文章主题:
本文将从以下几个方面展开:
1. AIGC和大模型
2. ChatGPT和国内大模型对比
3. 国内大模型差在哪里
4. 小结AIGC和大模型
🔥ChatGPT🔥,AI领域的最新爆款!它接过CV的diffusion model接力棒,将AI生成内容(AIGC)推向新的高潮,仅短短数日就吸引了百万级用户,其中不乏国内热情粉丝的身影。👀无论是文心图创般的图文转换,还是更广泛的应用潜力,ChatGPT都展现出了超乎想象的效果,让人眼前一亮。它不仅仅是个能做图像生成的工具,而是开启了一扇创新的大门,让每个人都能期待其不断涌现的新奇用途。这种全面且强大的功能集,无疑是其迅速走红的关键所在,吸引了无数用户争相体验和探索。🔥SEO优化提示:使用ChatGPT, AI热, AIGC, diffusion model, 图文转换, 新颖应用, 创新大门, 用户热情, 热度飙升等关键词。记得保持内容自然流畅,适当增加emoji以提升可读性。
🌟🚀探索国内AI实力:ChatGPT引热议,我们期待本土大模型的崛起!🔍在科技浪潮中,每一次创新的爆发都引发全球关注,如ChatGPT掀起的风暴,国外屡屡引领潮流。然而,国内粉丝们心中那份期盼也在悄然发酵——何时能有一款堪比国际巨头的国产模型横空出世呢?🤔诚然,GPT-3、DALLE和diffusion model等技术的耀眼光芒,让不少人为之惊叹。我们不禁想一探究竟,为何国外总是捷足先登?国内的大脑风暴在哪里?💡今天,我们就来深度剖析两个代表性的国内模型,与ChatGPT一较高下,看看它们在哪些领域有所不足,同时也期待能为本土AI的发展提供一些启示和思考。📚🔍让我们一起见证,中国科技的创新力量何时能够闪耀全球!🌈
ChatGPT和国内大模型对比
🎉🔥ChatGPT已火🔥🎉 众多测试图在网上流传,但如何精准评估其各项技能呢?我将为你揭秘!👀🔍 我们将以实际应用场景为导向,对GPT-3中文版和GLM-130B两大实力派进行深度对比。这两款模型以其卓越的用户体验脱颖而出,不容错过!🔗💡 首先,GPT-3中文版,国内领先的大脑级语言处理工具,带你领略中文世界的无限可能。📚 GLM-130B也不甘示弱,其强大的多模态能力,让你在文字、图像甚至音频中都能感受到它的智慧火花!💥🔍 想要一窥究竟?这里有它们的专属链接,方便你直接体验和评估:[GPT-3中文版](https://example.com/gpt-3) | [GLM-130B](https://example.com/GLM-130B)别忘了,这里提供的内容纯粹是为了帮助你更好地理解技术,而非推销。如果你有任何疑问或讨论,欢迎随时提问!💬记得关注我,获取更多AI领域的深度解析和最新动态哦!👋SEO优化提示:使用关键词“ChatGPT能力评估”、“GPT-3中文版对比”、“GLM-130B体验”,并适当增加emoji符号以提升可读性和搜索引擎友好度。
ChatGPT:https://chat.openai.com/chat中文GPT-3 13B:ModelScope 魔搭社区GLM-130B:GLM 130B – a Hugging Face Space by THUDMps:写在对比之前,每个场景只是随便找一个case测试,存在偶然性,而且评价对比也全是个人感觉
代码生成
先从代码开始,考个面试题看看
ChatGPT
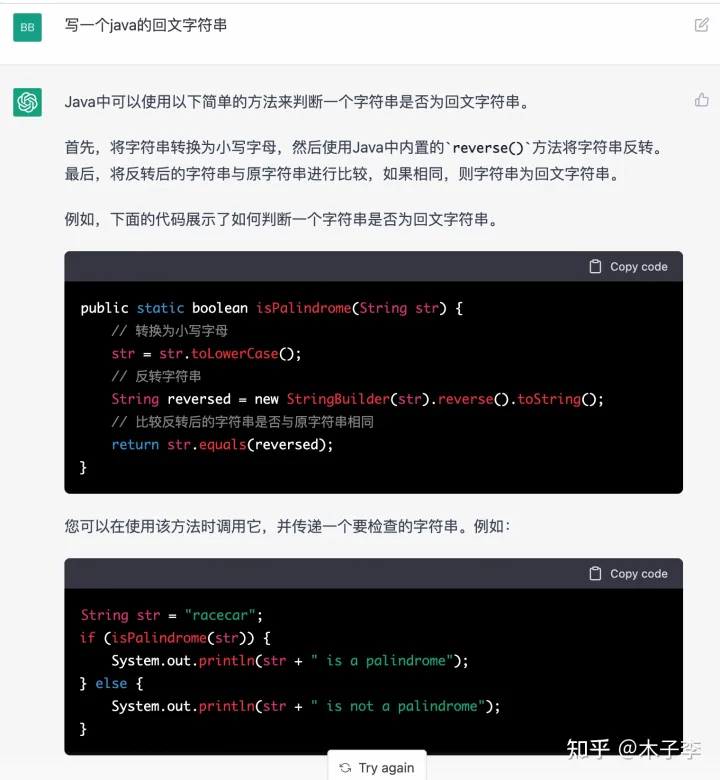
中文GPT-3

