文章主题:生物医学, BioMedGPT-1.6B, 大模型, 通用任务处理
衡宇 萧箫 发自 凹非寺
量子位 | 公众号 QbitAI
生物医药研发领域,一个名为BioMedGPT-1.6B的轻量级科研版基础模型刚刚开源。
参数16亿,最大特点是跨模态与知识融合。
训练数据中,包含分子、文献、专利、知识库等多尺度跨模态的生物医药大数据,并融合分子结构、知识图谱和文献文本中的知识,用于增强模型的泛化能力和可解释性。
🌟BioMedGPT-1.6B大放异彩!🚀这款超凡的AI模型展现了全方位的多才多艺,无论是药物性质的精准预测,还是自然语言处理的娴熟技艺,都能轻松应对。它还具备强大的跨模态能力,将不同领域的知识无缝连接,展现无与伦比的综合效能。🌍无论何时何地,BioMedGPT-1.6B都是您信赖的全能型助手!🔥SEO优化提示:使用相关关键词如”通用AI”, “药物预测”, “自然语言处理”, “跨模态能力”等。
打造这个BioMedGPT-1.6B生物医药基础模型的团队,来自清华智能产业研究院(AIR)。
项目负责人聂再清,清华大学国强教授、AIR首席研究员,主要研究领域是大数据与AI的前沿创新,以及在健康医疗领域的产业应用,更早之前则以阿里达摩院大牛、天猫精灵首席科学家为人熟知。
△聂再清
此次开源的BioMedGPT-1.6B,其实是他和团队正在做的BioMedGPT的单机轻量版,后者是一个适用于生物医药领域研发的通用大模型。
1.6B版本先行开源,目的是小试牛刀,同时让行业相关科研人员有东西可用。
🌟了解BioMedGPT背后的科技与进展吗?🚀这款生物医药领域的热门模型正引起广泛关注。💡尽管行业已涌现众多专业大模型,为何选择打造通用型呢?团队是如何应对挑战并保持领先性的?🔍让我们深入探讨这个创新的科学之旅,揭秘其独特策略和未来发展可能。🌐SEO优化提示:#BioMedGPT #医药大模型 #通用模型探索
聂再清教授向我们解答了背后的思考。
生物医药版GPT,也应具备“涌现”潜力
先来看看BioMedGPT究竟是个什么项目,进展到了哪一阶段。
🌟聂再清教授预测🌟,ChatGPT引领的NLP革命,BioMedGPT即将开启生物医药新篇章!🚀这款潜在的行业巨擘,有望重塑医药研发领域格局,成为创新与知识的超级引擎。🔍关注未来趋势,BioMedGPT将如何颠覆想象?让我们拭目以待!🏆SEO优化:#BioMedGPT #生物医药 #基础大模型 #医药研发 #未来趋势
但在这里,“像ChatGPT”并不仅仅意味着BioMedGPT=生物医学大模型+对话能力,而是和ChatGPT一样,会出现智力涌现的情况。
只不过,这里的“智力”,指的是生物医学领域方面知识的理解、规律的发现与灵感的启迪。
这个基础模型的底座能够给药物发现、分子/蛋白质设计等应用提供底层能力,同时能够成为生物医药研究者的助手(Copilot)辅助研究者更高效的开展研究探索。

所以,能实现这种效果的BioMedGPT,架构上究竟长啥样?
