文章主题:- lvxin – 推荐


@lvxin 推荐
#Knowledge Representation
论文链接:https://www.paperweekly.site/papers/2484
源码链接:https://github.com/davidlvxin/TransC
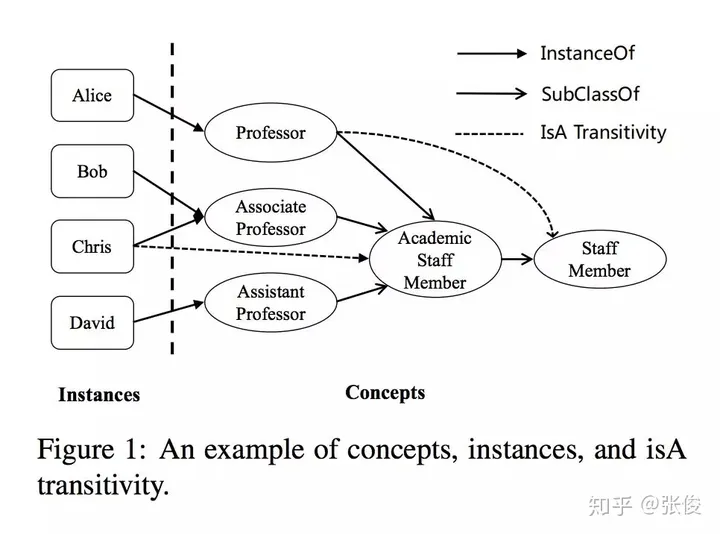
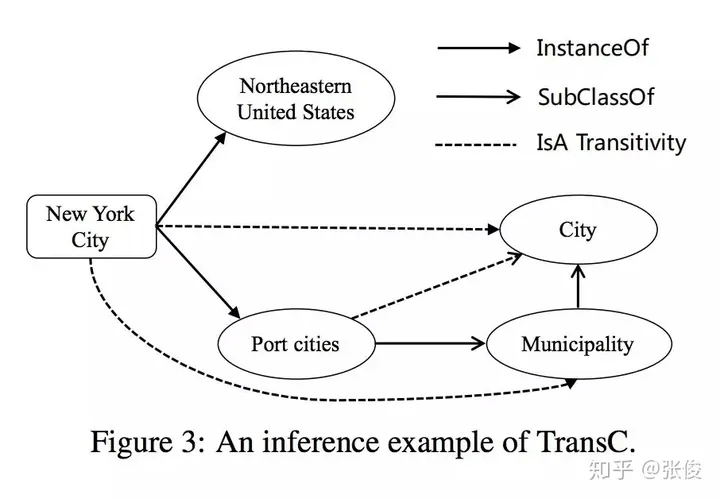
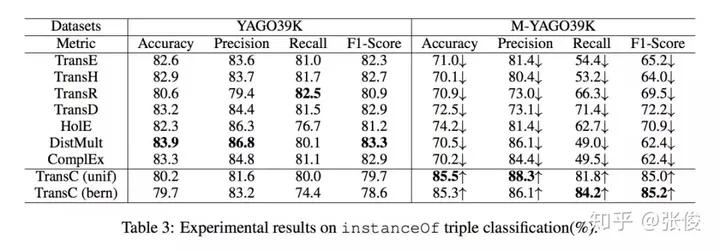
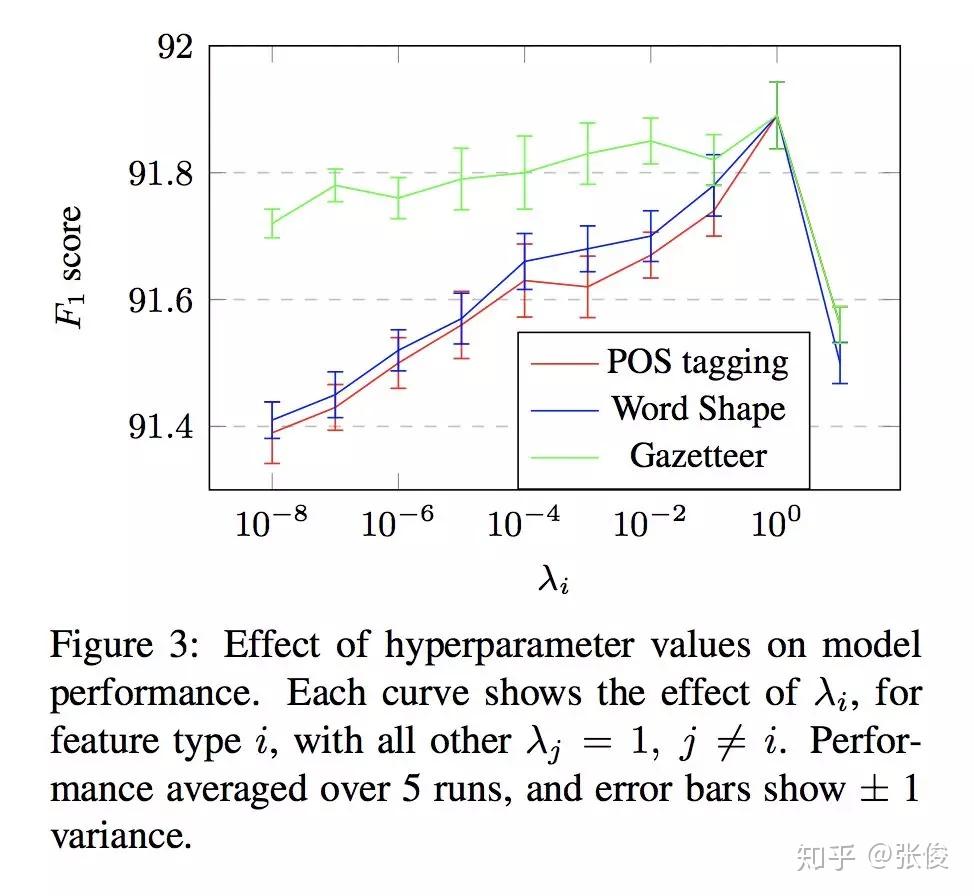
这篇文章是由清华大学在EMNLP 2018会议上发表的。该研究提出了一种创新性的知识图谱表示学习方法,通过引入上下位关系与普通关系的区分概念,成功解决了上下位关系传递性的一些问题。此外,这种方法还能够有效地表现概念在空间中的层次结构和包含关系。
在近年来的广泛研究中,知识图谱的表示学习得到了极大的关注。这一领域的研究成果对于知识图谱的补全和信息抽取具有重大价值。然而,传统的表示学习方法在处理概念与实例之间的关系时存在一定的不足。具体而言,这些方法往往将概念和实例等同对待,将其统一视为实体,然而这种做法忽略了概念和实例之间明显的层次差异,因此在表示上存在一定的缺失。更为关键的是,许多传统方法在处理上下位关系传递性方面存在问题,这主要源于其对概念和实例表示的不区分子午。因此,我们需要更加精细地处理这种关系,以期达到更优的表示效果。
在本文中,我们创新性地运用球体这一概念,将其表示为空间中的一个实体。具体来说,我们将实例定义为空间中的点,并通过点和球体之间的包含关系以及球体之间的相互包含关系来展示上下位关系。这种表示方法可以有效地解决上下位关系传递性问题,使得表达更加直观且富有逻辑性。




@paperweekly 推荐
#Named Entity Recognition
论文链接:https://www.paperweekly.site/papers/2464源码链接:https://github.com/shangjingbo1226/AutoNER
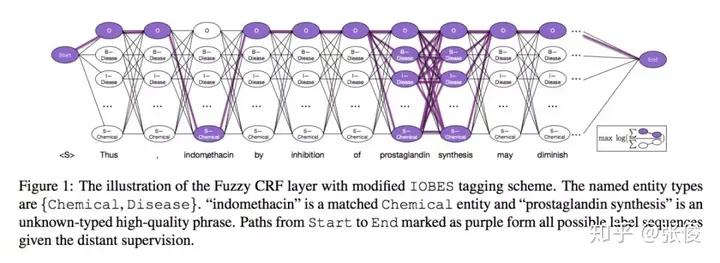
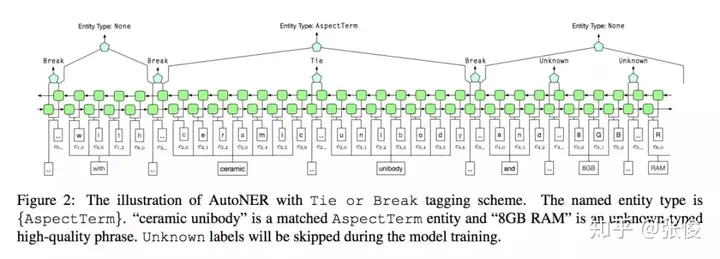
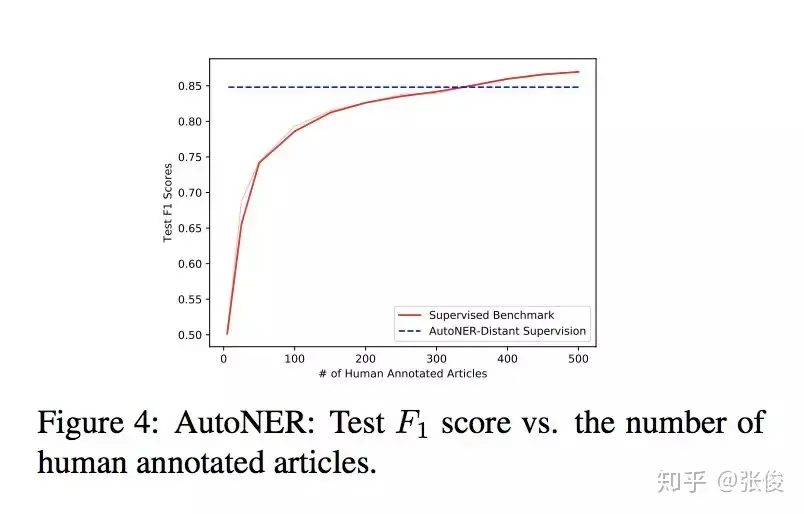
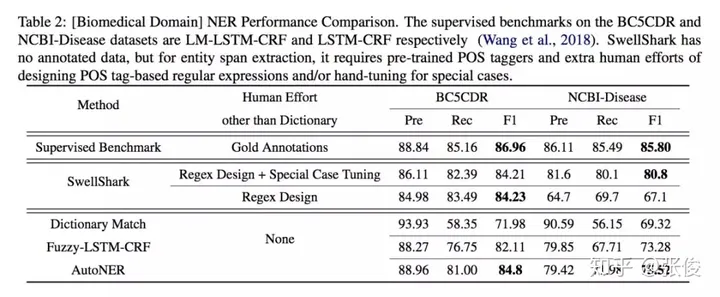
本研究由UIUC、USC与触宝科技联合完成,并发表在EMNLP 2018会议上。该论文提出了一种创新性的方法,无需人工标注即可自动标记数据并训练命名实体识别(NER)模型——AutoNER。经过实验验证,我们发现AutoNER训练出的模型在三个不同的数据集上,其性能都与监督基准相媲美。此外,在所有仅使用字典的方法中,AutoNER展现出了最佳的效果。



@paperweekly 推荐
#Knowledge Graph
论文链接:https://www.paperweekly.site/papers/2410源码链接:https://github.com/salesforce/MultiHopKG
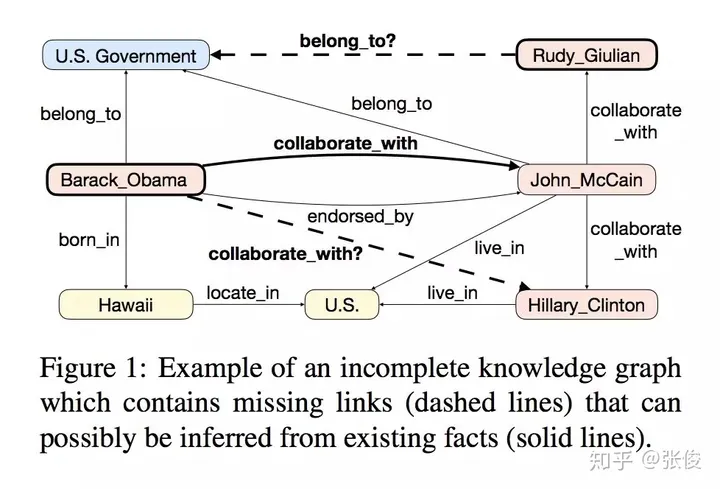
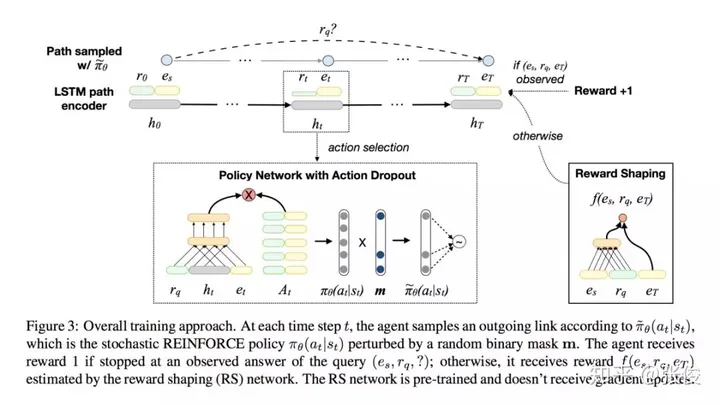
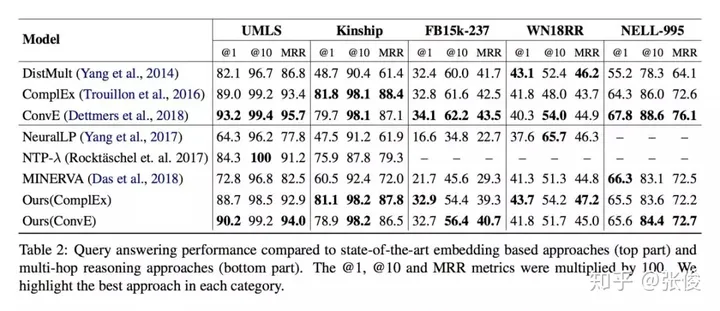
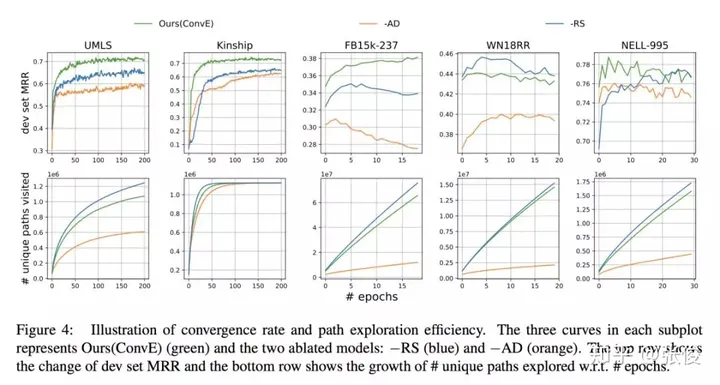
这篇文章是由Salesforce Research在EMNLP 2018上发表的,主要研究的是基于强化学习的知识图谱问答任务。为了提高模型的准确性和稳定性,作者提出了两个新的机制。首先,利用预训练的知识图谱嵌入模型,为任意三元组设定预期奖励,从而有效防止训练过程中出现的虚假负例对测试结果产生影响。其次,通过尝试各种路径,避免虚假路径对模型产生误导。这两个机制的提出,将有助于进一步提升基于强化学习 knowledge graph 的问答任务的性能。