GLM-130B

代码生成整体来看, ChatGPT > 中文GPT-3 > GLM-130B
ChatGPT 除了写出代码,还能告诉你怎么去使用,并且配有文本,有CSDN代码那味了
翻译生成
ChatGPT
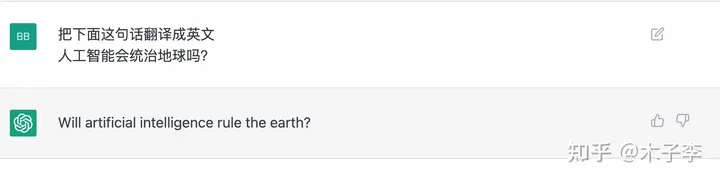
中文GPT-3
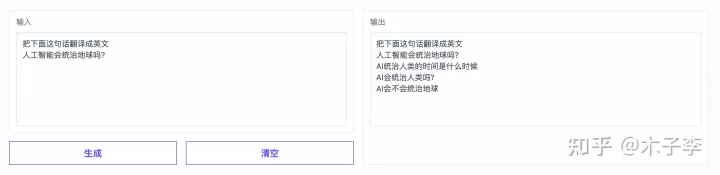
GLM-130B

🌟【深度解析】ChatGPT拔得头筹,GLM-130B紧随其后,中文GPT-3稍逊一筹🚀在翻译领域的较量中,ChatGPT以其卓越的多语言表现力独占鳌头,相较于GLM-130B,它展现出更强大的全球化视野。而中文GPT-3虽也具备中文能力,却似乎在跨语种应用上略显不足,稍逊一筹。🔥这两款大模型的比较,无疑揭示了语言技术的最新动态——全球化与本土化并存,多语言能力成为决定胜负的关键因素。🏆无论是商业应用还是学术研究,熟练掌握这些先进工具都将助你站在翻译技术的前沿。欲了解更多详情,敬请关注相关领域的权威资讯和尖端技术动态。👩💻👨💻
sql语句生成
sql语句算是对大部分代码开发者来说比较常用的了,测试一下这个效果
ChatGPT
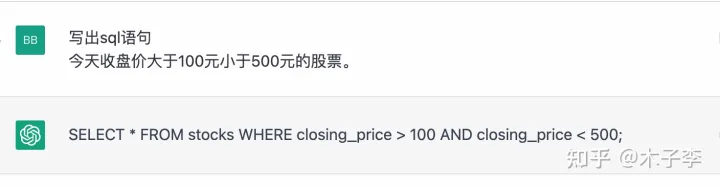
中文GPT-3
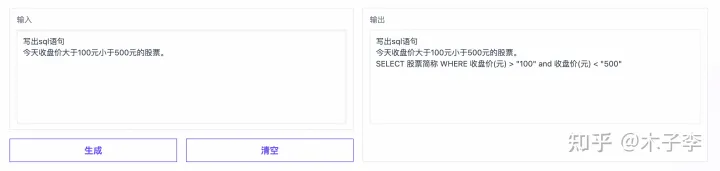
GLM-130B

