文章主题:- zhoujie17 – 推荐

@zhoujie17 推荐
#Graph-to-Sequence Learning
这篇文章介绍了一种新颖的图到序列学习框架,其主要应用于AMR图的序列生成和基于句法的神经机器翻译任务领域,表现出了优异的效果。与以往的工作相比,该方法有效地解决了一些问题,比如图结构的线性化导致的信息损失和参数爆炸的问题。
这篇文章介绍了一种图像转化的技术方案,通过将图像转化为Levi图,成功解决了原先的问题。同时,这个框架还将Gated Graph Neural Network加入到了encoder的部分中,而其他部分则维持了seq2seq的原始结构。这一改进在两个任务上都展现出了超越seq2seq的表现。
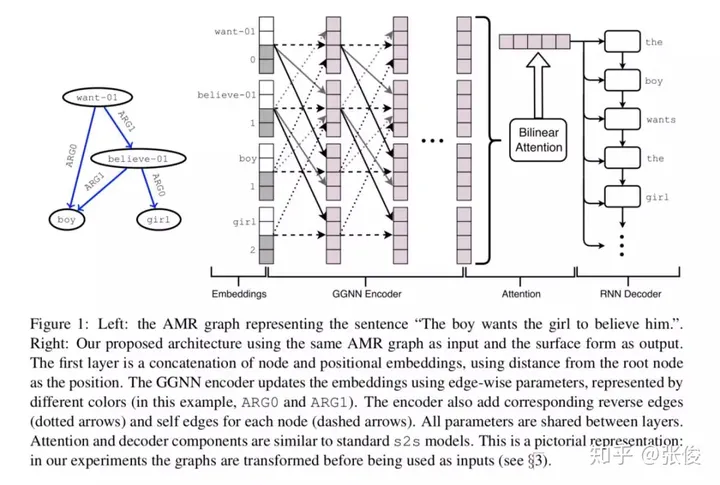
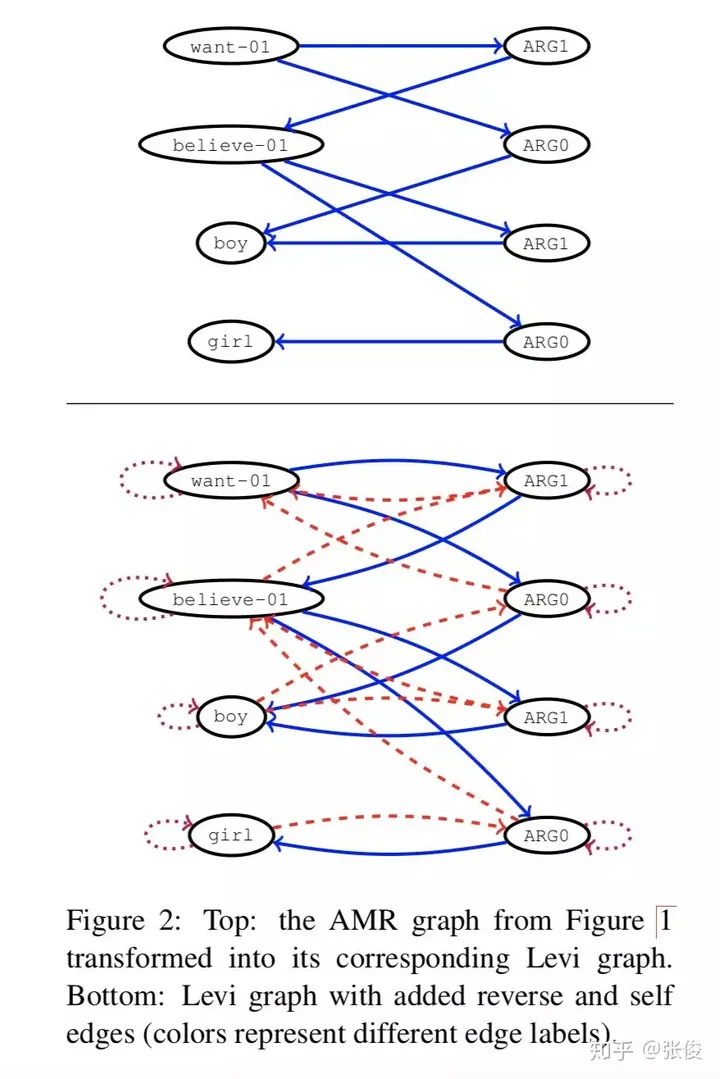
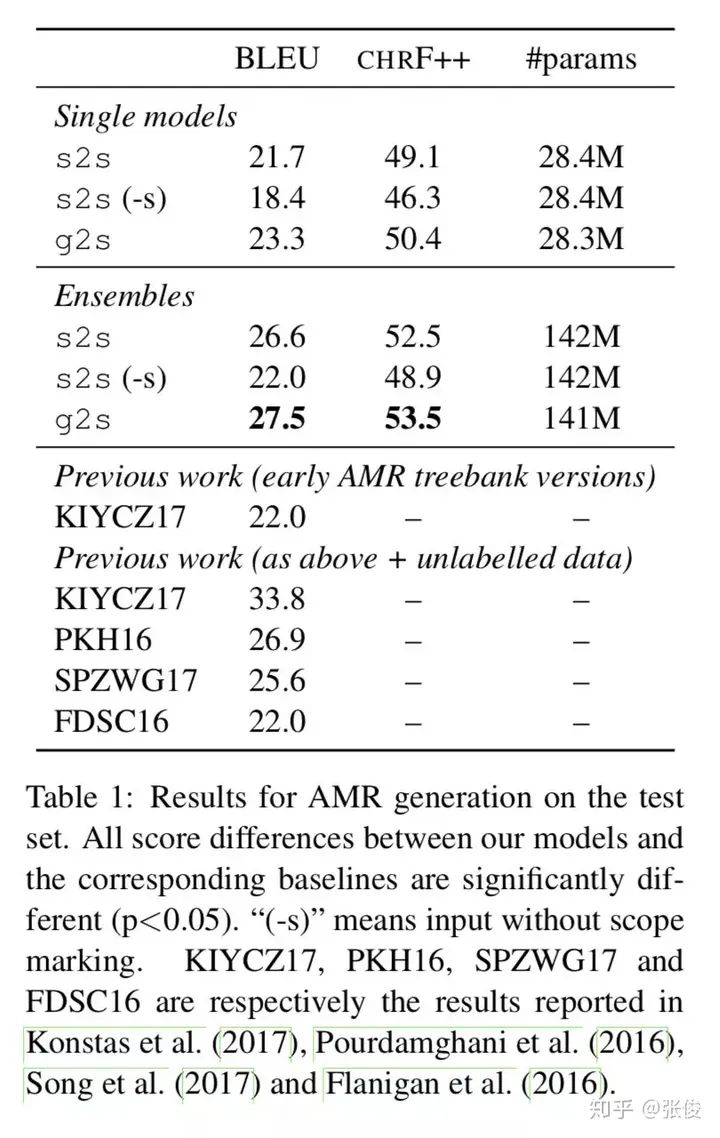
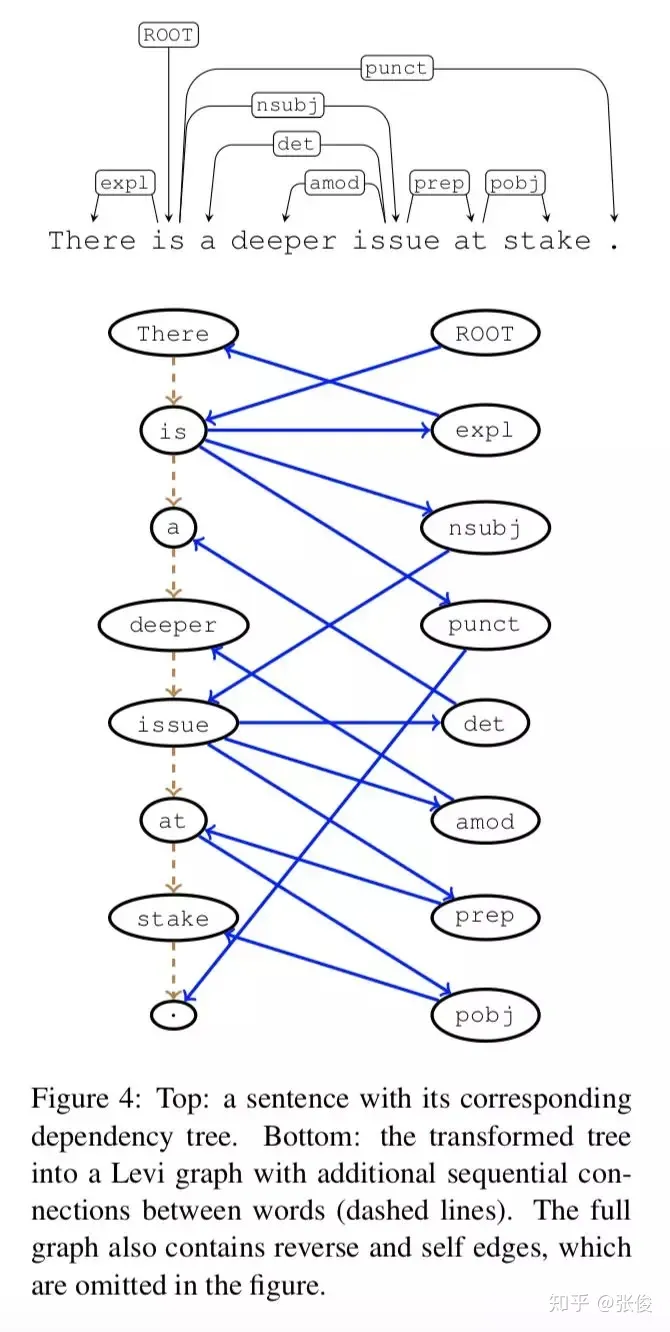
论文链接:https://www.paperweekly.site/papers/2301
源码链接:https://github.com/beckdaniel/acl2018_graph2seq

@paperweekly 推荐
#Dialog Systems
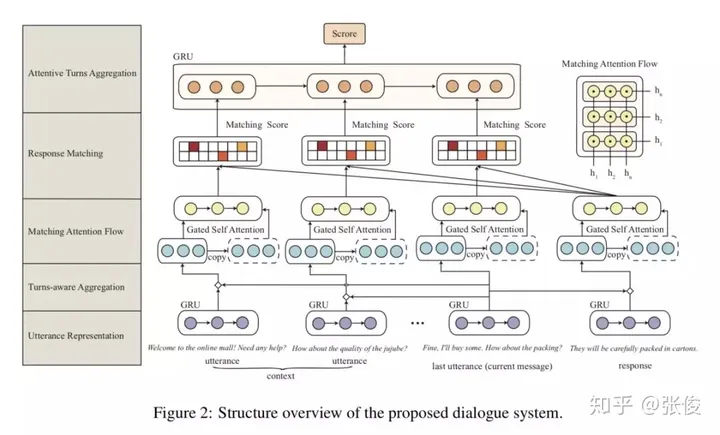
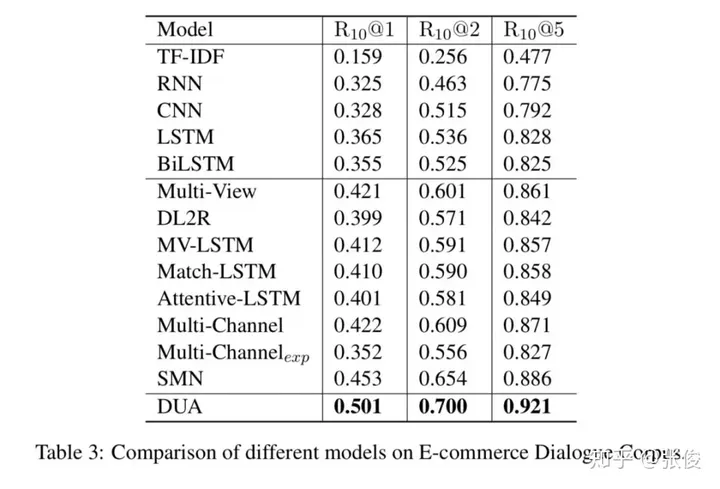
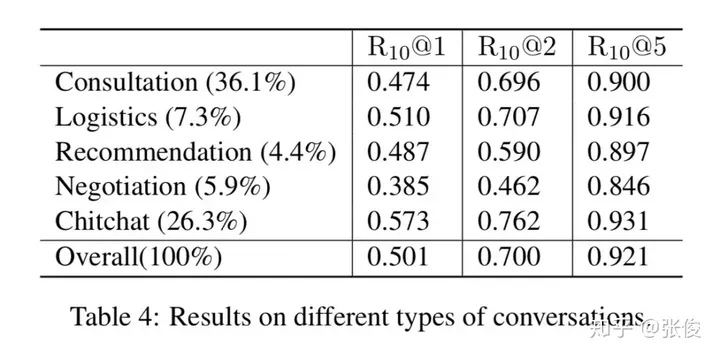
这篇文章是由上海交通大学团队于2018年在COLING会议上发表的,主要针对的是对话型检索系统的相关问题进行了深入探讨。该研究提出了一种全新的深度对话融合模型,这一模型在解决过去对话理解过程中将多个句子直接拼接在一起,从而忽视了它们之间的相互关系问题上,表现出了显著的优势。
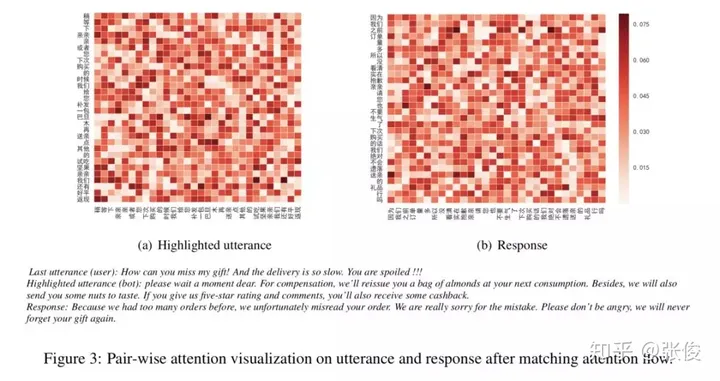
在论文模型的构建中,我们将过去的对话纳入到语境之中,通过分析话语和回复来提取关键信息。接下来,我们将每个过去的话语与其回复进行语义配对,从而计算出相应的匹配度。在这些匹配度中,我们特别关注回复中最后一句(可以被视为查询句)与其他过去话语的向量表示的融合。我们通过编码的方式,强调并过滤掉每句话语中的冗余信息,同时突出关键信息。

论文链接:https://www.paperweekly.site/papers/2352
源码链接:https://github.com/cooelf/DeepUtteranceAggregation

@guohao916 推荐
#Machine Reading Comprehension
在我们的日常生活中,人们经常会通过一系列相互关联的问题和回答来获取信息。因此,采用基于对话的机器阅读理解方式对于信息收集具有很大的优势。为了应对这一场景,本研究团队发布了一个名为 CoQA 的基于对话的机器阅读理解数据集。与现有的机器阅读理解数据集,例如 SQUAD 相比,CoQA 具有以下独特之处:
在本次数据集中,我们注意到与之前的答案通常出现在篇章中的句子片段有所不同。在生成过程中,我们力求避免直接使用现有的句子片段或短语,而是采用同义词或同义片段的方式来呈现。这样一来,我们就能够确保生成的答案具有更高的原创性,从而更好地满足您的需求。
2. 问题的答案中存在自由形式的短语片段,即需要对多条篇章句子加以归纳总结;
3. 篇章分别来自一系列不同的领域;
4. 和多轮对话的情况类似,问答对呈现出连续多轮的特点,平均轮数为 15 轮。问答对呈现出序列性的依赖关系。
该问题可以看成对话系统和问答系统的一个综合性的应用。论文使用多种基准算法进行对比实验,包括 Seq2Seq, PGNet, DrQA 以及 DrQA+PGNet。实验结果表明效果最优的模型 DrQA+PGNet 依然比人工标注得到的 F1 指标数目要低很多,因此该数据集具有很大的模型提升空间。



论文链接:https://www.paperweekly.site/papers/2251
源码链接:https://github.com/stanfordnlp/coqa-baselines