@paperweekly 推荐
#Abstractive Summarization
论文链接:https://www.paperweekly.site/papers/2448源码链接:https://github.com/yingtaomj/Iterative-Document-Representation-Learning-Towards-Summarization-with-Polishing
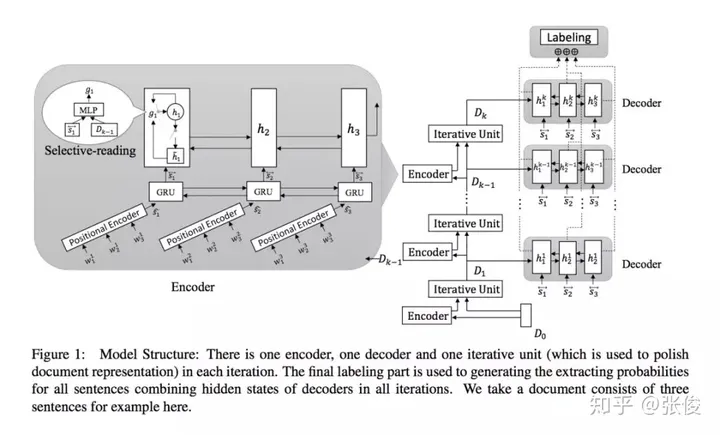
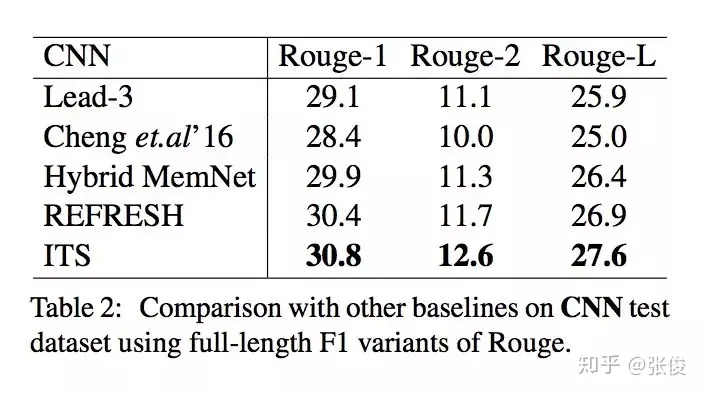
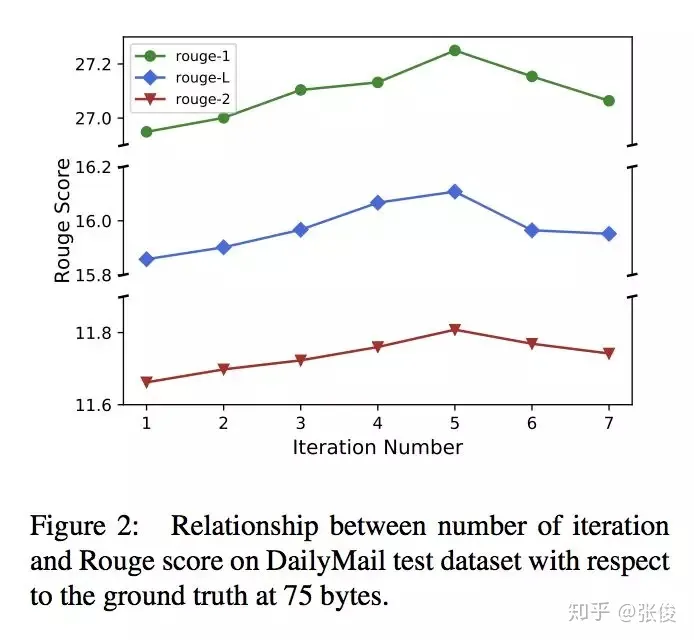
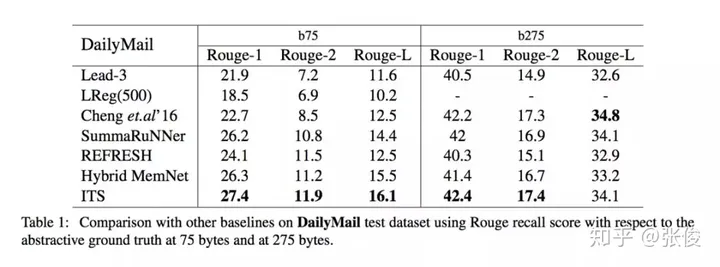
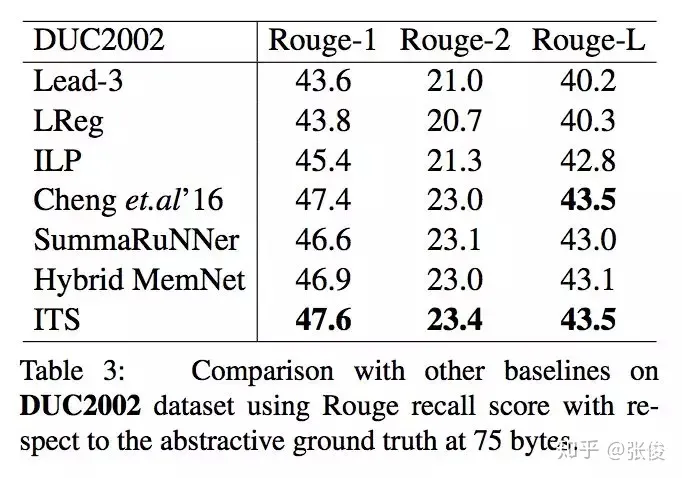
这篇文章是由北京大学和腾讯AI实验室于2018年在EMNLP会议上发表的。传统的摘要生成任务通常是基于单轮抽取的方法,而本文则提出了一个创新性的迭代式多轮摘要抽取模型,该模型引入了一种选择性读取机制,能够更准确地确定哪些句子需要更新。在实验中,本文的模型在CNN/DailyMail和DUC2002数据集上都表现出了SOTA(最佳性能)的水平。与传统的摘要生成方法相比,本文提出的模型具有更高的准确性和更好的可扩展性,能够在处理大规模文本时提供更好的表现。因此,本文的模型对于自然语言处理领域中的摘要生成任务具有重要的研究意义和应用价值。


@yangchengTHU 推荐
#Chinese Poetry Generation
论文链接:https://www.paperweekly.site/papers/2500
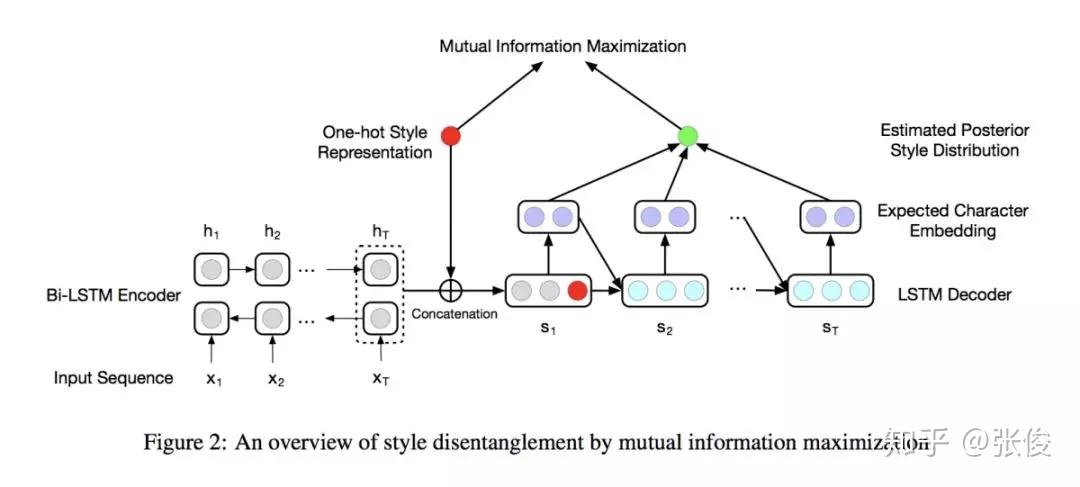
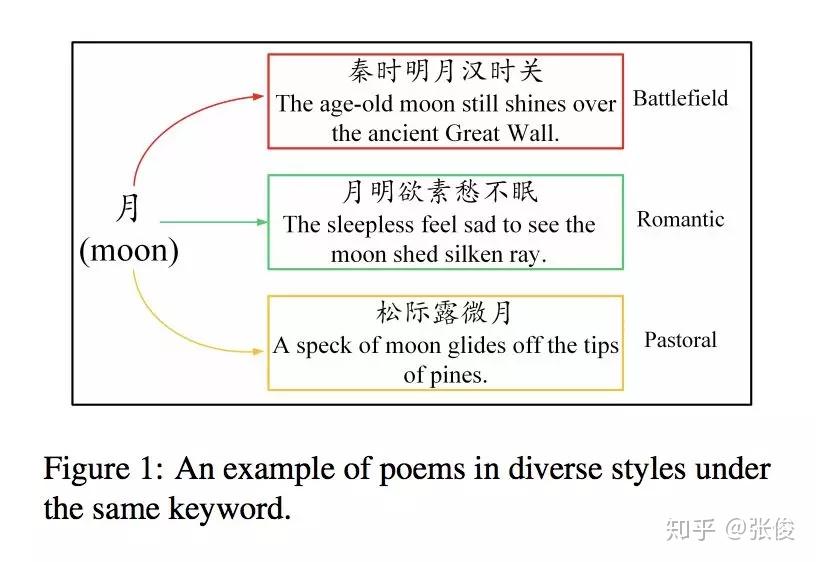
本文是清华大学发表于 EMNLP 2018 的工作。传统的中国古诗生成模型普遍采用机器翻译中的 seq2seq 模型,用上一句的诗句作为输入,预测生成下一句作为输出。但是机器翻译任务和古诗生成任务有很大的不同:机器翻译任务中输入与输出的一一对应关系比较强,如中英翻译中中文出现了“苹果”一词则英文翻译中就会出现“apple”;而诗歌生成任务中却是一对多的情况,即便作为输入的上句提到了“月”这个意象,下句也可能有风格迥异的完全不同的输出。如果使用机器翻译模型训练诗歌语料,则会有很大概率会生成例如“不知何处去”这种非常普遍但没有什么实质含义的句子,很难学习到不同风格的输出。
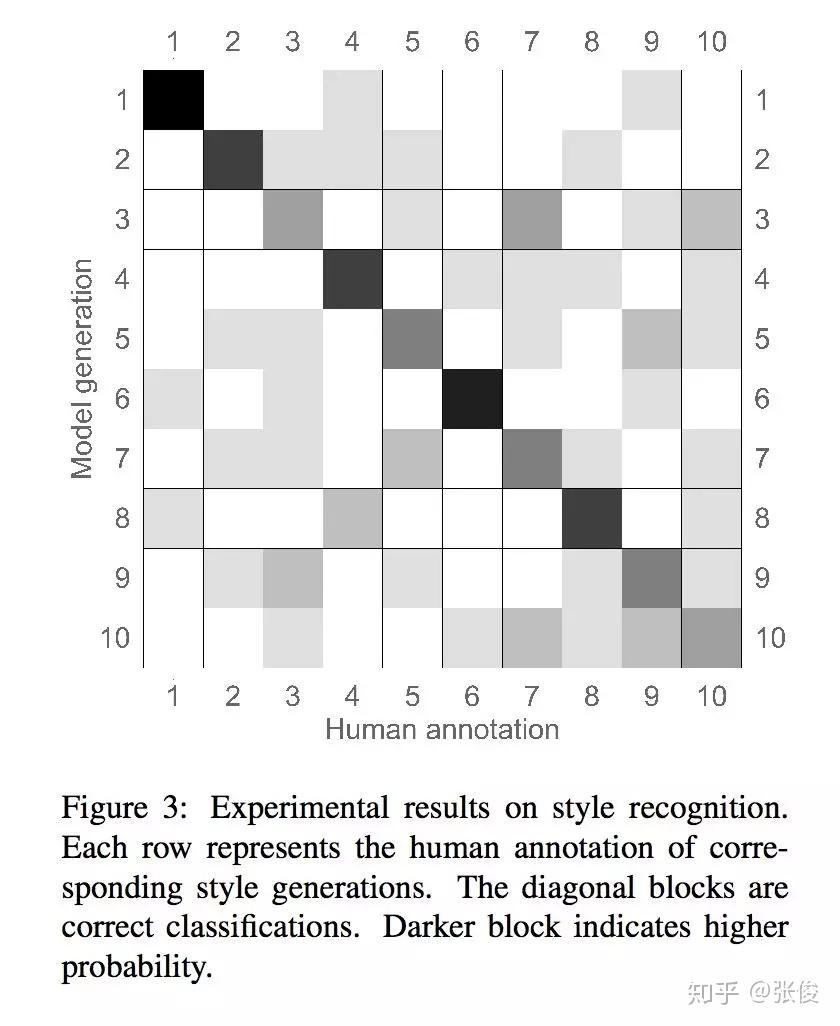
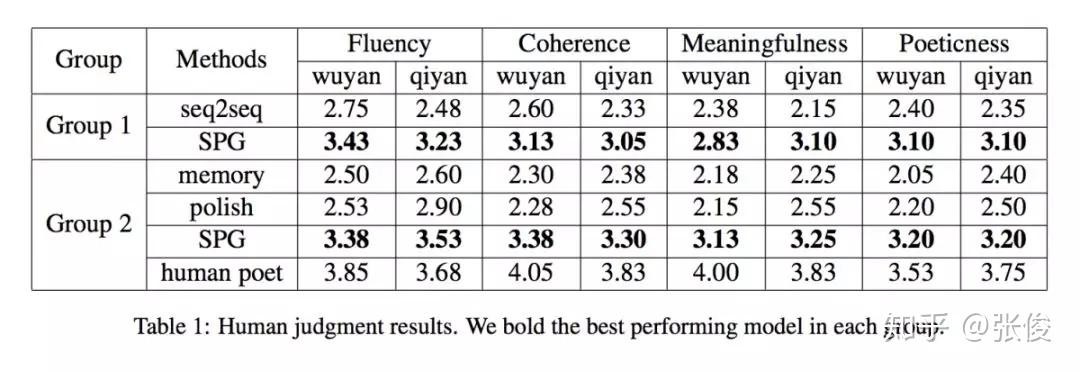
本文提出了一种对于同一输入可以产生多个输出的生成模型,同时保证不同的输出之间有较大的区分性。另一方面,因为语料库中对于诗歌风格暂时没有专家标注,我们的模型利用互信息作为约束正则项,可以实现完全无监督的风格生成。人工评测结果表明,我们的模型生成的各种风格都是可识别的,并且其他指标也优于基线模型。