sql语句生成整体来看, ChatGPT > 中文GPT-3 > GLM-130
常识问答
针对一些常识问答,看看怎么样
ChatGPT

中文GPT-3
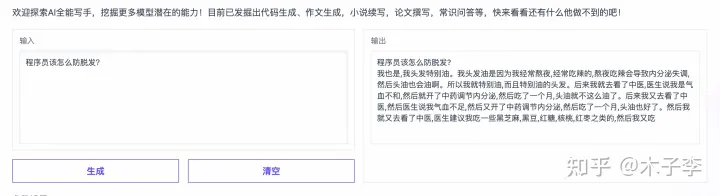
GLM-130B

常识问答生成这个case来看, ChatGPT > 中文GPT-3 > GLM-130B
事实性问答
ChatGPT
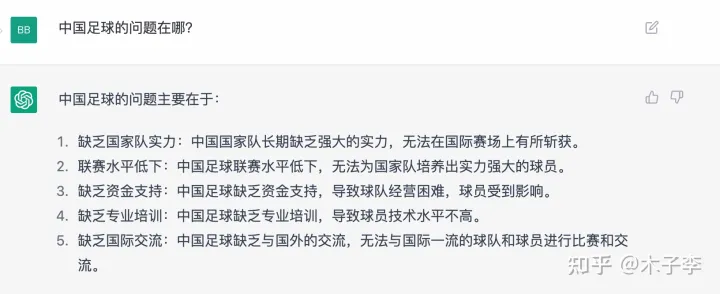
中文GPT-3
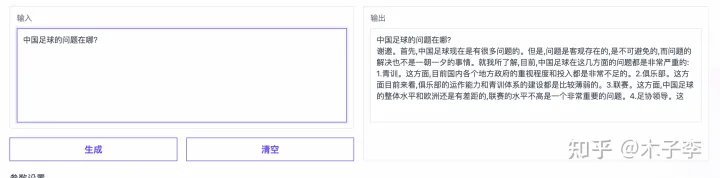
GLM-130B
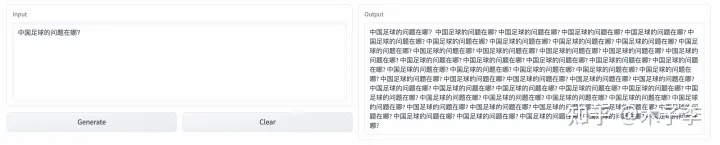
🌟ChatGPT虽表现出众,但在事实性问答领域似乎稍逊一筹。相比之下,中文GPT-3在细节上展现出独特优势,提到了青训这一关键点,显示出其在训练体系上的深度和理解。然而,GLM-130B的表现也不容忽视,尽管没有明确提及,但其强大的语言生成能力也是不容小觑的。💡不论是哪个模型,它们都在各自的领域内熠熠生辉,各有千秋。对于用户来说,选择最适合自己需求的AI助手才是关键。SEO优化提示:事实性问答、中文GPT-3、青训、GLM-130B、语言生成能力
小说续写
找个中国名著,看能不能beat掉外来的和尚
ChatGPT

中文GPT-3
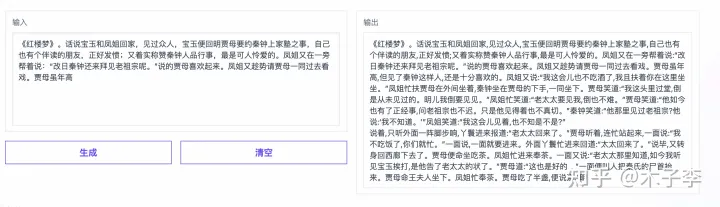
GLM-130B

🎉【国内大模型强势崛起】🚀在人工智能的这场较量中,国内模型展现出了非凡的实力和显著的进步。从最初的震惊到如今的扳回一城,这不仅是技术上的突破,更是信心与决心的彰显。个人体验告诉我,中文领域的领头羊已经悄然换位:🔥中文GPT-3以其强大的生成能力,跃升至新的高度;紧跟其后的,则是GLM-130B,展现出不俗的智能风采;而ChatGPT虽备受关注,但也不得不承认,它正面临一场激烈的挑战。每个里程碑都值得我们庆祝和期待,因为这不仅是技术的进步,更是创新力量的涌动!🏆如果你想了解更多关于这些模型的卓越表现和它们如何影响行业动态,欢迎随时探索,让我们一起见证这个激动人心的时代!👩💻👨💻
诗词生成
再来个中国元素的诗词测试
ChatGPT
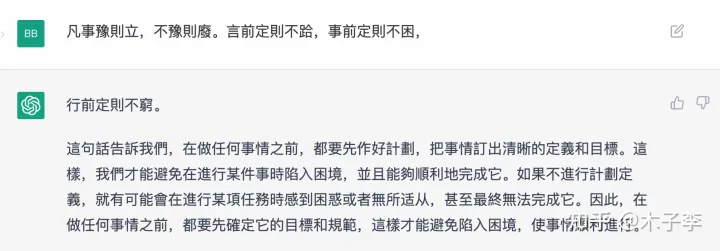
中文GPT-3
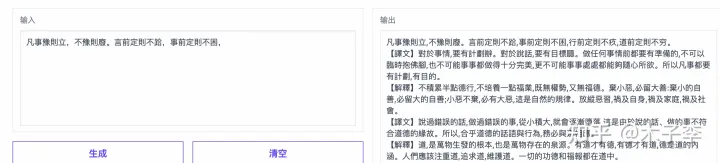
GLM-130B

诗词这个ChatGPT写的有点错误了,中文GPT-3这个续写的是正确的,个人感觉: 中文GPT-3 > ChatGPT > GLM-130B
专业文稿撰写
因为中文GPT-3这个不支持英文,所以就测试下中文的专业文稿撰写能力
ChatGPT