@tobiaslee 推荐
#Text Generation
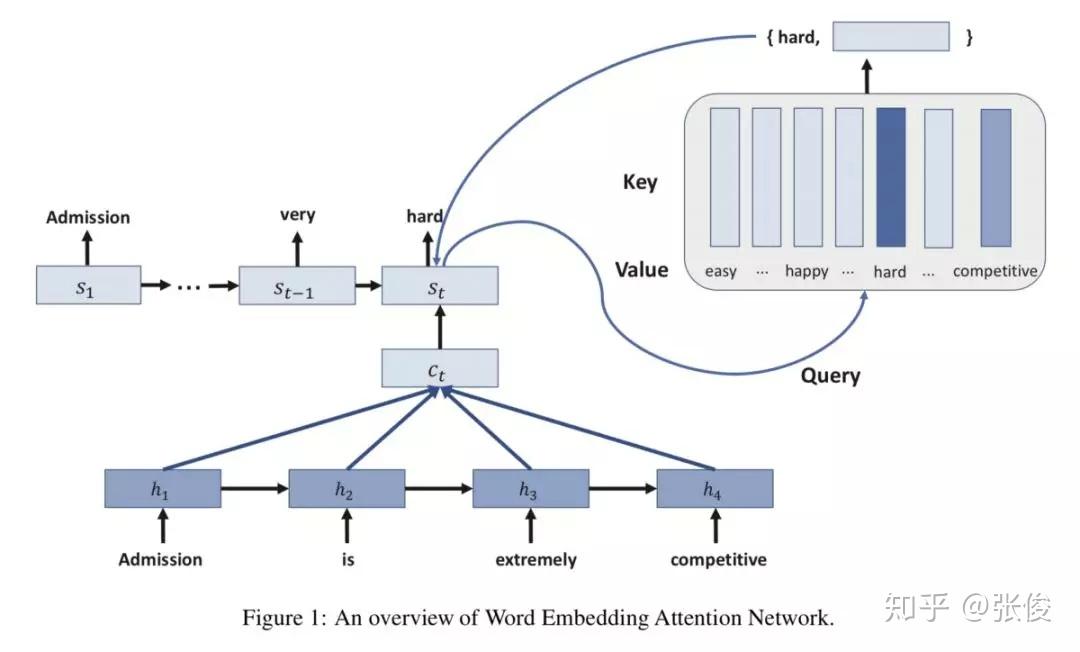
本文是北京大学发表于 NAACL 2018 的工作。论文借鉴了 Attention is All your Need 的思想,通过 Query 的方式来进行文本的生成。
传统文本生成的方式会使用一层全连接层将隐层状态映射到词表上,获得一个概率分布,这样做存在两个问题:参数量巨大和语言关系的丢失(没考虑到词的概率之间的关联关系)。
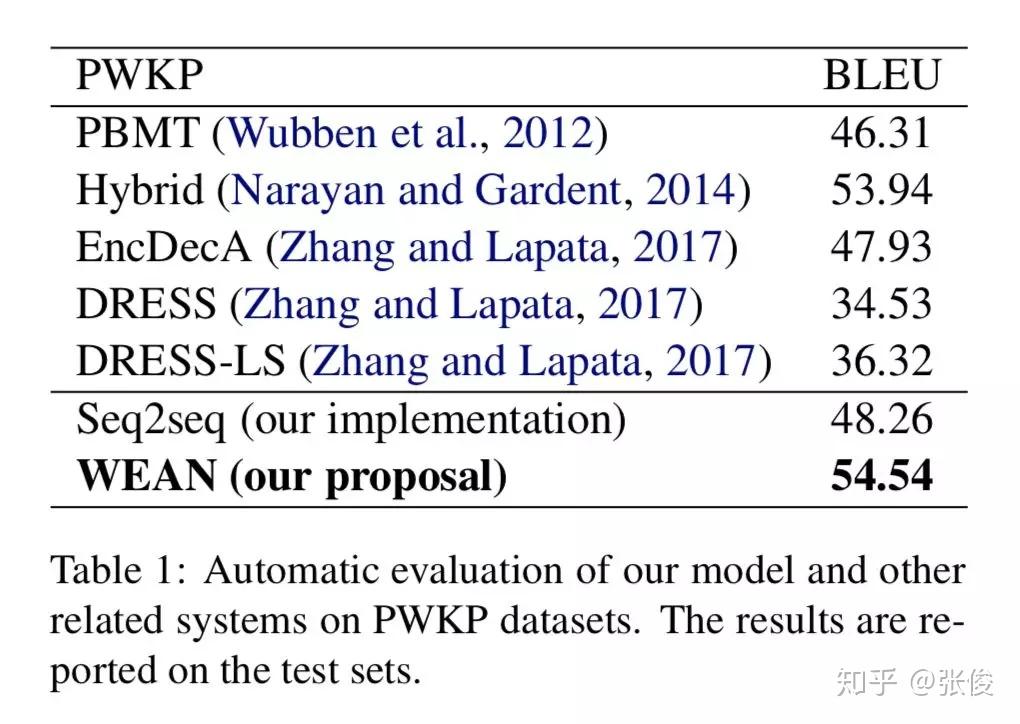
本文采用将候选词作为 value, 而对应的 word embedding 则是 key,通过将 RNN 的输出作为 query,根据 query 和 embedding 的 similarity 来进行生成词的选取。
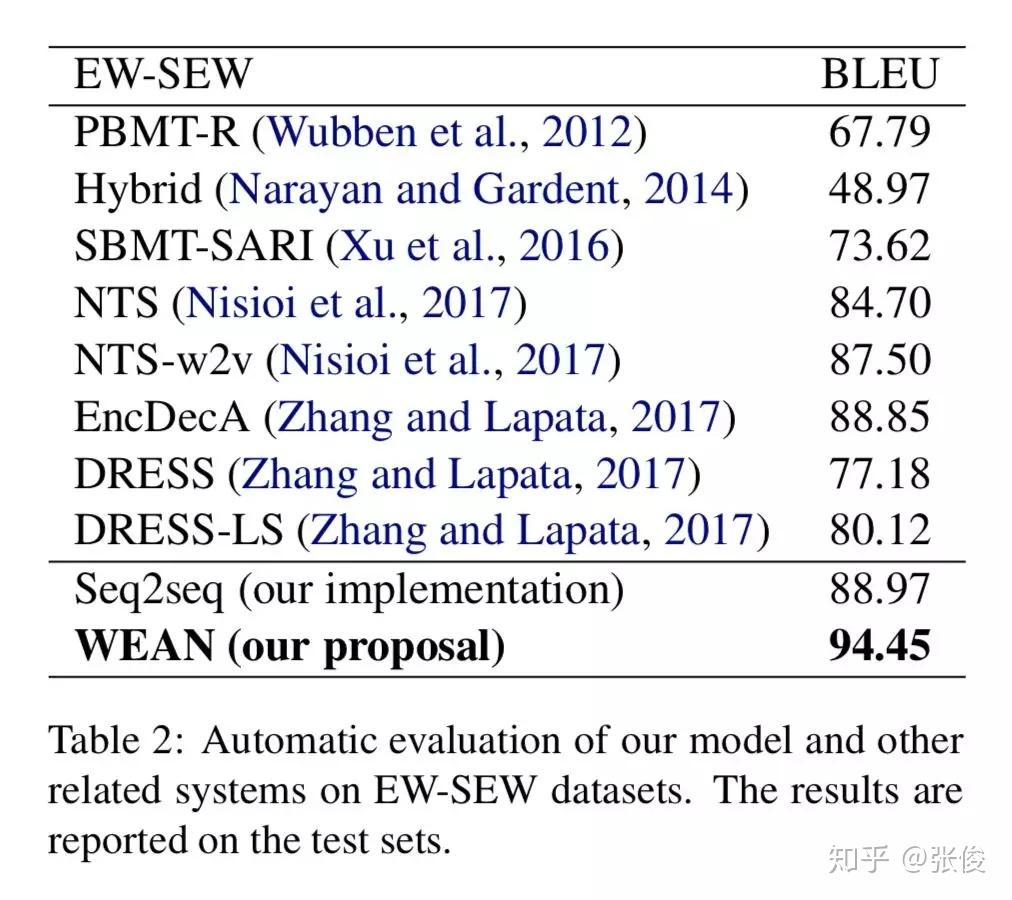
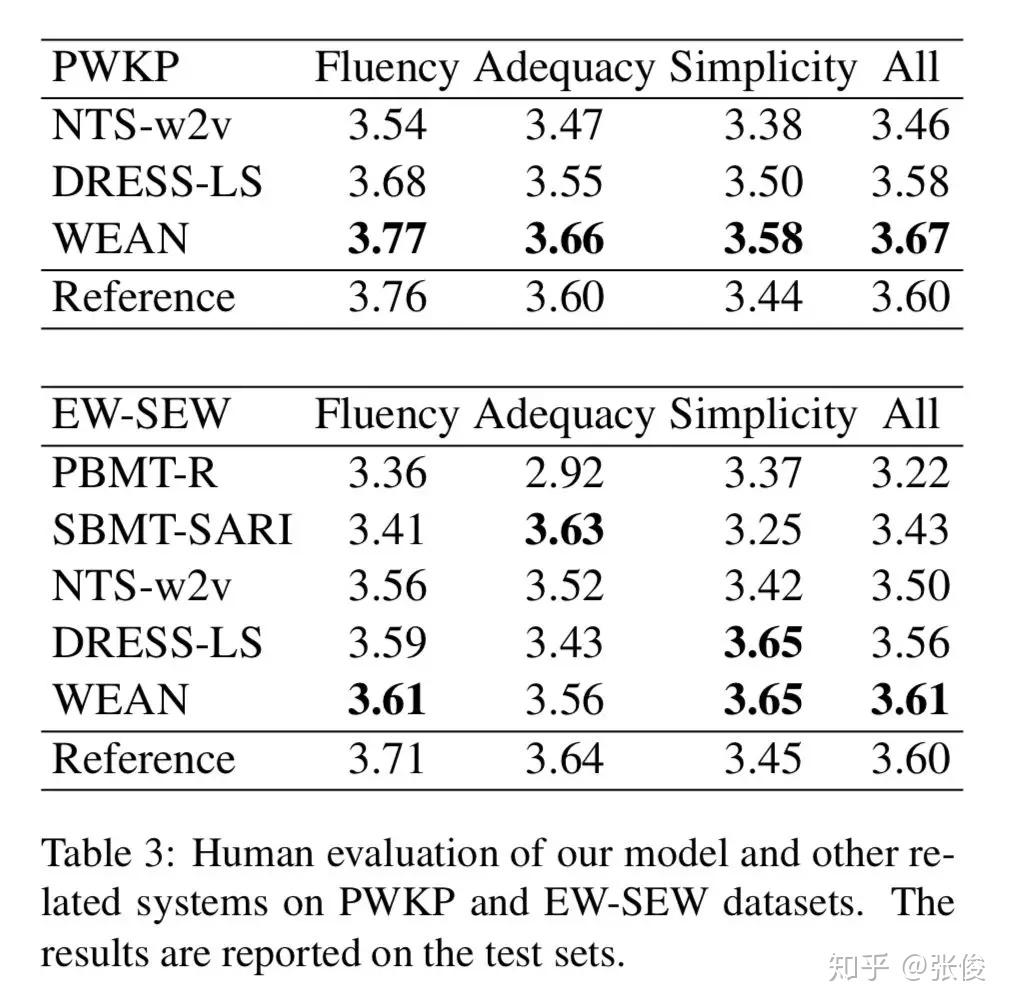
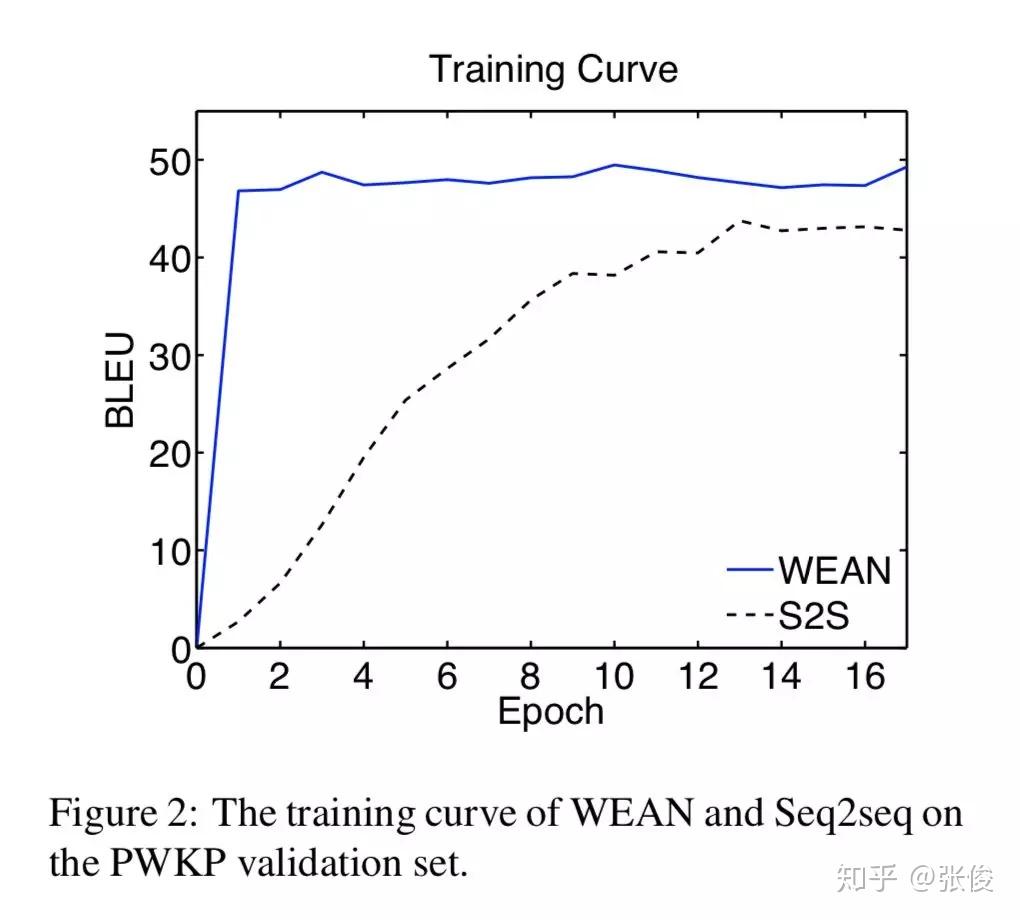
论文链接:https://www.paperweekly.site/papers/2302
源码链接:https://github.com/lancopku/WEAN

@paperweekly 推荐
#Question Answer Matching
本文是汉诺威大学发表于 SIGIR 2018 的工作。Answer Selection 是 QA 任务中的重要子任务,现有方法往往先通过单个向量对问题和回答进行表示,然后再计算打分。论文提出了一种多阶段的 Sequential Attention 机制,将问题进行多次 attention,从而使得能够在不同阶段注意到答案不同的阶段,有效处理了长文本语义的表达问题。
实验表明,本文提出的模型在各主流 QA 数据集(TREC-QA、WikiQA、InsuranceQA、FiQA)上均取得了最优表现。
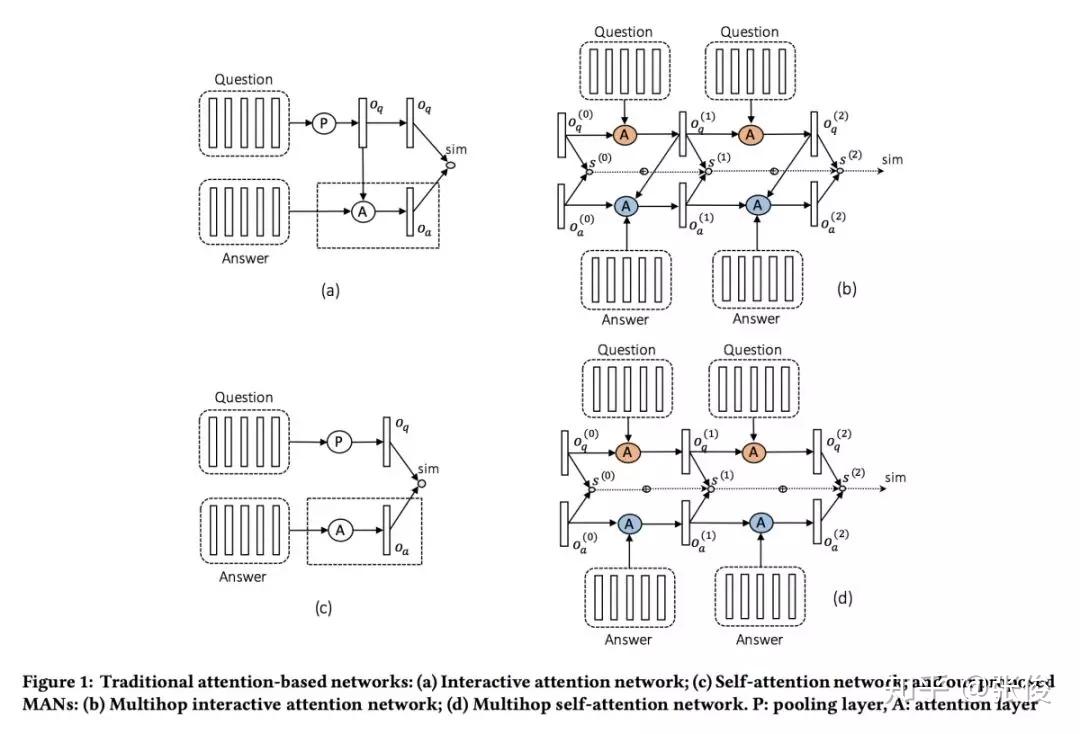
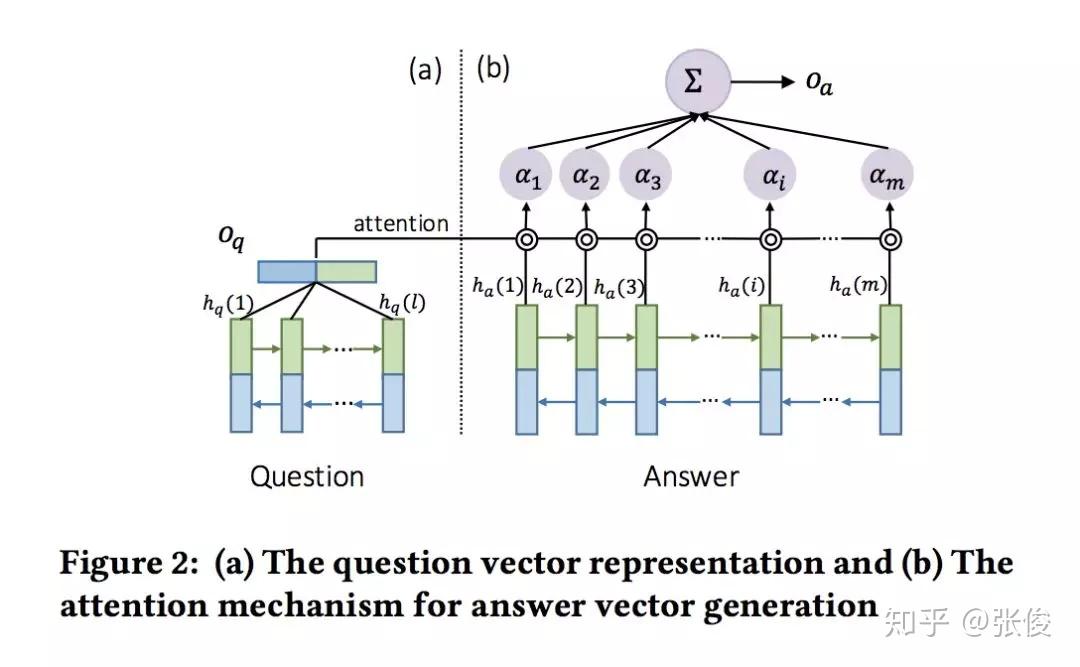
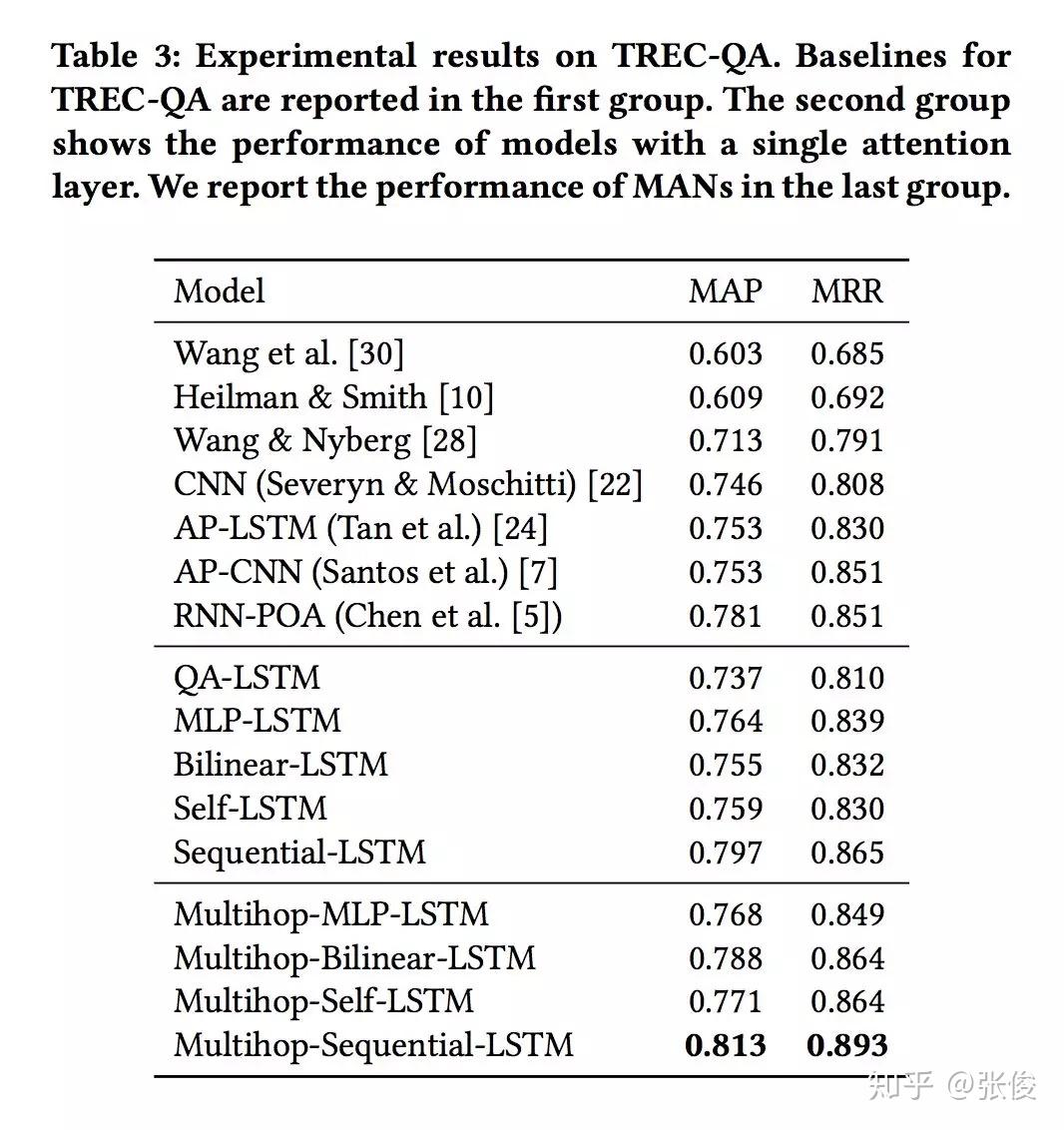
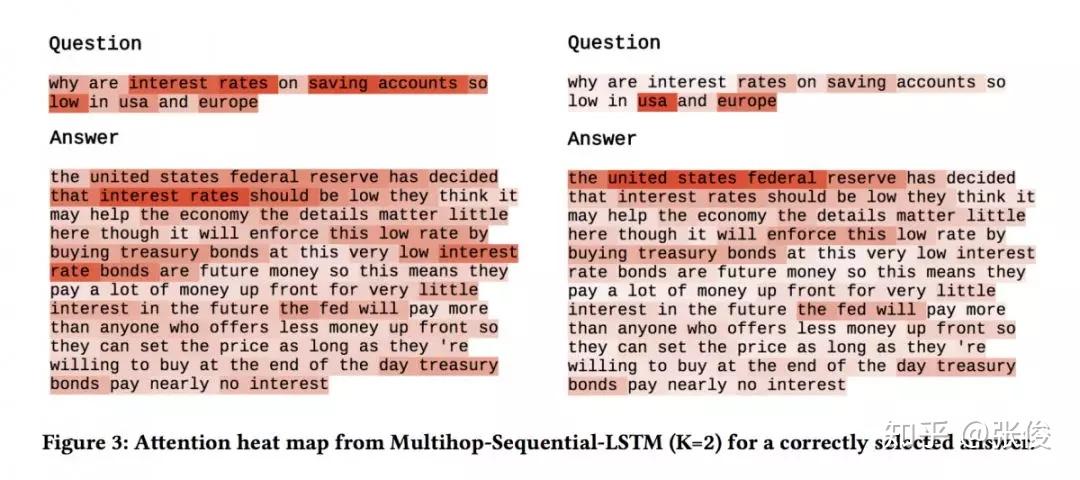

论文链接:https://www.paperweekly.site/papers/2338

@mrililili 推荐
#Natural Language Inference
本文来自赫尔辛基大学,论文主要关注的是自然语言推理任务。作者利用多层双向 LSTM 进行句子编码,并用上一个 LSTM 的结果初始化下一个 LSTM,取得了较好的结果。此外,实验表明本文提出的句子嵌入方法可应用于各类迁移学习任务。
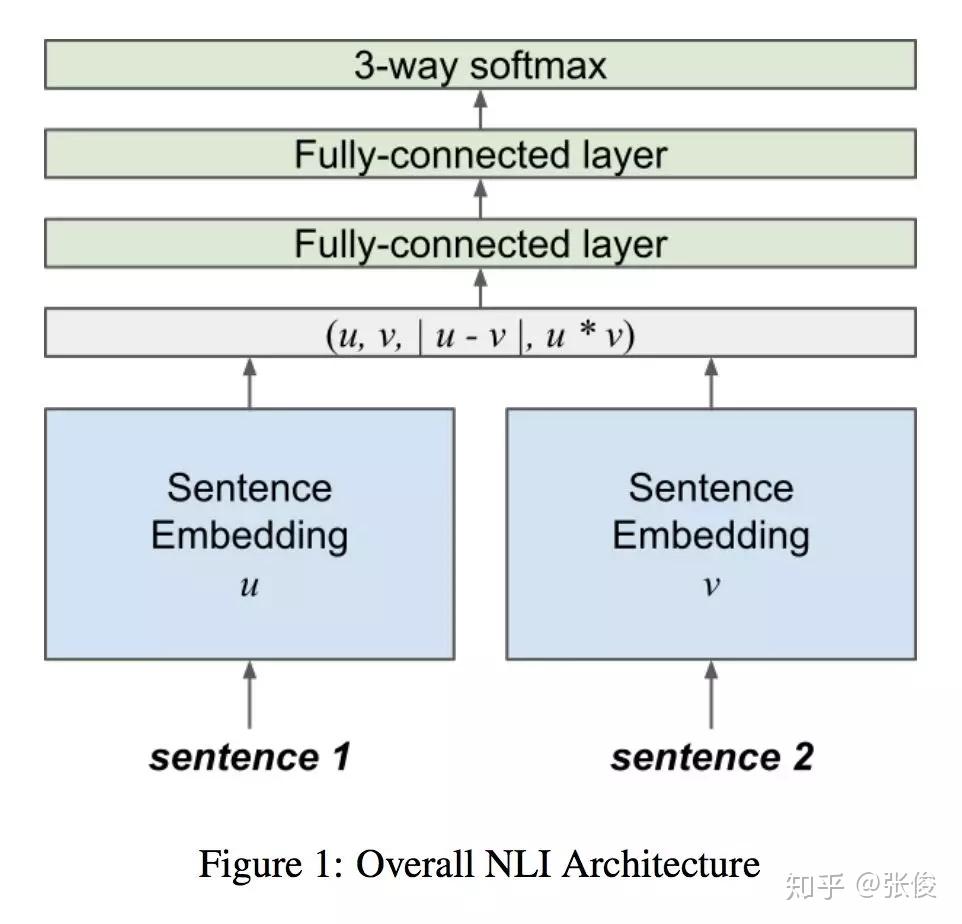

