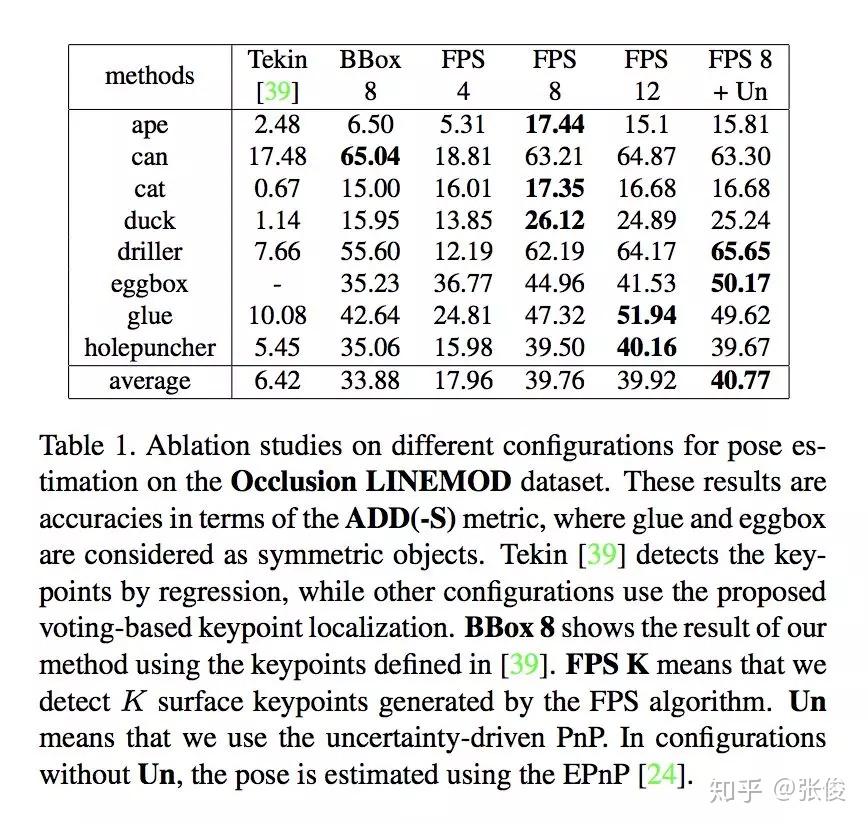
本文来自浙江大学,论文研究的问题是基于 RGB 的姿态估计,作者引入一个逐像素投票的网络来定位 2D keypoints。本文方法在 LINEMOD、Occlusion LINEMOD 和 YCBVideo 数据集上均取得了 SOTA 结果。


@IndexFziQ 推荐
#Multi-task Learning
论文链接:https://www.paperweekly.site/papers/2708
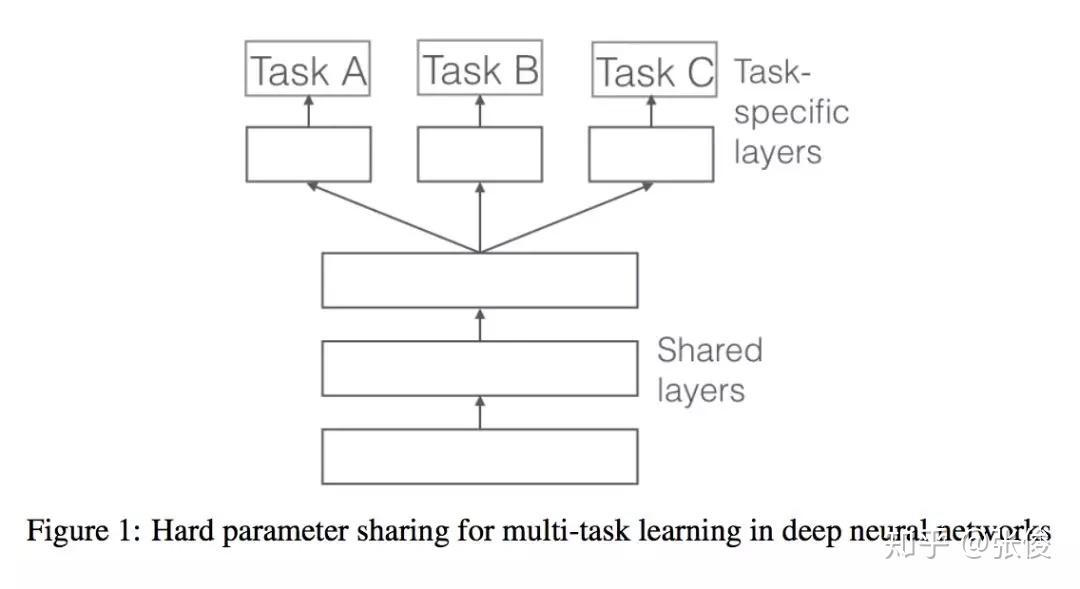
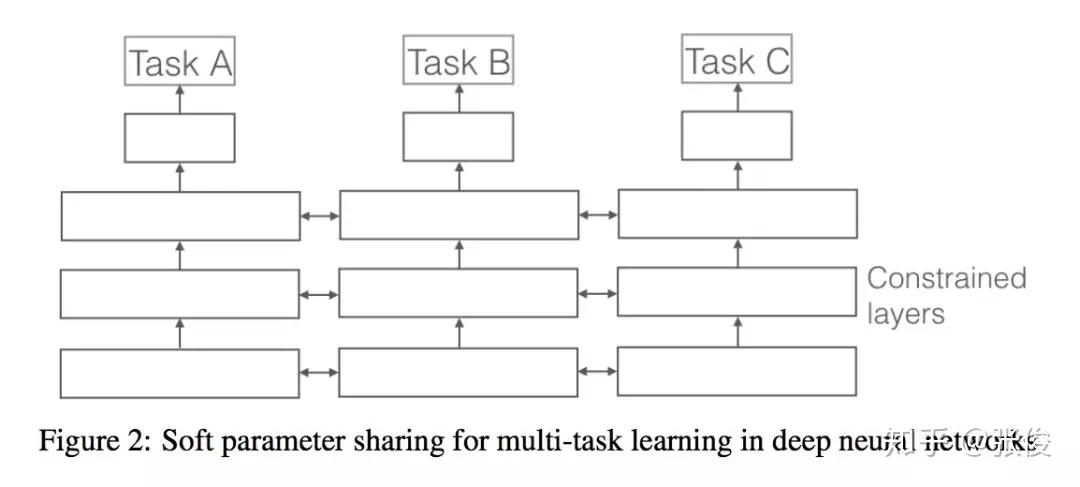
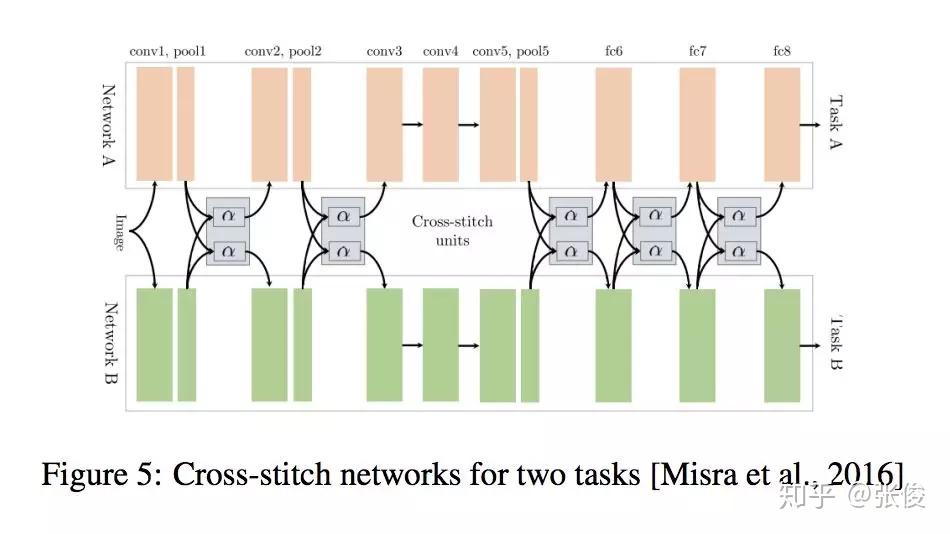