@paperweekly 推荐
#Sequence Labelling
论文链接:https://www.paperweekly.site/papers/2468
源码链接:https://github.com/minghao-wu/CRF-AE
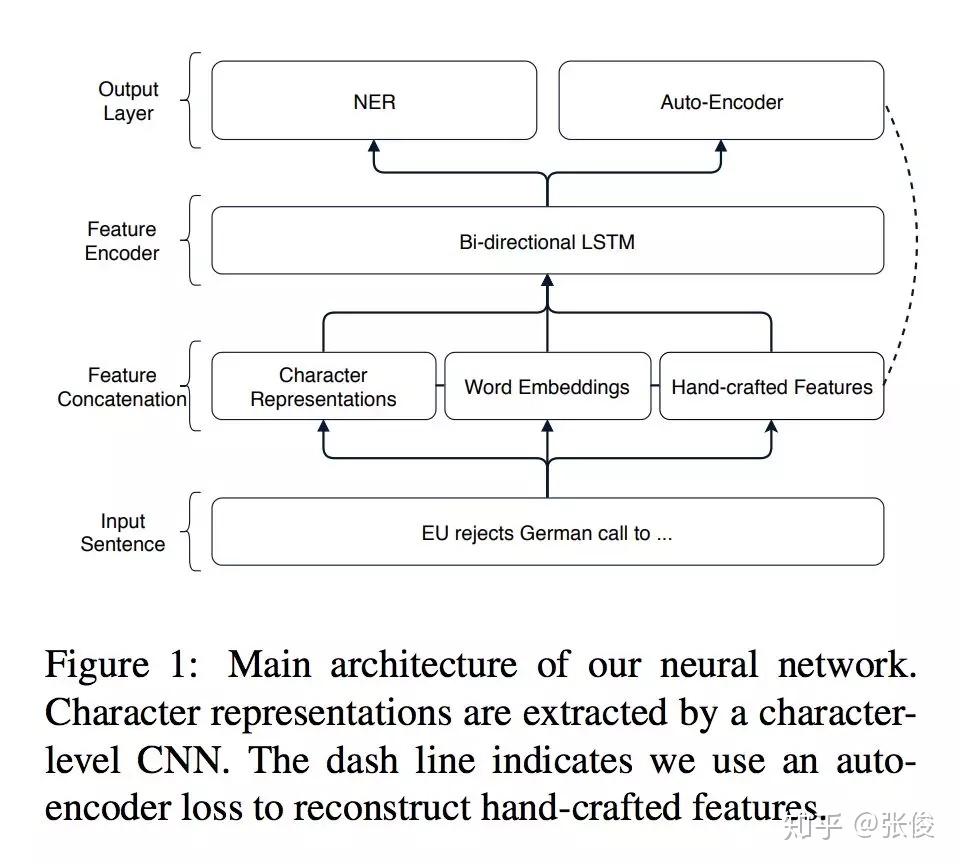
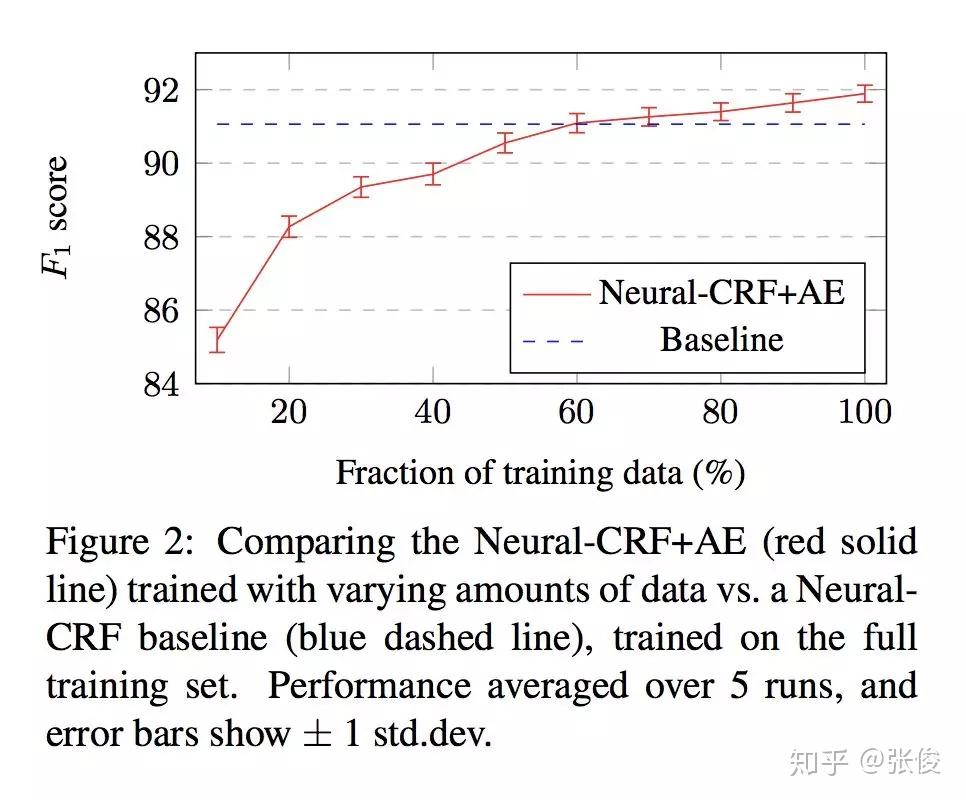
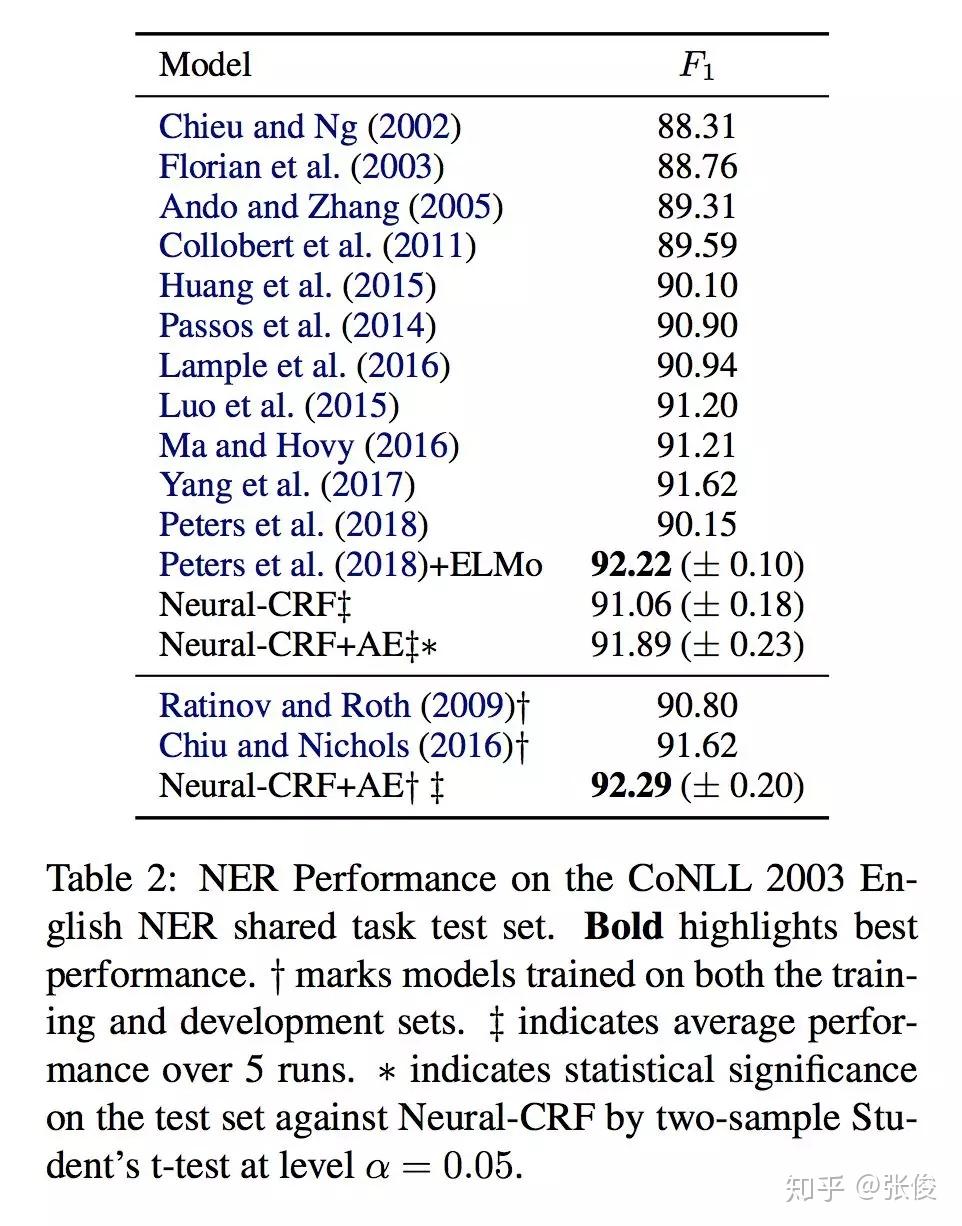
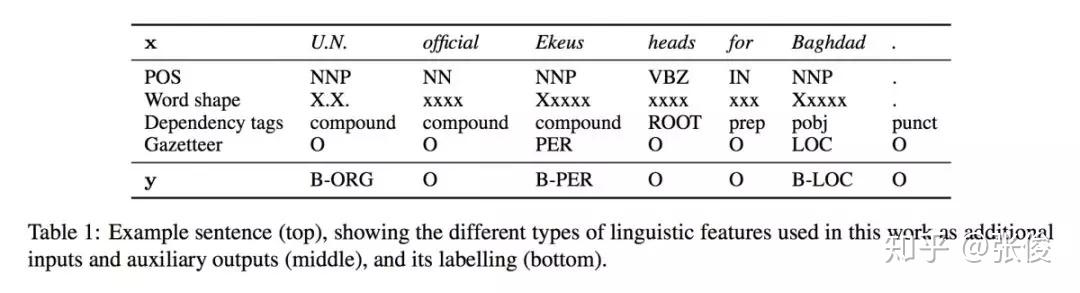
本文是墨尔本大学和京东发表于 EMNLP 2018 的工作,论文针对端到端模型提出了一种全新利用特征工程的方法,将 Auto-Encoder 嵌入端到端模型中。在训练阶段,在手动提取特征之后,将其输入到深度学习 Encoder 中,随后在输出端重建特征并计算损失函数做反向传播。在预测阶段,只将手动提取特征输入到 Encoder 中,但不重建特征。

@ttmy5 推荐
#Object Detection
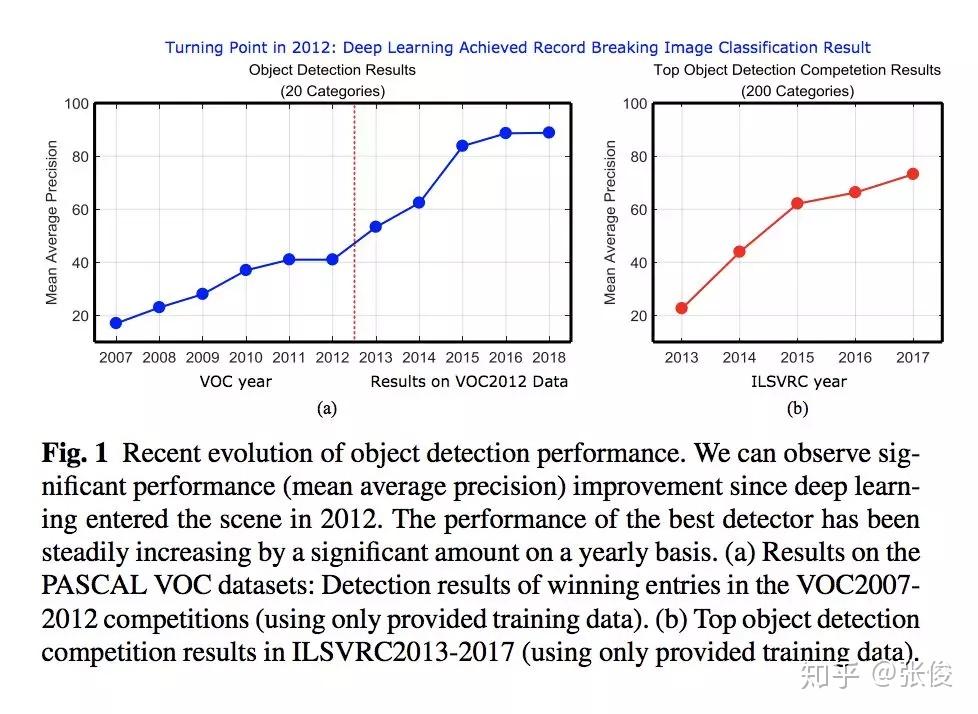
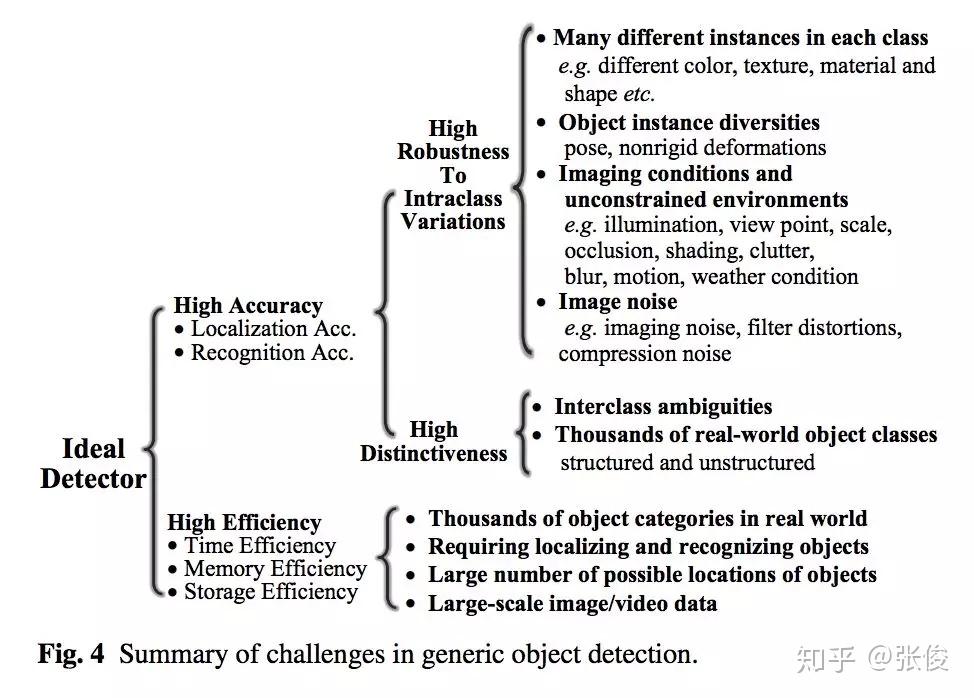
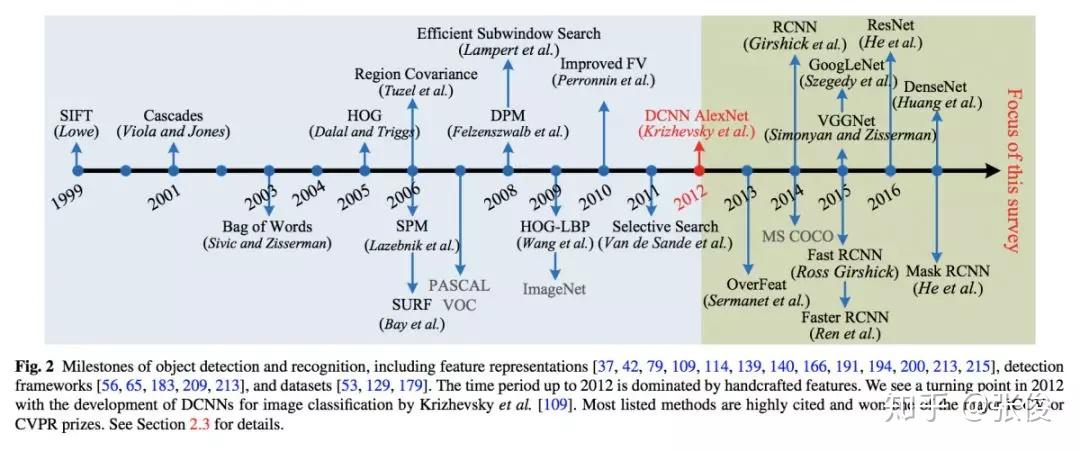
本文总结了最近 5 年来计算机视觉重要领域——目标识别的重要进展。内容非常详细,是目标识别领域这几年来少见的综述,文章指出了未来值得研究的几个方向,对研究者有很大的指导意义。该文章也已提交 IJCV 候审。