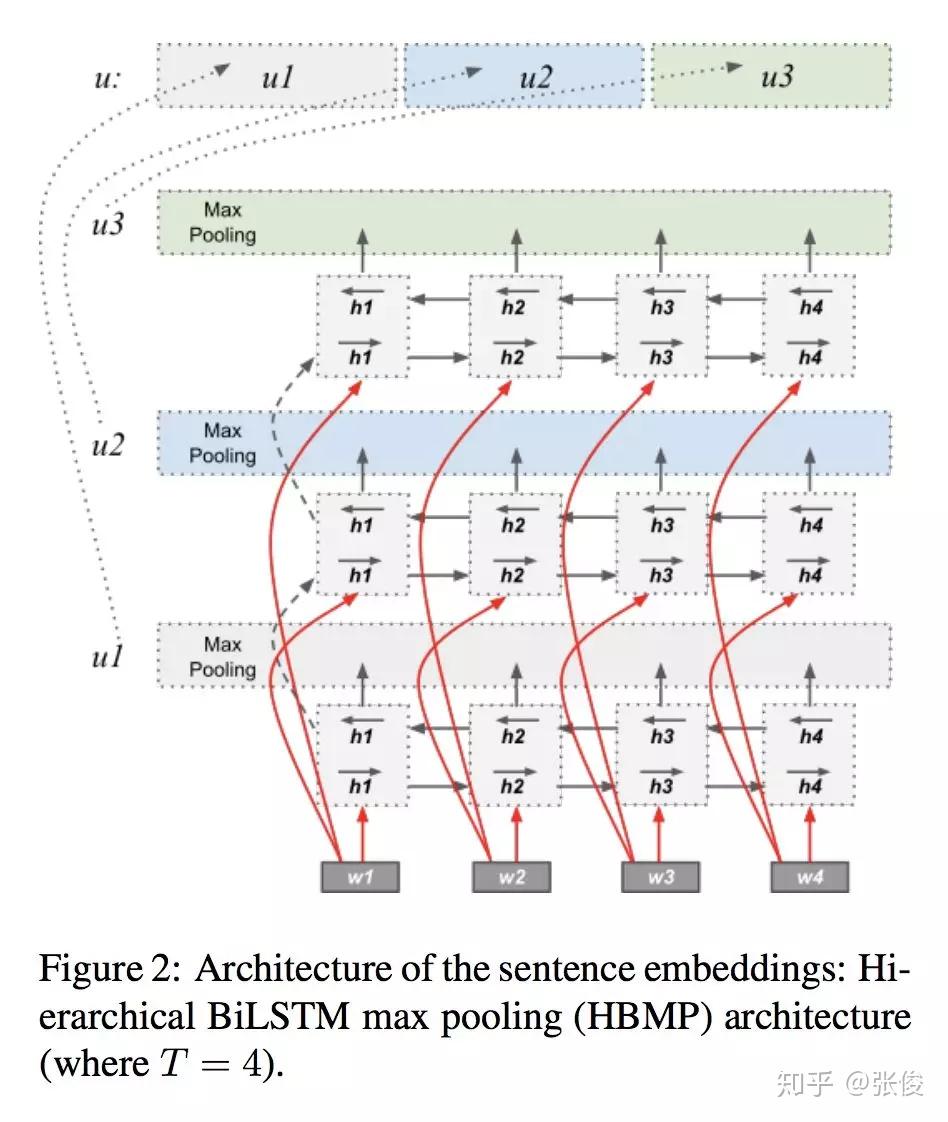


论文链接:https://www.paperweekly.site/papers/2323
源码链接:https://github.com/Helsinki-NLP/HBMP

@paperweekly 推荐
#Natural Language Understanding
自然语言处理任务的成功取决于标注数据的数量和质量,训练数据不足将直接影响任务精度和准确度。针对文本语料不足的情况,本文提出了一种将神经网络和正则表达式相结合的方法,来改进 NLP 的监督学习。
本文提出的方法在少量学习和完整注释设置上都明显提高了神经网络的性能。此外,本文为如何将 REs 与 NNs 和 RE 注释相结合提供了一套指南。

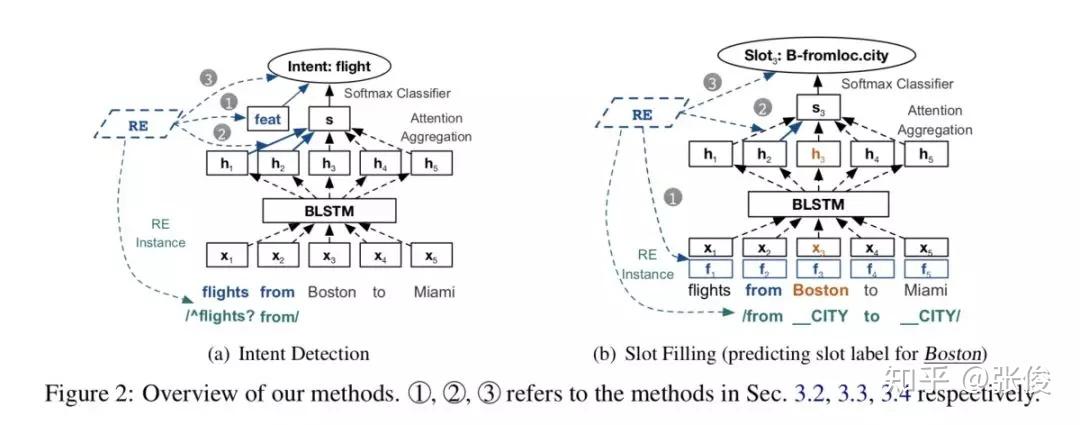
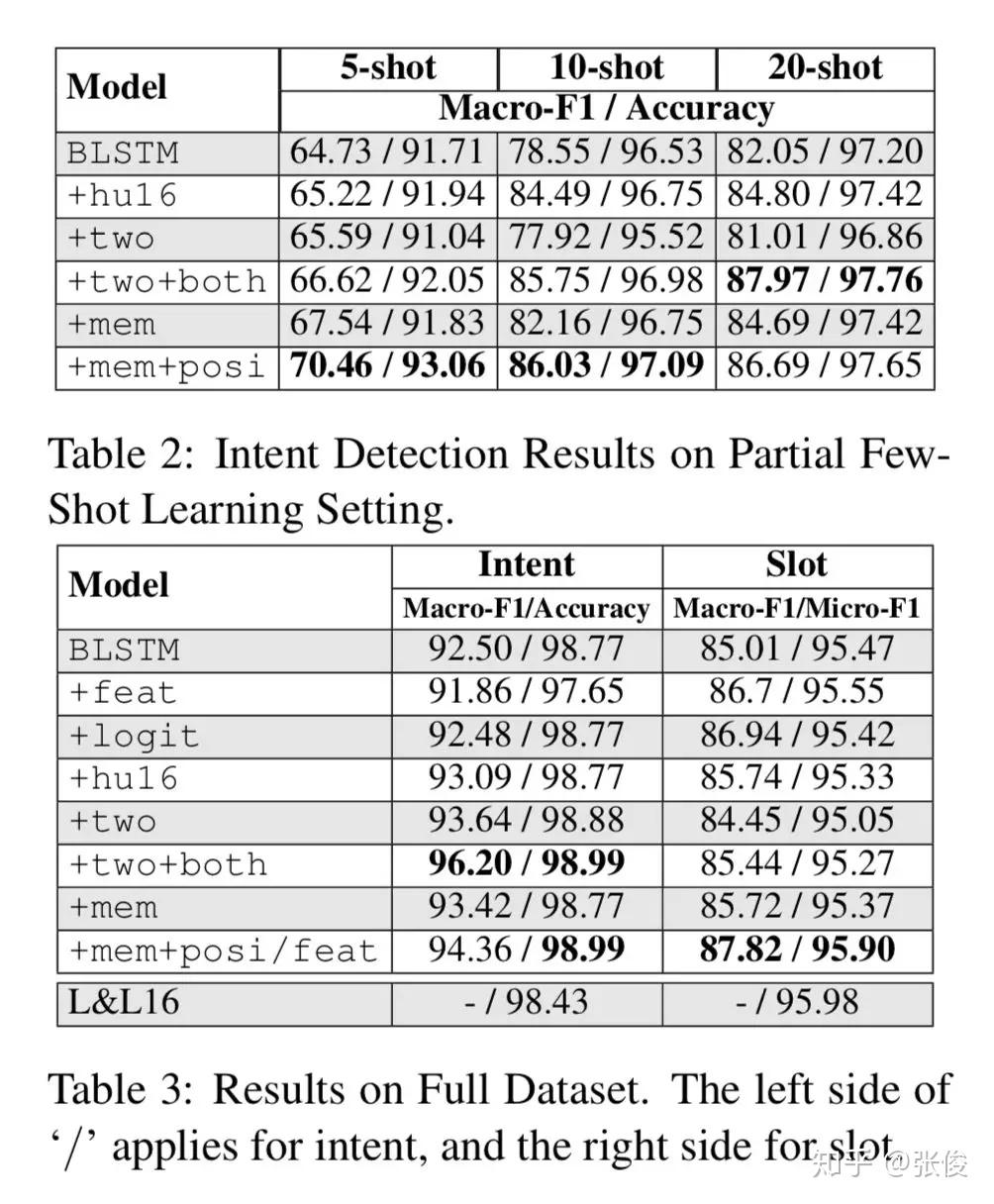
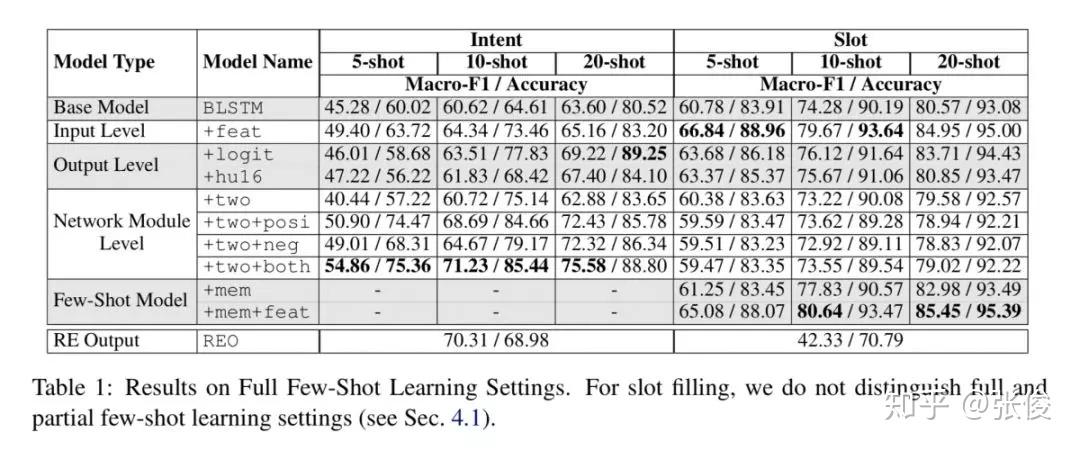
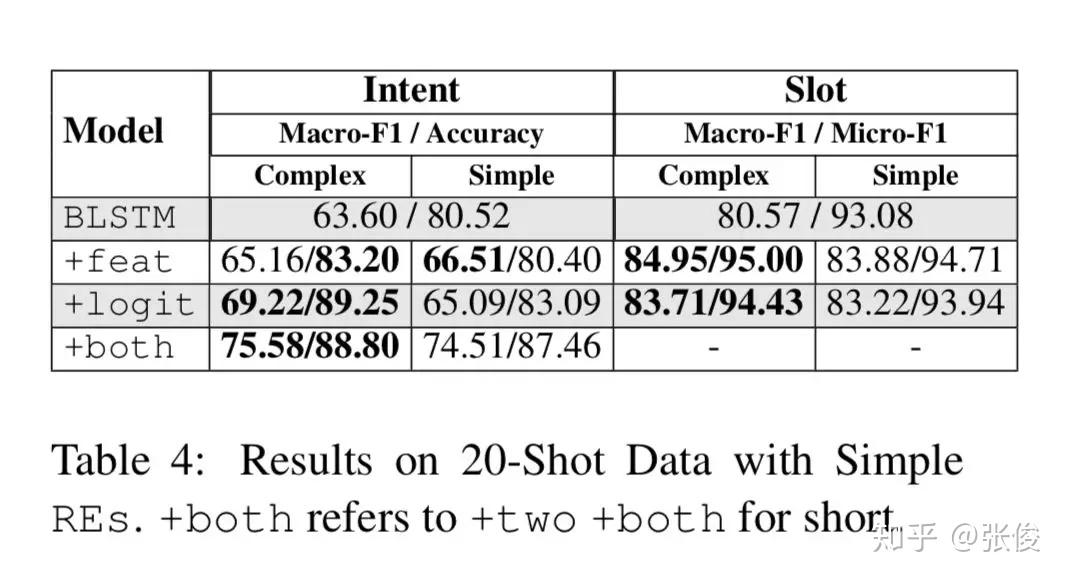
论文链接:https://www.paperweekly.site/papers/2344
数据集链接:http://www.lancaster.ac.uk/staff/wangz3/publications/ACLData.zip

@lunar 推荐
#Dataset Creation
本文是由 CMU 的一众科学家发布的一个公开数据集,他们组织了 4 个受试者去观察 5000 张图片,并在他们观察图片时记录下当时脑部的核磁共振图。 通过该数据集,我们可以将人工神经网络和人类神经网络联合起来分析,可以想象通过这个数据集,可以做出许多有趣的工作。
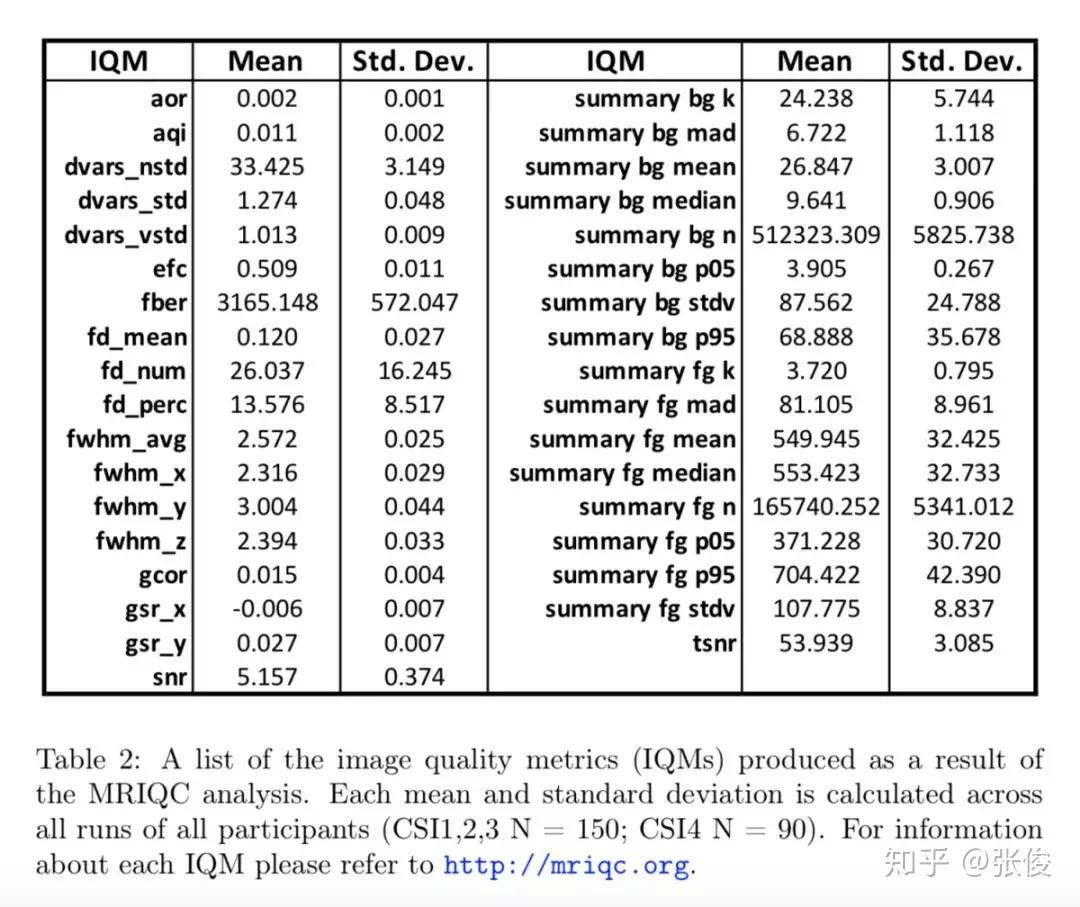

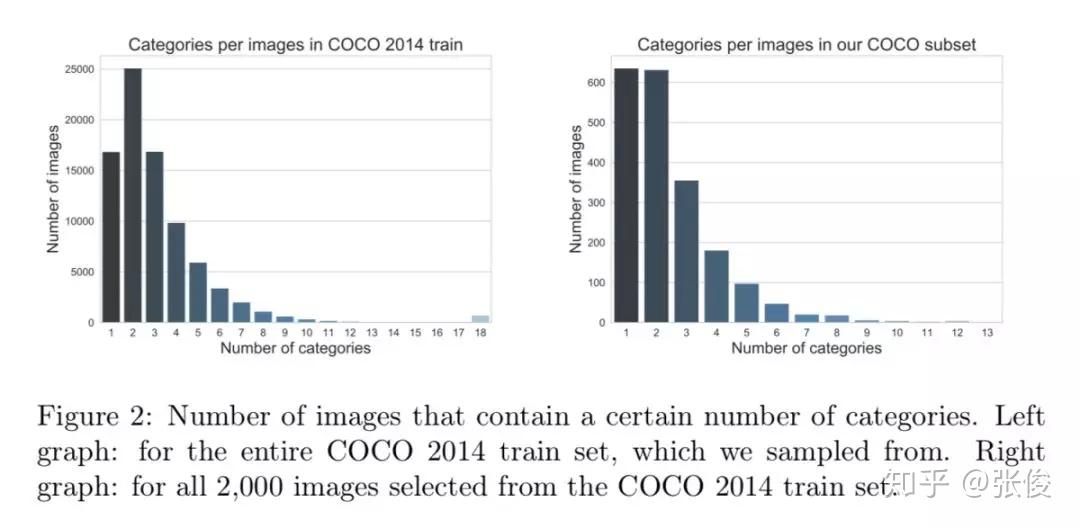
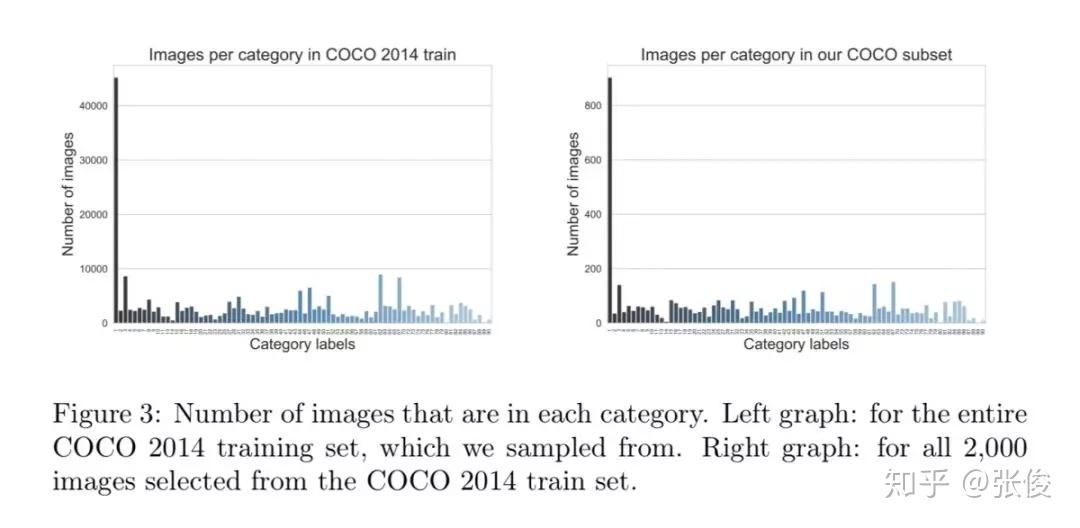
论文链接:https://www.paperweekly.site/papers/2325
源码链接:https://bold5000.github.io/