这是一篇来自爱尔兰学者 Ruder 的综述文章。论文整理了 Multi-task Learning 的相关工作,重点介绍在深度学习上的应用。多任务学习在很多任务上都可以获得比较不错的效果,如何选择合适的辅助任务帮助主任务获得更好的效果也是值得关注的地方。
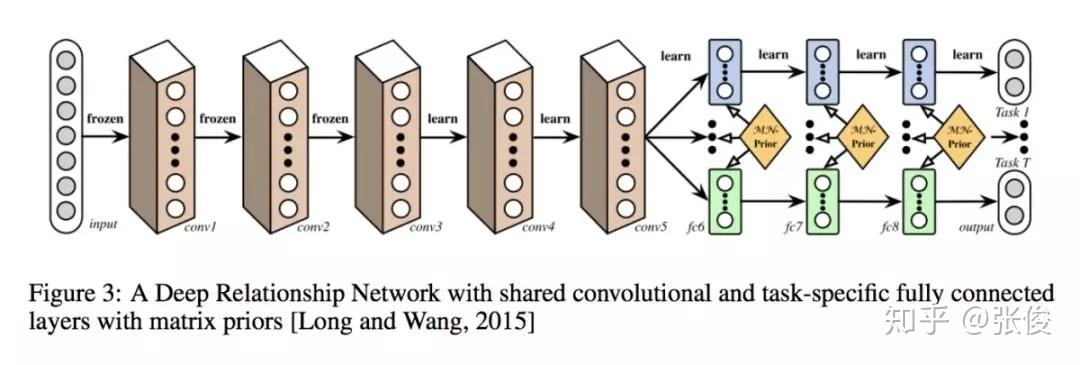
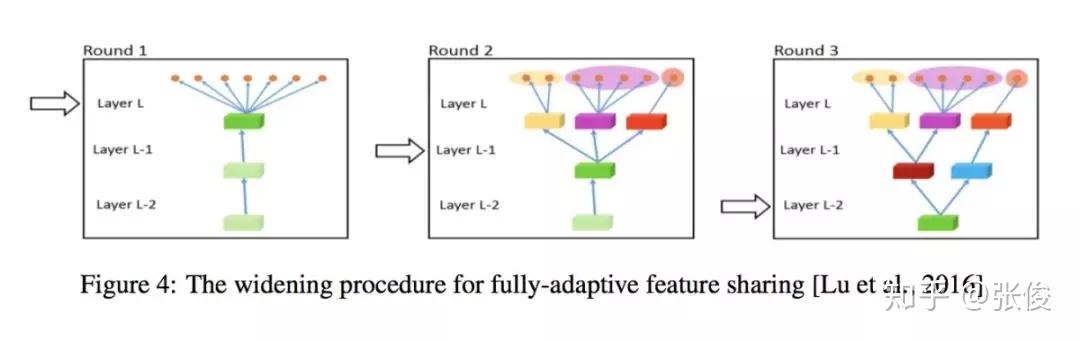

@Yerrick 推荐
#Learning to Rank
论文链接:https://www.paperweekly.site/papers/2667
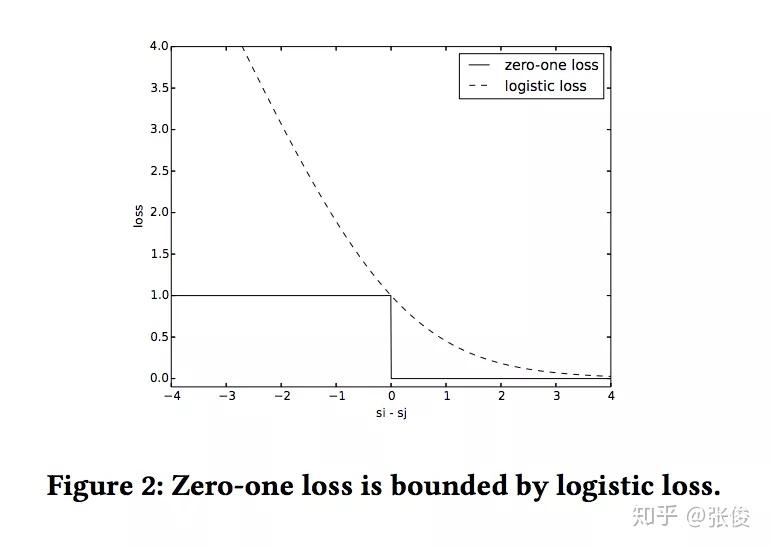
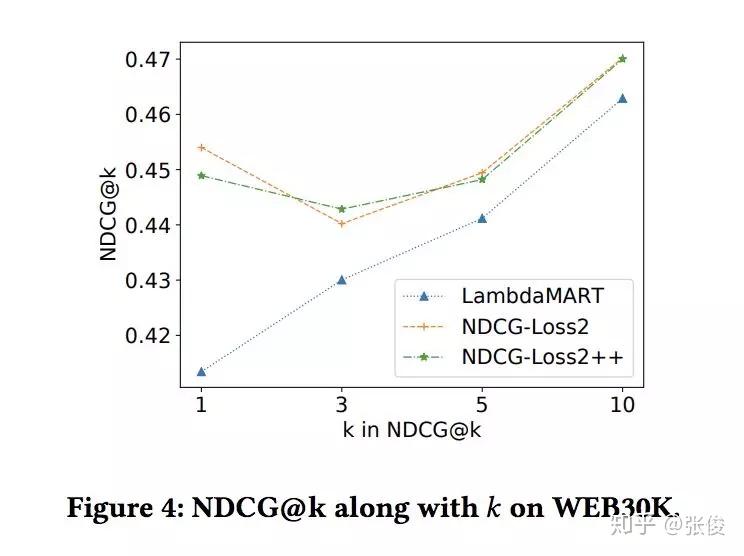
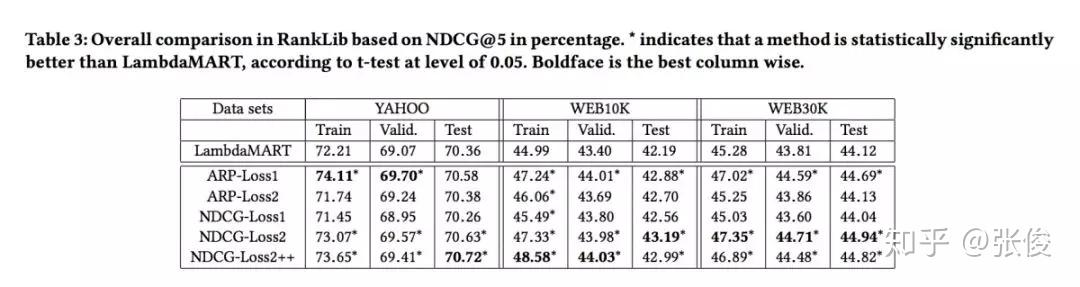
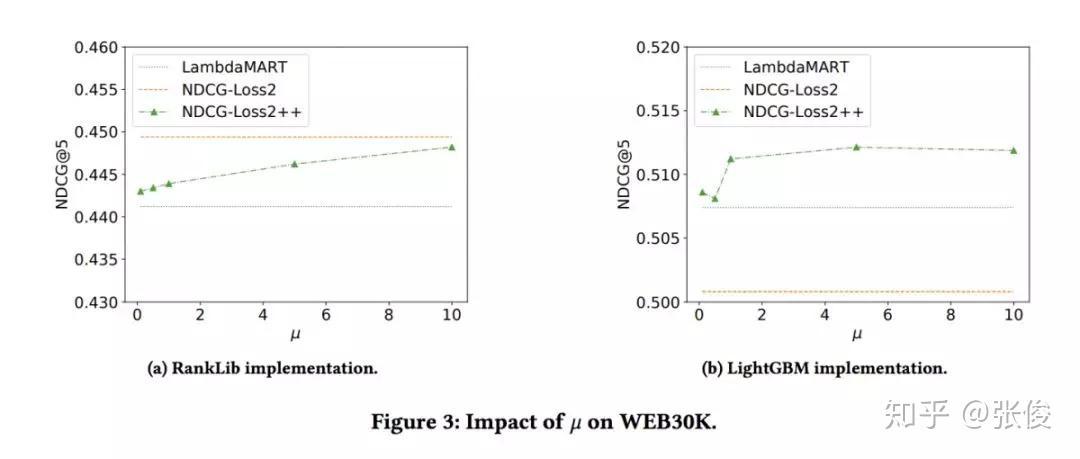