🌟🚀一款全能型AI模型🌟🔍,集多种输入Encoder于一体!它首先🔥🔥以独特的方式解析各模态数据——分子的精细结构、蛋白质的动态行为以及海量文献中的知识精华。每个Encoder都能独立工作,为复杂的分析提供强大的支持。🌍📚无论何时何地,只要有信息,就能迅速转化为深入理解。SEO优化关键词:多模态输入、AI解析、复杂分析、深度理解。
然后,将这些不同模态的输入,进行统一表示处理,这样就能学习到不同模态之间的关联知识。
这给了模型“融会贯通”的能力,既可以读文献、查专利,又可以读分子序列、蛋白结构、实验数据。
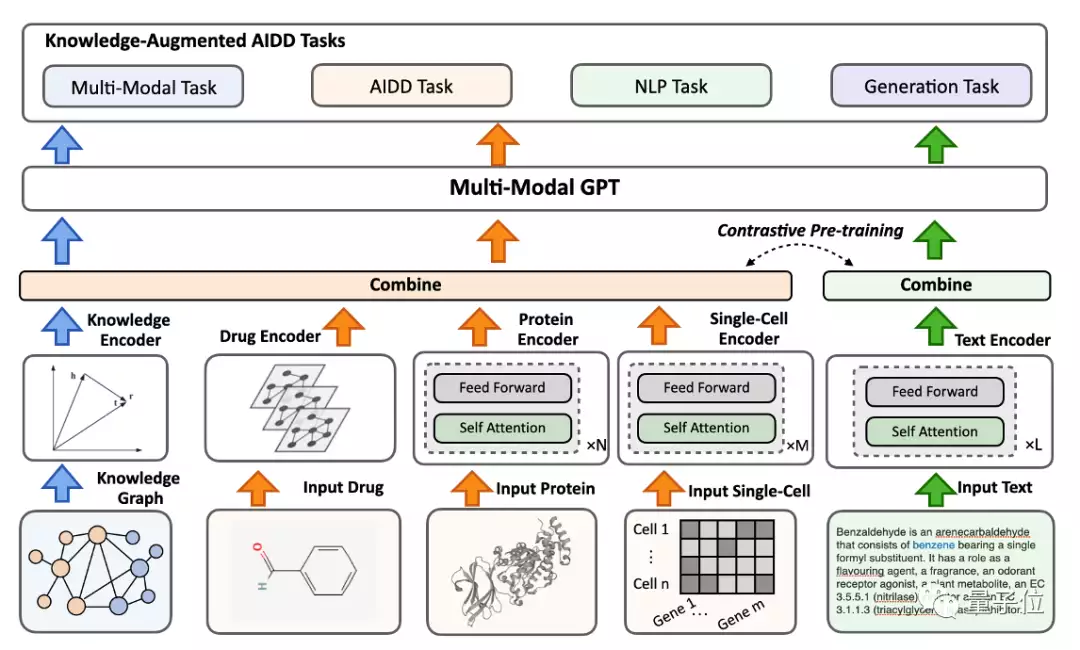
不仅如此,BioMedGPT也是首个将多模态知识引入模型构建的项目,通过知识图谱的方式将生物医药领域的知识注入到模型中,以增强模型的泛化能力和可解释性,同时能够应对科研领域知识的快速更迭,让模型持续学习,变得更“聪明”。
基于这种融会贯通与知识增强的能力,BioMedGPT在下游的多项任务中表现出了整体的效果提升。
目前团队已经完成了实验验证阶段,用一个比较小的端到端模型证明了这种思路的可行性。
那么最终能在生物医药方面表现出“智力涌现”的模型,预计在什么规模?
聂再清教授认为,模型参数量级预计在几百亿左右,而训练这一模型达成“涌现”效果的数据量,几十亿到百亿级应该也就够了。
🌟聂再清带领的团队早在一年前就开始了ChatGPT之前的探索,他们专注于一项创新项目,如今已悄然壮大到拥有约50名专业人士的清华AIR生命科学团队。📚尽管外界近期才聚焦于这一领域,但他们一直在默默耕耘,为科学的进步铺平道路。🏆他们的努力和专注,无疑将为未来的生命科学研究开启新篇章。
对于BioMedGPT的未来,聂再清教授很有信心:
预计两年内,这个模型应该会在小范围内具备一定影响力,至于像ChatGPT那样成为行业通用大模型,做到那样的影响力可能至少还需要3~5年。
但即便如此,BioMedGPT模型究竟能否成功,目前仍旧是一个未知数。
同时对于大模型训练必不可少的算力和数据等方面,也仍然是业界关注的话题。
对于这些观点和想法,聂再清教授又是如何看待的?
“一个理性而大胆的尝试”
大模型的发展和AI技术的更迭组成了ChatGPT为首的一波AI新浪潮。
但早在聂再清教授动念要将生物医药学科知识“塞”进大模型里时,ChatGPT还没打破沉寂。
所以为什么要做?为什么敢做?