@paperweekly 推荐
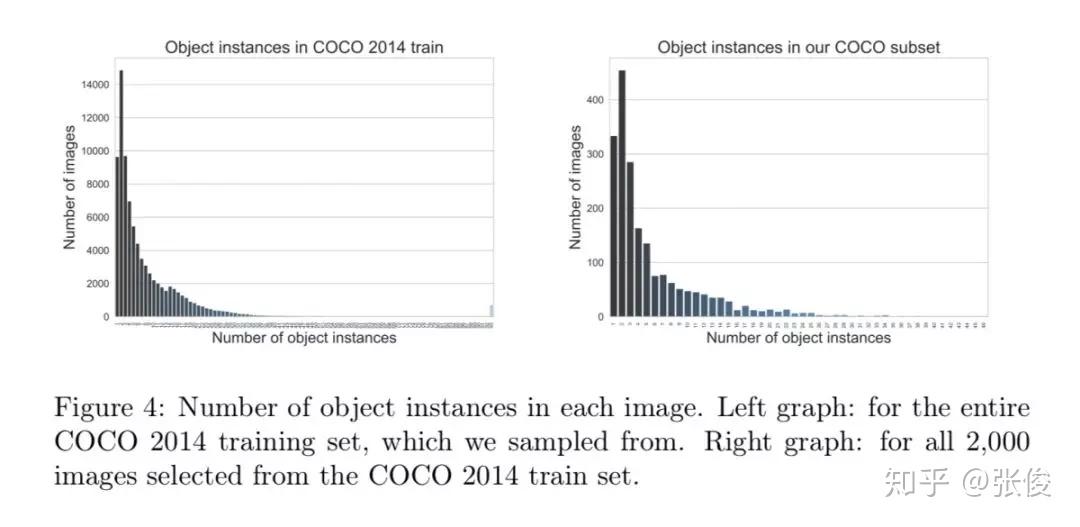
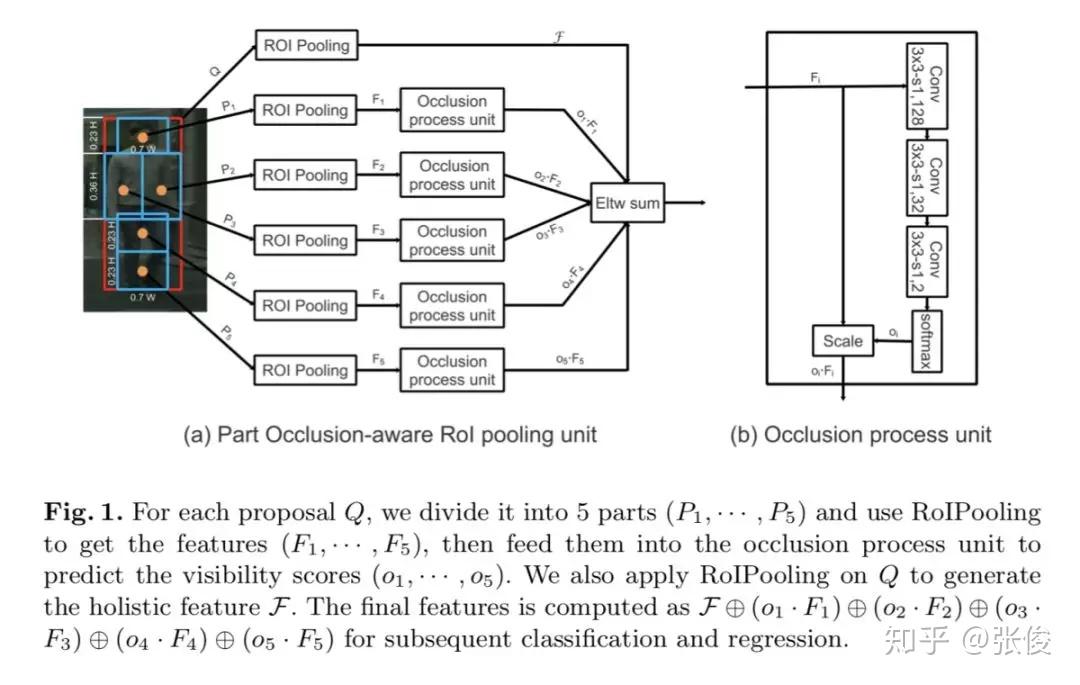
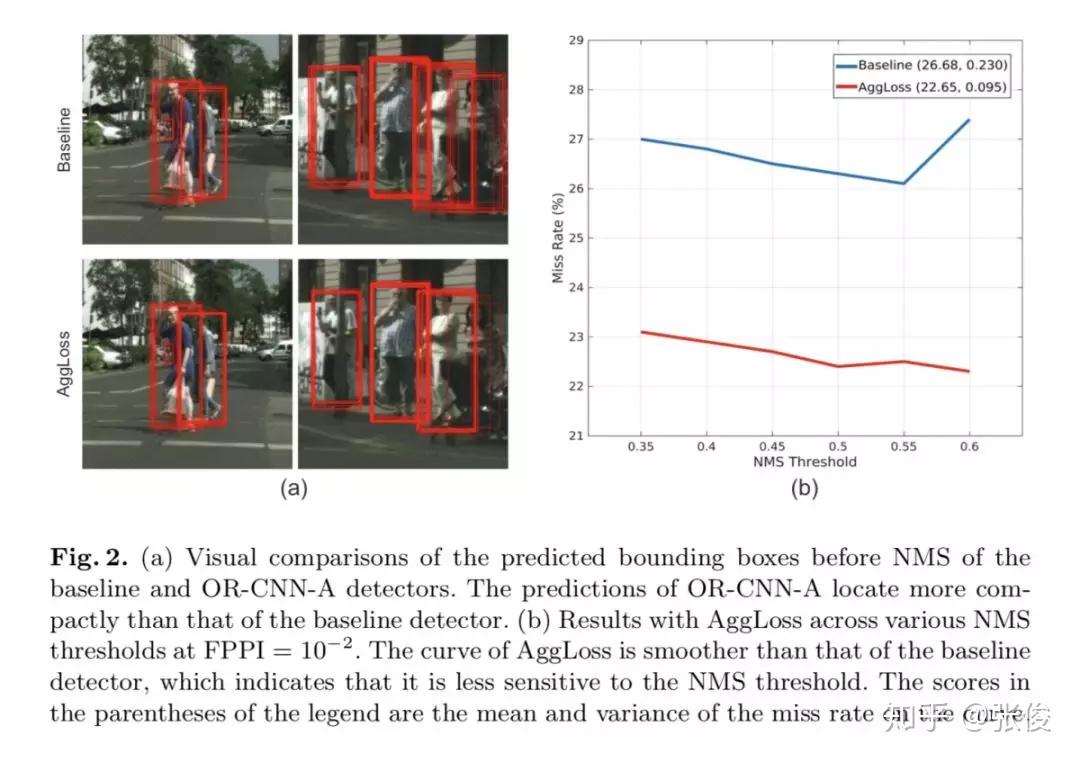
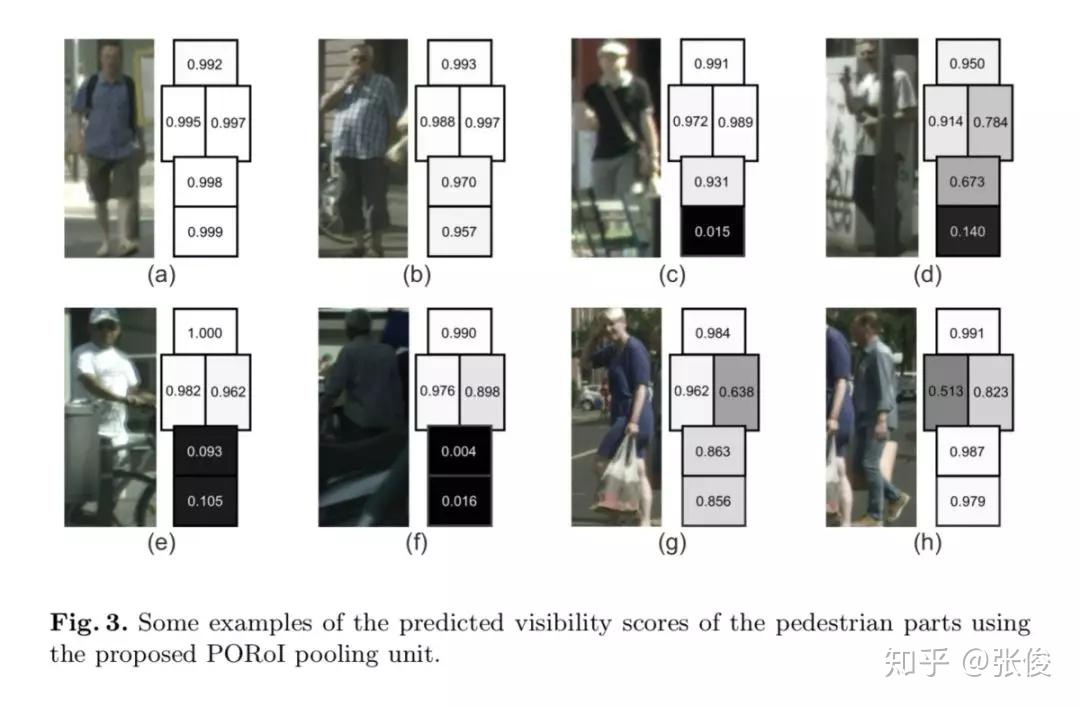
#Pedestrian Detection
本文是中科院自动化发表于 ECCV 2018 的工作。本文重点关注行人检测中的遮挡问题,并为此提出了两种遮挡处理策略。作者在Faster R-CNN的基础上提出了一种全新方法——OR-CNN,其主要包括两个部分:第一阶 段RPN 产生目标候选框,第二阶段 Fast R-CNN 对目标候选框进行进一步的分类和回归。
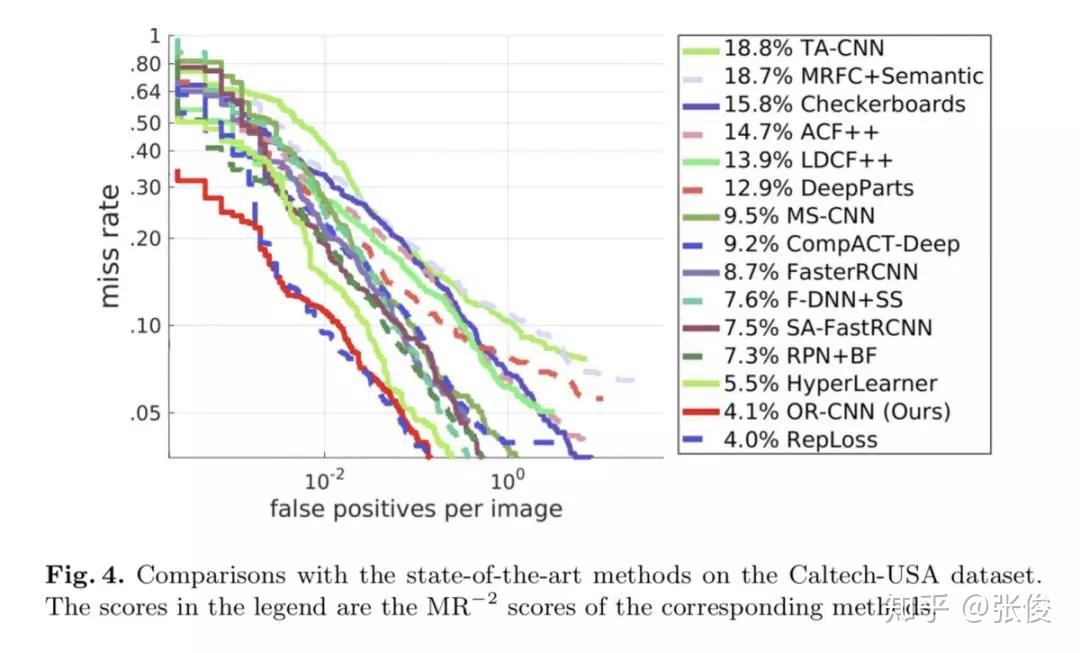
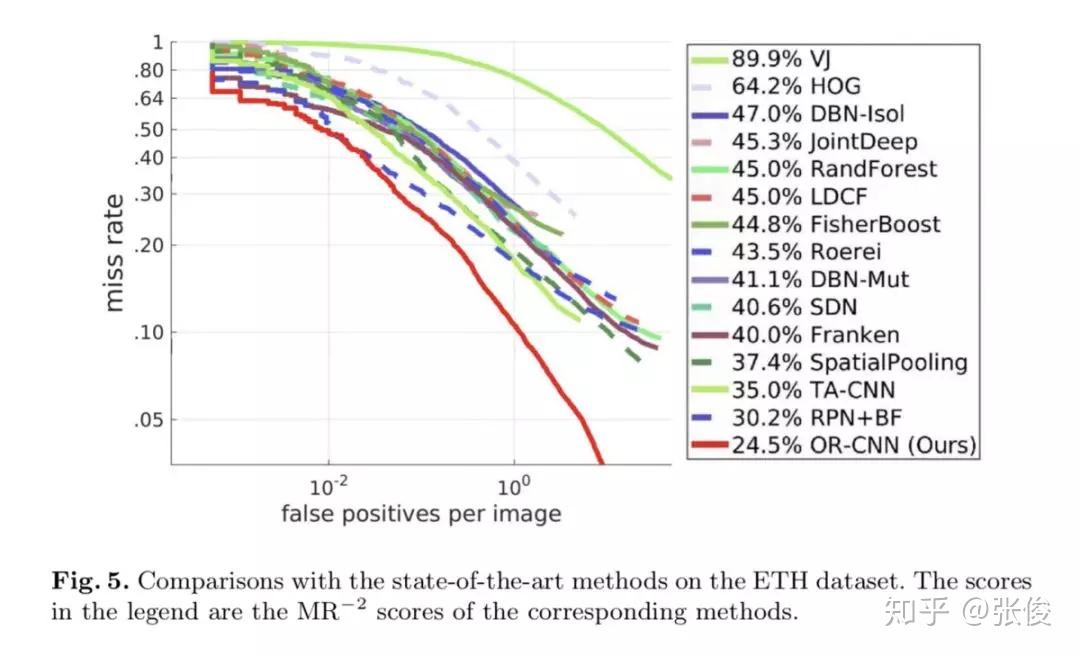
论文链接:https://www.paperweekly.site/papers/2364

@paperweekly 推荐
#Semantic Segmentation
本文是 UC Berkeley 发表于 ECCV 2018 的工作,论文提出了一种以自适应相似场(Adaptive Affinity Fields )来辅助语义分割的方法,增强了网络对目标结构推理的能力,取得了非常显著的性能提升。
此外,本文提出的方法也是一种全新的深度学习结构建模方法,不仅可以用于语义分割,理论上也适用于图像深度估计、光流计算等对图像进行像素级理解的任何场景。

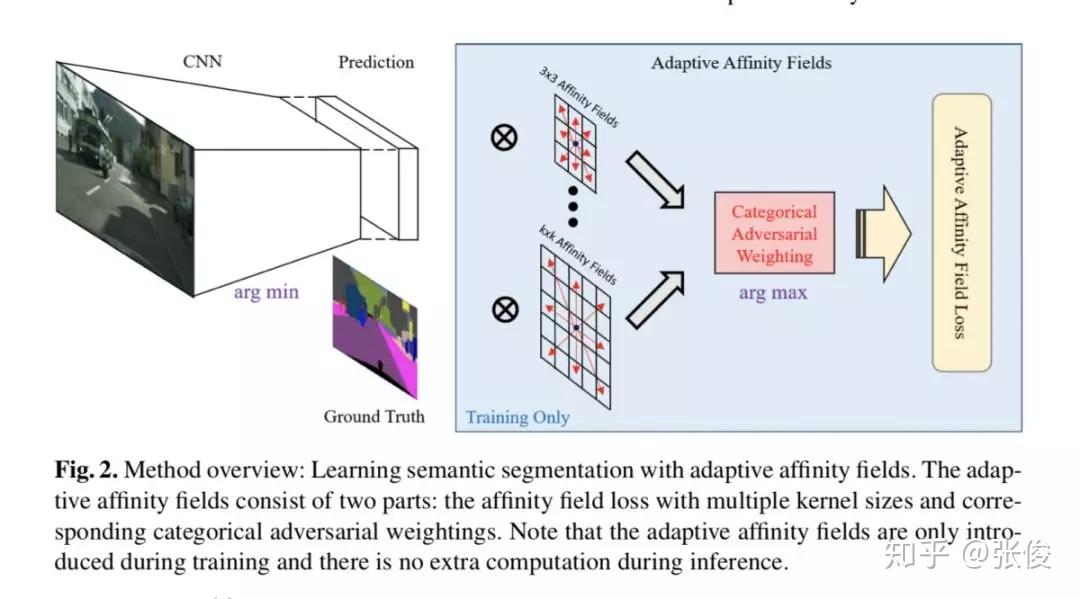

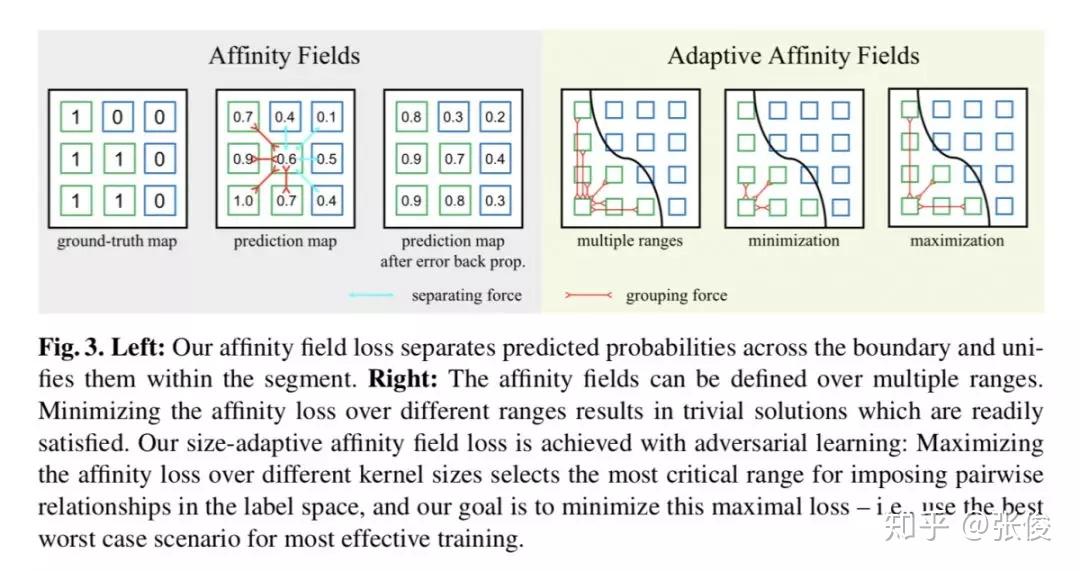
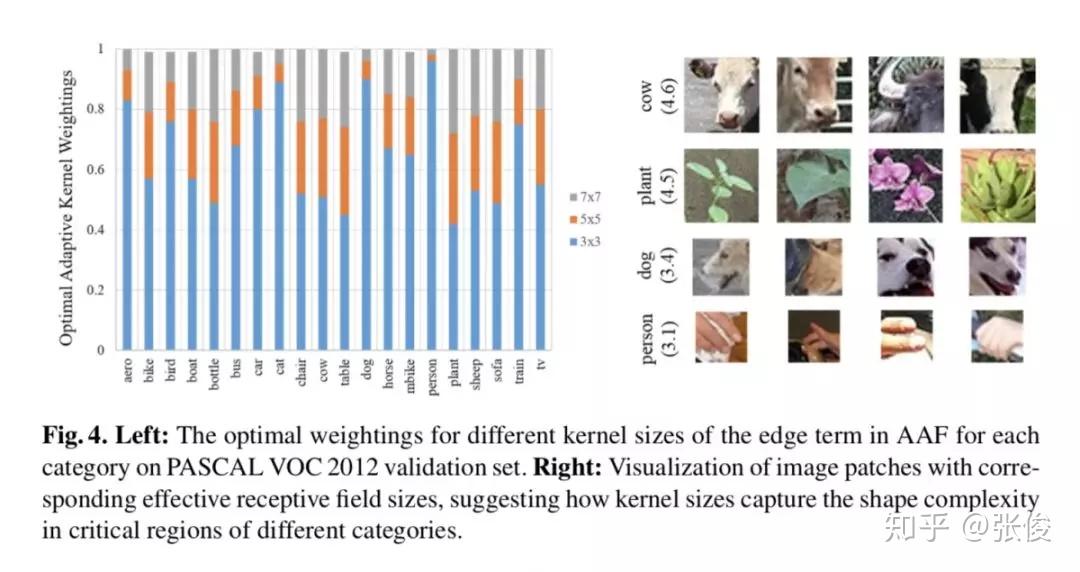
论文链接:https://www.paperweekly.site/papers/2365
源码链接:https://github.com/twke18/Adaptive_Affinity_Fields

@paperweekly 推荐
#Person Re-ID
本文是复旦大学发表于 ECCV 2018 的工作,论文主要研究的是行人重识别任务中的人体姿态变化问题。作者利用 GAN 生成新的姿态行人图片,然后融合原图和生成图的 ReID 特征作为最终特征。在测试阶段,论文定义了八种代表性的姿态,然后生成八张人造图,加上原图总共可以得到九个特征,最后使用 max pooling 得到最终的 ReID 特征。
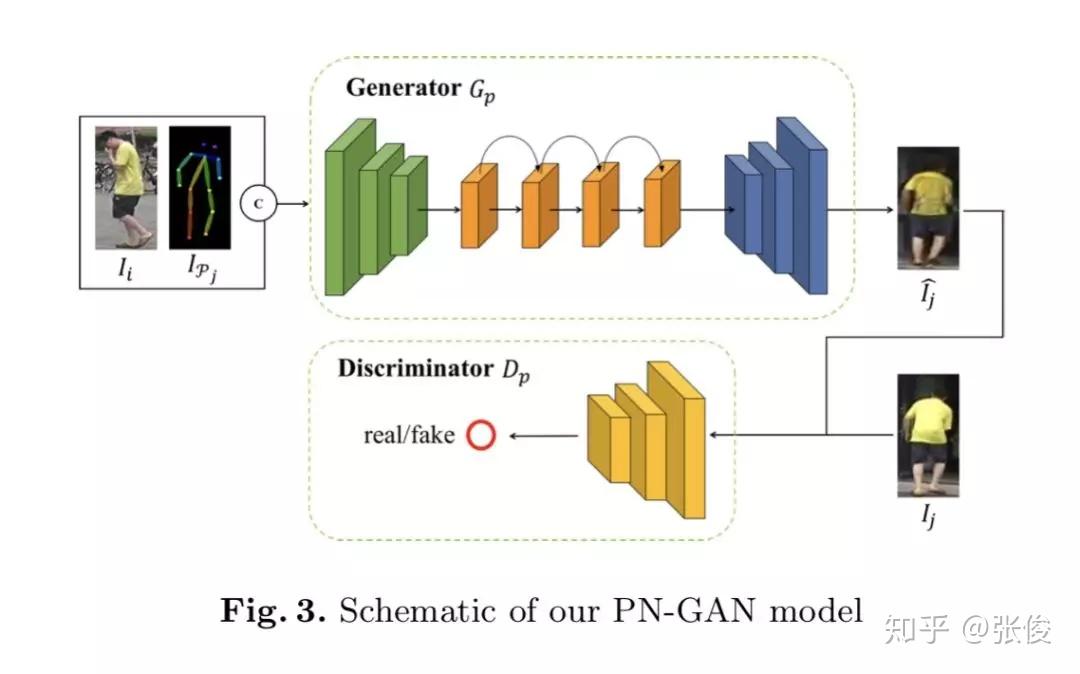