本文是 Google 发表于 CIKM 2018 的工作,论文形式化地将 Learning to Rank 领域经典的 LambdaMart 方法的 loss 表示出来,并提出了对于 NDCG 更紧的 bound,能够更好地在训练时提升 NDCG。同时基于他们的方法可以设计更多基于 Listwise 的 metric 直接进行优化。推导并不特别复杂,很有启发意义。方法也被TensorFlow/ranking所实现。
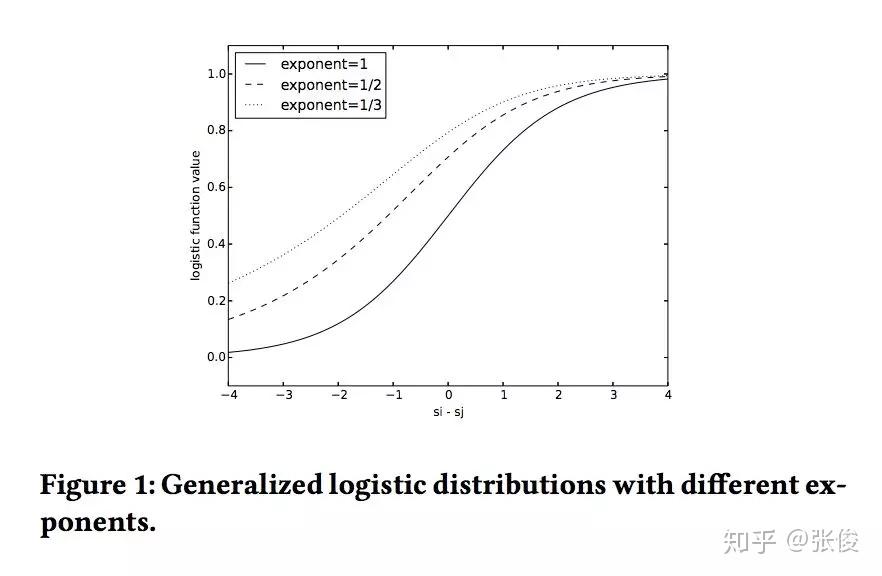

@NeoTheSunshine 推荐
#Graph Neural Networks
论文链接:https://www.paperweekly.site/papers/2730
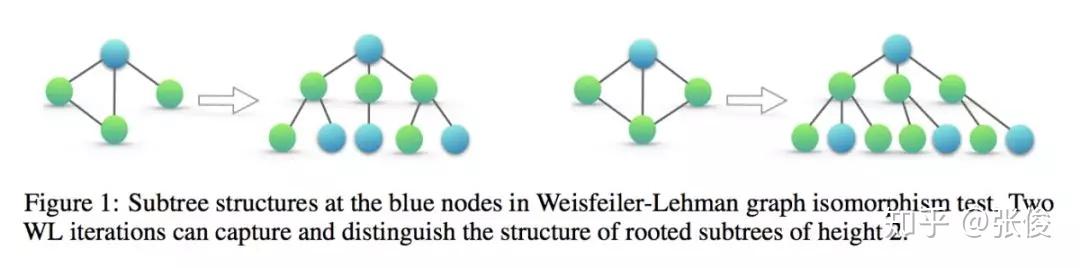
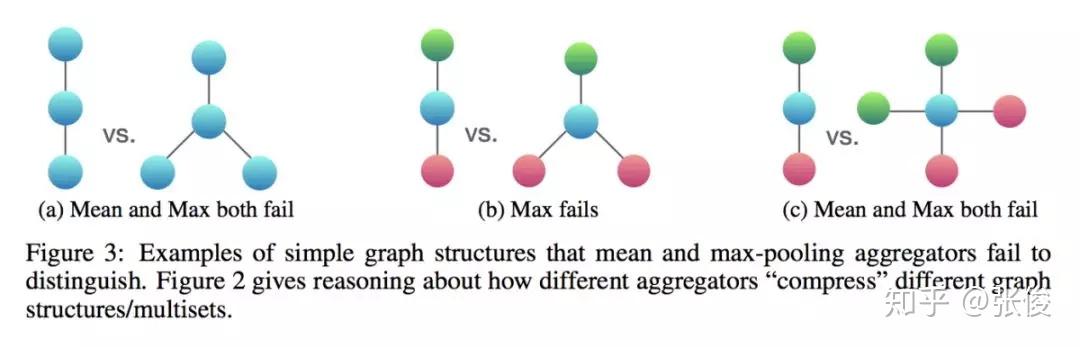
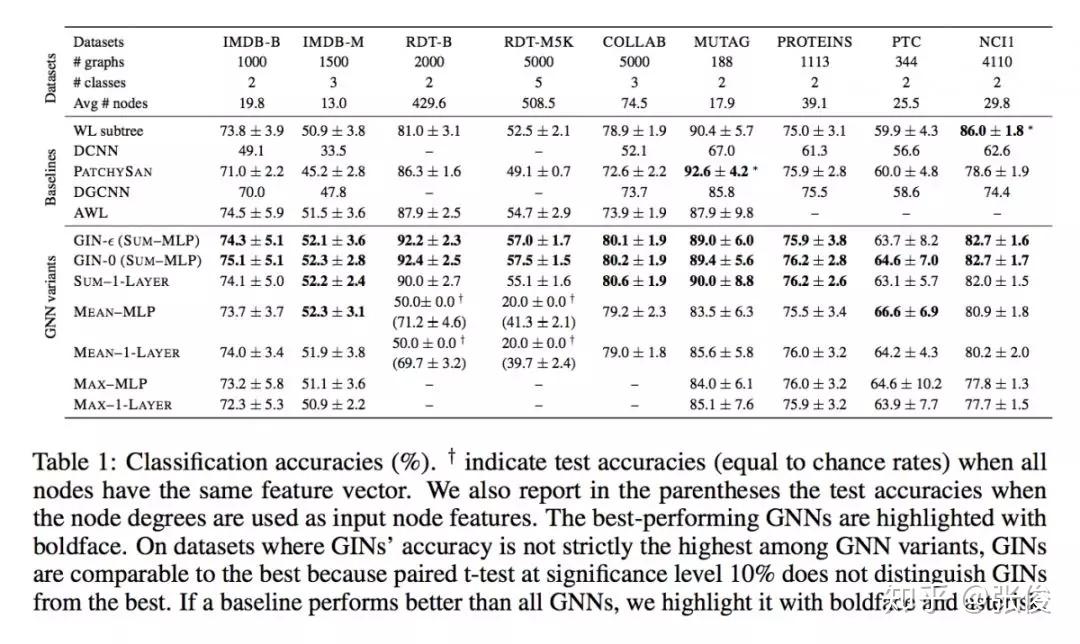
