文章主题:AI, ChatGPT, GPT-4, 模型训练
从一个AI学习者的视角来看待ChatGPT,站在业界巨匠的肩头之上进行创新尝试。我只是一个学术界的小工匠,擅长修补各位专家所传授的各项技术知识。如果想要对这些技术有更深入的理解,建议您去阅读文末的正统专家们发表的学术著作。
全文阅读时长:15min
背景介绍
ChatGPT太牛批引起了全球关注,不光卷AI圈内人,还连带卷了圈外人。
发展现状
ChatGPT和去年公布的InstructGPT是一对姊妹模型,它们有时被称作GPT-3.5。这两款模型是在GPT-4发布之前的预热版本,因此,它们具有重要的历史地位。据传,尚未正式发布的GPT-4是一款多模态模型,这意味着它将能够处理多种类型的输入,包括文本、图像、音频等。这将使得GPT-4的输出更加丰富多彩,为用户带来更为丰富的体验。对于ChatGPT而言,它的能力也将得到进一步提升,不仅能够理解并生成文本,还可能能够理解并处理其他模态的信息,从而使得其生成的回复更加生动有趣。
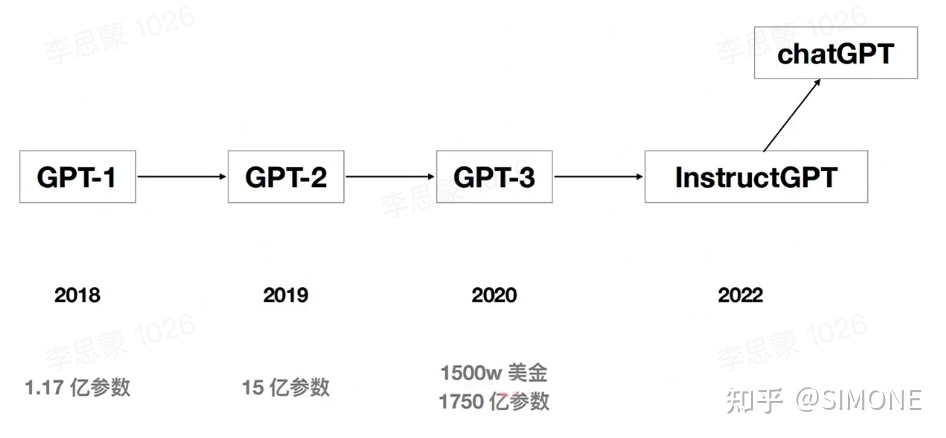
GPT进化史
模型架构
ChatGPT和InstructGPT在模型架构和训练策略上具有高度相似性,它们均采用了指令学习和人工反馈强化学习(RLHF)的方法来优化模型性能。尽管两者在数据收集方式上存在差异,但这并不会影响我们对ChatGPT模型及其训练过程的理解。事实上,借助于InstructGPT的研究成果,我们已经可以对ChatGPT的模型结构和训练细节有更深入的认识。
核心技术
指令学习(Instruct learning):其实就是prompt learningRLHF(Reinforcement Learning from Human Feedback):基于人工反馈的强化学习
训练步骤
在本篇文章中,我们将深入探讨 InstructGPT/ChatGPT 的训练过程,并将其拆分为三个主要阶段:SFT、RM 和 PPO。接下来,我们将逐一剖析这些阶段的原理及实际应用。

InstructGPT/ChatGPT模型架构
1.SFT
ChatGPT 作为一个对话模型,其工作原理是什么?首先,我们需要了解它依赖于一项名为 SFT 的技术。SFT 的全称是 Supervised FineTune,这是一种针对 GPT-3 的有监督微调技术。它的核心目标是优化数据集,具体来说,就是利用人类喜闻乐见的答案作为训练数据,让机器生成的内容更符合人类的喜好。
GPT原本是使用互联网海量语料库训练的大模型,但互联网上的语料非常杂乱,不一定是人类想要的答案,GPT依靠此数据生成的答案正确性和有用性不能保证。在此基础上,对数据集优化,把人们喜欢的答案喂给已经训练好的GPT再次微调,这样模型可以对齐人的思考模式得到提升。可以理解成升级后的模型只订阅人们喜欢的内容。对话机器人的雏形已经生成,它可以根据问题生成一系列的答案,但是缺陷是它不具备人的判断能力。机器生成了答案A,B,C,D,但哪个是想要的呢的答案呢?由此,引入RM奖励模型。