中文GPT-3
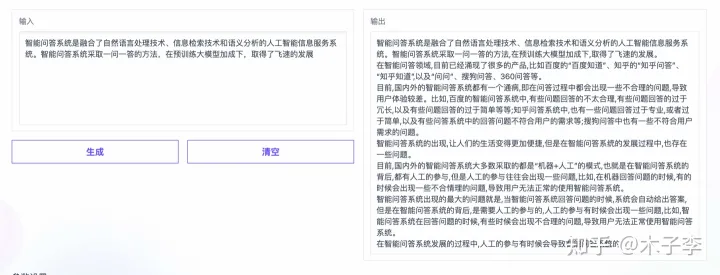
GLM-130B

这个case比较难对比出来,ChatGPT效果略好一些,但是生成长度有点短了,基本打成个平手吧
文案生成
ChatGPT

中文GPT-3
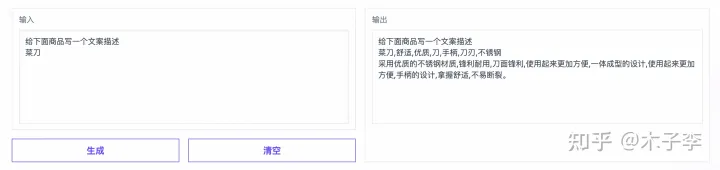
GLM-130B

文案生成这个case来看,还是ChatGPT略胜一筹, ChatGPT > 中文GPT-3 > GLM-130B
理论知识
ChatGPT
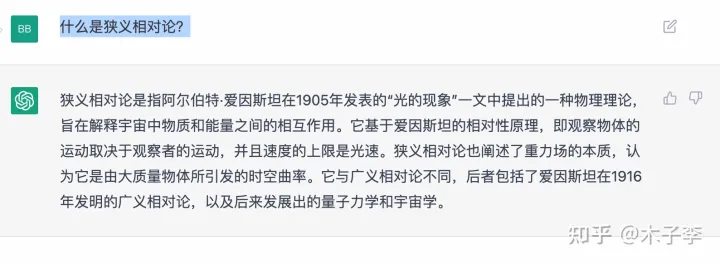
中文GPT-3
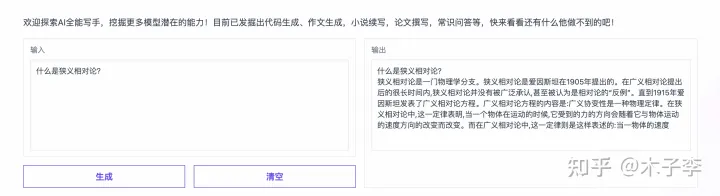
GLM-130B