本文是麻省理工和斯坦福发表于 ICLR 2019 的工作,论文证明了 GNNs 至多可以和 WL test 在区分图结构方面同样有效。此外,作者还证明了 GNN 和 WL test 同样有效情况下的对 neighbor aggregation 和 graph pooling functions 的条件,并且提出一种简洁但有效的模型架构 GIN。
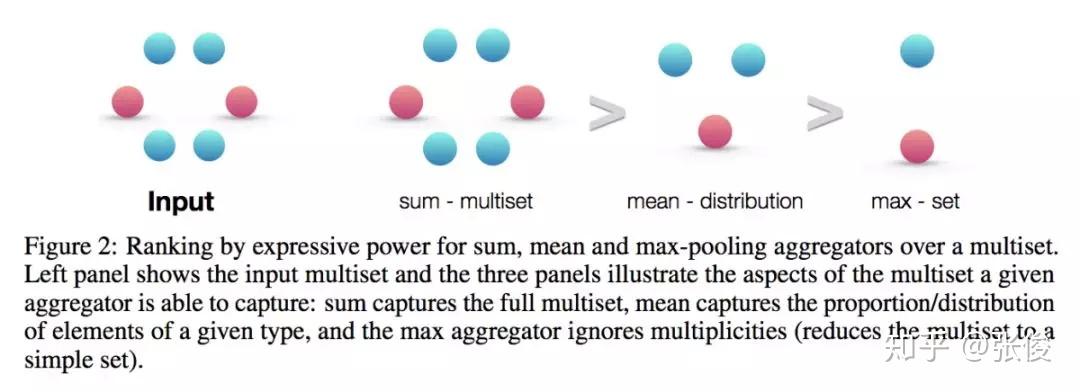
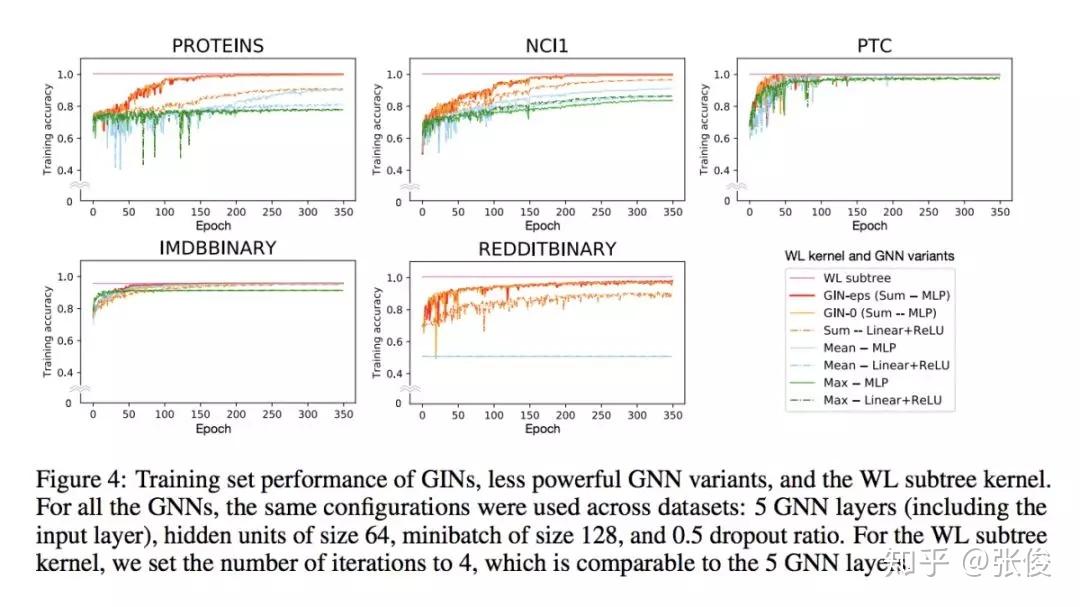

@figo 推荐
#Neural Architecture Search
论文链接:https://www.paperweekly.site/papers/2740
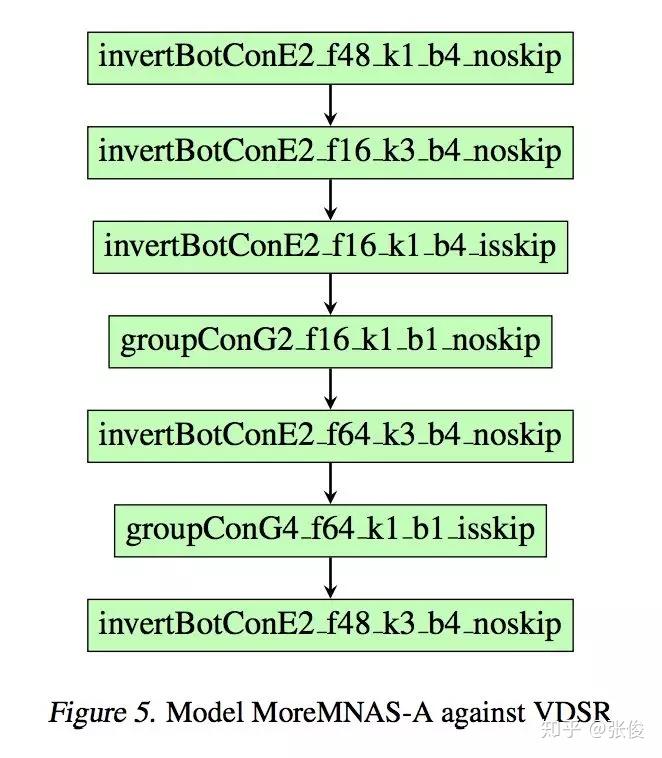
