文章主题:ChatGPT, GPT模型, 语言理解, 语言生成
ChatGPT最近太火爆了,
有人说它能写文案、设计广告赚钱,
有人说它能写小说、写代码,让作家、程序员都下岗。
有人说它能帮学生写论文,让老师分不清真假,让学校抓狂。
还有人说它能像人类一样和你交流,连情感问题都能帮你分析的头头是道。
甚至有人说它将代替搜索引擎,引领技术革命,人工智能的奇点已经到来。
那它到底有没有传说的这么神乎其技?ChatGPT到底是个啥?今天我们就来深度剖析一下。

ChatGPT 是由 OpenAI 开发的一种语言模型,该模型基于 Transformer 架构,属于深度神经网络类别,主要用于解答人工智能相关的问题。经过大量文本数据的训练,ChatGPT 在语言理解和生成方面表现出了卓越的能力。用户只需输入文本信息,便可向其咨询各类问题,模型将会以最明确、最精确的回答来回应。
这段描述由ChatGPT生成的内容,尽管没有展现出极高的文学素养,但整体上仍然具备一定的可读性,至少在语法和句子流畅度方面表现良好。
ChatGPT其实不是个新东西,顾名思义,它是由GPT模型演化而来的,而GPT模型则是由transformer的decoder部分演化出来的。transformer我们之前多次介绍过,它产生于2017年的一篇论文

生成式模型是一种人工智能技术,其核心在于通过给定问题和上下文,自动生成相应的回答,而非简单地从数据库中查找和摘抄相关内容。具体而言,生成式模型会根据问题及其周边信息,生成第一个词语,随后在已生成的词语基础上继续生成下一个词语,由此循环反复,直至生成完整的句子。这种模型的优势在于其能够真正理解并处理自然语言的复杂性和多样性,从而实现更为准确、流畅的自然语言生成。
为了让模型达到这样的功能,一般会使用了海量的数据来训练它,使它具备“语感”,多大的数据呢?
GPT-3的训练过程依赖于海量的数据,约为45TB,这一数字大约是维基百科所有数据量的100倍。要处理如此庞大的数据集,模型本身需要具备超强的能力。GPT-3模型的参数量高达1700亿,将其与人类大脑进行对比,人类大脑拥有约100亿个神经元,相当于17名成年人的大脑总体积。尽管这样的数值看似庞大,但实际上,许多人认为自己的大脑并未被充分开发。
ChatGPT 作为 GPT-3 的基础上发展而来,自然具备了其卓越的信息整合和再生产能力。无论是撰写文案还是创作小说,都轻而易举。然而,ChatGPT 并未满足于此,它在算法上进行了多项优化和改进。其中,最重要的就是采用基于人工反馈的强化学习训练方式。尽管听起来十分复杂,但我将其简化为三个步骤,使其变得易于理解。
首先,我们需要理解这一步骤的目的。这个步骤是为了让 GPT 模型能够分辨出哪些句子是优秀的,哪些句子需要改进。然而,手动标注的过程既耗时又低效。
在第二个阶段,标注师会转移注意力去培养一名得力的助手——评分模型。这个评分模型将负责为GPT模型所生成的各类句子进行评分。对于那些语言通顺、表达流畅、富有美感的句子,我们会给予较高的评分;而对于那些语义模糊、表达不畅,甚至带有侮辱性倾向的句子,我们将给出较低的评分。
在进入第三步之前,我们需要拥有一个名为“打分模型”的辅助工具。接下来,我们将利用该模型对GPT模型的输出结果进行大规模的评分和训练。