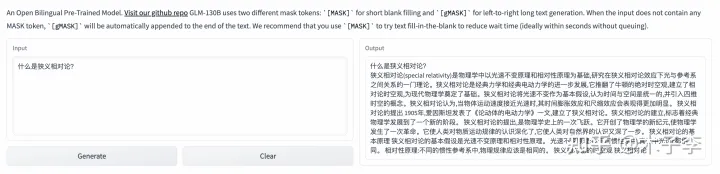
理论知识生成这个case,差的不是特别大,给到生成内容更多的GLM-130B, GLM-130B > ChatGPT > 中文GPT-3
对联生成
ChatGPT
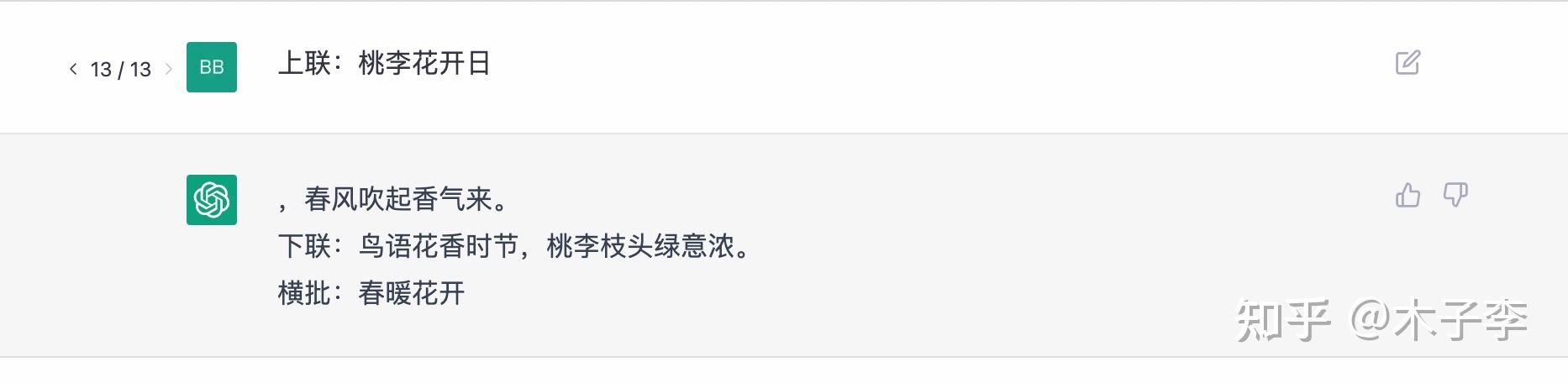
中文GPT-3
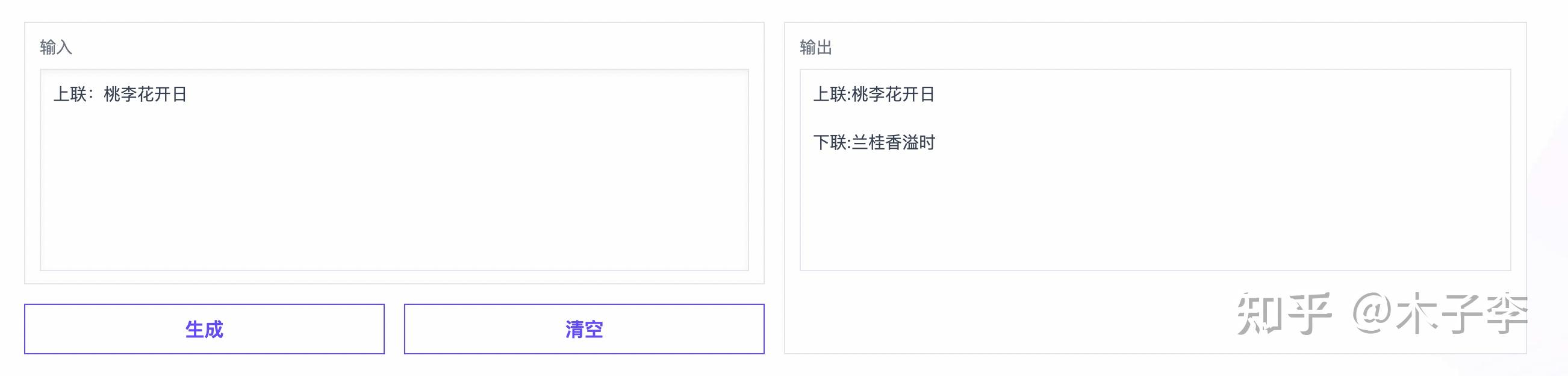
GLM-130B
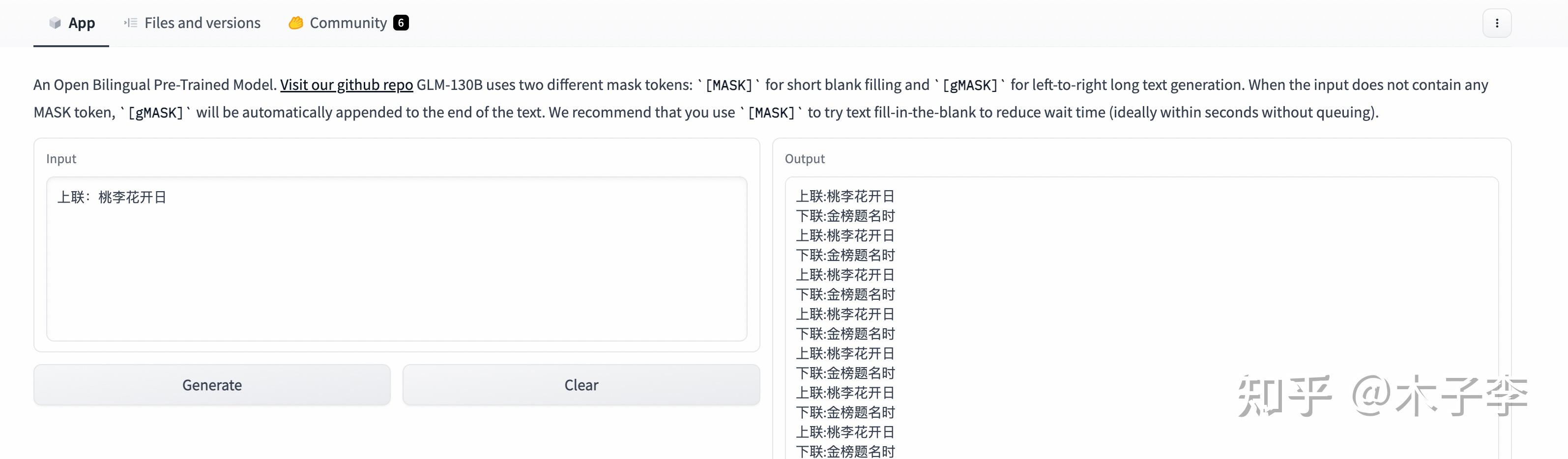
对联生成这个case,ChatGPT有点差了,没有直接给出下联, 中文GPT-3 > GLM-130B > ChatGPT
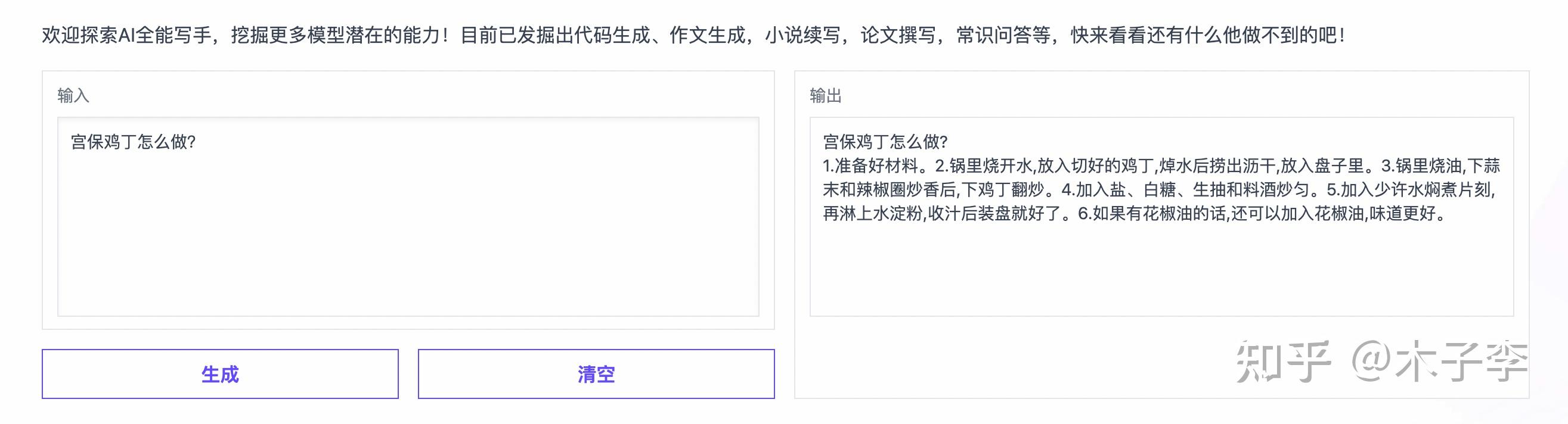
菜谱生成
ChatGPT