本文来自小米 AI,内容上属于目前很火的 AutoML Neural Architecture Search。这篇论文提出了 MoreMNAS 算法,应该是多目标(EA-NSGAII)+强化学习 NAS 的首篇论文。论文的初步试验,已经击败了 SRCNN、FSRCNN、VDSR 等单帧超分辨率领域知名网络(应该是截止到 CVPR 2016 的成果)。
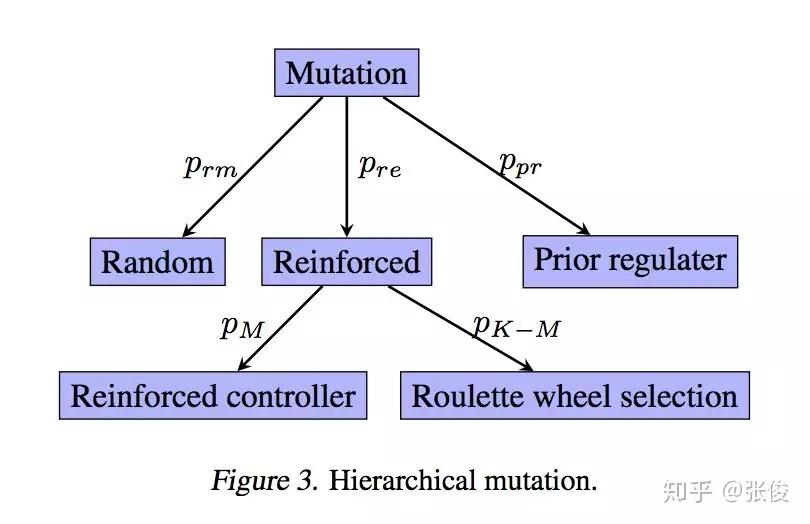
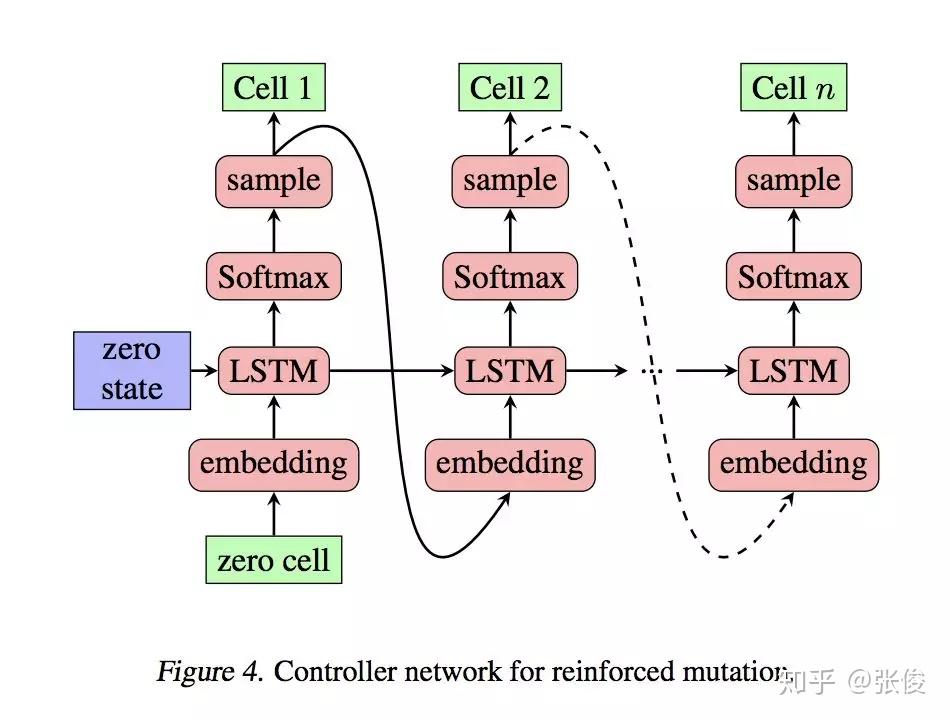
论文的想法是比较巧妙的,采用 NSGAII 作为主框架,解决强化学习由于超参、算法等导致的可能的衰退问题,同时采用强化学习变异可以更好的利用学习的经验,二者相互补充,使得方法的鲁棒性有保证。另外强化学习只用来解决那些不容易解决的目标例如超分的 PSNR,对于其他可以提前计算的目标,则用了 Roulette-wheel selection。
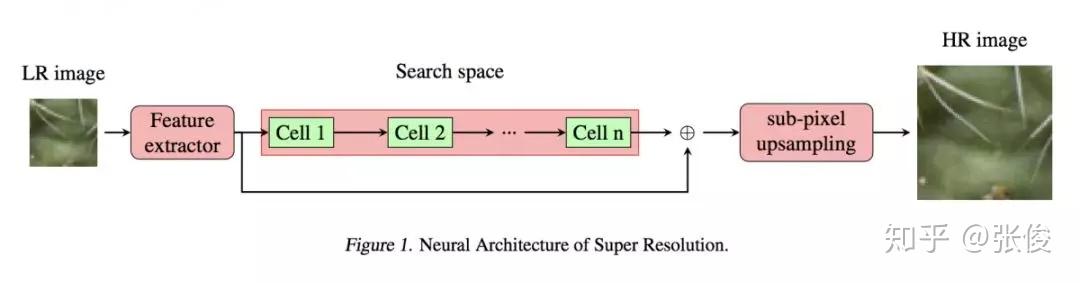