SFT工作流
2.RM
强化学习(Reinforcement Learning,简称RM)是一种先进的机器学习方法,其主要目标是通过不断与环境的交互来优化模型的性能。相较于传统的模型训练方式,RM引入了一种全新的思路:评估生成内容的质量,而非指导模型如何改进。这种策略赋予模型更大的探索空间,从而使其具备更强的泛化能力。以下是实施这一策略的具体步骤:
首先,模型根据问题生成多个答案。人工对给定的答案进行排序和打分。机器通过人工打分的数据训练奖励模型,可以预测用户更喜欢哪个模型输出。
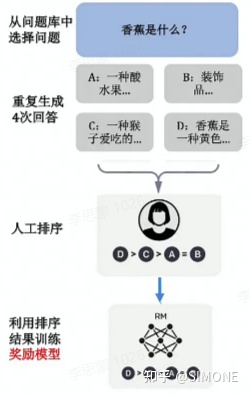
RM工作流
一个更通俗的例子,讲解SFT和RM的工作方式和区别:
SFT用「人工标注」的问题回答数据,并用监督性学习技术训练的自动回答问题的模型。RM用「人工打分」的问题回答数据,并用强化学习技术训练的自动给回答打分的模型,SFT是通过「人工标注」解决答案「有没有」的问题,RM则通过「人工打分」来解决答案「好不好」的问题。
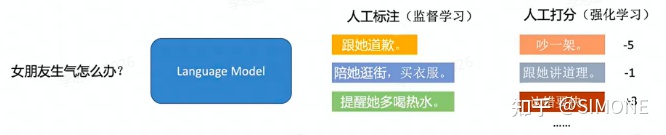
SFT和RM的工作方式和区别
3.PPO
该阶段将前面训练好的SFT和RM两个模型结合起来,利用PPO(Proximal Policy Optimization)算法微调SFT训练出来的生成模型,再把生成出来的答案喂给RM打分模型,基于RM的loss持续迭代生成模型。具体步骤如下:
由第一步fine-tune后的SFT模型来初始化PPO策略模型,由第二部生成的RM模型初始化价值函数。从PPO数据集中随机采样一个prompt,并通过第一步的PPO策略模型生成输出结果answer。对prompt和answer,带入RM模型计算奖励值reward。利用reward来更新PPO策略模型参数。重复2~4步,直至PPO策略模型收敛。
强化学习和预训练模型是最近两年最为火热的AI研究方向,之前不少科研工作者说强化学习并不是非常适合应用到预训练模型中,因为很难通过模型的输出内容建立奖励机制。而InstructGPT/ChatGPT反直觉的做到了这点,它通过结合人工标注,将强化学习引入到预训练语言模型中是这个算法最大的创新点。
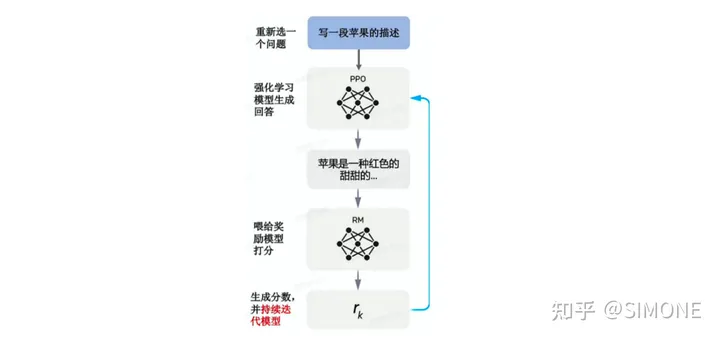
PPO工作流
参考文献
https://arxiv.org/pdf/2203.02155.pdf
https://zhuanlan.zhihu.com/p/590311003

AI时代,拥有个人微信机器人AI助手!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
搜索微信号aigc666aigc999或上边扫码,即可拥有个人AI助手!