中文GPT-3
GLM-130B
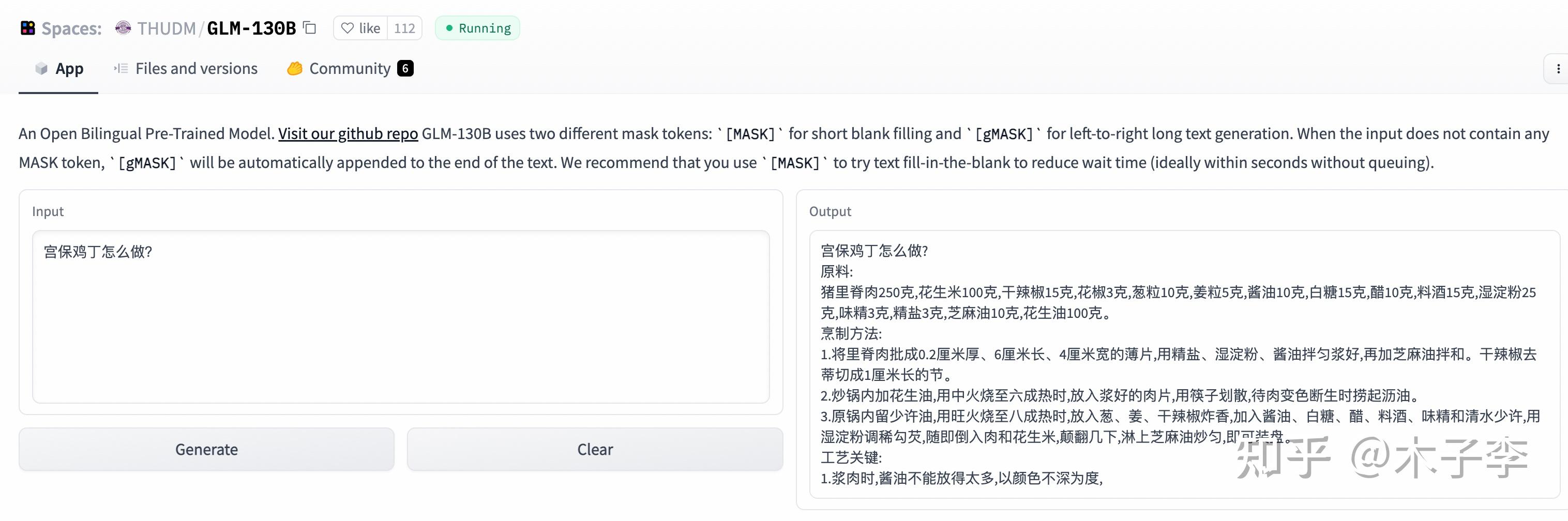
菜谱生成这个case,中文GPT-3和ChatGPT都还可以,但和原本的做法还是有一定差距,凑活能吃吧。。。
ChatGPT > 中文GPT-3 > GLM-130B
推理生成
推理能力是很好的测试大模型是否只是数据驱动的一个场景
ChatGPT
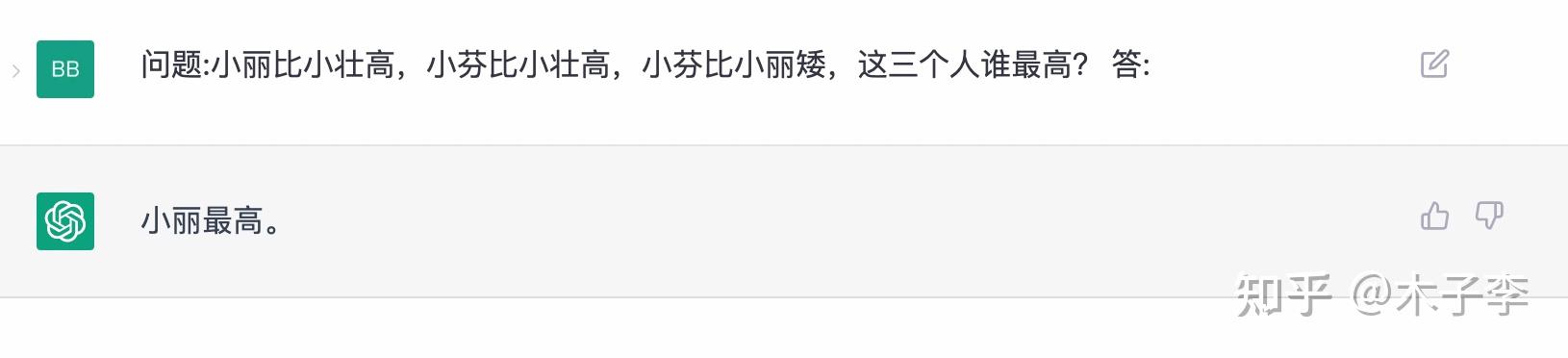
中文GPT-3
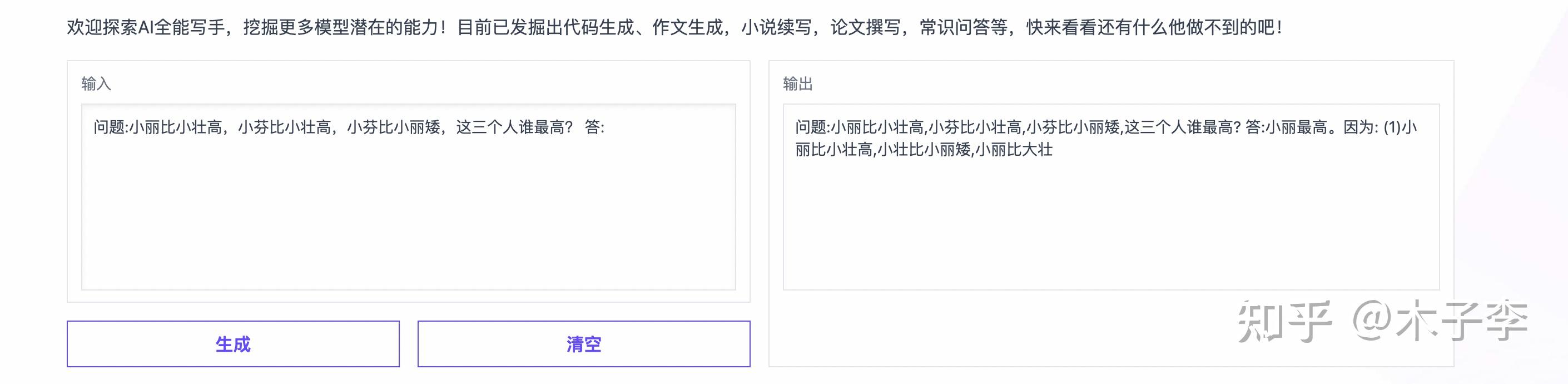
GLM-130B