论文中的搜索空间直接采用 cell-block,看起来效果也不错,比较自然地完成 Cross Over 和 Natural Mutation 环节。另外,论文解决的实际上是带约束的 MOP 问题,并对最低的 PSNR 进行了约束,以保证模型的业务可用性。
实验结果是基于一台 8GPU 机器完成(V100,1 周),实乃深度学习炼丹师的福音,对于不少公司而言,这个配置是现成的。总体这种方法有一定的通用性,感兴趣的读者可以用来试水其他领域。遗憾的是该论文没有公开源码。
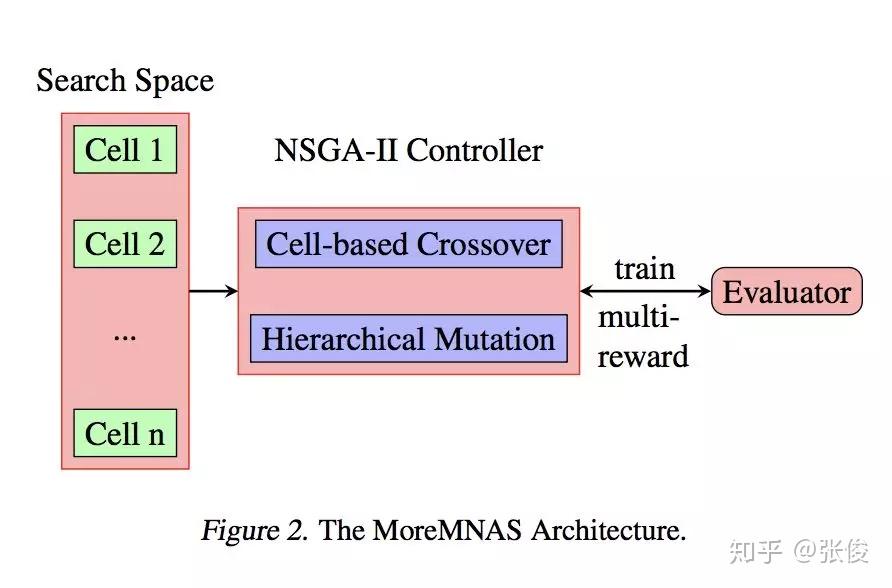

@paperweekly 推荐
#Click-Through Rate Prediction
论文链接:https://www.paperweekly.site/papers/2692
源码链接:https://github.com/alibaba/x-deeplearning/tree/master/xdl-algorithm-solution/DIEN