经过这三步的训练,我们就看到最终颇具智能的产品-ChatGPT了。
了解完它的原理后,再分析它能干什么、不能干什么就更简单清楚了。
作为一个人工智能助手,我必须指出,ChatGPT生成的所有内容,都源于其大量的训练数据,这意味着它对信息进行了整合和再创作。因此,我们无法确保这些信息的准确性,也不能排除出现信息混淆的可能性。简而言之,如果某个关联词在其训练样本中出现的频率足够高,那么ChatGPT可能会错误地将其视为正确的答案。
比如:
当我输入
太阳从东边升起,乌云满天,天气如何?
它的回答是:
如果太阳从东边升起,而天空满是乌云,那么天气可能很阴沉,可能下雨。请注意,本回答仅基于您给出的信息,在没有其他信息的情况下,可能不准确。如果需要更准确的天气预报,请查询当地的气象数据。
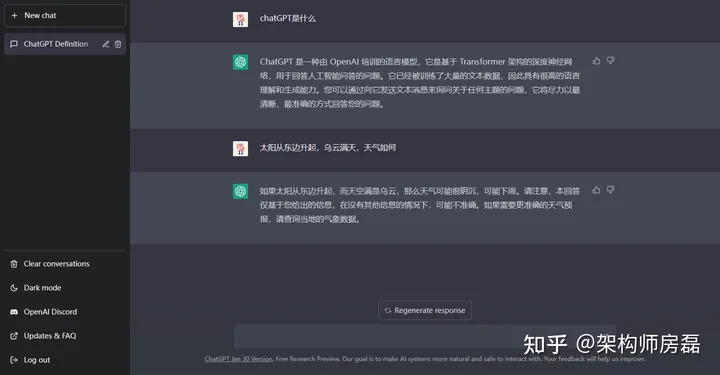
这是因为乌云、天气经常会和阴天下雨一起出现,它并未发现我前半句太阳从东边升起的反常识。
再比如:
太阳围着地球绕一圈是多长时间?
它的回答是:
太阳围着地球绕一圈的时间称为地球公转周期。它通常被称为一年,并且持续大约 365.24 天。
需要注意的是,地球公转周期并不是一个固定的数字,它是受到多种因素影响的,因此可能有微小的变化。为了方便计算,人们通常使用平均数 365.25 天来计算地球公转周期。
也是类似的问题,因为太阳、地球、公转时间、一年这些词经常一起出现,它很自然的就把一年作为这个问题的答案,但却忽略到底谁围着谁转的逻辑关系。
其次,模型训练是个阶段性的工作,它的训练是在2021年完成的,所以它并没有了解最新的数据,你问他22、23年发生的事,它就无法回答了。这点和搜索引擎还是有很大不同。
最后,它是对信息的整合加工,很难完成复杂的、需要假设的如逻辑推理这样的工作。
比如你问它
1元钱一瓶汽水,喝完后两个空瓶换一瓶汽水,问:你有4元钱,最多可以喝到几瓶汽水?

它就有点懵了,很难完成连续的空瓶换水推理,像最后那种借一个空瓶喝完再还的操作假设更不可能完成。
最后,我们总结一下到底该给ChatGPT怎么定位。ChatGPT是GPT模型系列发展到今天的一个产物,虽然它在技术上并没有完成什么创新,但模型的规模达到了空前的巨大,给用户的体验也是非常不错,作为产品是非常成功的。从技术上讲,人工智能奇点还谈不上,但这或许也给我们一点启示,也许真正的智能并不需要什么高深的算法,而只要把数据规模不断扩大,大到可以涵盖我们人类所有的知识就可以接近了呢?
这个结论如何我们慢慢看,但以后NLP大模型必将大行其道,而且有两个趋势可以预见。一是ChatGPT主要由英语语料完成训练,中文支持效果一般。国内厂商必将跟进,中文版的ChatGPT应该不远了。二是如果ChatGPT想从搜索引擎处分一杯羹,那时效性就是必须解决的硬伤,在线训练或许是个方案。
以上就是关于ChatGPT的全部,欢迎关注我的微信公众号”架构师房磊”。

AI时代,拥有个人微信机器人AI助手!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
搜索微信号aigc666aigc999或上边扫码,即可拥有个人AI助手!