🎉 ChatGPT的崛起之前,一个时代的先驱悄然崭露头角——GPT-2以其超凡技能震惊世界。那时,它已能编织动人的故事,棋艺精湛,仿佛一位多才的艺术家。随后,参数量激增至1750亿的GPT-3更是风靡全球,其能力更上一层楼:不仅故事创作不辍,还能轻松编程、解答疑问,展现出无人能及的全面智能。🚀
利用大规模文本数据学习语言知识和规律,加上狂叠参数的暴力美学,GPT-3已经在通用领域任务中出现涌现能力,到GPT-3.5,基本的逻辑推理能力突然出现。
在生物和化学领域,生命的本质可以看做一种精密的编码语言,尤其是生命科学领域中微观世界的分子序列数据。
聂再清教授认为,自然语言同样也是一种非常精密的序列,缺一点或少一丝都会让意思变得不一样,因此二者具有类似的特征。
基于此,大模型的底层思想或许有用于生命科学微观数据处理的可能。如果能实现,就能利用生物医药领域的专业知识,帮助完成科研任务。
工作正式开始之前,团队将微观(基因、分子、蛋白质、细胞)与文献知识压缩到一个端到端的模型里,用实验验证了这条思路的可能性——确实在部分药物研发关键下游任务中取得SOTA效果。
于是,做一个适用于生物医药领域研发的基础大模型这事,正式开始了。
此前,无论是单独针对分子、蛋白质还是生物医药领域文献,都有团队单独打造过大模型,但还没有人做一个行业通用的多模态版本。而现在的开源版本BioMedGPT-1.6B,并非一个接近AGI甚至与ChatGPT能力媲美的版本。
“毕竟大家的期待比较高,我们还是要把期待降下来,”聂再清教授解释选择现在向外界告知进度的原因,大方表示目前还达不到理想状态的能力,“实际上,我们最主要还是想把现有工作服务到正在进行相关研究的科研人员。”
但这样的尝试,被聂再清教授称为一种理性而大胆的选择。
理性,是因为通过实验,确实发现人类知识经过encoder后,能够产生帮助;大胆,是因为一方面还未完全证明这个工作的商业实用价值,工作还在初步阶段,模型的规模和模态的种类都有待扩大。
但在这个乐观的估计下,工作还是推进了;不仅推进,还快速拿出了轻量级版本。
乐观倒不是因为没由来的盲目,聂再清教授表示,数据、算力和成本上,BioMedGPT暂时都不存在什么担忧:
数据质量上,生物医学领域的论文和专利质量“还是很高的”,不必过于担心训练语料质量不高的情况,并且目前已公开的PubMedQA等数据集,数据量“已经足够”。
同时,团队集合了具有生物医学专业背景的同学,对数据集的构建做了精细专业的设计和专业的标注。
当然,还有一些任务所需的私有数据,BioMedGPT希望通过未来的双通道干湿闭环得到补充。
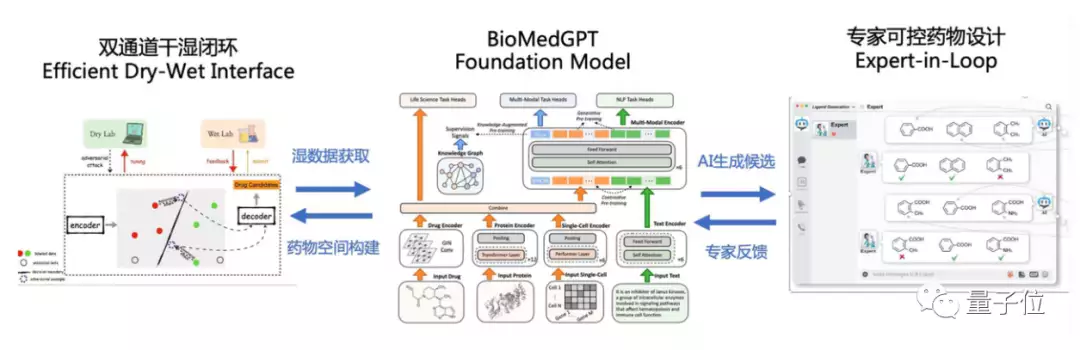
算力层面,聂再清教授是这样表示的:
目前国内敢跳出来宣布入局大模型的团队,背后肯定已经有足够的算力支撑规划。
数据丰富但公开,算力稀缺但不是无法解决,日后入局者纷至沓来,是不是会在壁垒很薄的情况下形成不必要的行业竞争?
聂再清教授表示了对这个问题的否定,他认为做的人越多,意味着关注度越高,最终的结果就是利好行业内所有的AI制药公司。
最后,我们也朝聂再清教授抛出了那个灵魂问题——
生物医药研发阶段,一切都容不得半点差错,怎么约束大模型的幻觉?