论文链接:https://www.paperweekly.site/papers/2461

@darksoul 推荐
#Convolutional Neural Networks
论文链接:https://www.paperweekly.site/papers/2471
源码链接:https://github.com/hujie-frank/GENet
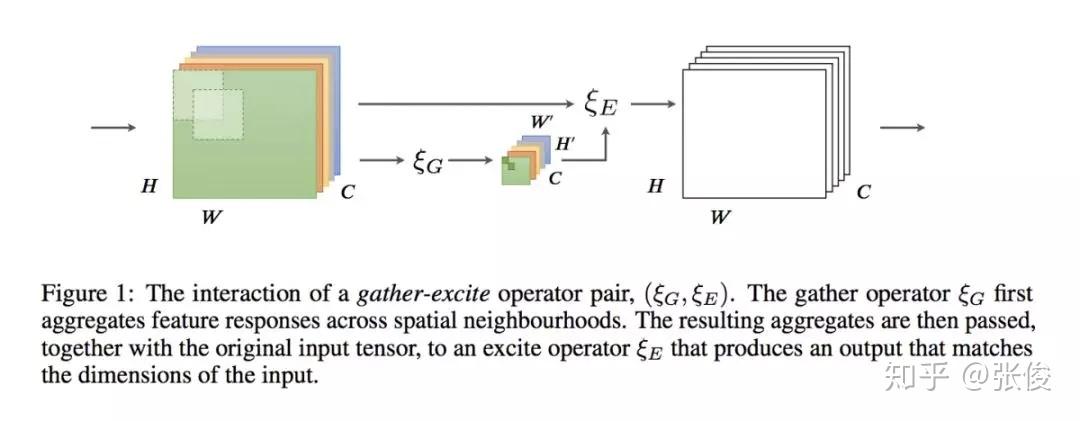
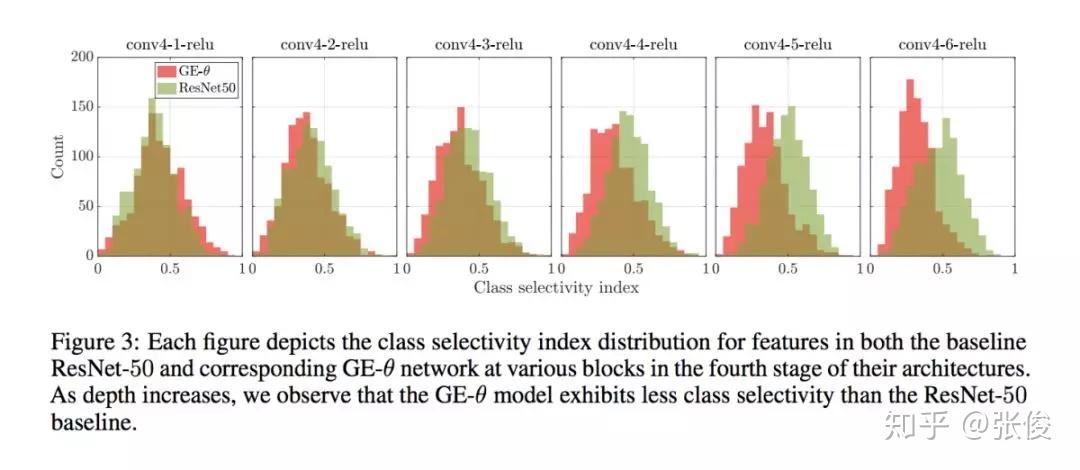
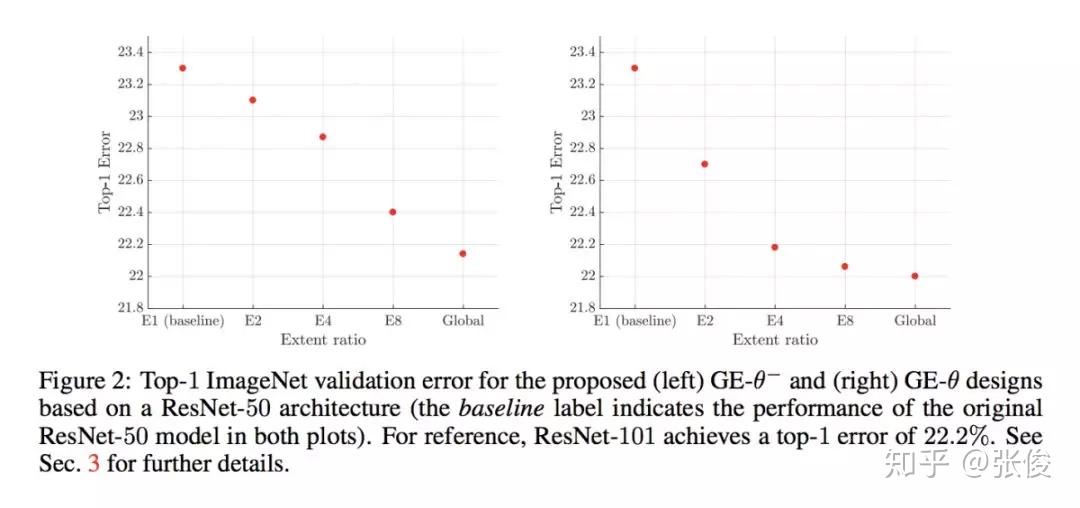
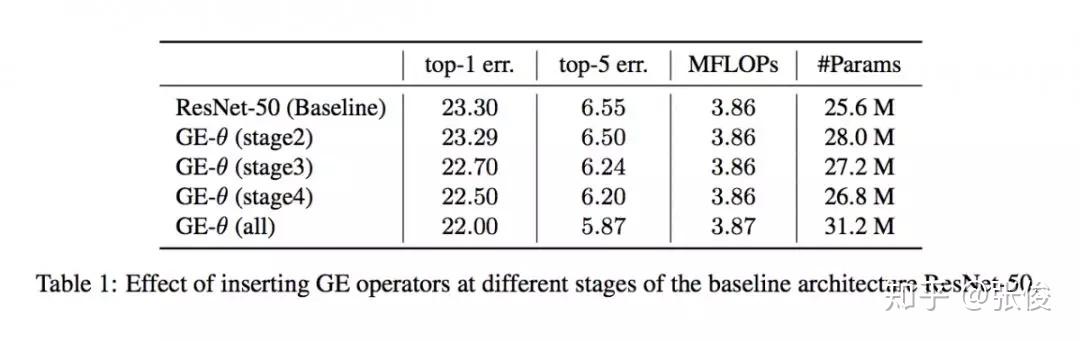
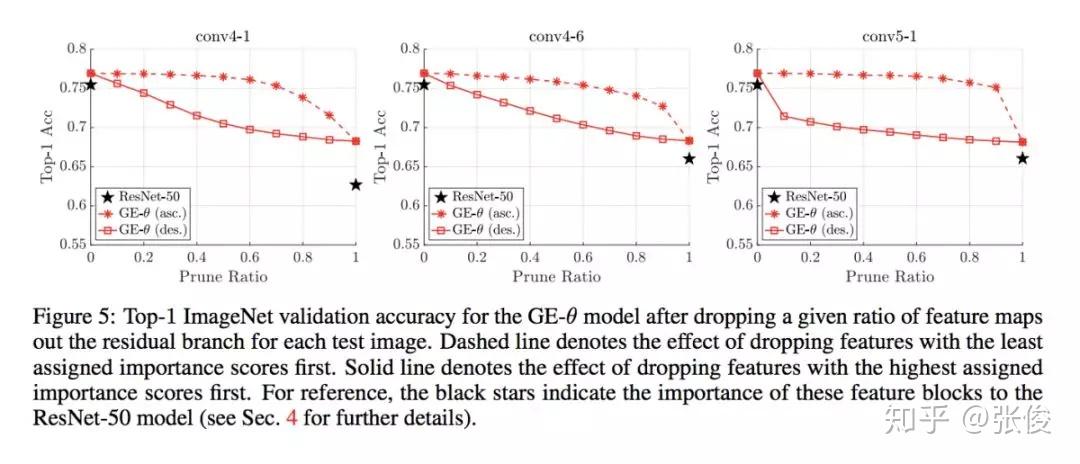
本文是 Momenta 和牛津大学发表于 NIPS 2018 的工作,论文来自原 SENet 作者。本文使用了一种新的 attention 机制,对 feature map 上每一个点单独学习weight。
论文思路和 CBAM 相似,不同之处在于学习 weight 的方式,文章使用了 g 和 e 两个主要模块,g 部分将原 feature 尺度精炼缩小,e 将精炼的 feature 进行插值还原到原始尺度,使用 Hadamard Product 的方式将原始 feature 进行重构(本质上是将原始 feature 上的高响应部分进行放大,也就是文章说的 excite 过程)。
SENet 本质上是对每个 channel 进行 weight,本文提出的 GENet 则是从本质上对 feature 每个点进行 weight。从包含关系上讲,SENet 是 GENet 的一种特例。论文想法简单,有种大道至简的感觉。

@Kralkatorrik 推荐
#Face Recognition
论文链接:https://www.paperweekly.site/papers/2463
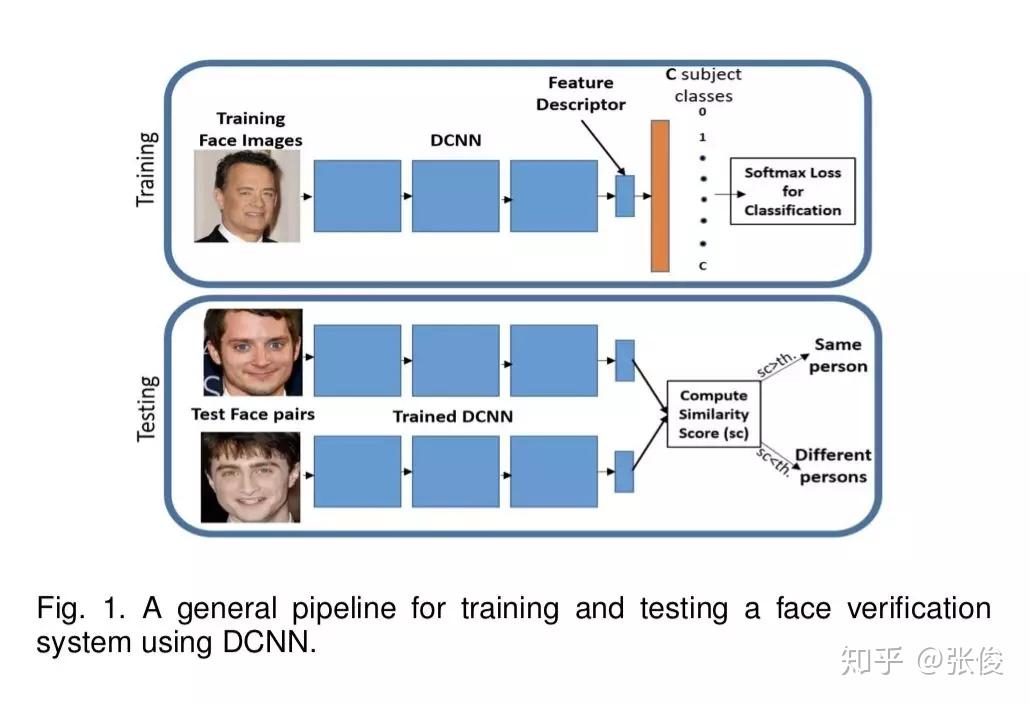
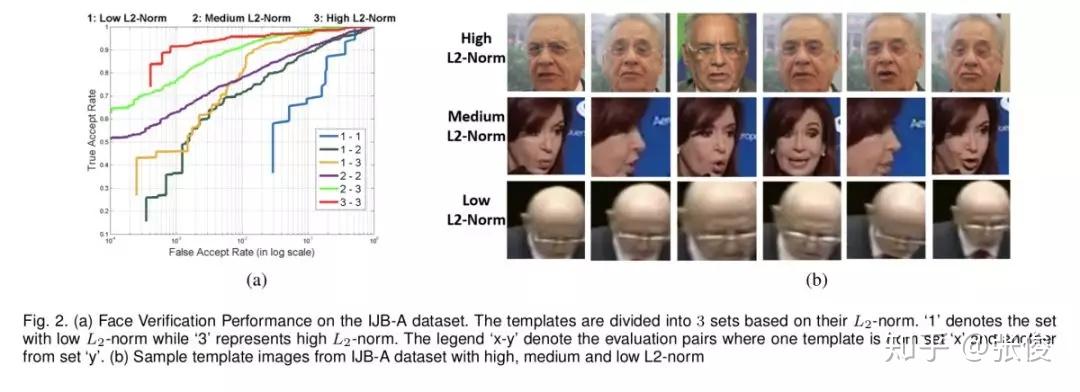
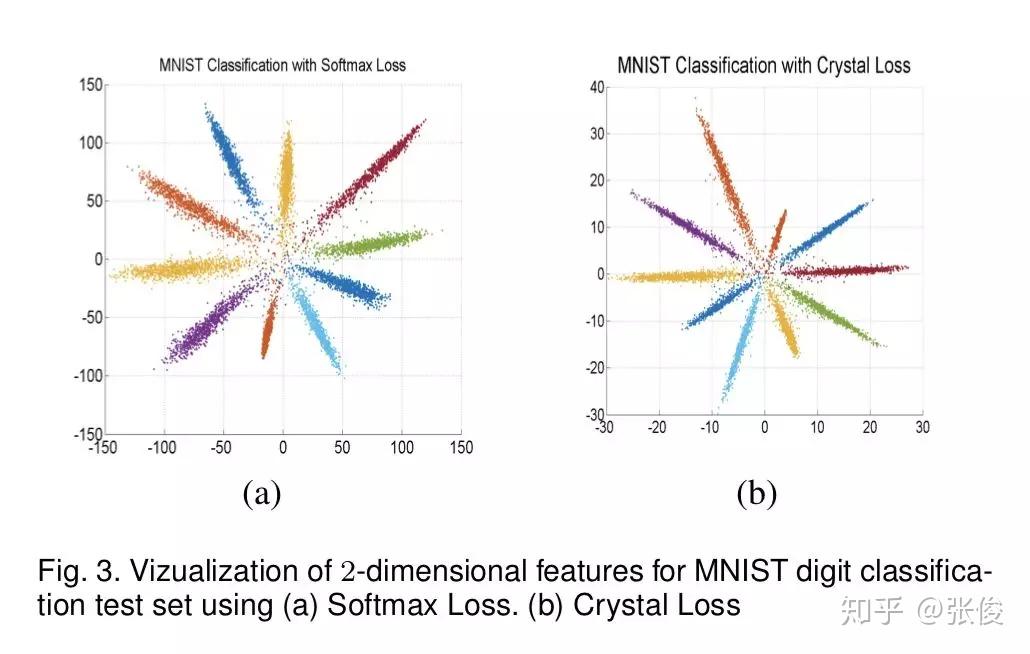
本文是 L2-Softmax 作者对之前工作的扩展,作者将 L2-Softmax 更名为 Crystal Loss,分析了在视频人脸验证的流程中序列特征取平均值,由于不同帧之间图像质量不同,会导致这样的特征表达是非最优的。于是作者引入了 Quality Pooling 概念,通过检测得到的 bbox score 来对序列特征做 rescale,最终能够在 LFW、IJB 等数据集上达到 SOTA 效果。
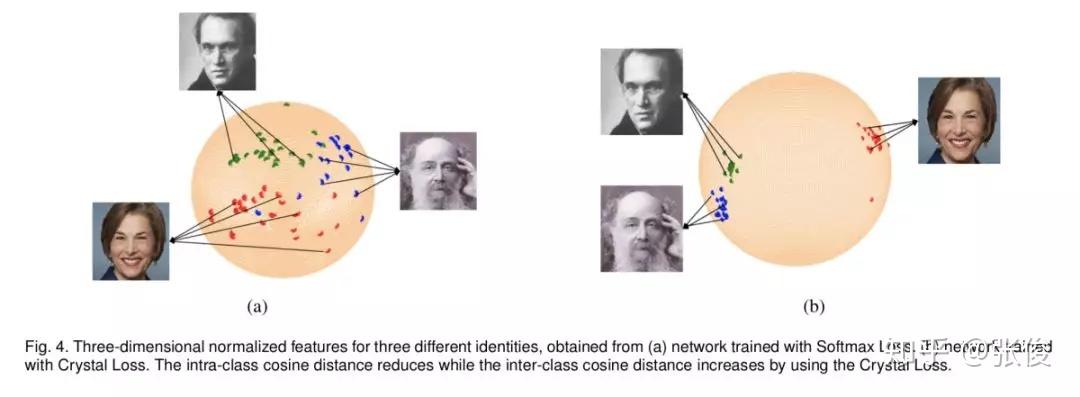
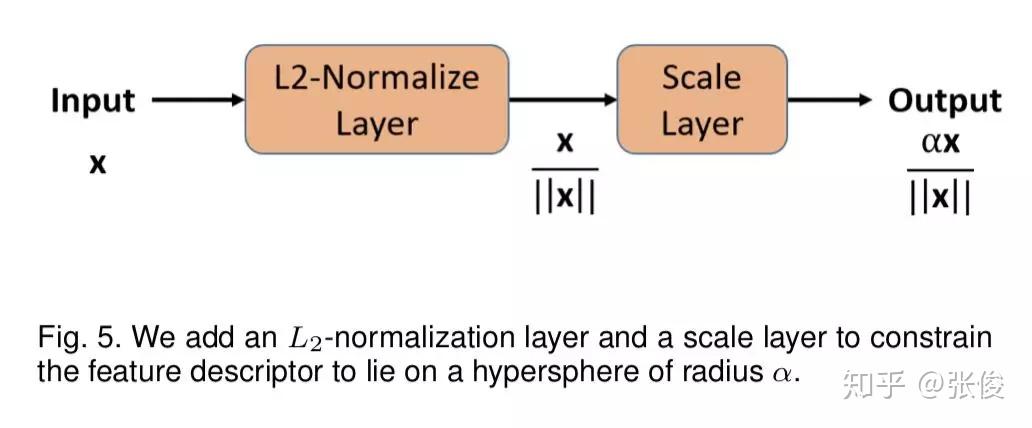