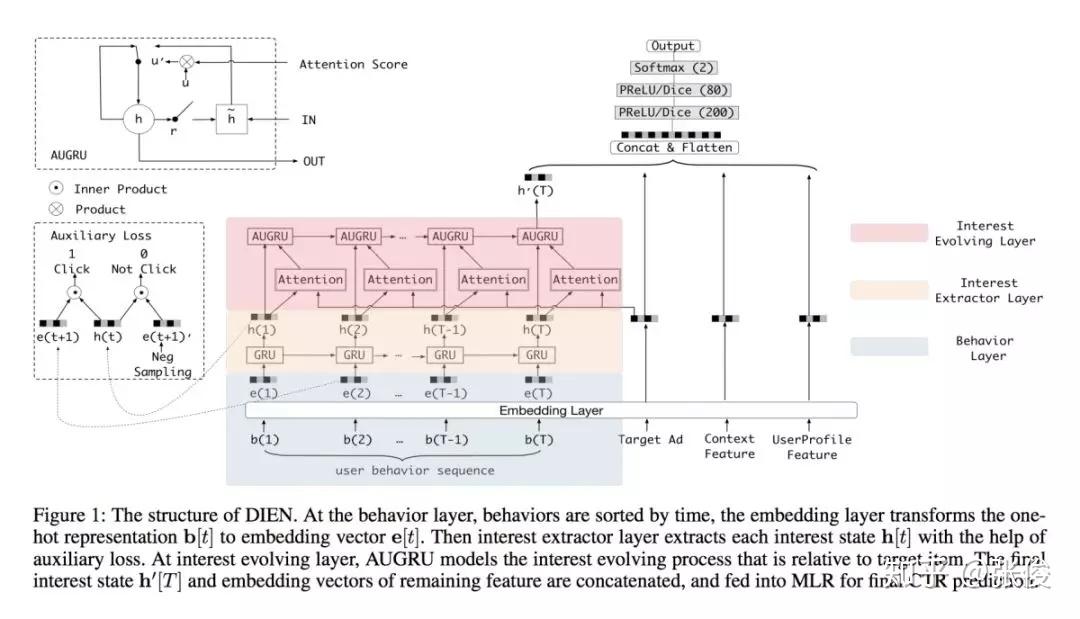
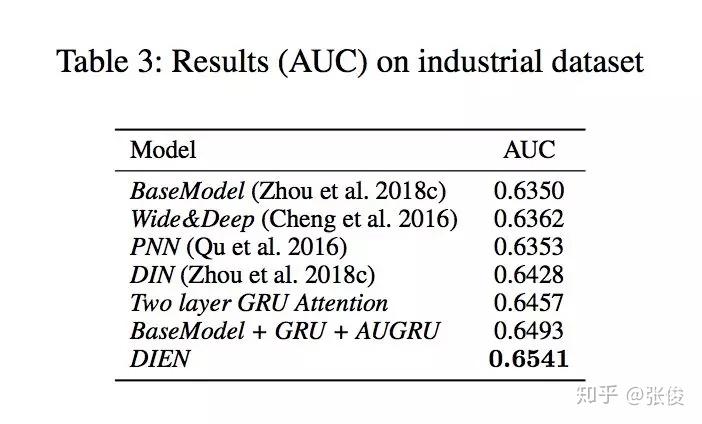
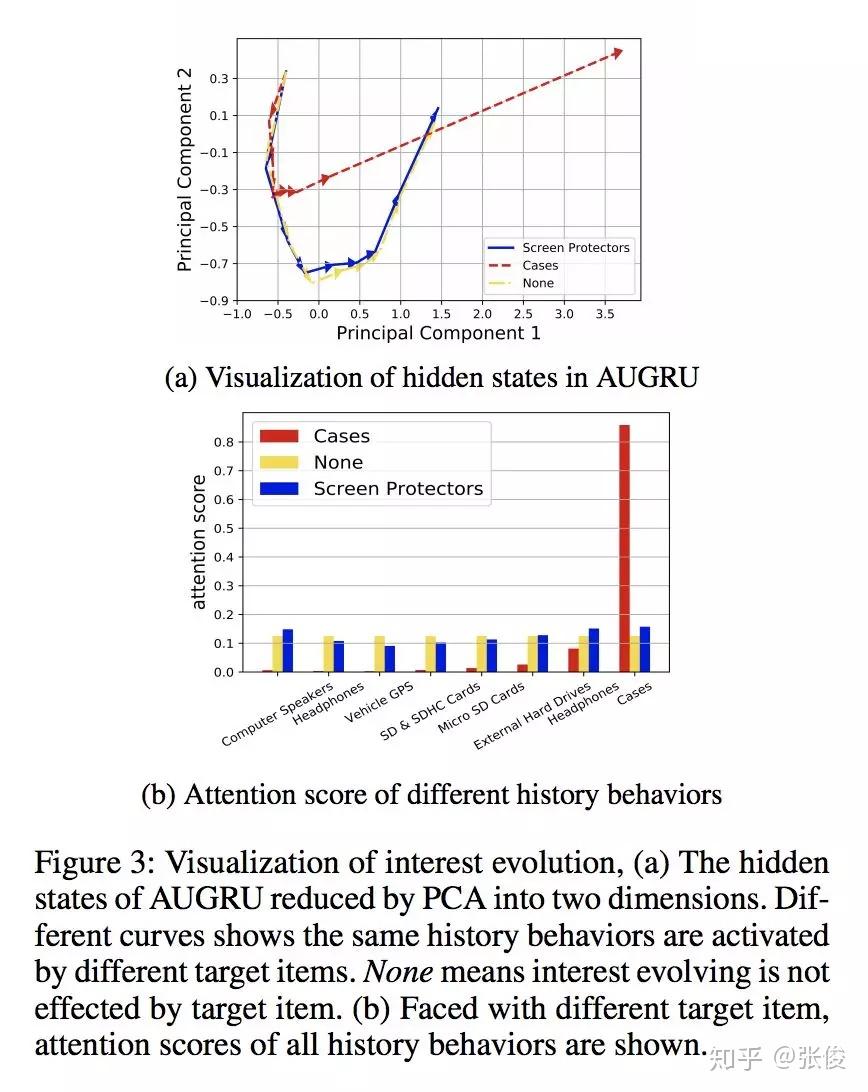
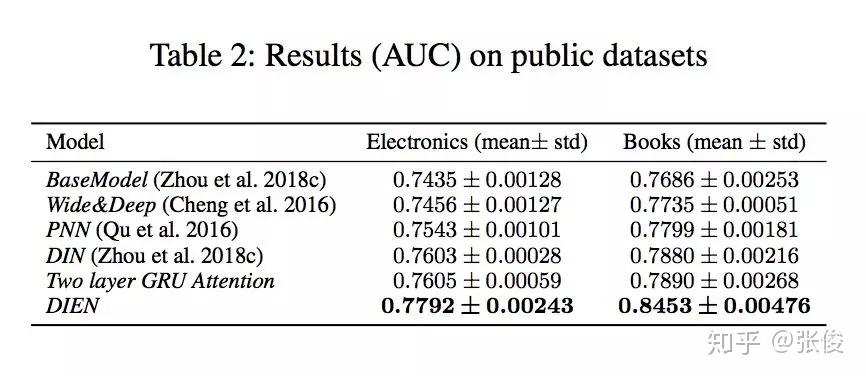
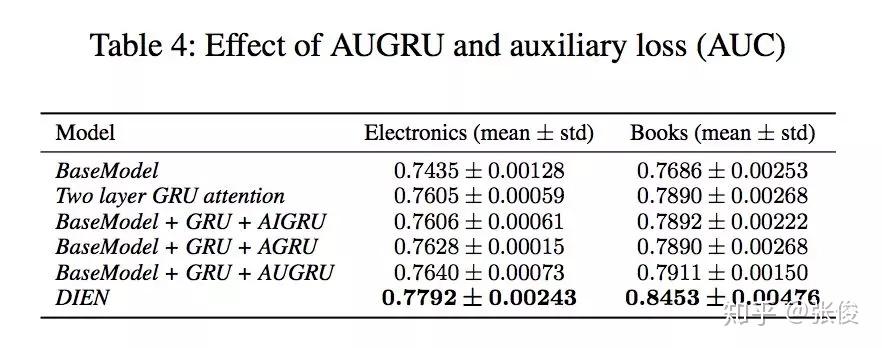
本文是阿里巴巴发表于 AAAI 2019 的工作,作者提出了一种由兴趣抽取和兴趣演化两个模块共同组成的 CTR 预估模型——DIEN。论文亮点在于作者关注隐藏在用户行为背后的潜在兴趣特征的挖掘和表示(GRU + auxiliary loss)。
淘宝平台上商品种类繁多,用户兴趣具有多样性。预测时,仅仅捕获与目标商品相关的兴趣及其演变(AUGRU)。该算法被应用于阿里妈妈定向广告各大产品中,在DIN的基础上取得了非常显著的效果提高。
#投 稿 通 道#
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢? 答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
投稿方式:
• 方法一:在PaperWeekly知乎专栏页面点击“投稿”,即可递交文章
• 方法二:发送邮件至:hr@paperweekly.site ,所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
加入社区:http://paperweek.ly
微信公众号:PaperWeekly
新浪微博:@PaperWeekly

AI时代,拥有个人微信机器人AI助手!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
搜索微信号aigc666aigc999或上边扫码,即可拥有个人AI助手!