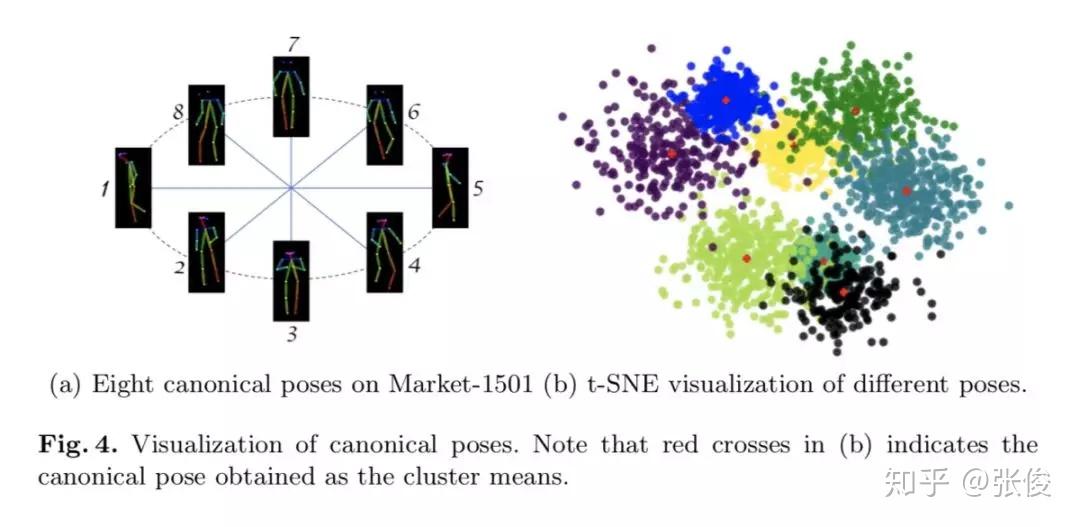
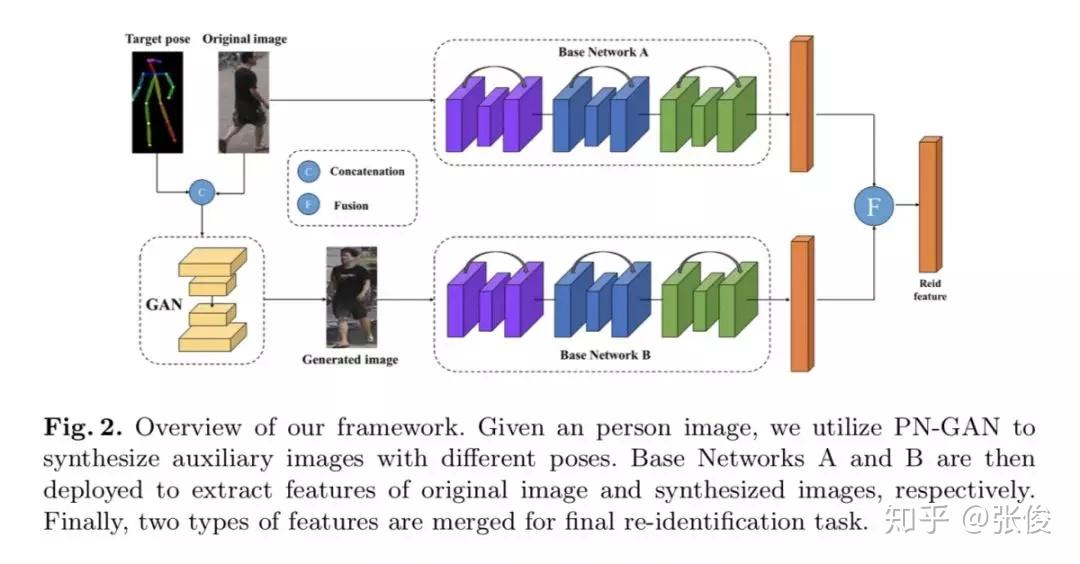
论文链接:https://www.paperweekly.site/papers/2361
源码链接:https://github.com/naiq/PN_GAN

@DanielTANG 推荐
#Object Tracking
本文来自 UCL,论文提出了一种动态 RGBD SLAM 方案,不仅能实现实时的场景感知 3D 重建,而且利用了 Mask RCNN 以及几何分割对 2D 图像进行实例分割,同时映射到 3D,建立 3D 模型的语义分割。并且将要开放源码,对于语义 SLAM 研究有着一定帮助。
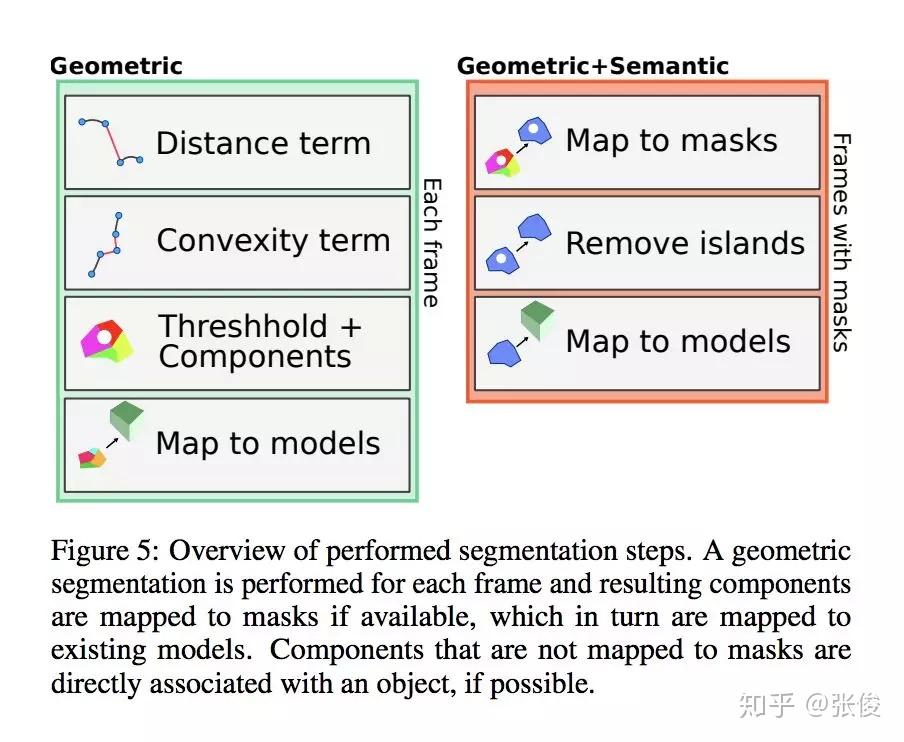
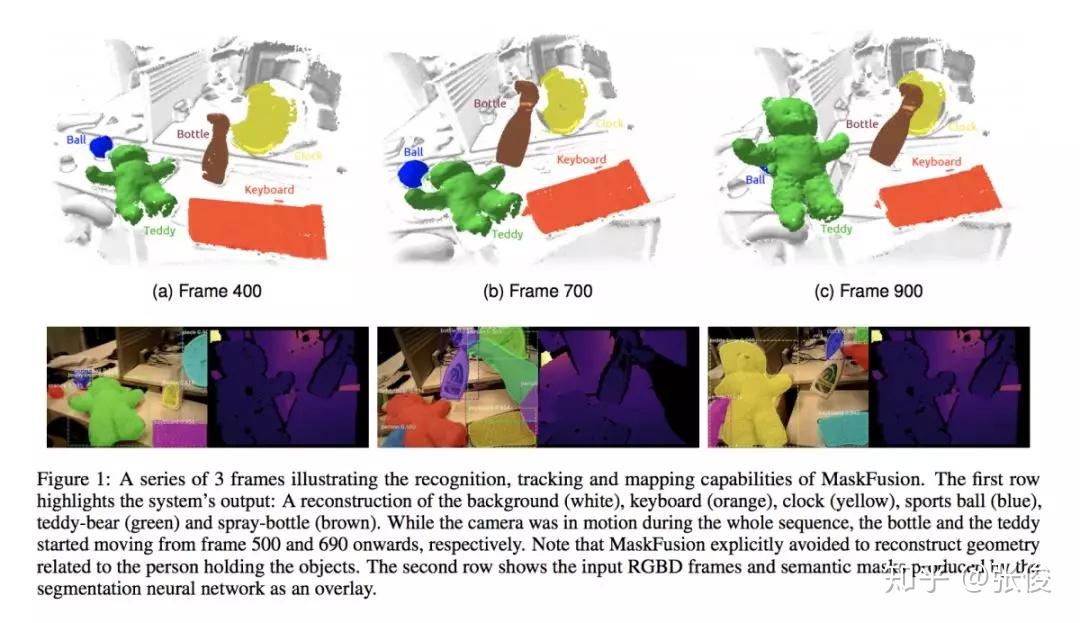

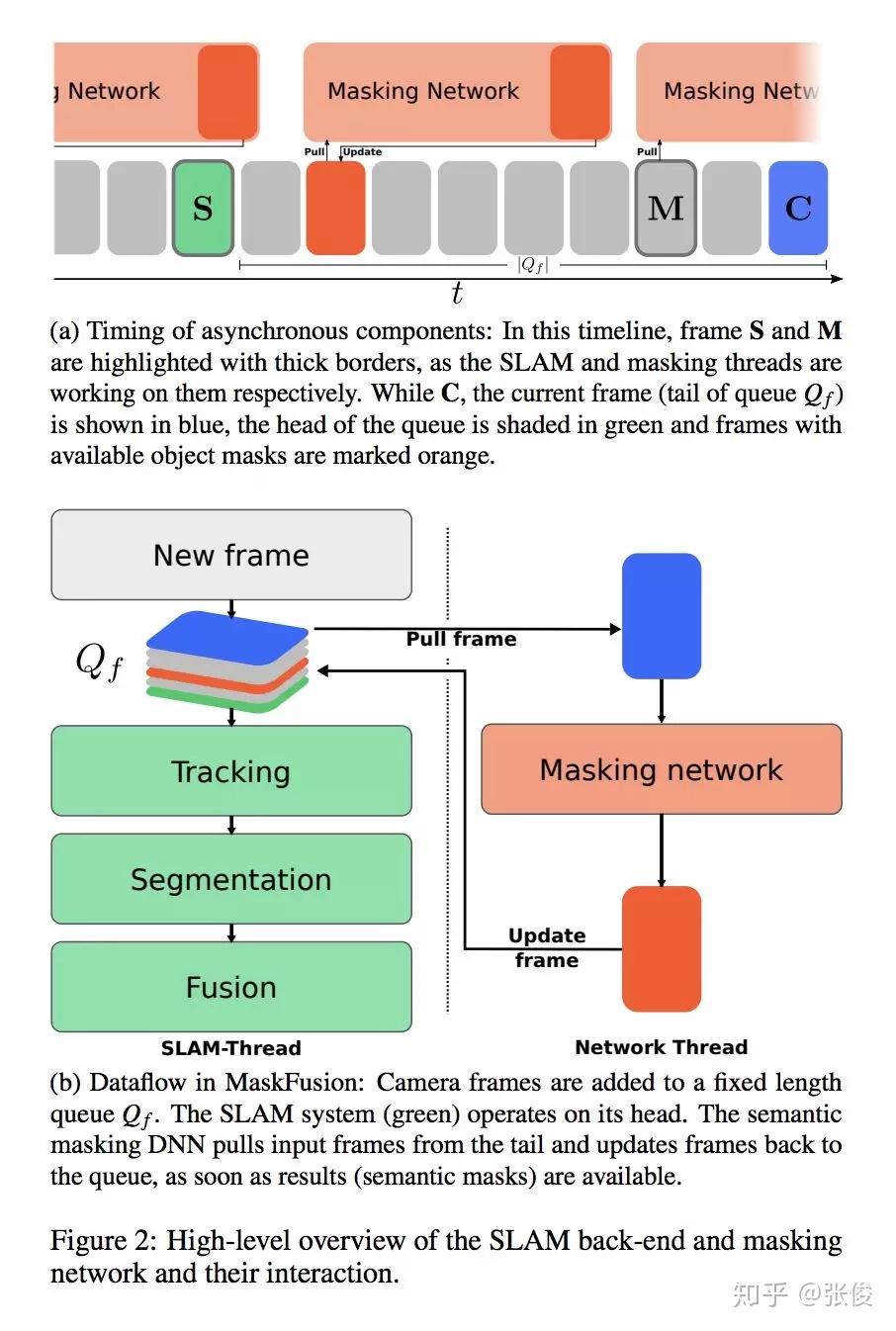
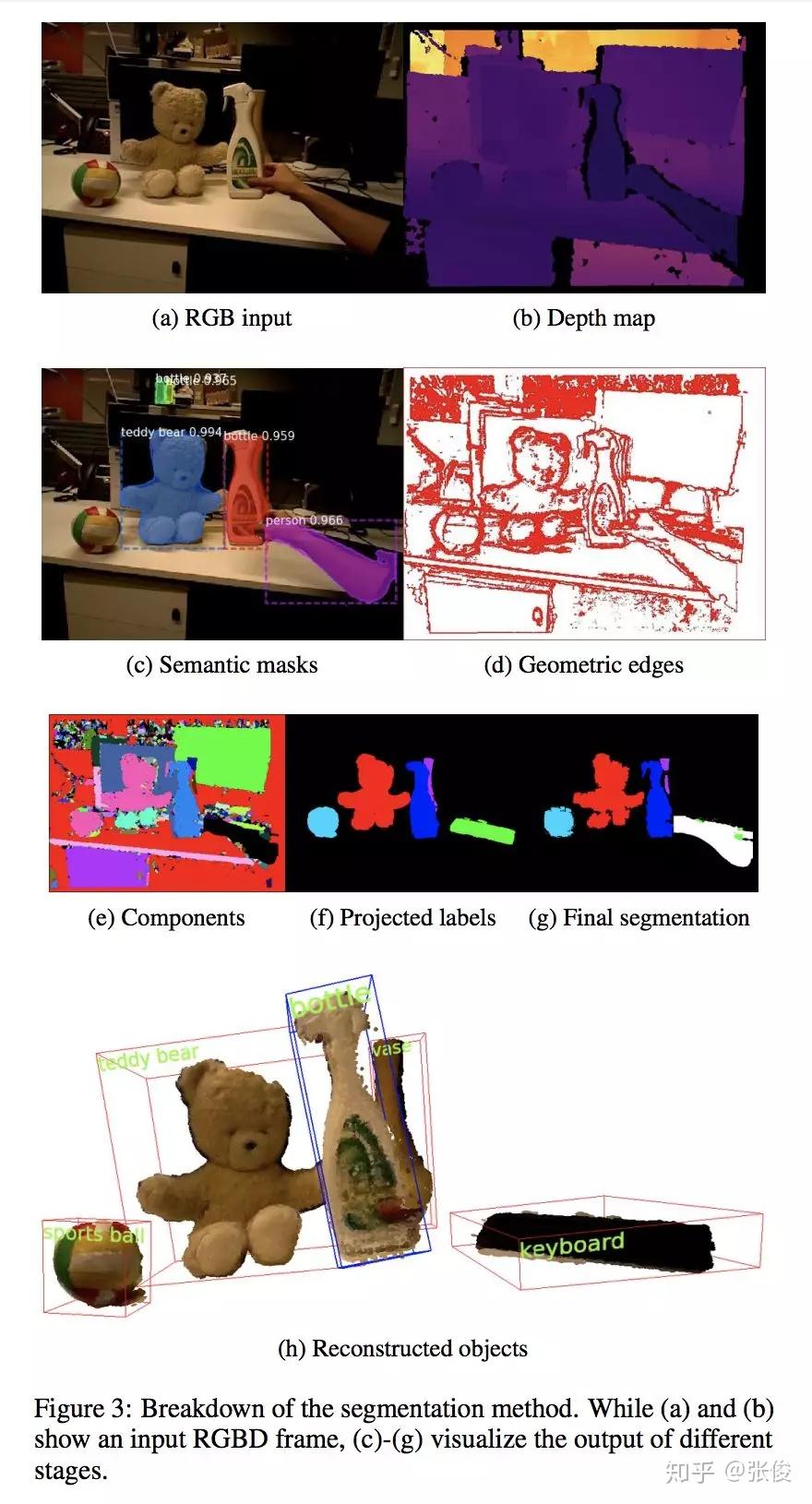
论文链接:https://www.paperweekly.site/papers/2314

@woonchao 推荐
#3D Reconstruction
本文是香港中文大学和腾讯优图联合发表于 ECCV 2018 的工作,论文提出了一个用于基于点云的 3D 模型重建损失函数,相较于传统的 Chamfer distance,这个损失能更好的刻画全局信息,对于提升 3D 模型重建效果有很大帮助。
论文用 GAL 来刻画重建之后的模型损失,它由两个术语组成,其中几何损失确保从不同视点接近 Groundtruth 的重建 3D 模型的一致形状,条件对抗性损失生成具有语义意义的点云。

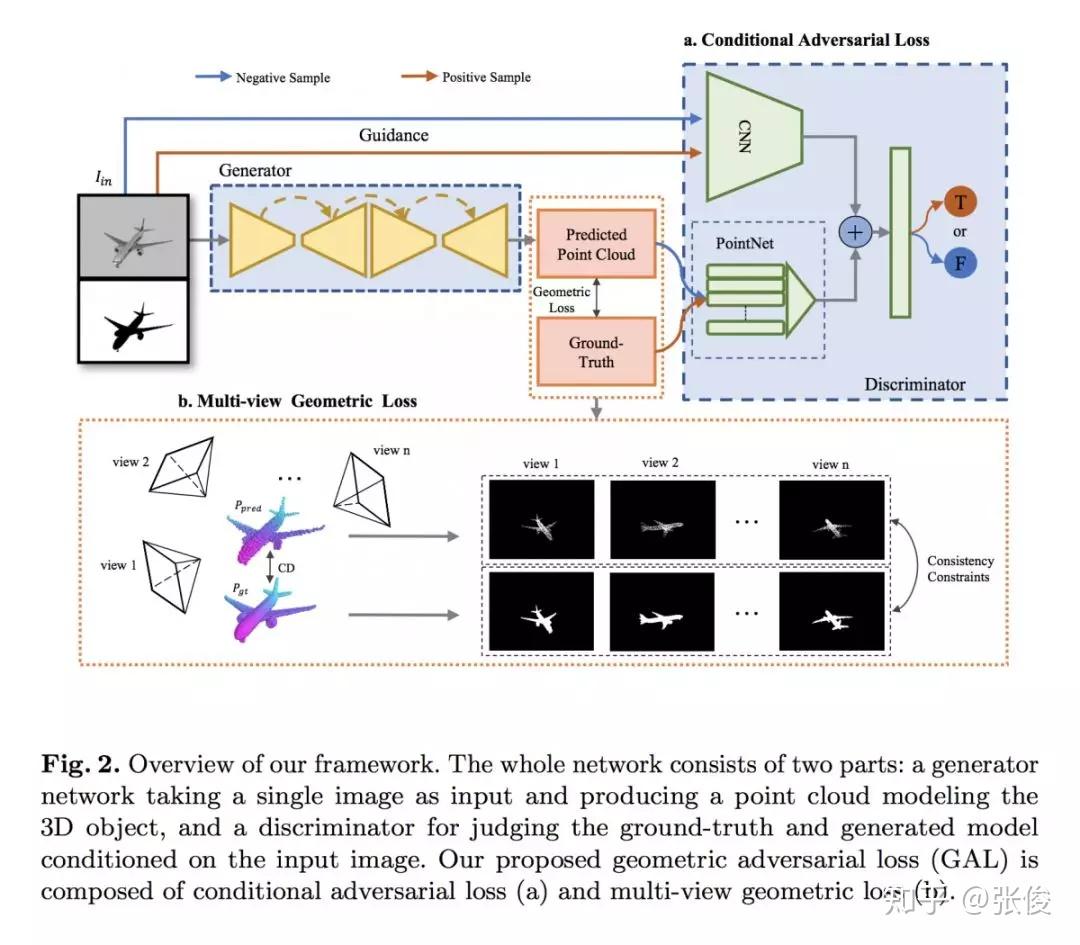
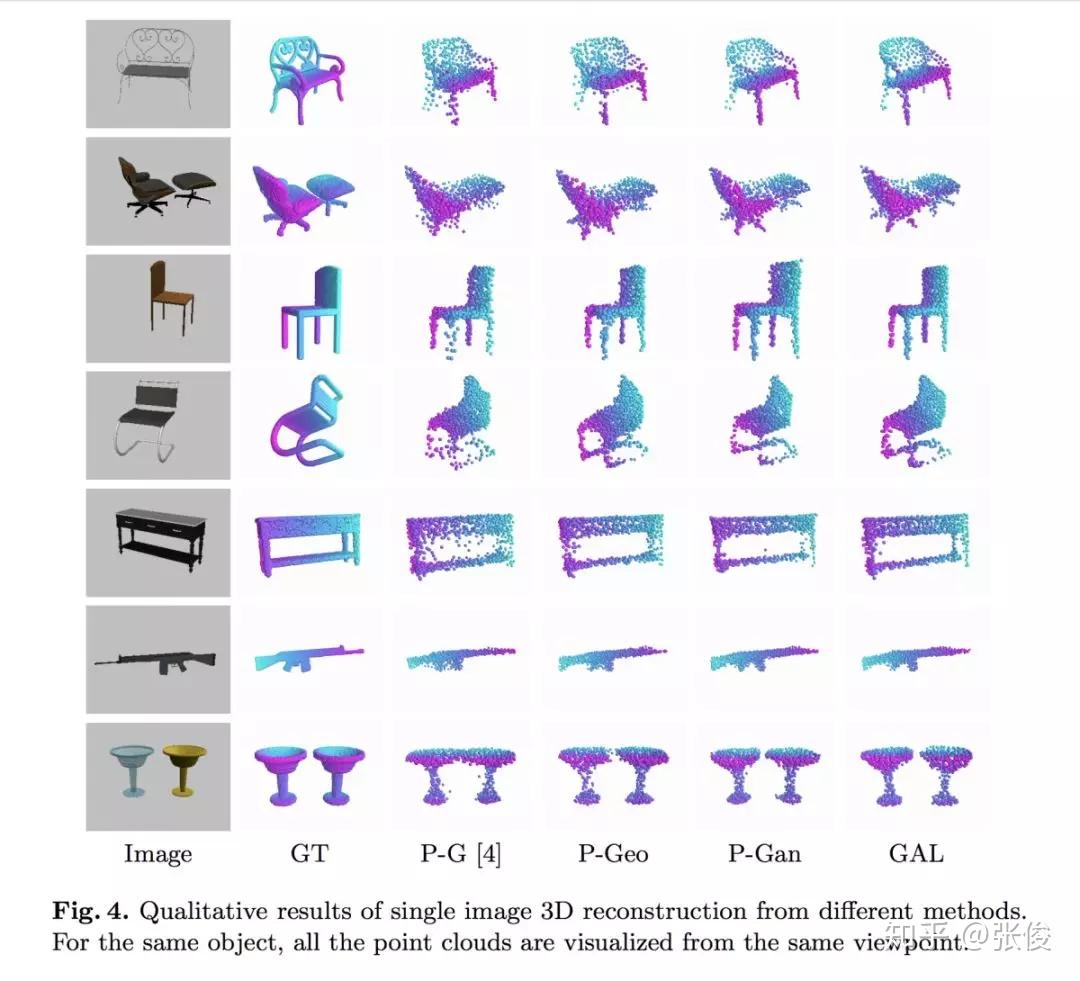