@paperweekly 推荐
#Person Re-identification
论文链接:https://www.paperweekly.site/papers/2363
本文是 Argo AI 和拉瓦尔大学发表于 ECCV 2018 的工作,论文提出了一个全新合成数据集 SyRI dataset,该数据集通过改变 HDR 参数等方法,使得一个行人 ID 可拥有一百多个环境下图像数据。此外,为了在未见过的真实场景中实现更好的域适应效果,论文基于这个合成数据集提出了一种新的方法,这个方法性能超越了目前最先进的半监督和无监督的方法。


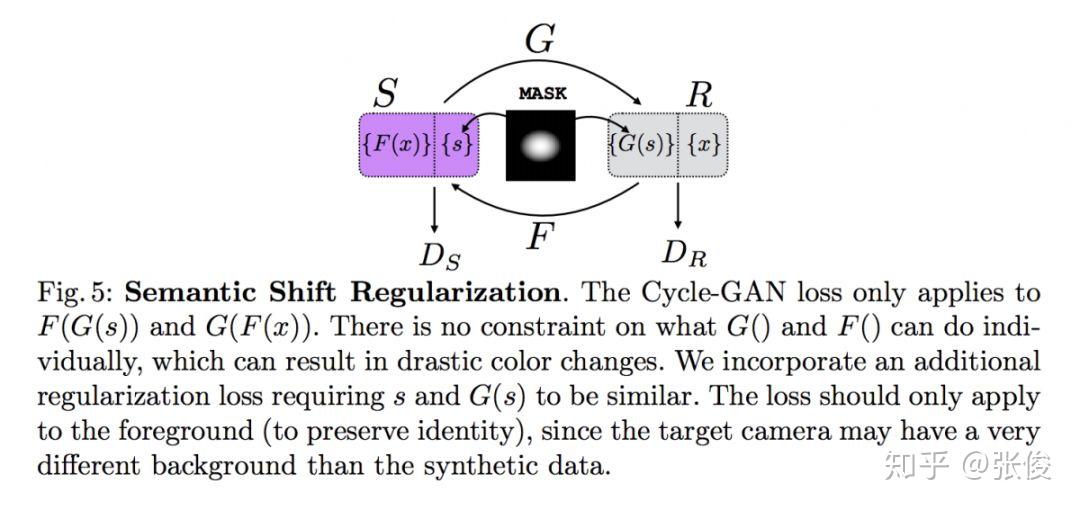

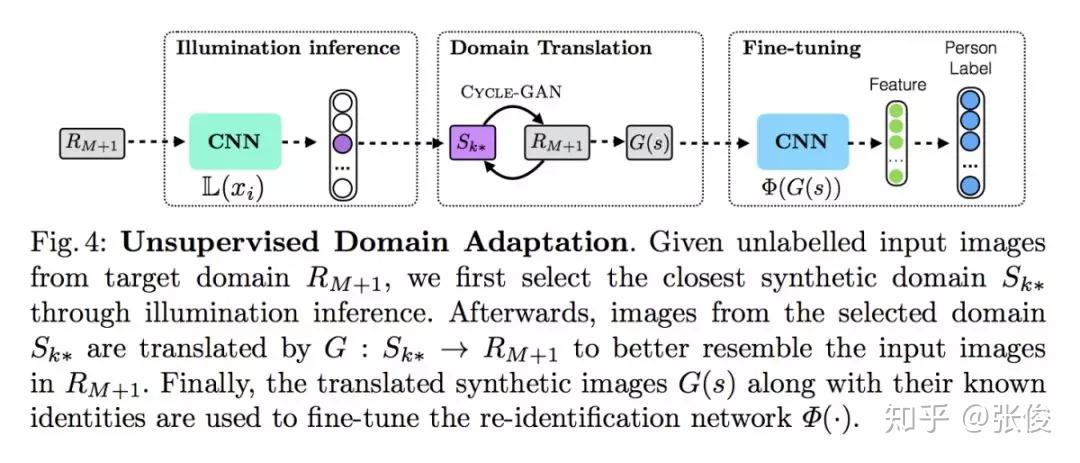

@zhangjun 推荐
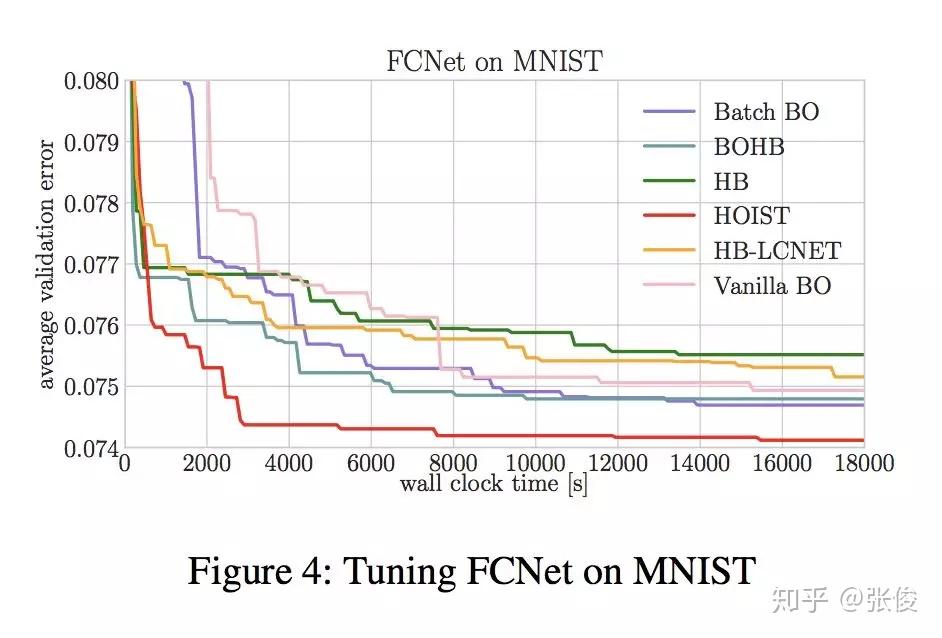
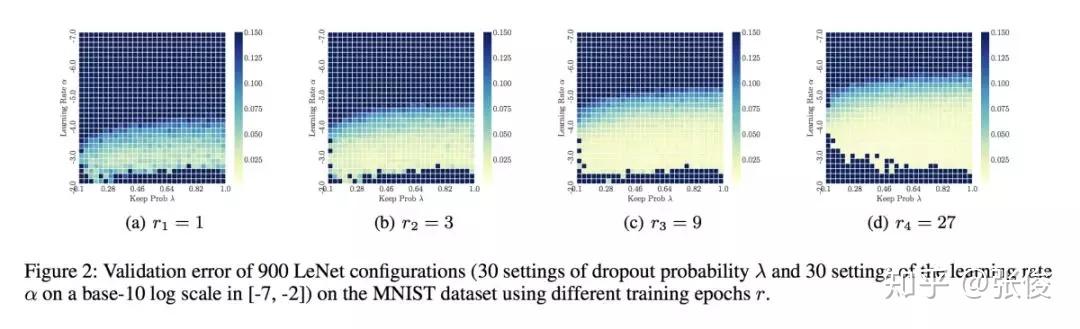
#Hyperparameter Optimization
论文链接:https://www.paperweekly.site/papers/2478
本文来自 AAAI 2019,针对深度神经网络超参优化时间成本过高的问题,论文提出了一种将多个代理模型进行集成的方法,并在 CNN、RNN、VAE 等 DNN 模型中进行了效果验证。
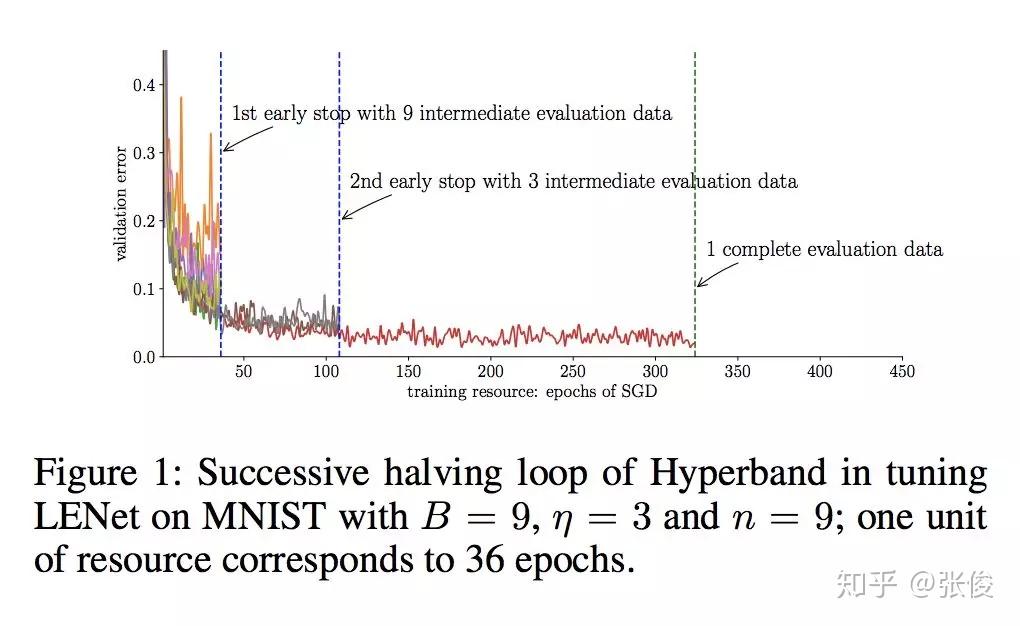
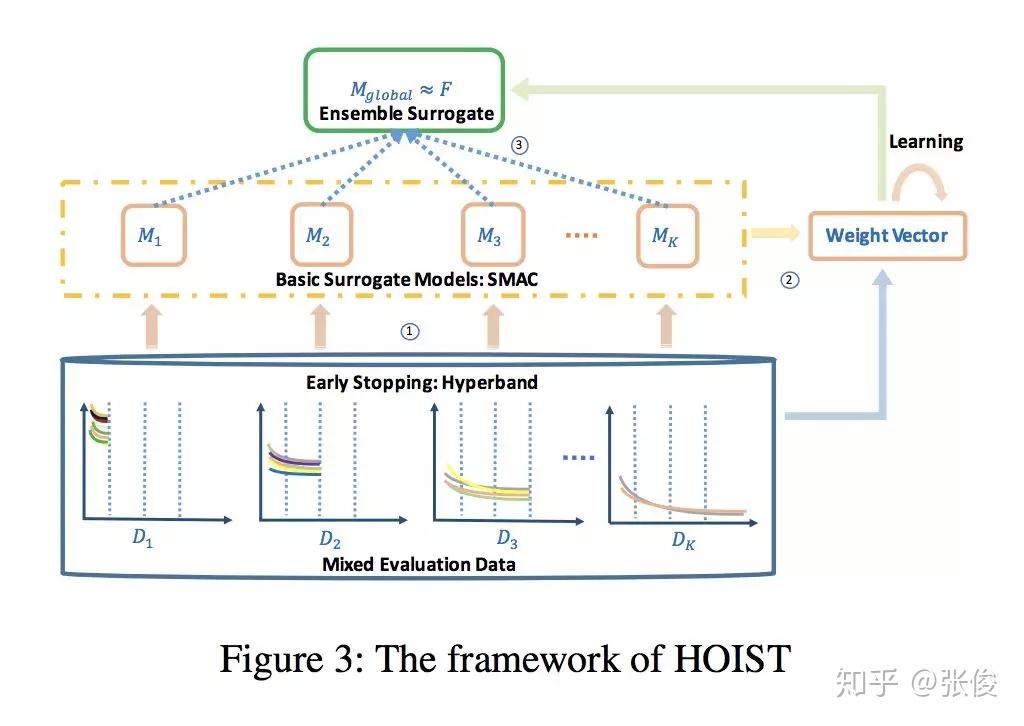


@jindongwang 推荐
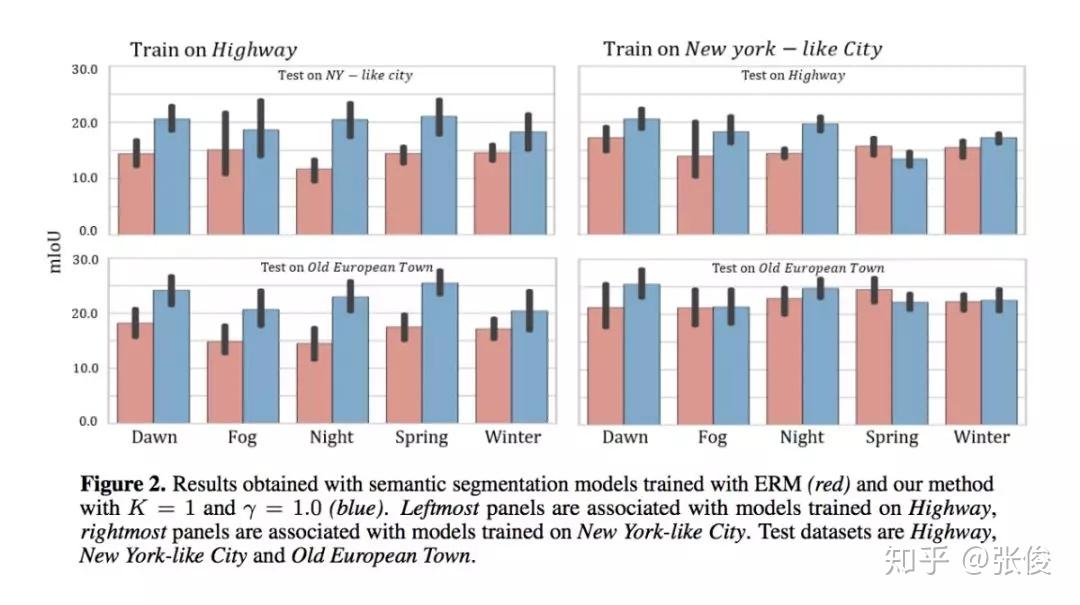
#Domain Generalization
论文链接:https://www.paperweekly.site/papers/2481
源码链接:https://github.com/ricvolpi/generalize-unseen-domains
本文是斯坦福大学发表于 NIPS 2018 的工作,论文研究的问题是比域自适应(Domain Adaptation)更前沿的一个方向——Domain Generalization。
在迁移学习领域,数据主要分为源域和目标域,源域的数据和标签是可获得的,而目标域的数据标签获得成本高,现有的一些迁移学习方法主要是在做源域和目标域的数据特征分布的对齐对源域用监督训练,而对于目标域任务应用无监督学习。但对于有些目标任务,目标领域的数据可能非常缺失或者获得成本非常高,以至于只有很少的目标域数据,甚至没有目标域数据。
为了应对这种目标领域数据缺失或收集成本高的挑战,作者提出了用于 Domain Generalization 的对抗增强迁移方法。该方法的大致思路介绍如下:这是一种无监督的对抗数据增强迁移学习方法,在该方法中,作者利用了样本级和特征级的表征,以及语义损失和循环一致性,使得模型在样本层面和特征层面都能进行适应,在利用任务损失的同时能保持循环一致性,而且无需对齐的配对。