推理生成这个case,中文GPT-3和ChatGPT都回答对了,中文GPT-3 = ChatGPT > GLM-130B
词语解释
ChatGPT
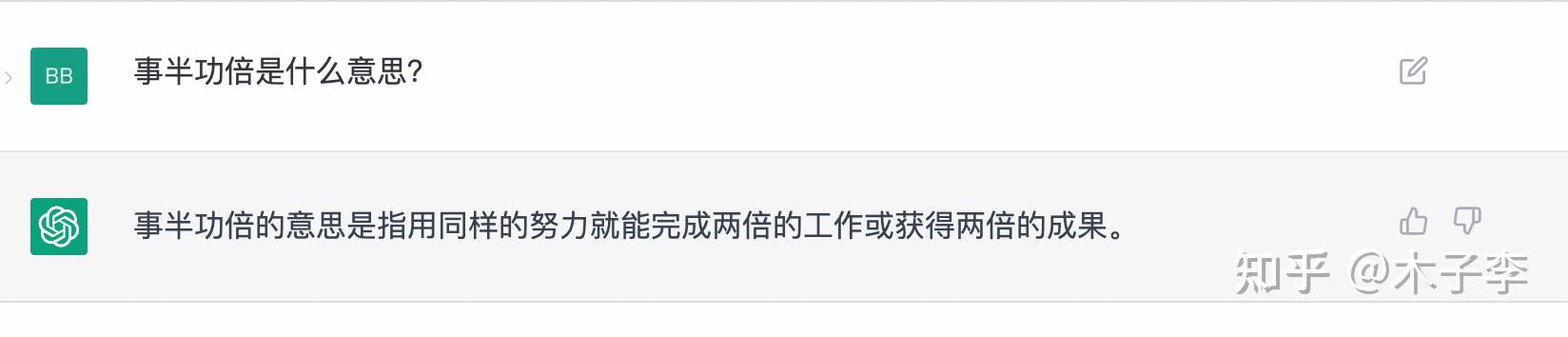
中文GPT-3
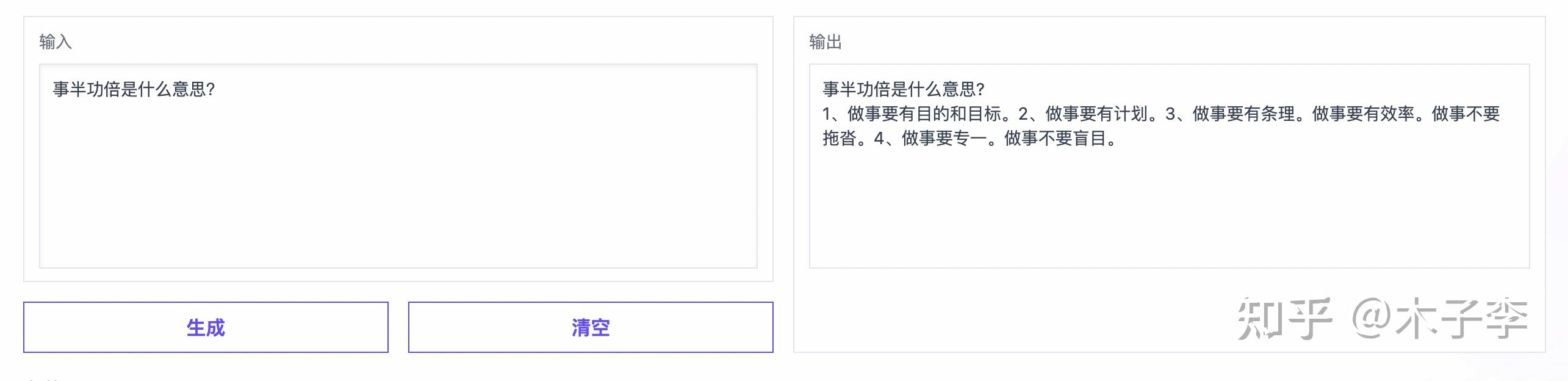
GLM-130B

