文章主题:ChatGPT, 自然语言处理, 聊天机器人程序, 生物信息
ChatGPT 是一个由 OpenAI 于去年年底推出的聊天机器人程序,它卓越于自然语言处理领域,能够像人类一样理解和回应人类的语言。此外,该程序还能考虑到对话场景的上下文信息,为用户提供更为精准和流畅的交互体验。
GPT 全称是 Generative Pre-trained Transformer, 翻译成中文是生成预训练转换器。ChatGPT并不是一个搜索引擎,而是一个深度神经网络模型。GPT通过对大量无标签的数据的学习产生一个预训练的生成式语言模型,再根据特定任务(人工标记的语料)进行微调。GPT 预训练时需要的数据不是“问题 1 – 答案 1”这样的语句对,而是一句句或一段段完整的话,如”学习生信就看生信宝典”,GPT 会计算每个字、每个词或每个句子后面承接哪个字、词或句子的可能性更大,从而构建出模型,再有人提问时,根据提问者的语句,去模型中提取最可能跟着的文字,给出答案。
以一名文章写作高手的视角,我们可以将这段内容重新组织如下:当我们向ChatGPT提出问题时,例如“如何学习生物信息”,模型会依据其概率模型来预测该问题后面可能跟随的词汇。以“就”为例,模型会计算“就”出现在“如何学习生物信息”后面的可能性,并随机选取一个 follow-up 词,如“看”。随后,模型将继续探寻“看”之后可能出现词汇,直至找到完整的回答或触达终止策略。值得注意的是,每个问题的答案都存在一定的随机性,因此,即使提出相同的问题,也可能获得不同的回答。
ChatGPT 作为一款基于深度学习的自然语言处理模型,其在提升文本生成质量方面已经取得了显著的成果。然而,为了进一步提高性能,ChatGPT 还采用了多种基于反馈模型的增强学习技术。这些技术在 ChatGPT 的训练过程中起到了关键的作用,使得模型能够根据之前的预测结果和实际反馈不断调整自身,从而生成更加准确、流畅和有深度的文章。尽管这些技术的具体细节尚未在 ChatGPT 的论文中得到详细阐述,但相信随着研究的深入,它们将会被逐步公开,让我们期待 ChatGPT 在未来的表现。
这块也是才刚开始接触,有理解不对的,请大家指出。原理先不管,我们后面看看其效果怎样!
ChatGPT 试用
首先需要注册一个账号(好在我有一个比较早之前注册的账号),网上也有很多教程教怎么注册账号的。
在访问该平台时,首先呈现的是一块干净整洁的画面,用户可以在此输入相关文字并启动对话。随后,系统会提出首个问题:“如何学习生物信息?”对此,系统给出的回答非常详细且有条理,类似于大多数公众号文章中的建议,看起来似乎很有帮助。然而,实际上这些建议的深度并不大,由于问题的范围过于宽泛,因此回答也显得较为笼统。

再问个问题,“请帮我写一段 python 代码从 FASTA 文件提取特定基因序列”。
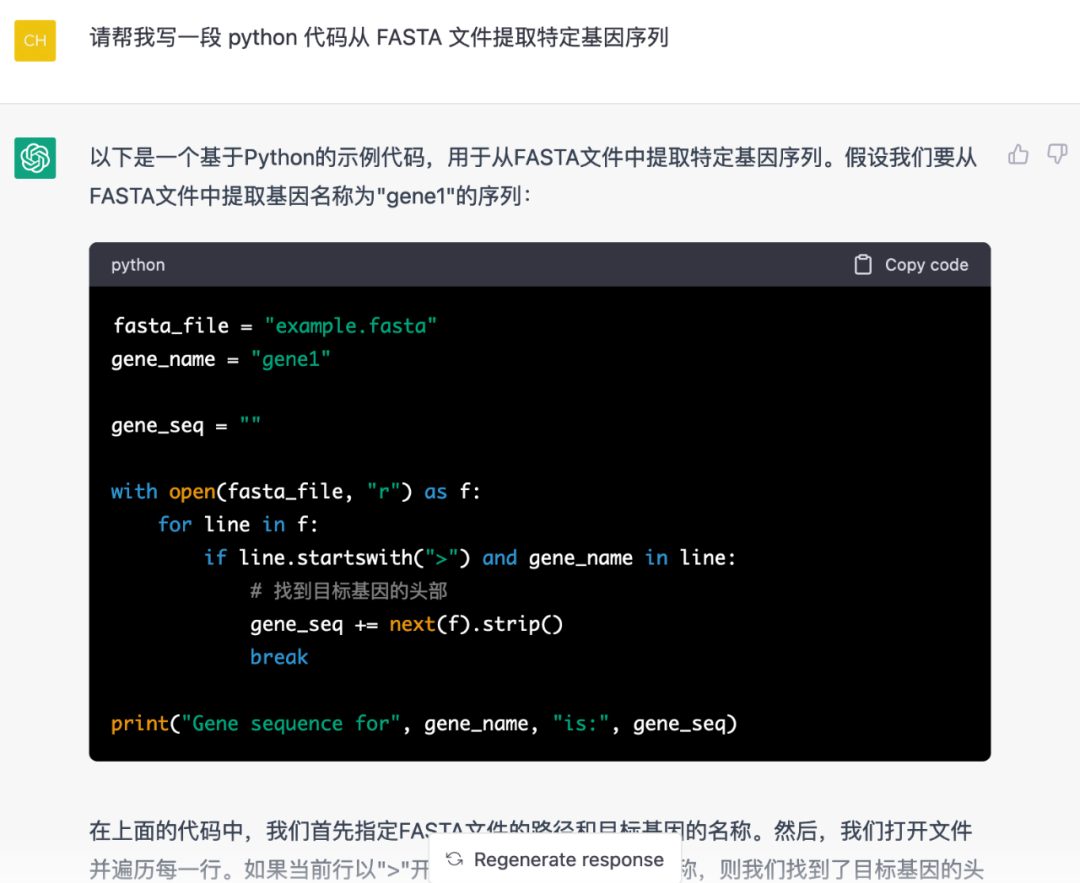
这个代码看上去是很不错的,三步走:
设置2 个输入变量,fasta 文件和基因名字;
读取文件,根据>判断 FATSA的名字行和判断基因名字是否存在; 拿到序列,存起来;
输出序列。
这篇文章的结构非常出色,并且作者还附加了一些代码解释、代码的局限性分析以及改进策略。对于初学者来说,能够独立完成这样的任务,无疑表明他们的编程能力已经达到了一定的水平。