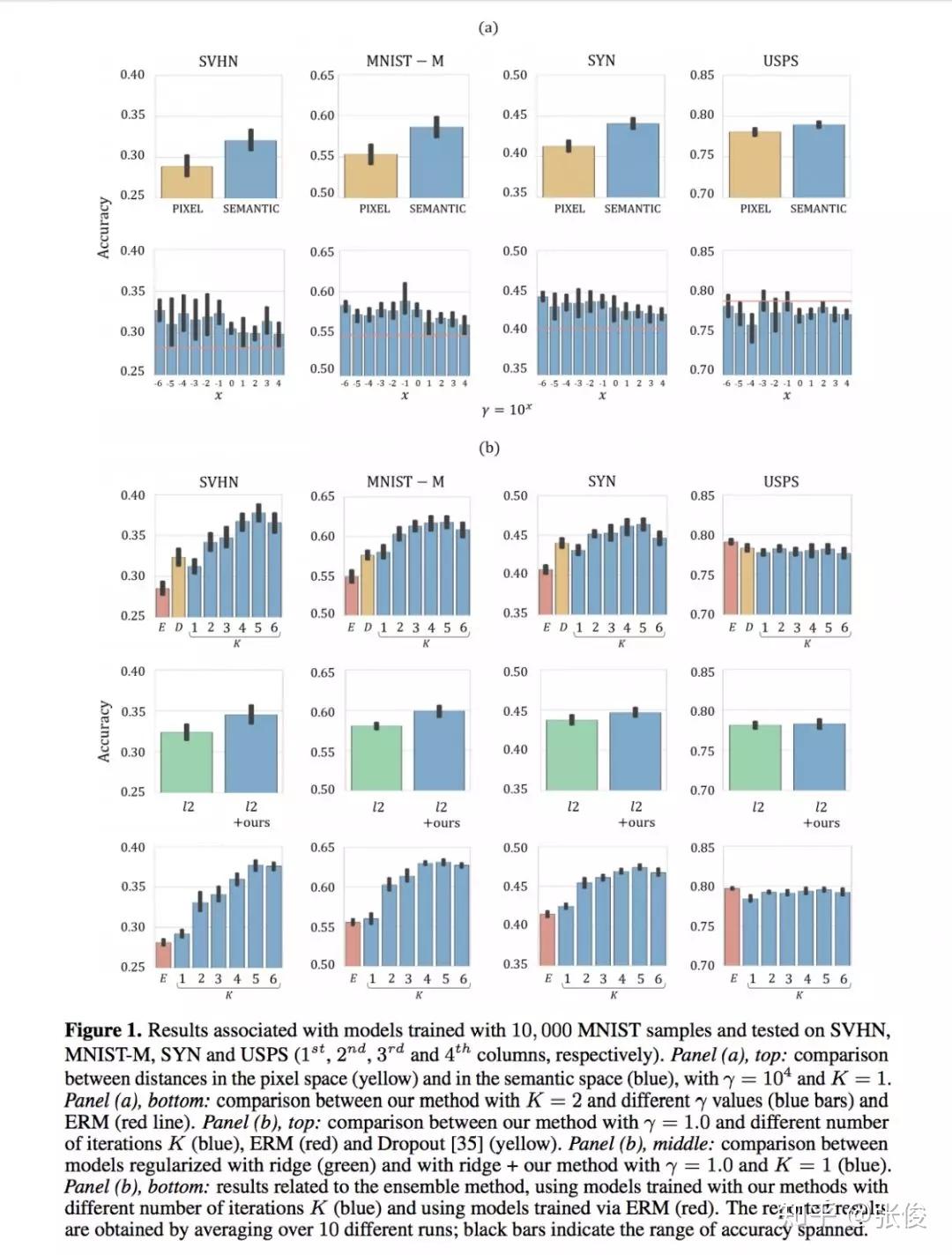
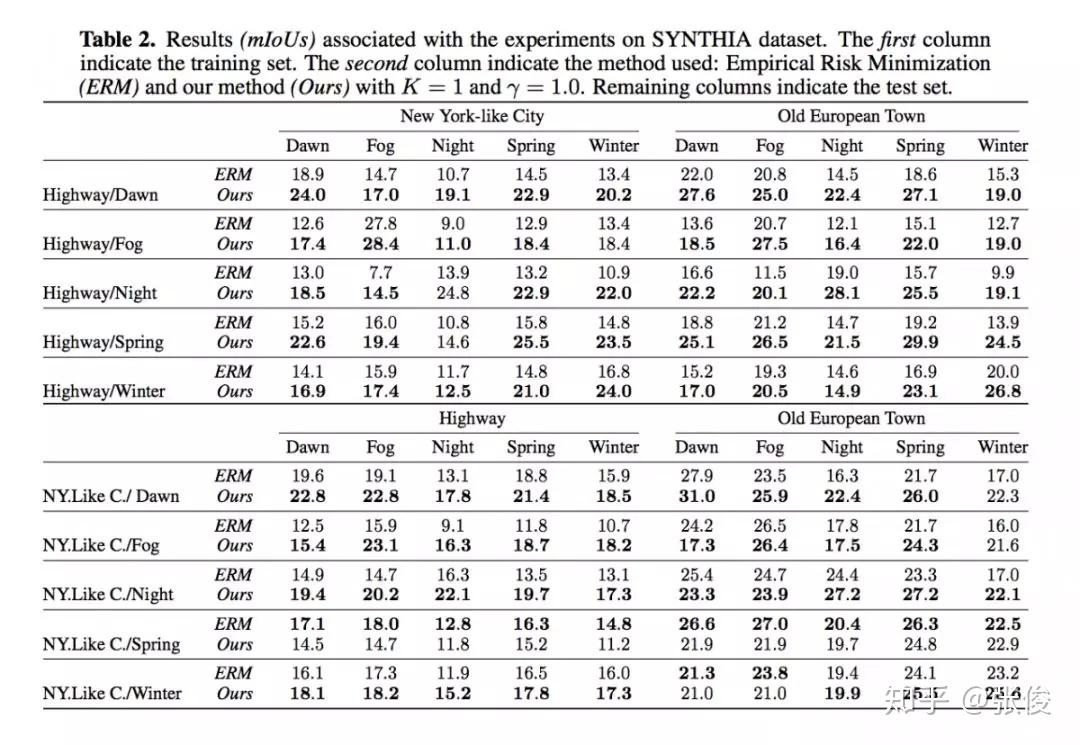
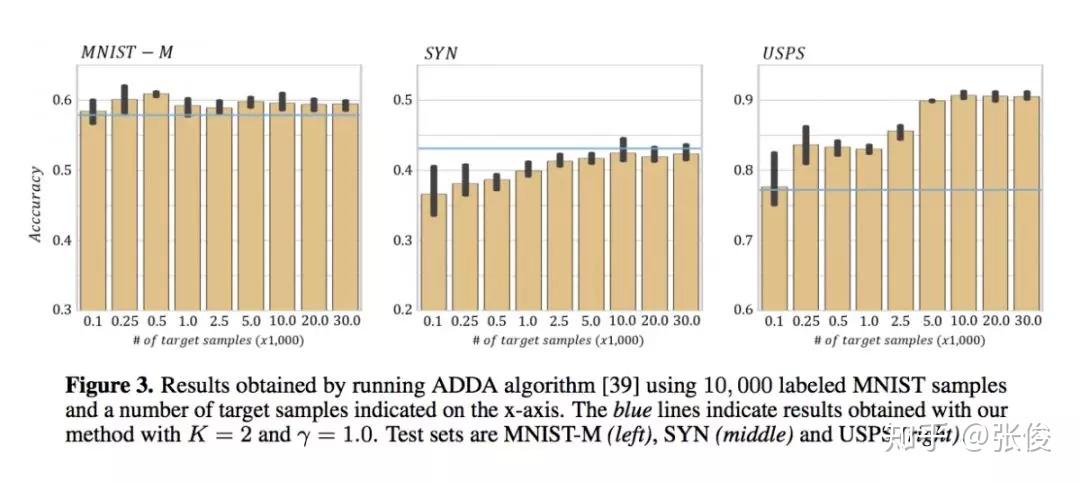

@paperweekly 推荐
#Recommender System
论文链接:https://www.paperweekly.site/papers/2458
源码链接:https://github.com/kang205/MoHR
本文是加州大学圣地亚哥分校发表于 CIKM 2018 的工作,论文借助混合专家模型(mixtures-of-experts)和知识图谱嵌入思想提出了一种全新框架,巧妙利用用户序列行为中相邻物品间的关系来解释用户在特定时间点的行为原因,进而基于用户的近期行为对其下一次行为进行预测。
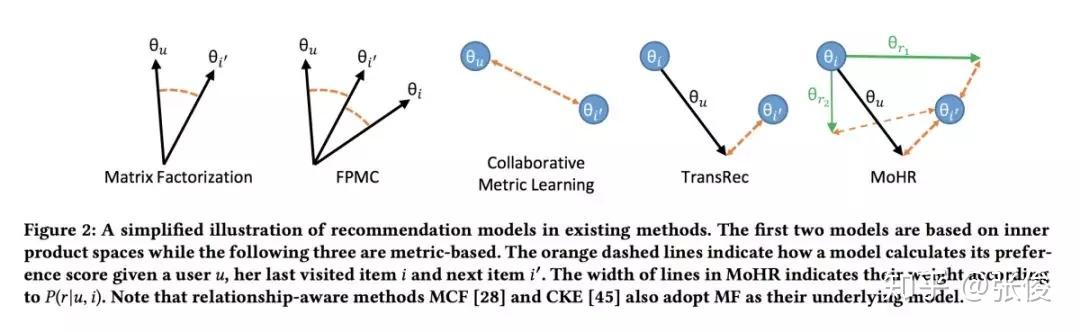
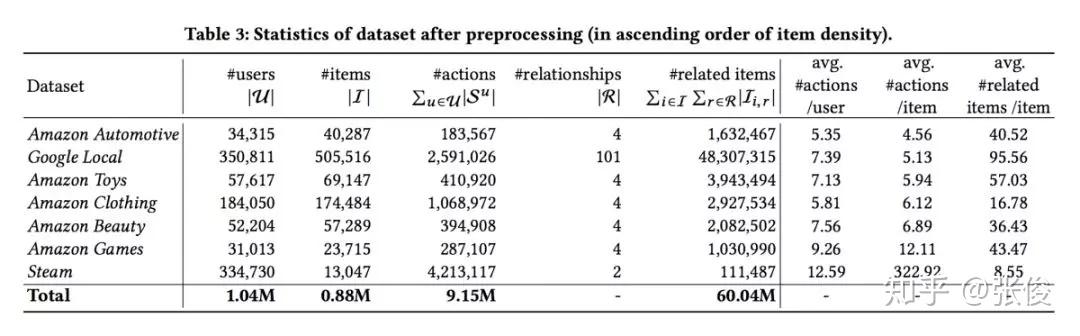

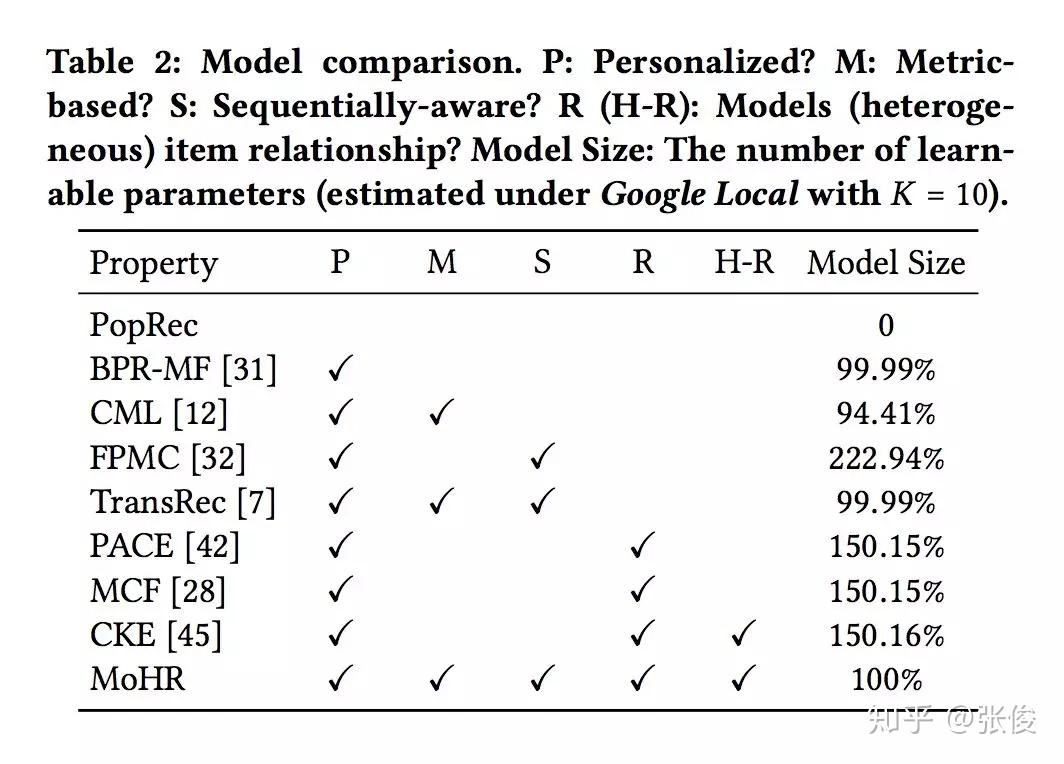
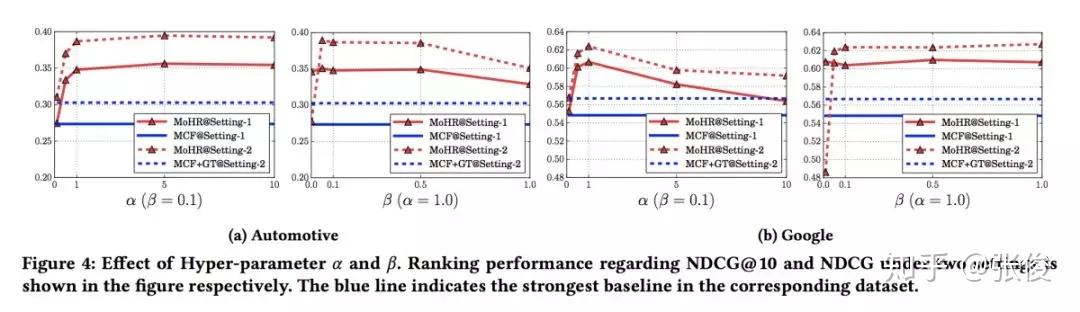