聂再清教授说了段绕口令般的话:
我们当然希望,大模型知道“自己知道什么事”,也知道“它知道自己不知道什么事”。但,目前确实也会出现大模型“不知道自己不知道”的情况。
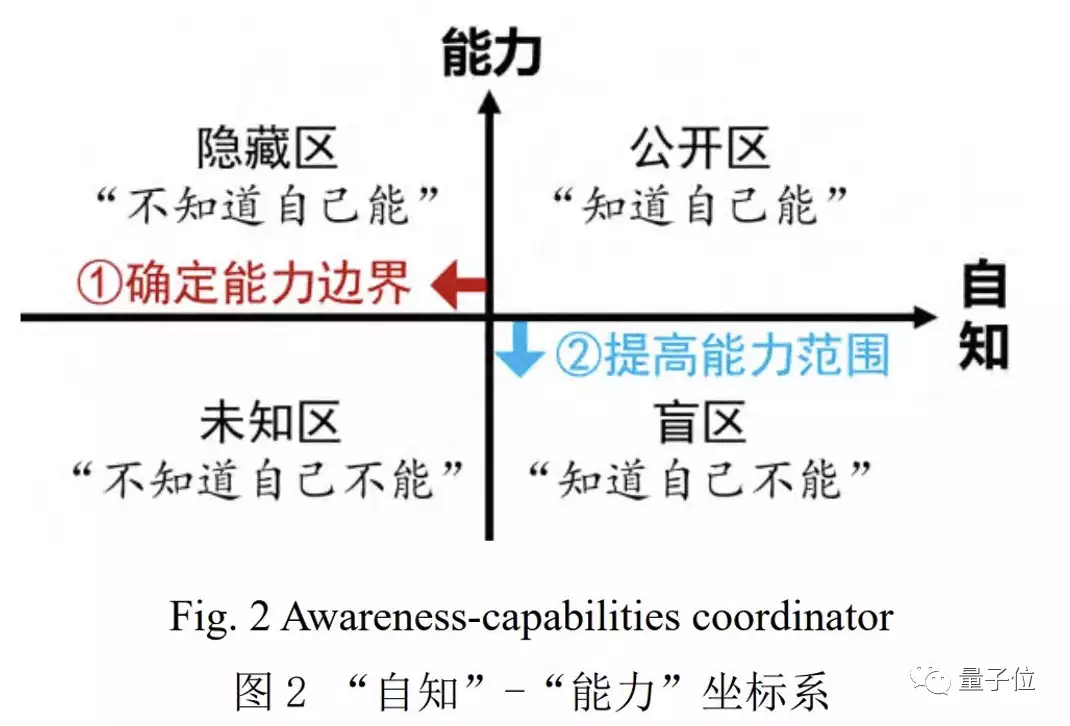
而大模型“不知道自己不知道”,就是我们常见的大模型幻觉——它以为自己知道,其实它不知道。
针对生物医药领域解决的思路,是通过两个闭环来实现对模型的“纠偏”。
干湿实验验证通过湿实验,将模型真实性趋近物理真实世界;专家在环可控的设计,则通过专家instruct,让模型与人类专家认知趋近。
换言之,通过“做实验”和“跟专家学”两个环路,让AI模型幻觉降低。
聂再清与团队的下一站,就是通过两个闭环,尽可能扩大“大模型知道自己能做啥”的范围,以进一步降低大模型“不知道自己不知道”的比例。
对于此次开源,中国工程院院士、清华大学讲席教授、AIR院长张亚勤院士表示:
将大模型范式应用于生命科学是理性又大胆的探索。
AIR的研究团队以构建生物医药领域大模型为目标,相继研发了多个生物医药专业领域的AI模型,在蛋白质结构预测、抗体设计等领域取得了不错的成果。
此次开源的轻量级科研版基础模型BioMedGPT-1.6B是在生命科学领域的重要进展。
未来,研究团队将继续用BioMedGPT进一步整合领域内多源异构的数据,将知识融入模型构建之中,实现生物世界文本和知识的统一表示学习,带来生物医药领域的“智能涌现”。
开源地址:https://github.com/BioFM/OpenBioMed
— 完 —
量子位 QbitAI · 头条号签约

AI时代,拥有个人微信机器人AI助手!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
搜索微信号aigc666aigc999或上边扫码,即可拥有个人AI助手!