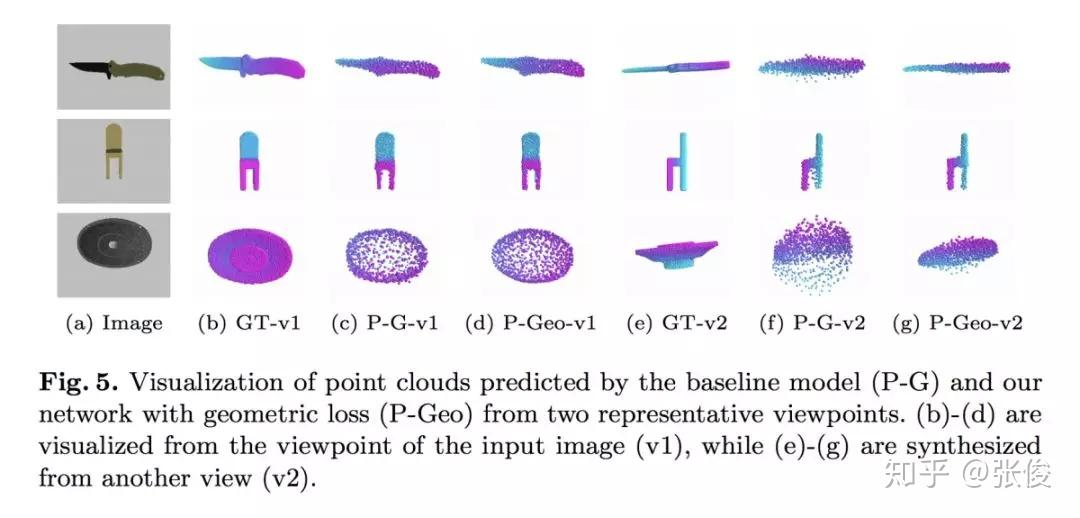
论文链接:https://www.paperweekly.site/papers/2334

@paperweekly 推荐
#Image Retrieval
本文是厦门大学和悉尼科技大学发表于 ECCV 2018 的工作,论文提出了一种异质同源学习方法来解决无监督域适应问题,归根结底其依然是基于 GAN 生成图的工作。
本文工作主要基于两个假设:1. 相机不变性,同未标注的正样本对来学习到相机的风格;2. 域连通性,即 source 和 target 域的行人图片默认没有重叠,是负样本对。第一点是同源学习,因为用的样本都是相同域的。第二点是异质学习,因为用到了两个域的样本。

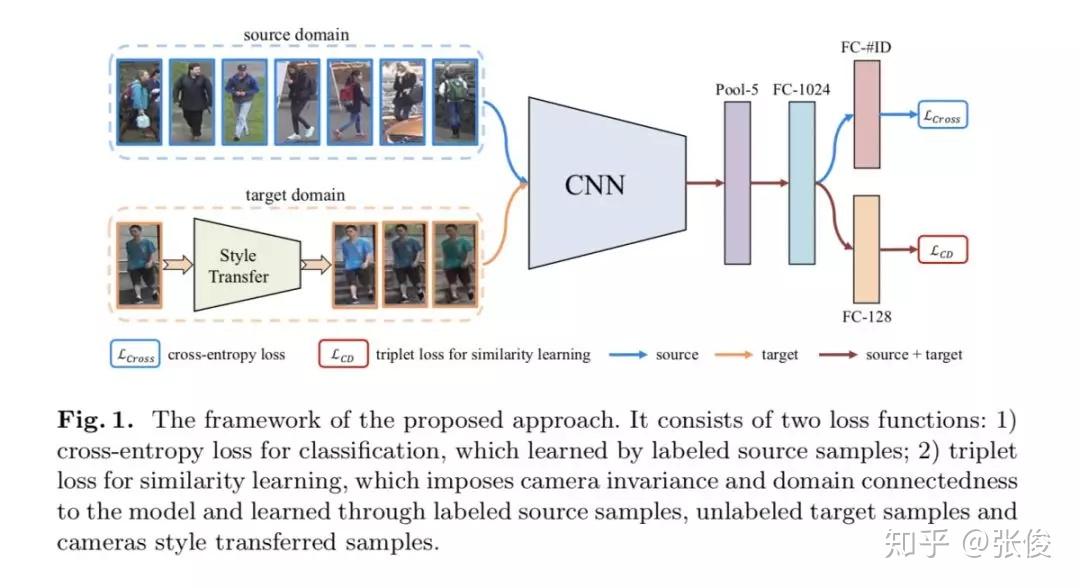
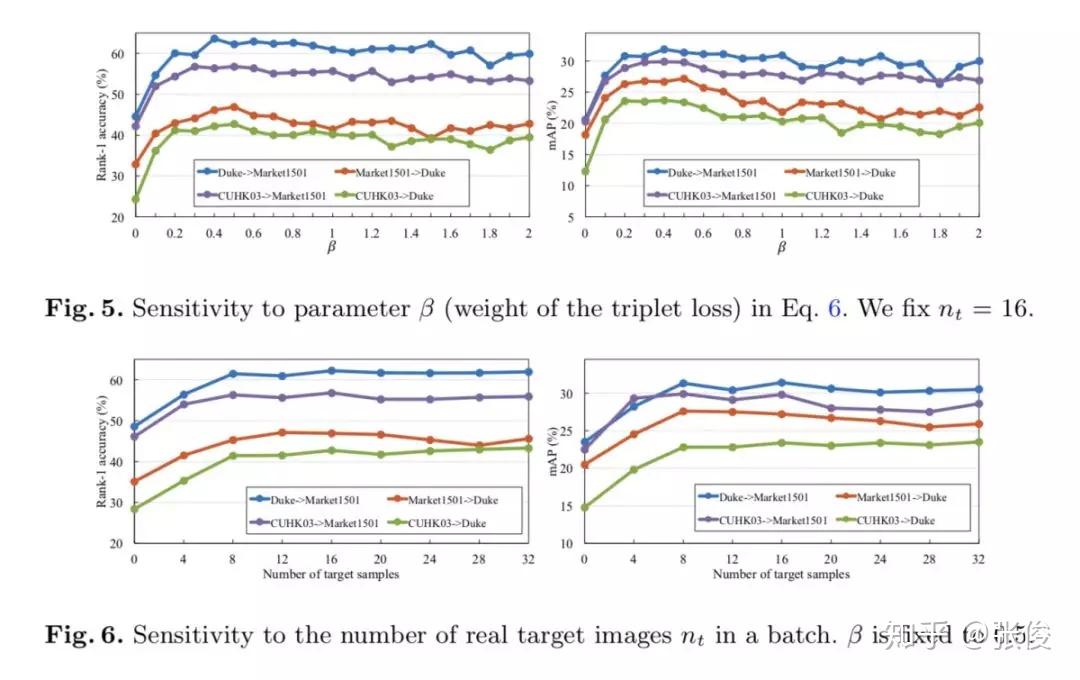
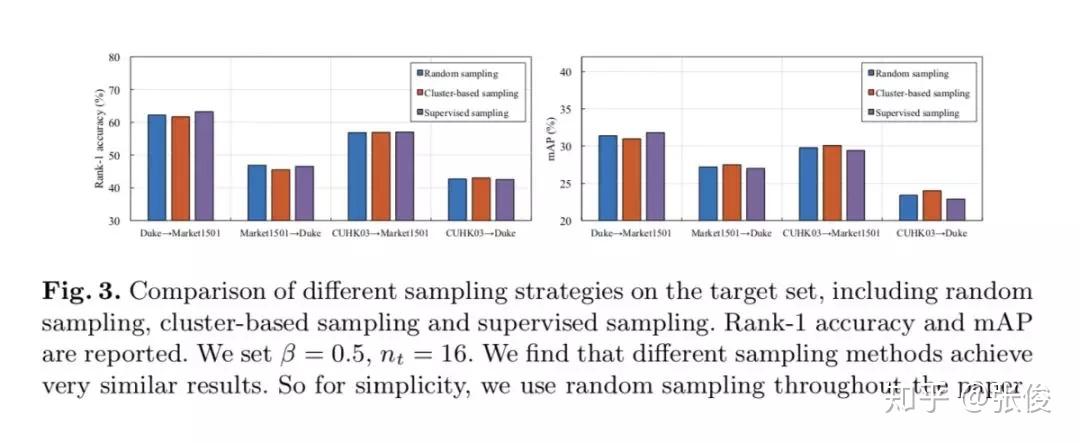

论文链接:https://www.paperweekly.site/papers/2362
源码链接:https://github.com/zhunzhong07/HHL

@xuehansheng 推荐
#Network Embedding
本文是香港科技大学和腾讯发表于 IJCAI 2018的工作,论文提出了一种可扩展的多路复用网络嵌入模型(scalable multiplex network embedding model),将多字形关系的信息表示为一个统一的嵌入空间。
为了在保持其独特属性的同时组合不同类型关系的信息,对于每个节点,作者为每种类型的关系提出一个高维公共嵌入和低维附加嵌入。然后,可以基于统一的网络嵌入模型联合学习多个关系。
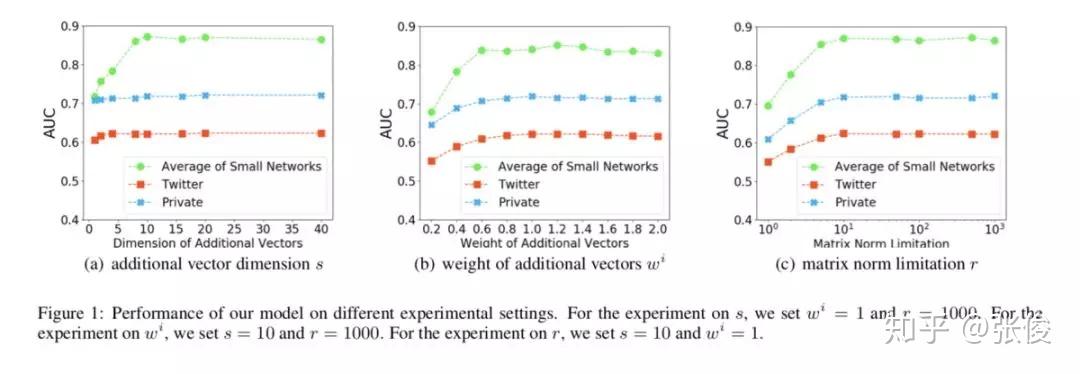
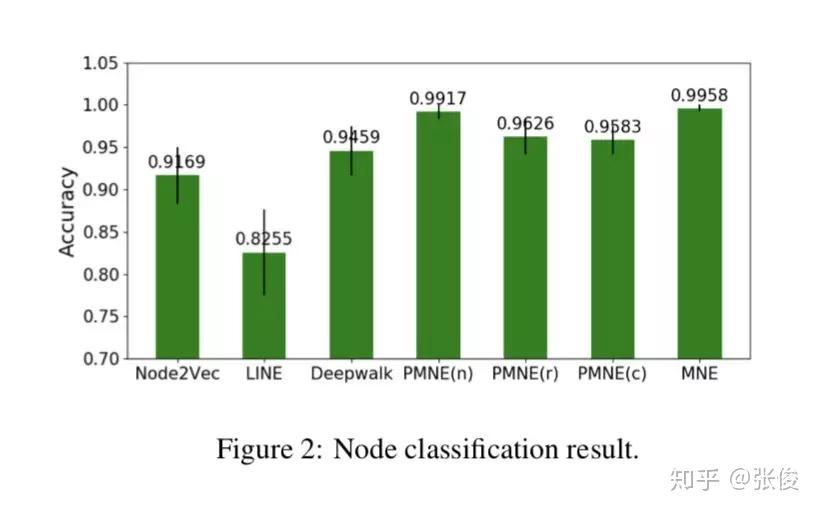

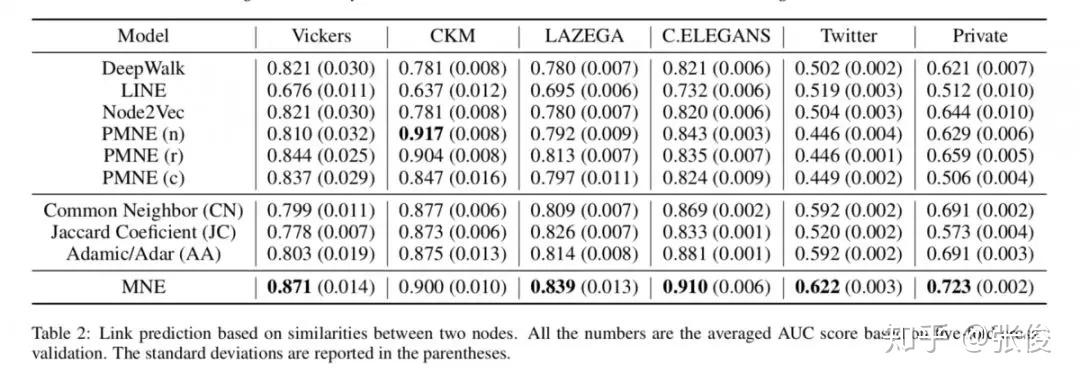
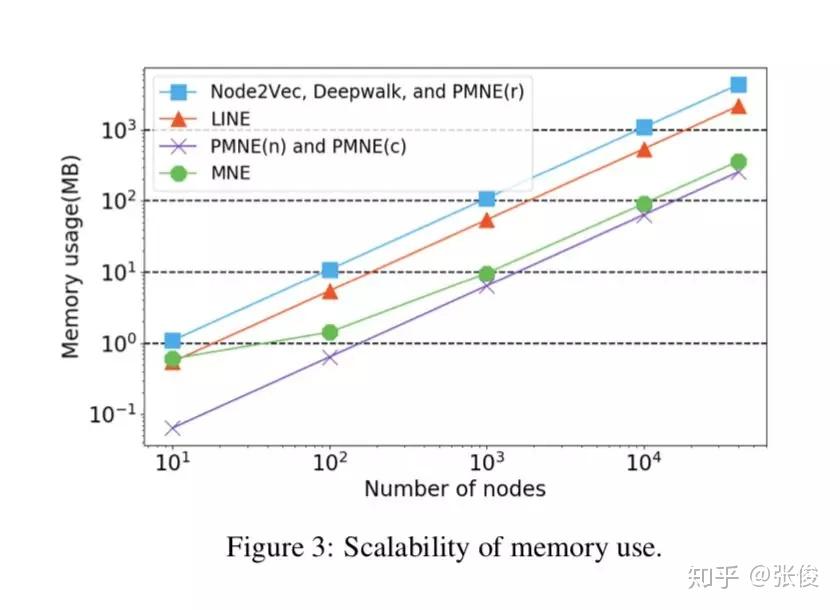
论文链接:https://www.paperweekly.site/papers/2305
源码链接:https://github.com/HKUST-KnowComp/MNE

@simonhua 推荐
#Neural Networks
本文利用 ML 对网络进行建模用来评估网络性能,成功对网络建模有利于网络优化,配合 SDN 在 SDN 控制器的帮助下能够有效对网络配置进行合理优化。本文提出了使用神经网络根据输入流量函数准确对网络时延进行建模。
作者基于不同计算机网络参数(网络拓扑,网络大小,流量强度,路由策略)训练了不同神经网络模型,研究了不同的计算机网络参数对于学习能力有何影响,对未来使用机器学习对网络建模的可行性进行了验证并提出了几点讨论建议,可以作为实际环境部署的指南方针。
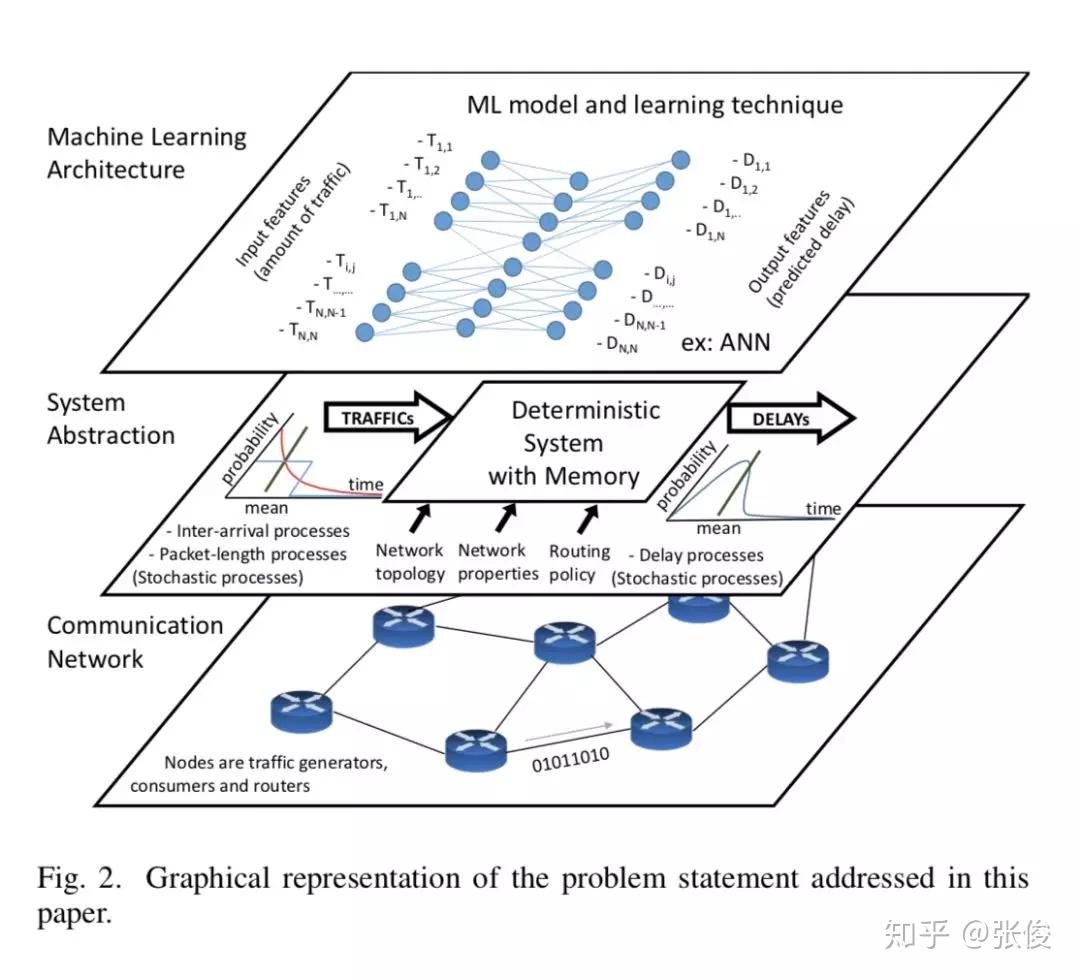
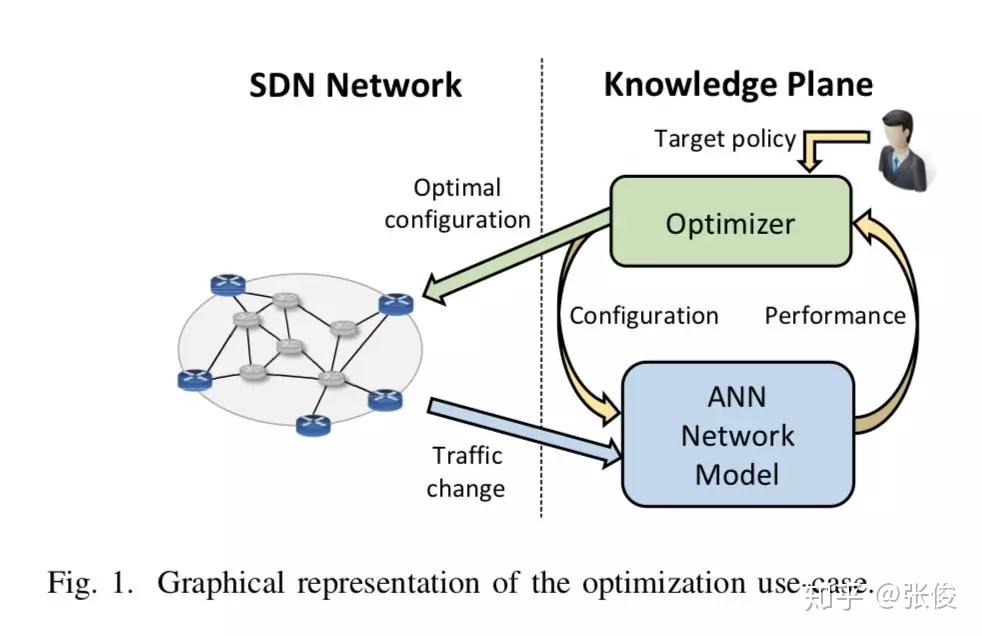
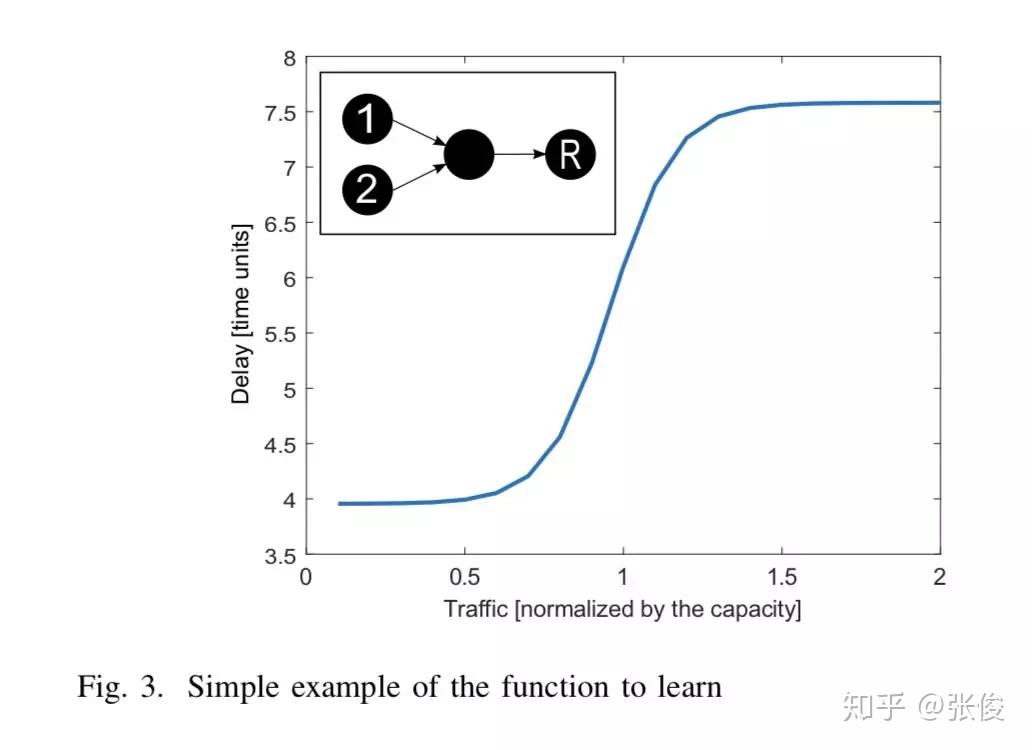
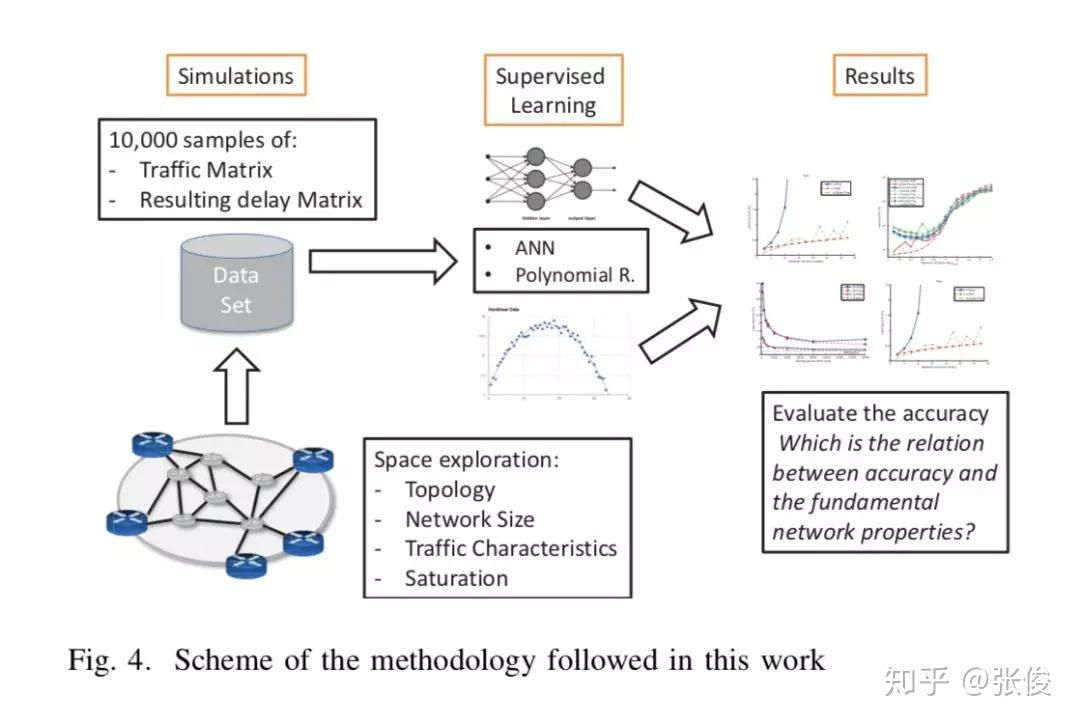
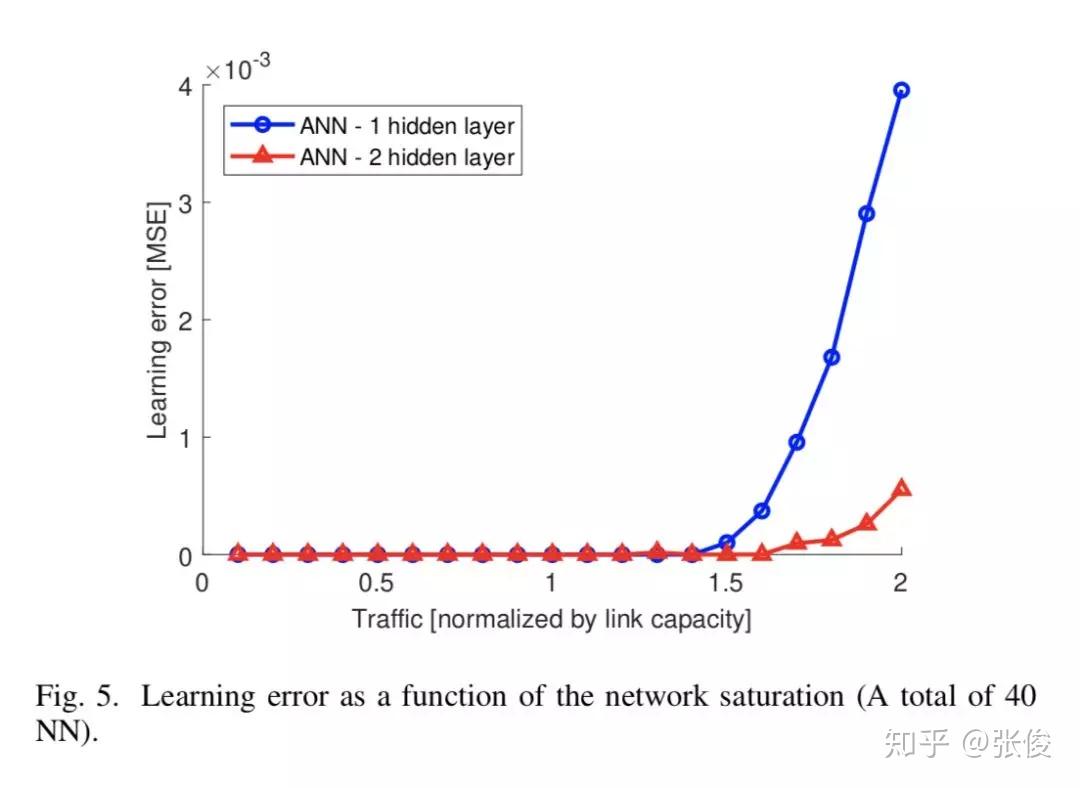
论文链接:https://www.paperweekly.site/papers/2312