@xuzhou 推荐
#Time Series Analysis
论文链接:https://www.paperweekly.site/papers/2509
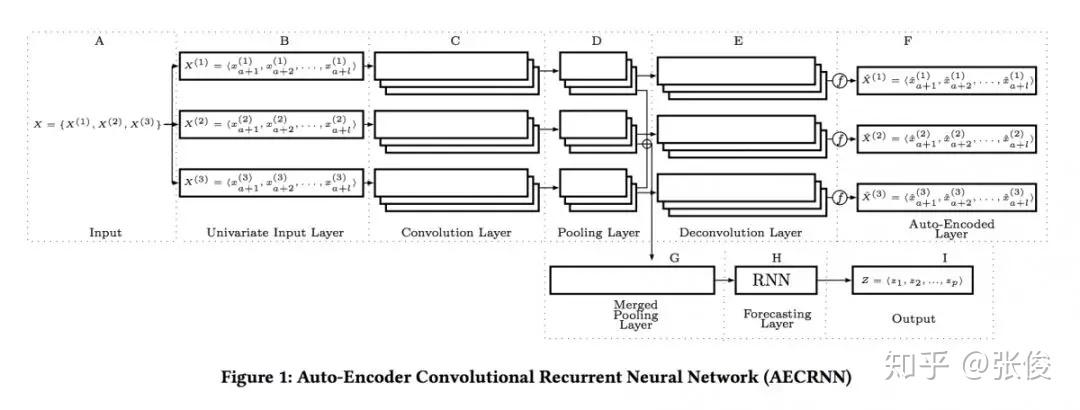
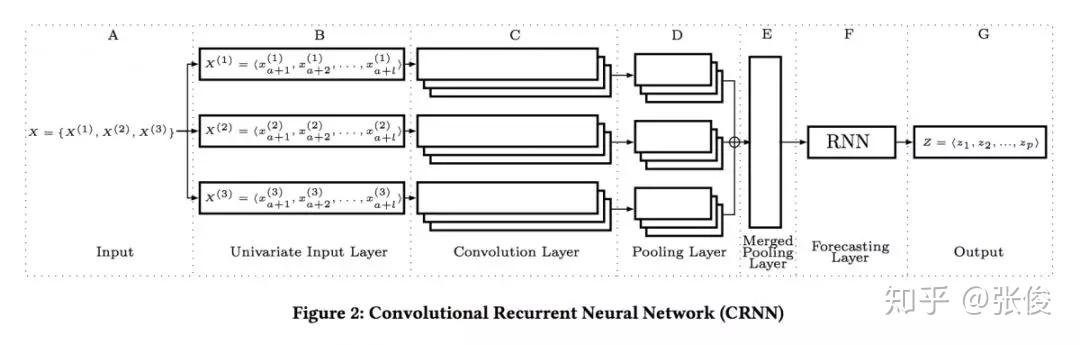
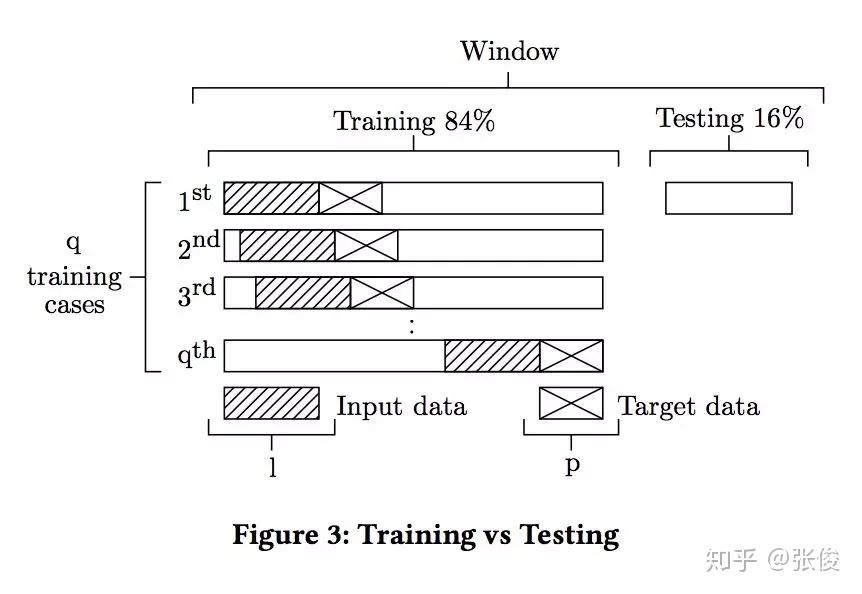
本文是奥尔堡大学发表于 CIKM 2018 的工作。为了确保准确预测时间序列,论文首次提出结合 CNN 和 RNN 来分析和提取时间序列特征并进行预测,将深度神经网络应用到时间序列分析,提供了启发性的研究。
具体来说,第一个模型在每一个时间序列上进行 CNN,组合卷积的特征并在卷进中的前几个特征上使用 RNN 进行预测。第二个模型在每一个 CNN 上添加了自动编码器,从而模型转换成了多任务学习模型,并且 juice 更加准确。两个真实数据集的实验结果显示了两个模型的有效性。
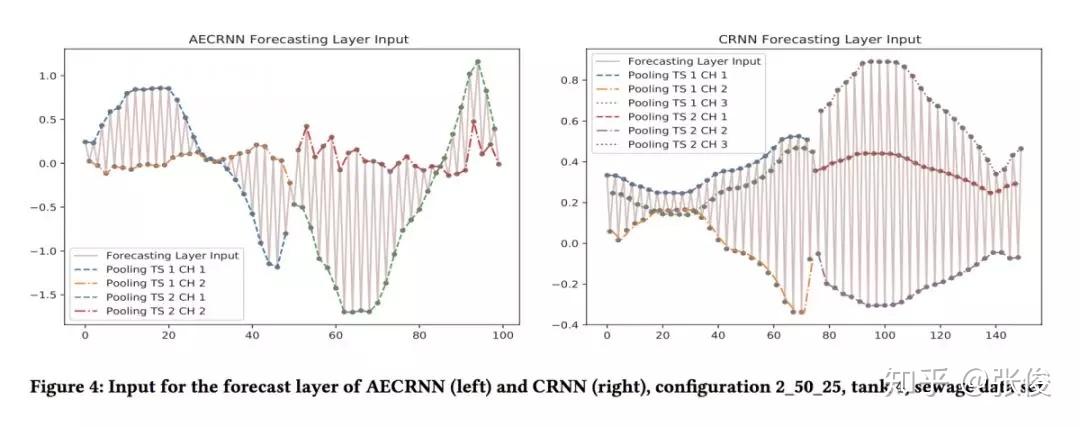
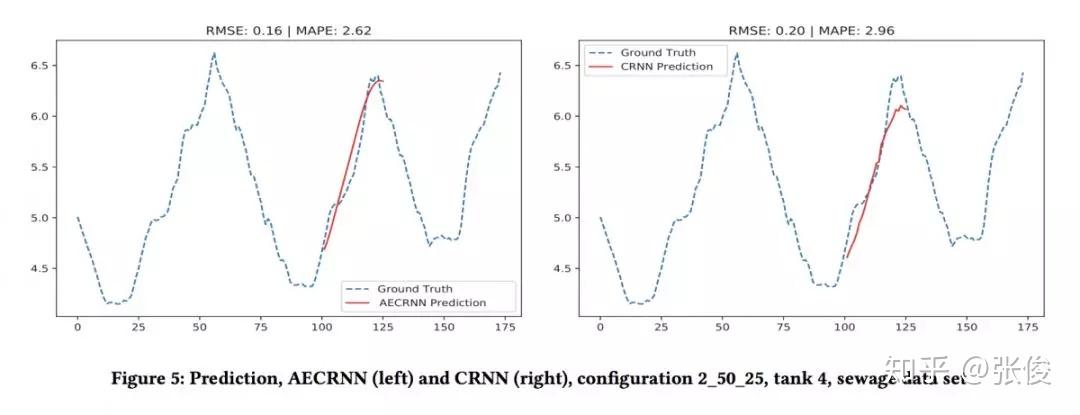

@xinqin 推荐
#Transfer Learning
论文链接:https://www.paperweekly.site/papers/2474
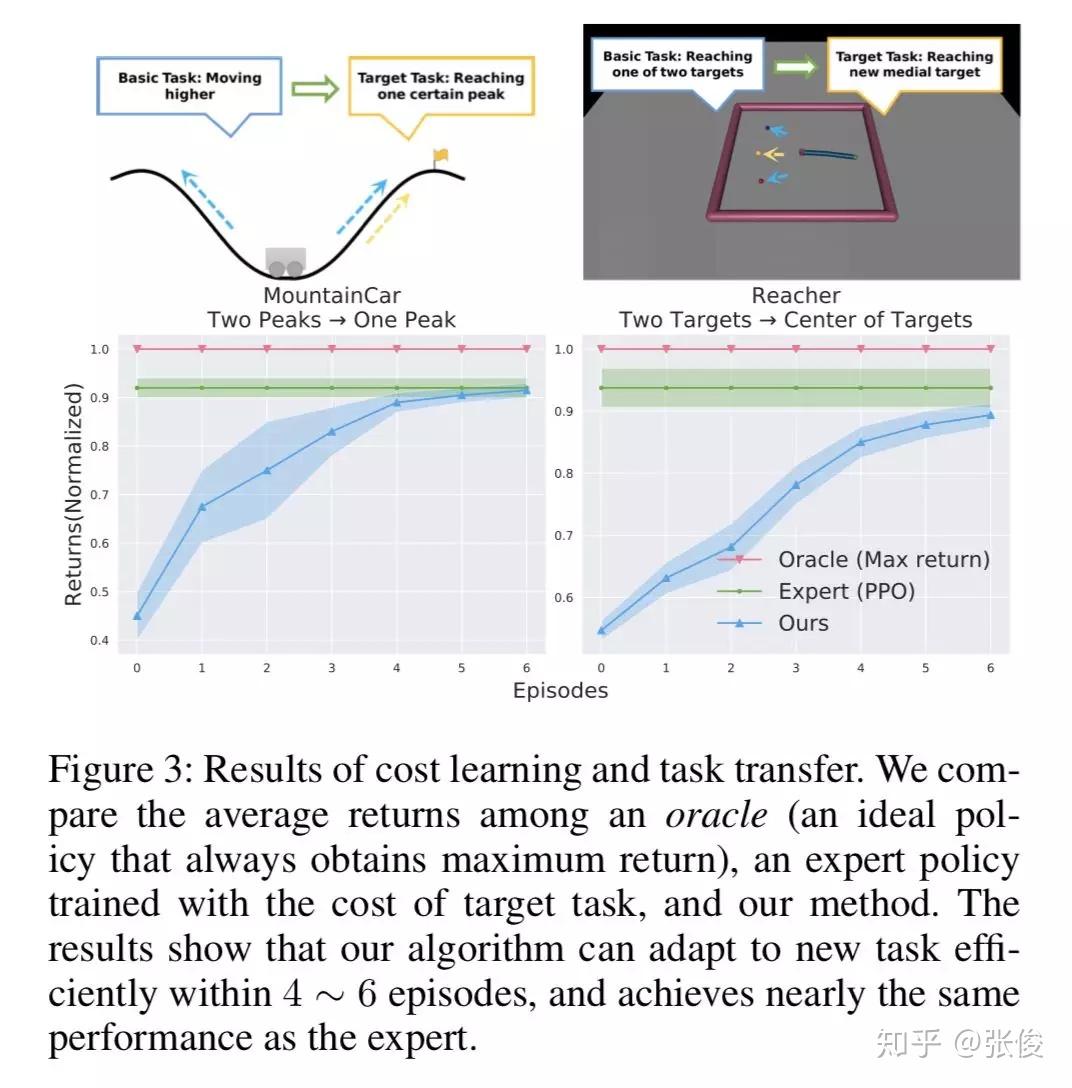
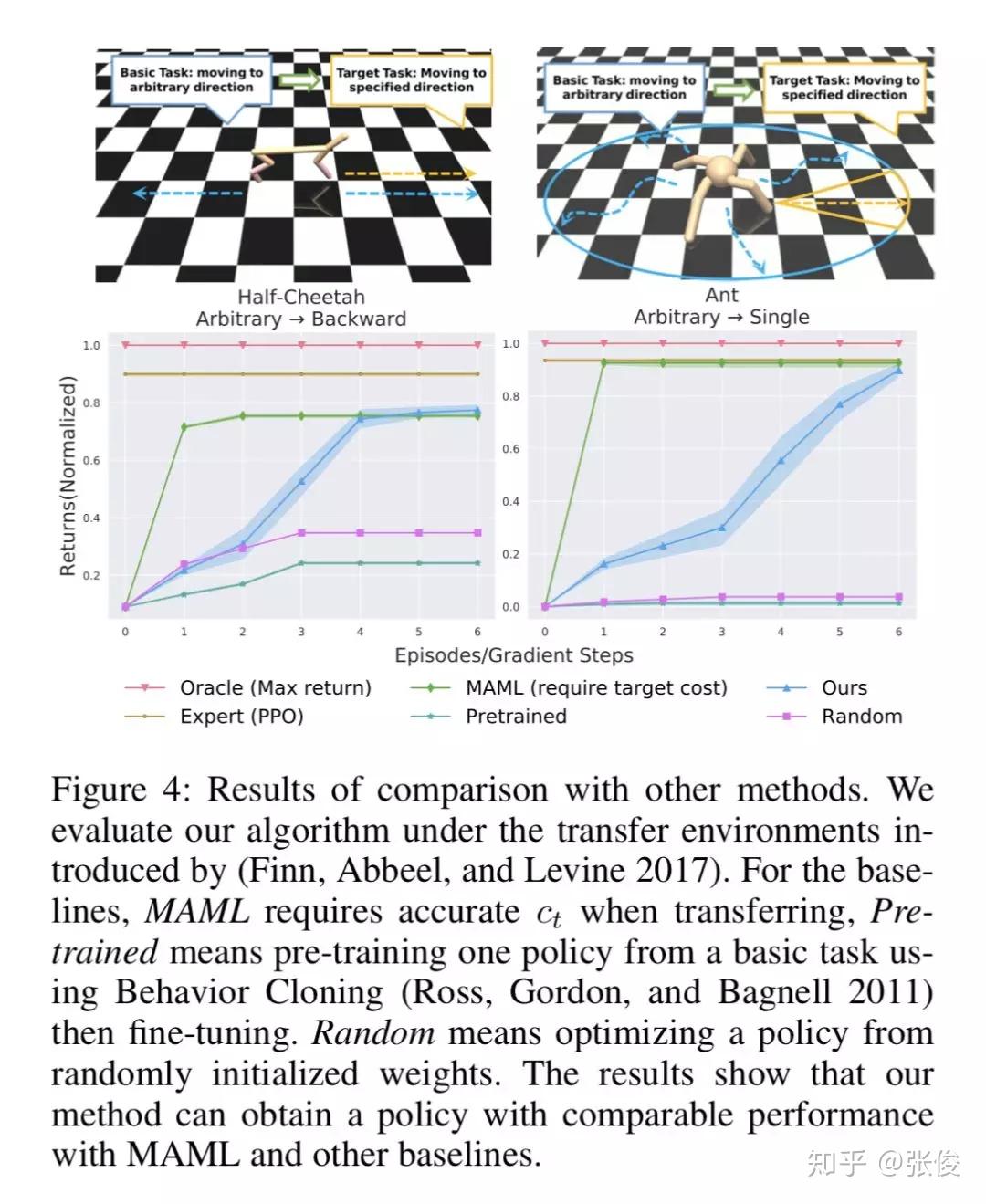
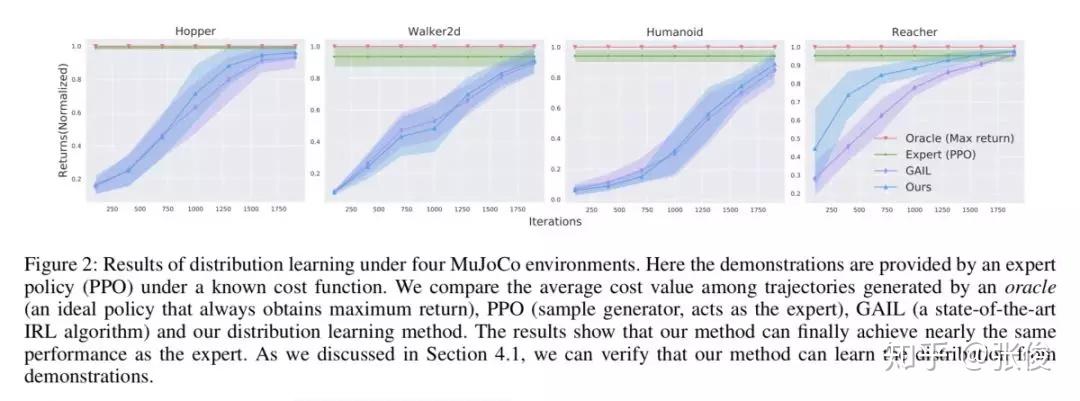
本文是清华大学和腾讯 AI Lab 发表于 AAAI 2019 的工作。当前主流用于机器人行动规划的方法主要依赖于两个要求:精确相关的专家示例或目标任务的显式编码代价函数,但在实践中获取并不方便。模仿学习目前面临的一个问题是要求提供的专家示例与机器人期望执行的动作要高度一致。然而,这一要求可能并不总是成立,因为收集准确相关的演示是资源消耗的。
本文通过将专家偏好作为指导放松了这两个强条件,开发了一种新的任务迁移框架。具体地,通过调整两步完成:首先,让专家应用预先定义的偏好规则,为目标任务选择相关专家论证。其次,在选择结果的基础上,通过增强对抗式 MaxEnt IRL,同时学习目标成本函数和轨迹分布,并通过学习目标分布生成更多轨迹,用于下一个偏好选择。
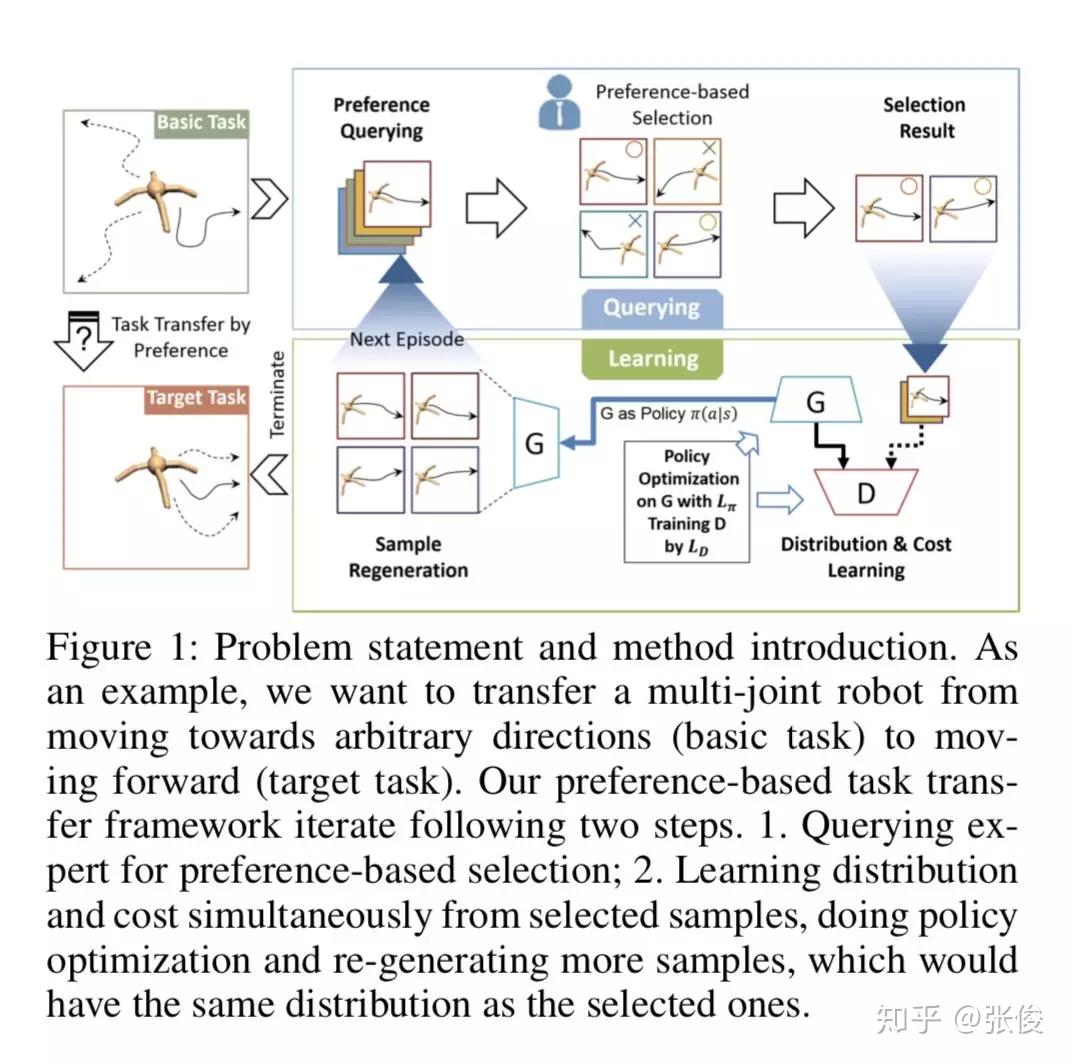