当然这个程序还存在至少 2 个问题:
只能处理单行序列的 FASTA 文件,因为它只取了”>”开头的行后面的第一行。
如果是多行 FASTA 序列,取出的结果是不完整的;
在基因名称的比对过程中,我们会采用匹配模型的方式来判断。举例来说,如果我们输入的是Sox1这个关键词,系统会自动地在数据库中寻找与Sox1相匹配的基因名称。如果在数据库中找到了先于Sox1出现的Sox11,那么匹配模型就会认为输入的Sox1与Sox11是相同的。
拿到代码了,怎么调用呢?我们继续追问下去。这个回答还是很详细的,
体现出了上下文思想,ChatGPT 知道要运行的是上面回答的代码;
告诉了我们如何把代码存成文件,然后在终端用命令行调用;
还贴心的提示了代码什么地方要修改。
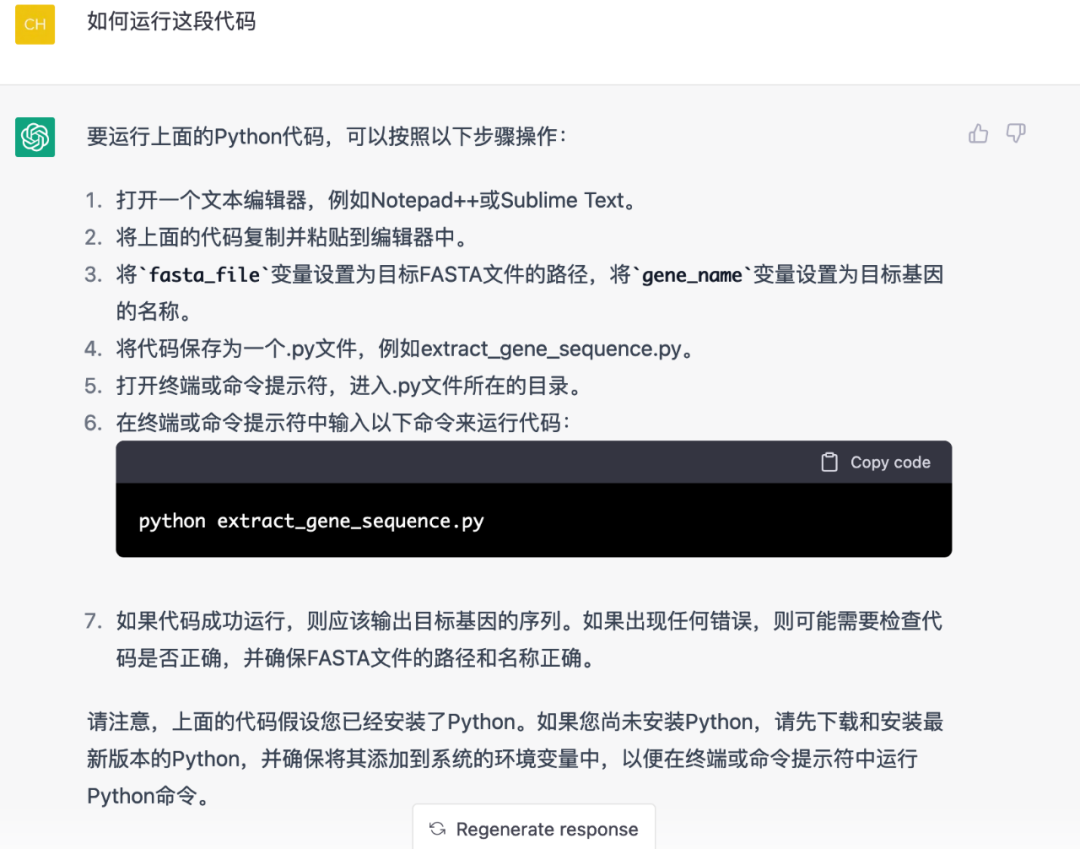
如果有不懂的还可以继续追问,下面的视频展示了与ChatGPT交流的实时过程。
后面有新的测试,再来分享。
往期精品(点击图片直达文字对应教程)




























后台回复“生信宝典福利第一波”或点击阅读原文获取教程合集




AI时代,拥有个人微信机器人AI助手!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
搜索微信号aigc666aigc999或上边扫码,即可拥有个人AI助手!