@MADONG 推荐
#Deep Reinforcement Learning
本文来自 DeepMind,论文主要贡献如下:
1. 关系推理中深度学习的加入:深度学习让关系表达的对象得以加入到我们的控制中,原先无法直接处理的物理对象可以引入了,这样 agent 与真实世界的交互变得可能了,推理也就变得有意义了。 深度学习对特征的提取功能,让关系强化学习能够关注在深度学习抽象后的特征中,把特征对应成自己需要掌握的关系对象。这样其实比直接对应真实的物体更进一步;
2. Attention 模块的加入:Attention 模块让关系强化学习中关系的表达得以更优秀。原本的 RNN 等算法对于序列的长短比较敏感,但是在 attention 机制下,两个向量之间关系的计算不再受向量之间距离的影响。同一个场景下欧式距离较远的对象也可以很好的提取出存在的关系;
3. 强化学习的加入:在这里主要是监督 attention 模块中权值 w 的改变调整。

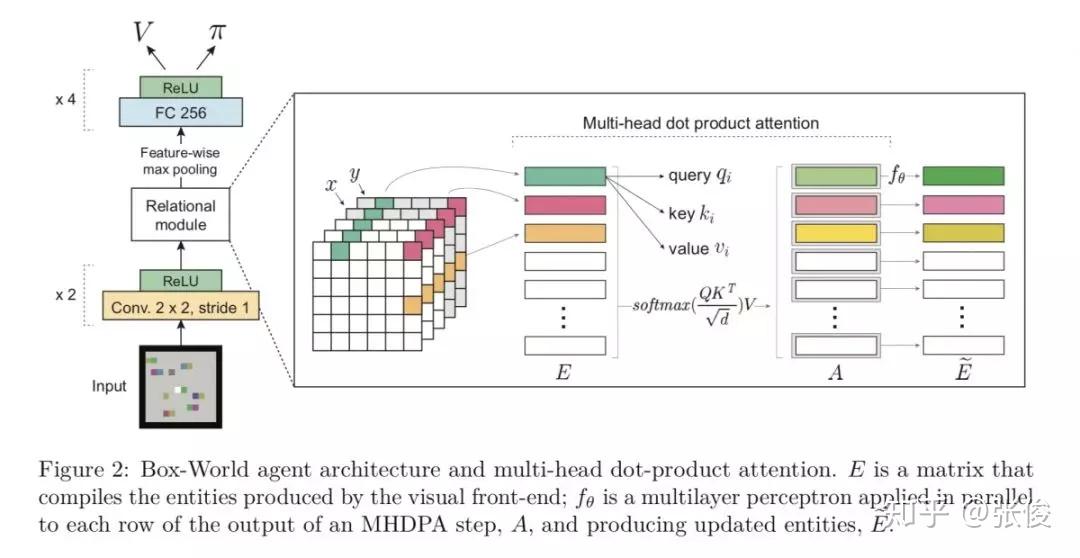
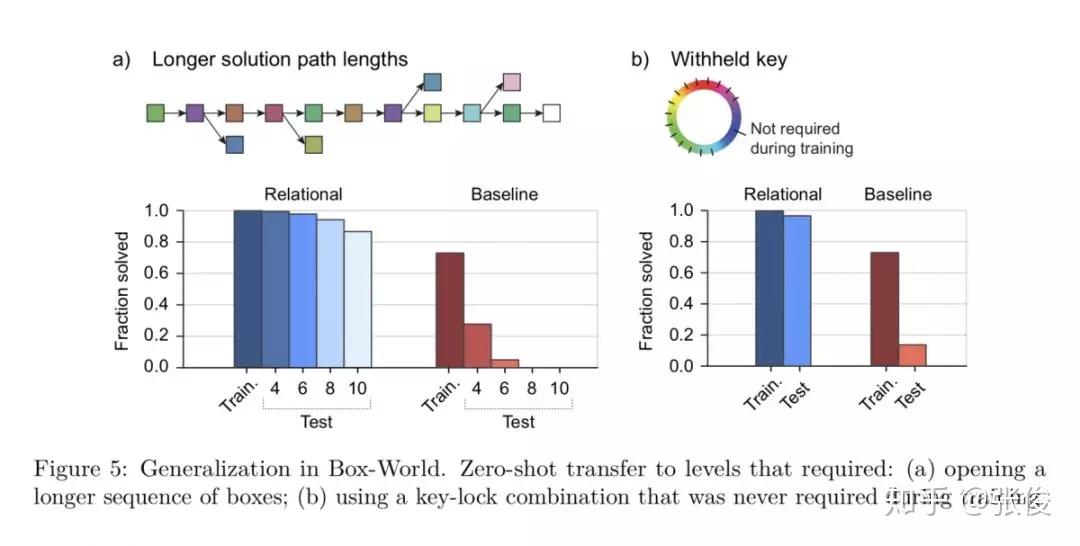
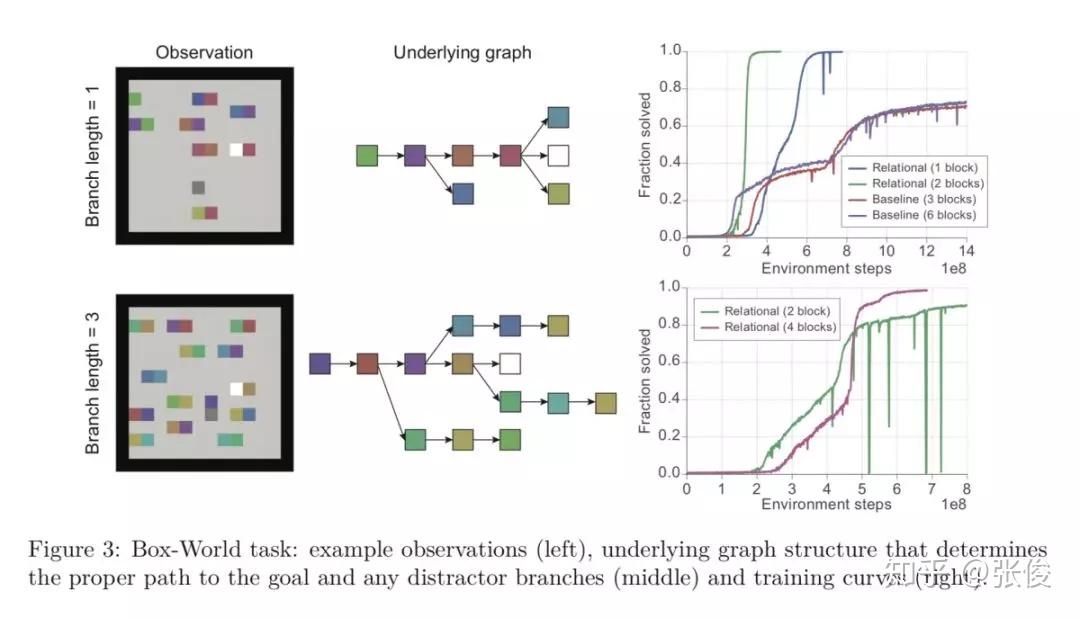
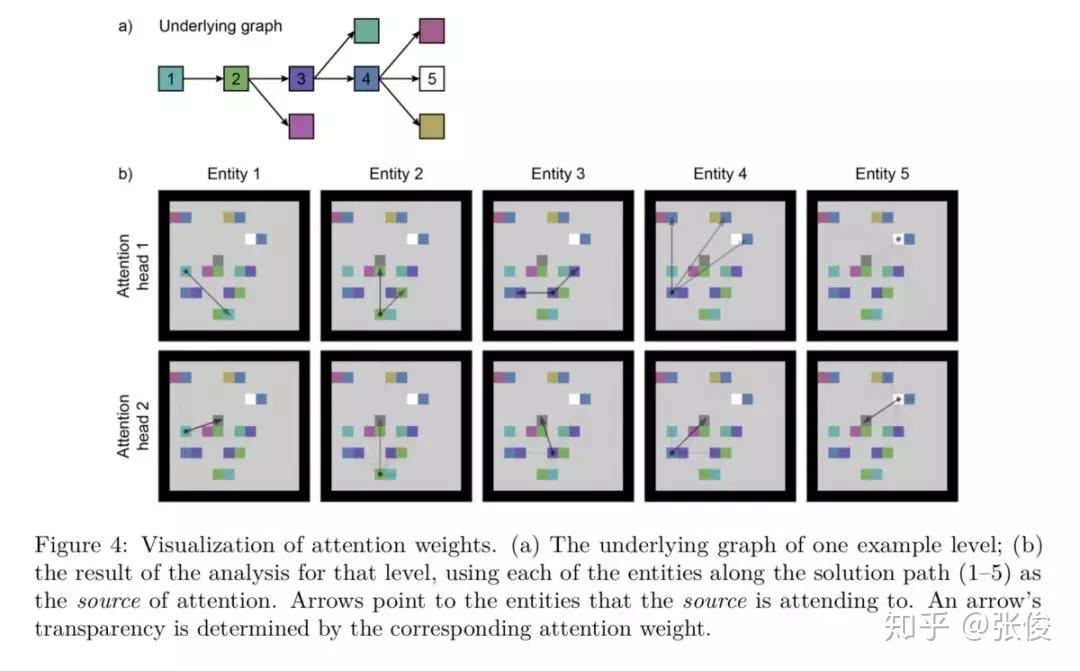
论文链接:https://www.paperweekly.site/papers/2300

@xuehansheng 推荐
#Network Embedding
本文来自亚利桑那州立大学,论文提出了一种新颖的多级网络嵌入框架 BoostNE,它可以学习从粗到细的不同粒度的多个网络嵌入表示,而不会强加普遍的全局低秩假设。方法新颖值得深入研究。
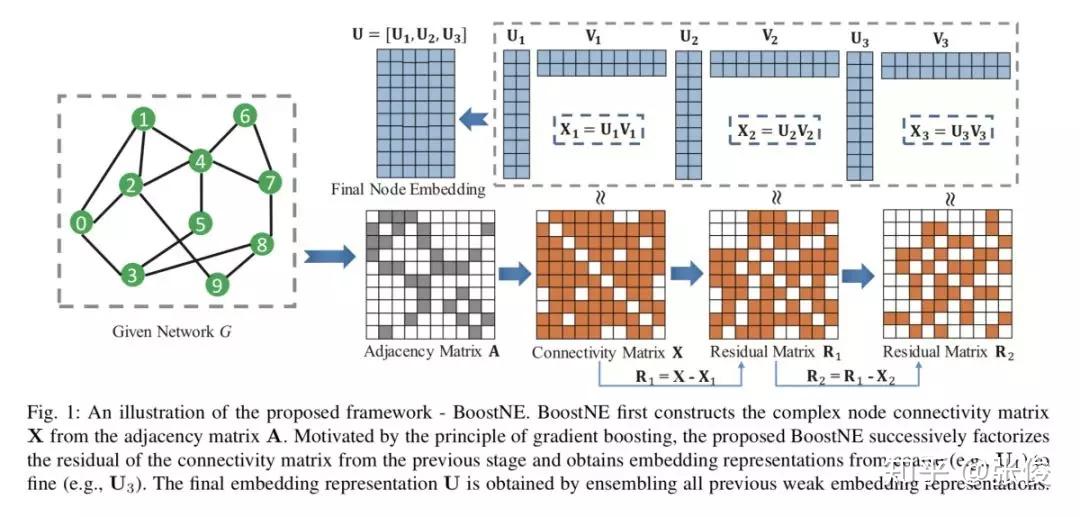

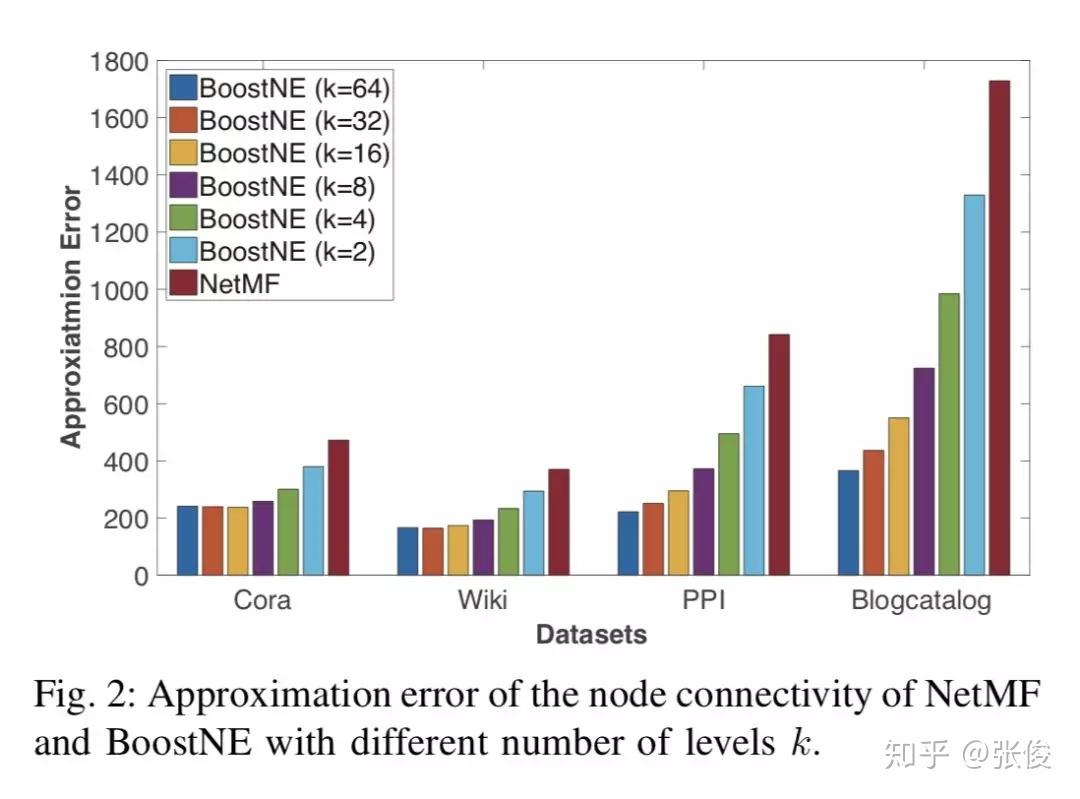
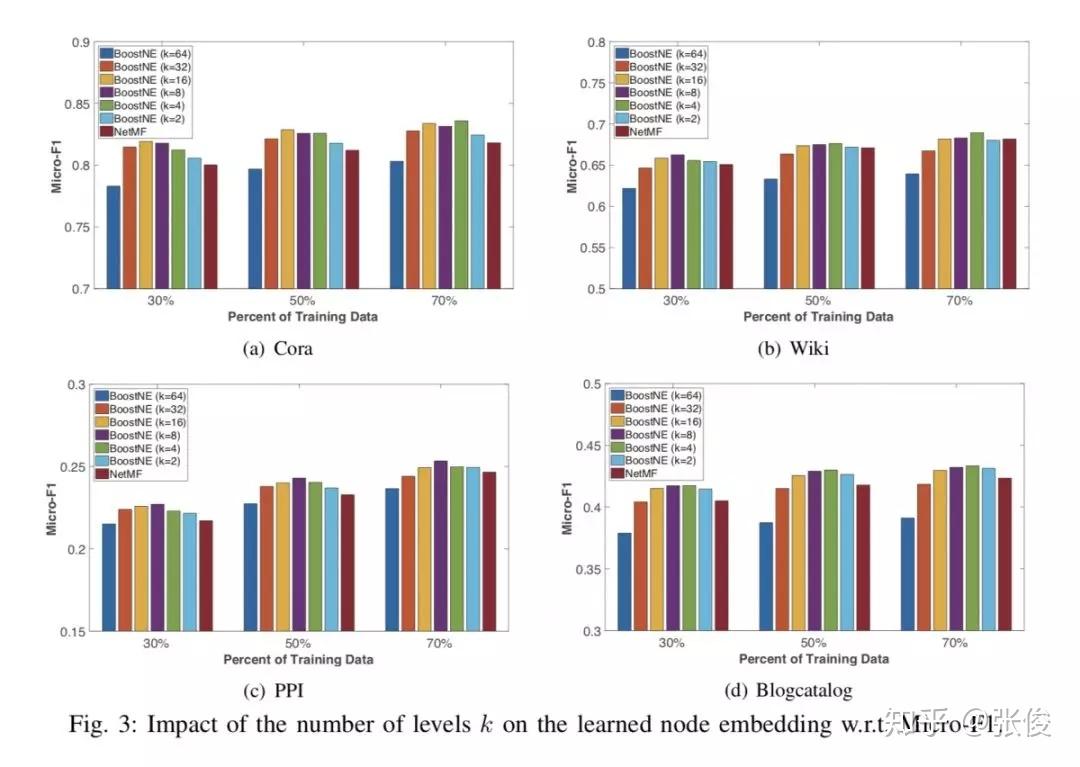
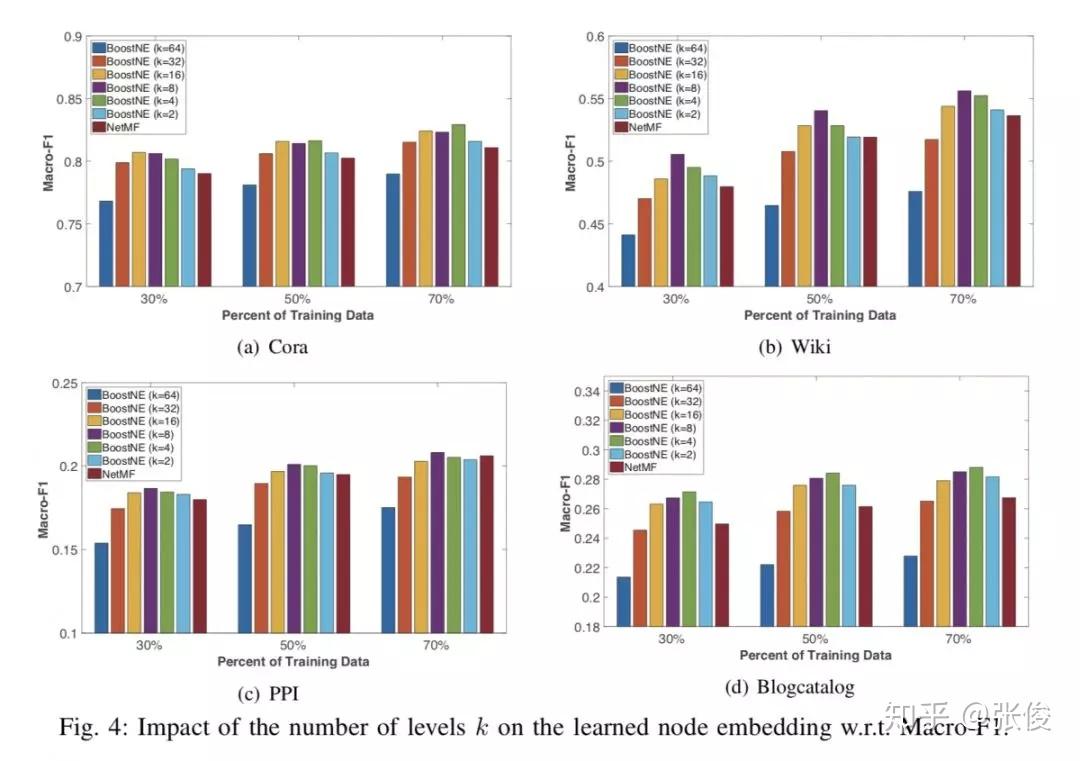
论文链接:https://www.paperweekly.site/papers/2269