@paperweekly 推荐
#Social Recommendation
论文链接:https://www.paperweekly.site/papers/2469
源码链接:https://github.com/Coder-Yu/RecQ
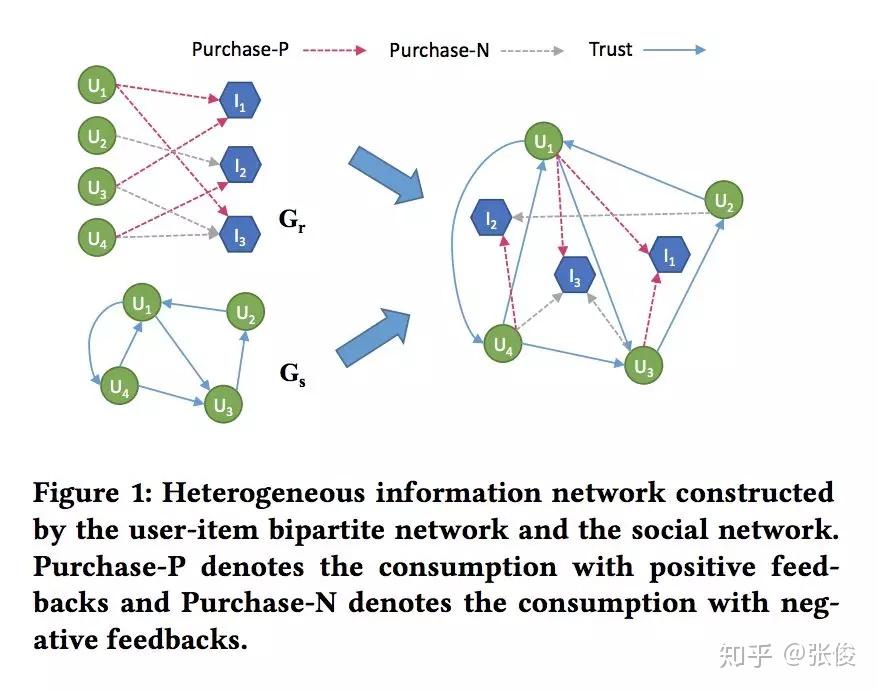
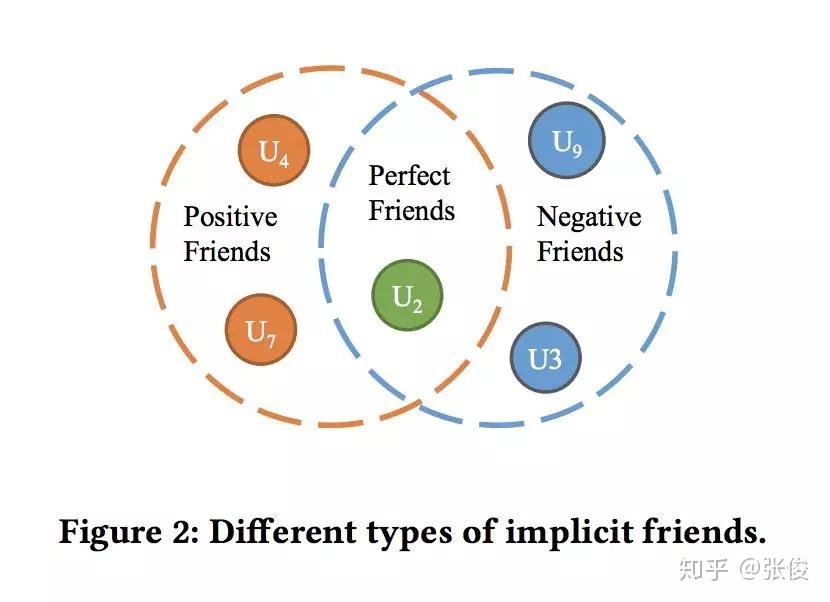
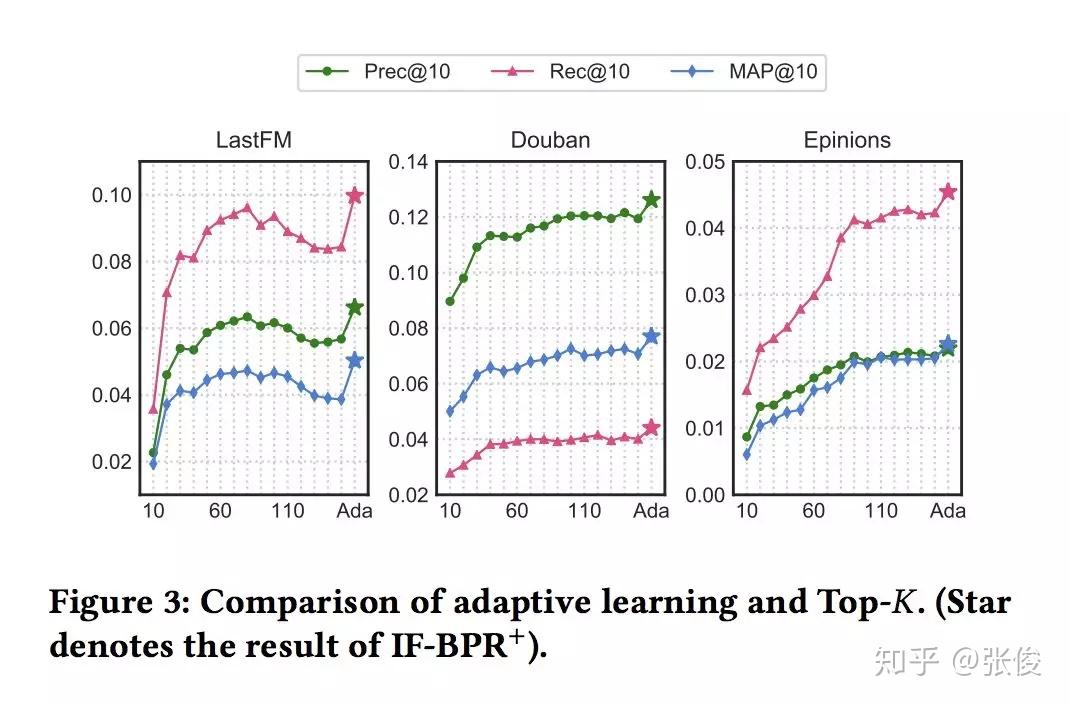
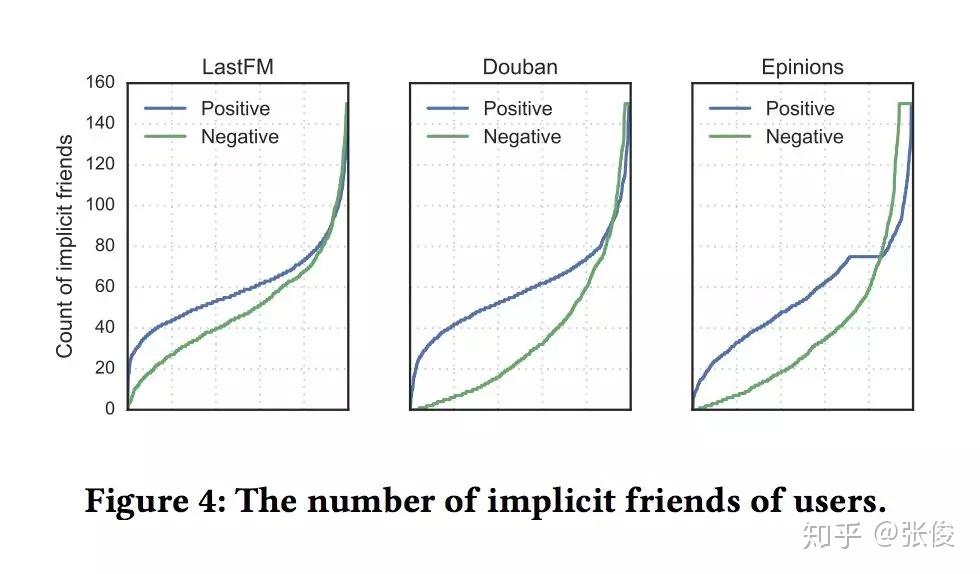
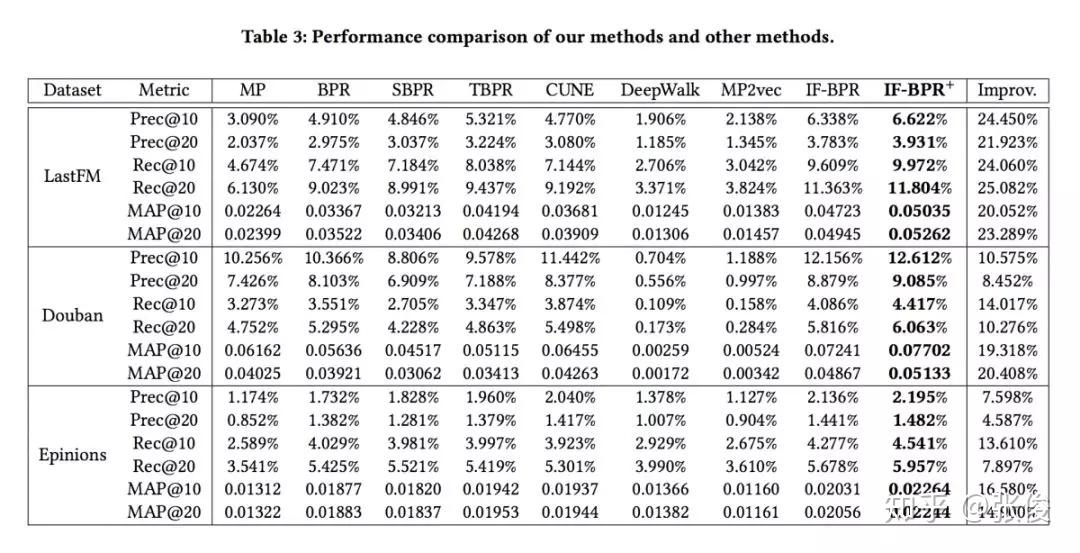
本文是重庆大学、亚利桑那州立大学和昆士兰大学发表于 CIKM 2018 的工作。论文提出了一种基于潜在好友关系和购买关系构建异质信息网络的方法,针对不同用户,采用动态采样方式生成用户的潜在好友。实验表明,本文方法在 Last.fm、豆瓣和 Epinions 数据集上,均达到了当前最优效果。本文实验丰富、数据真实、相关代码完善,在社会化推荐方面十分有借鉴和参考意义。
#投 稿 通 道#
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢? 答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
投稿方式:
• 方法一:在PaperWeekly知乎专栏页面点击“投稿”,即可递交文章
• 方法二:发送邮件至:hr@paperweekly.site ,所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
加入社区:http://paperweek.ly
微信公众号:PaperWeekly
新浪微博:@PaperWeekly

AI时代,拥有个人微信机器人AI助手!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
搜索微信号aigc666aigc999或上边扫码,即可拥有个人AI助手!