@linxi2333 推荐
#Audio Generation
本文是对 DeepMind 的 Tacotron2 的改进,Tacotron2 是一种端到端的语音合成系统。论文单高斯简化了 parallel WaveNet 的 KL 目标函数,改进了蒸馏算法(distillation),使得结构更简单,更稳定;通过 Bridge-net 连接了 Tacotron(特征预测网络)和 WaveNet,彻底实现端到端。

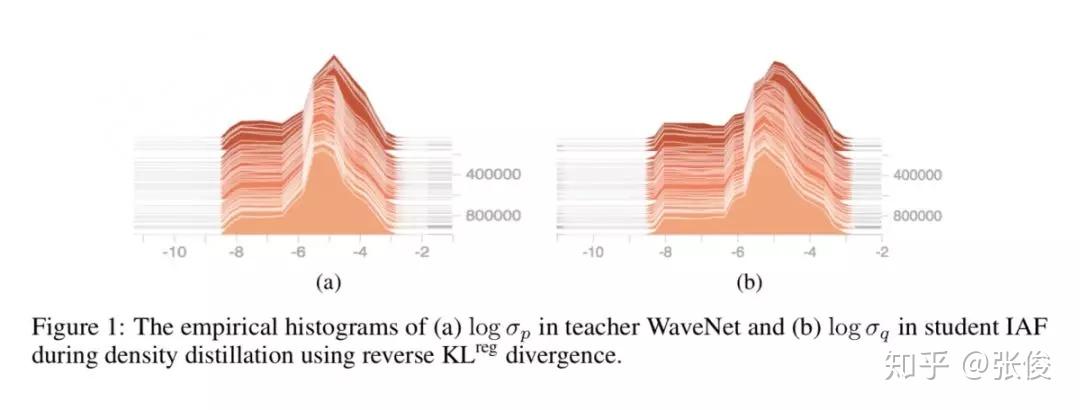
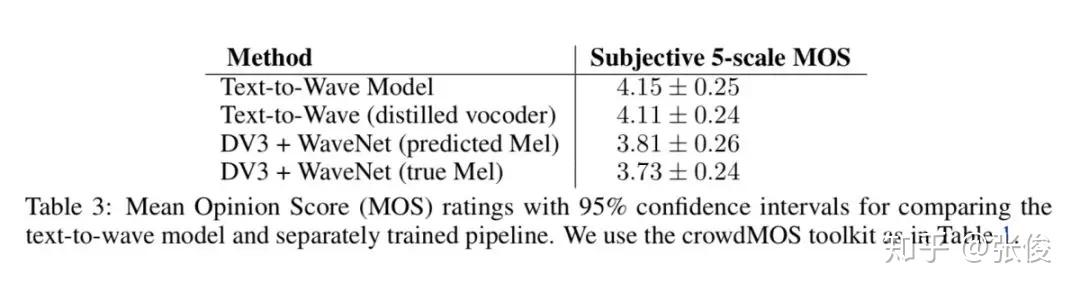
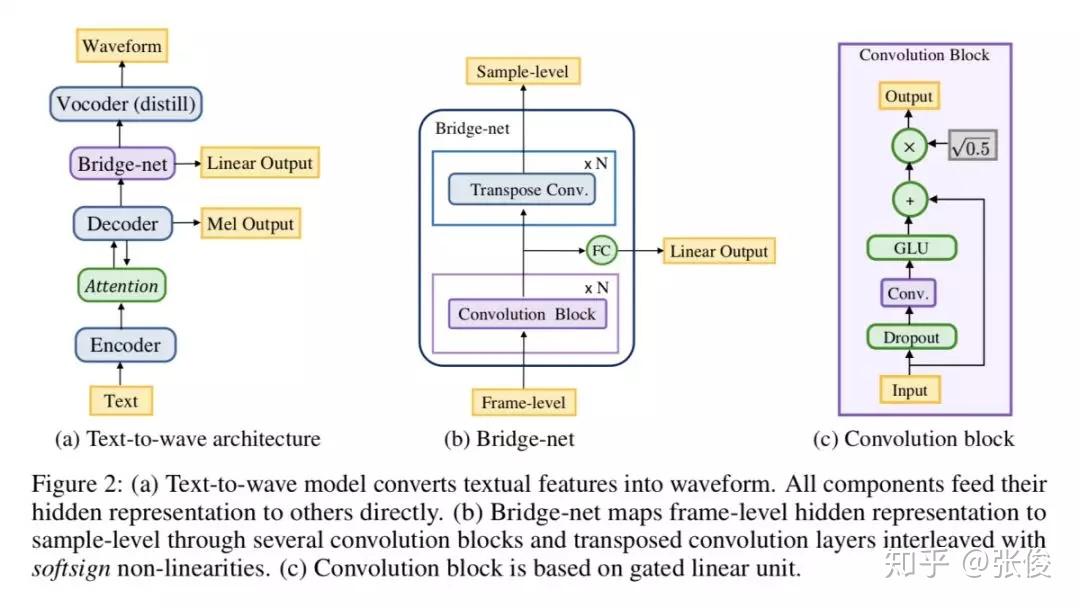
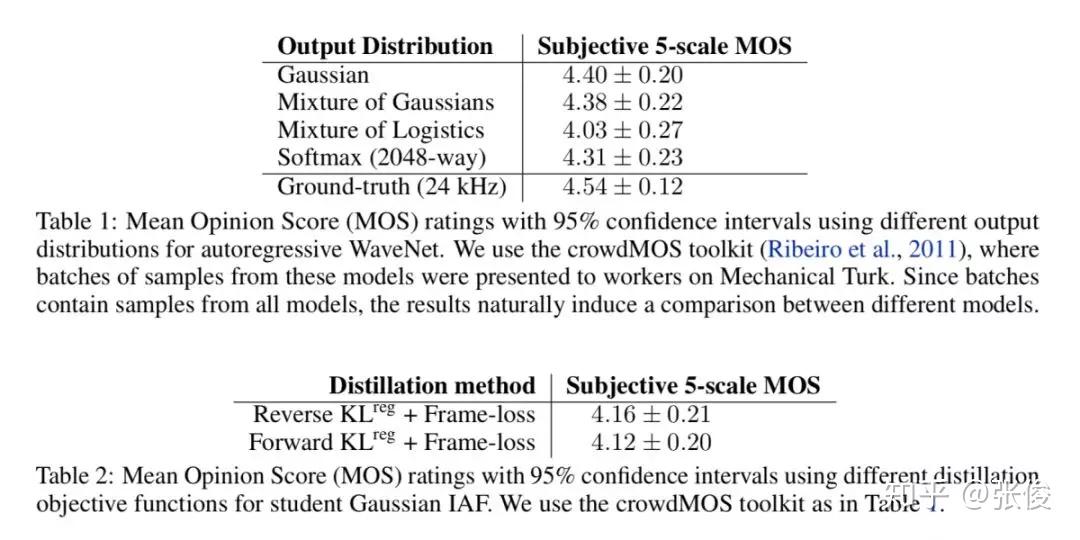
论文链接:https://www.paperweekly.site/papers/2290
Demo链接:https://clarinet-demo.github.io/

@Ttssxuan 推荐
#Reinforcement Learning
本文对 ALE (Arcade Learning Environment) 平台做了进一步深入介绍,主要从以下几点出发:1. 总结了关于 ALE 相关问题的经验,如:Frame skipping, Color averaging and frame pooling 等;2. 总结最新成果,以及当前待解决的一些问题 ;3. 新的 ALE 版本,介绍了新平台的特性,如:sticky actions, multiple game modes 等。
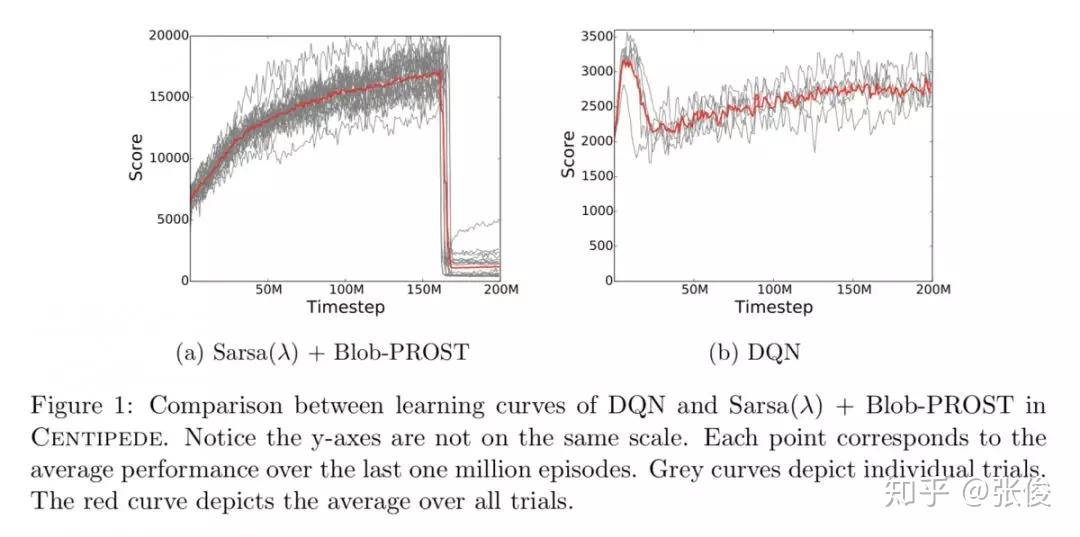
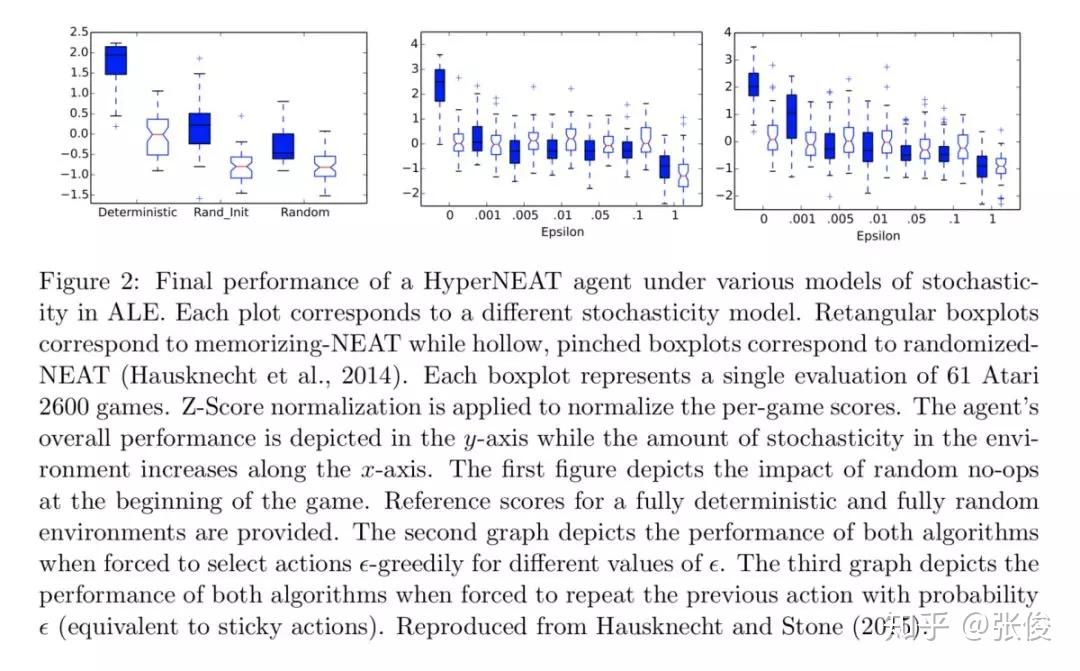
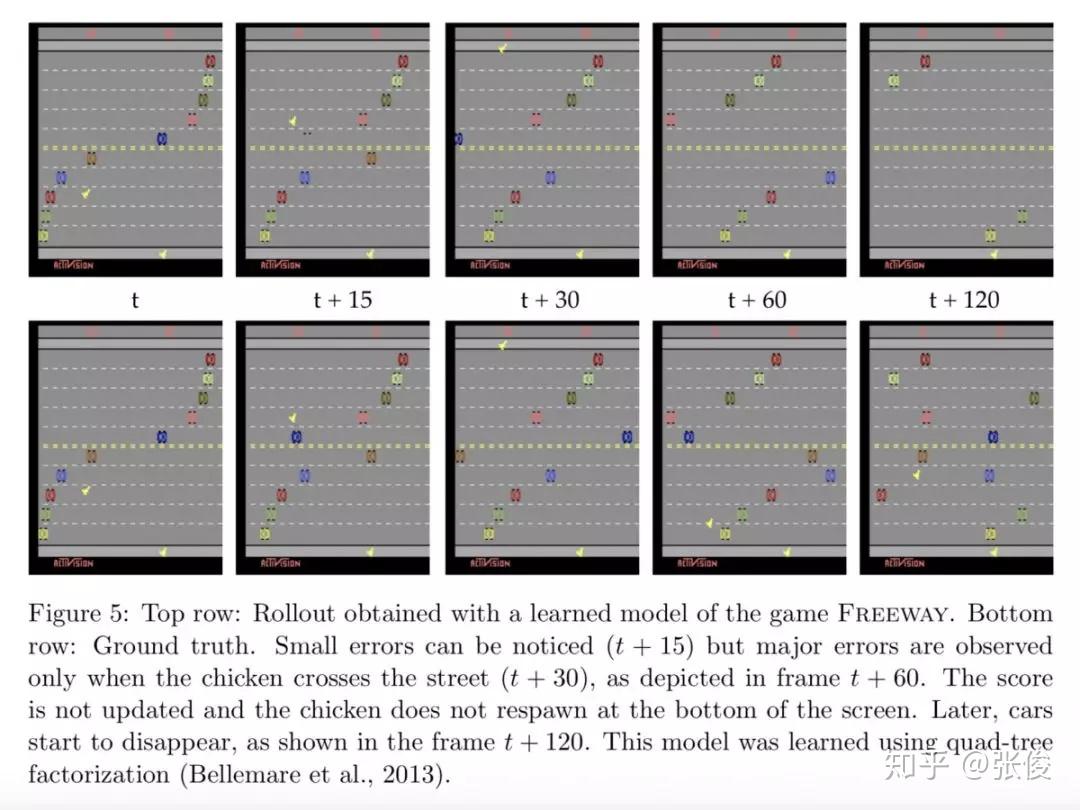
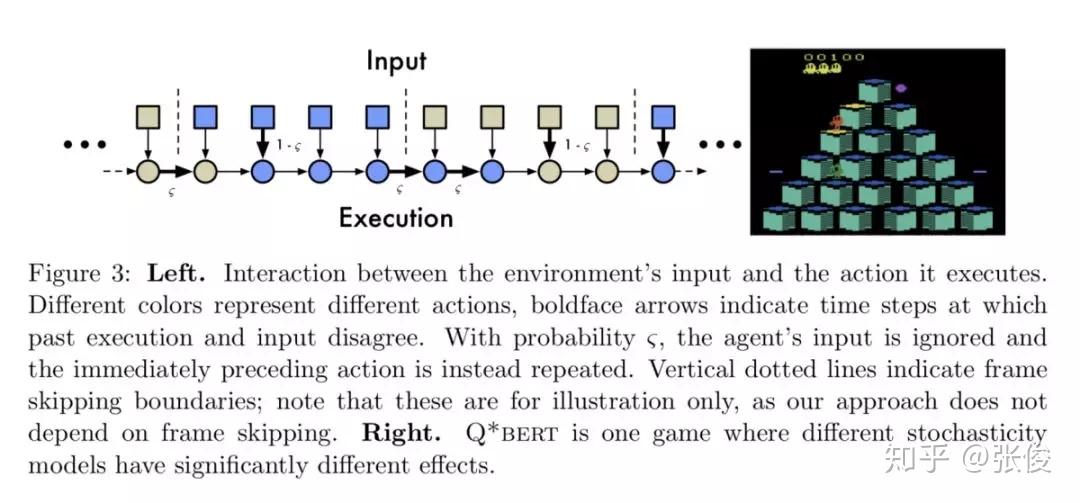
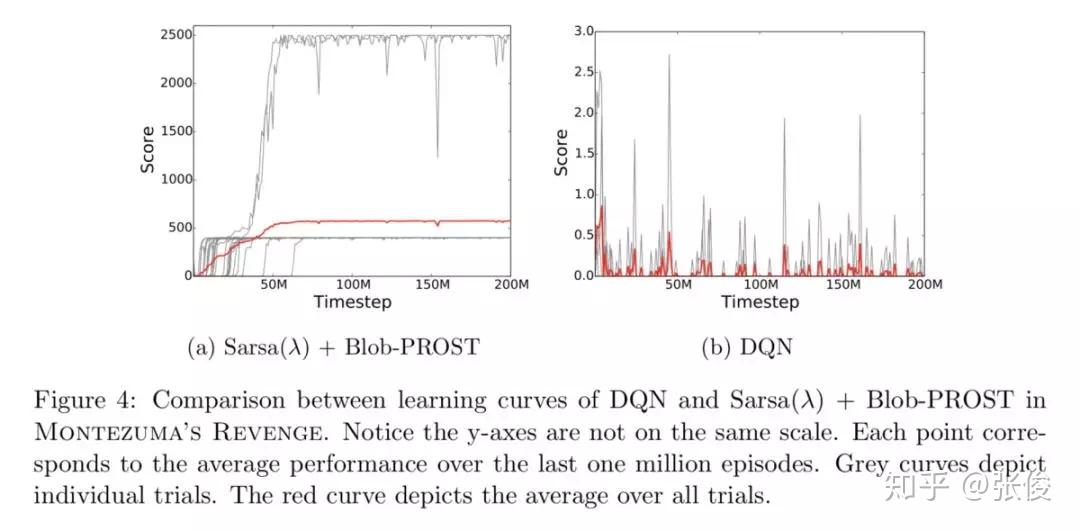
论文链接:https://www.paperweekly.site/papers/2343
源码链接:https://github.com/mgbellemare/Arcade-Learning-Environment
#投 稿 通 道#
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢? 答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
投稿方式:
• 方法一:在PaperWeekly知乎专栏页面点击“投稿”,即可递交文章
• 方法二:发送邮件至:hr@paperweekly.site ,所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
加入社区:http://paperweek.ly
微信公众号:PaperWeekly
新浪微博:@PaperWeekly

AI时代,拥有个人微信机器人AI助手!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
搜索微信号aigc666aigc999或上边扫码,即可拥有个人AI助手!