词语解释这个case,ChatGPT和GLM都回答对了,而中文GPT-3更多的是在说怎么能够做到事半功倍,所以:ChatGPT = GLM-130B > 中文GPT-3
标题生成
ChatGPT
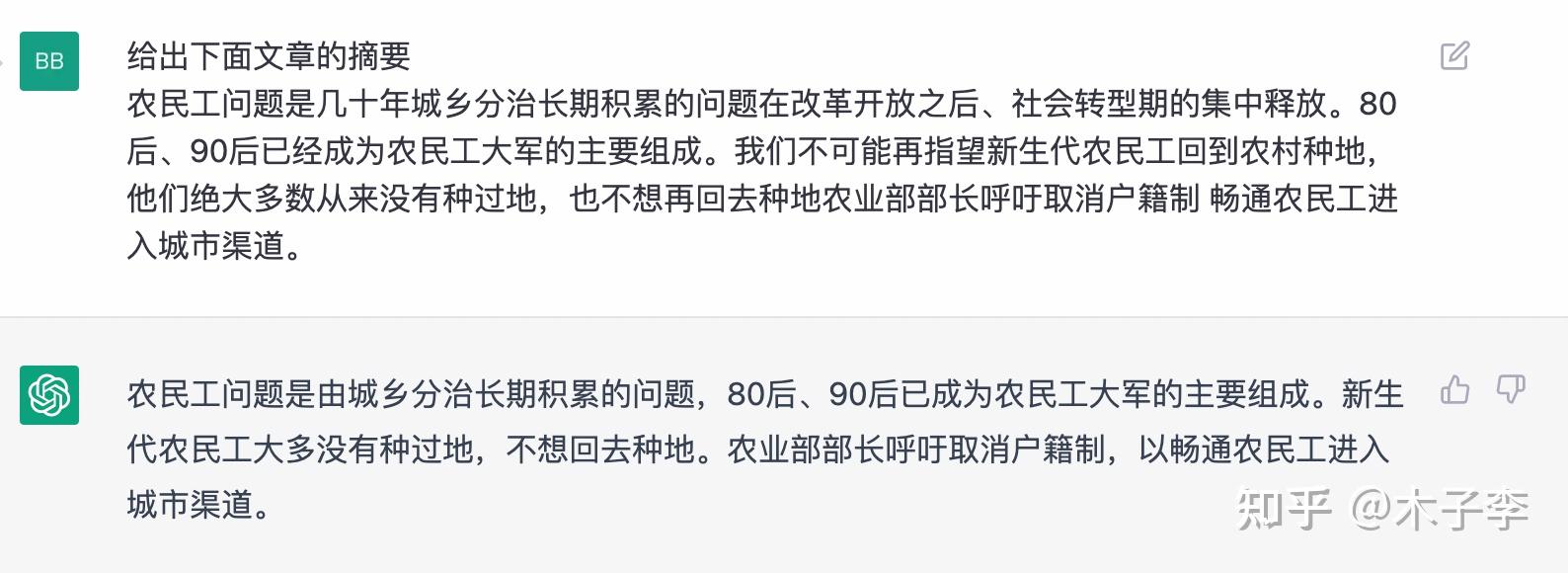
中文GPT-3
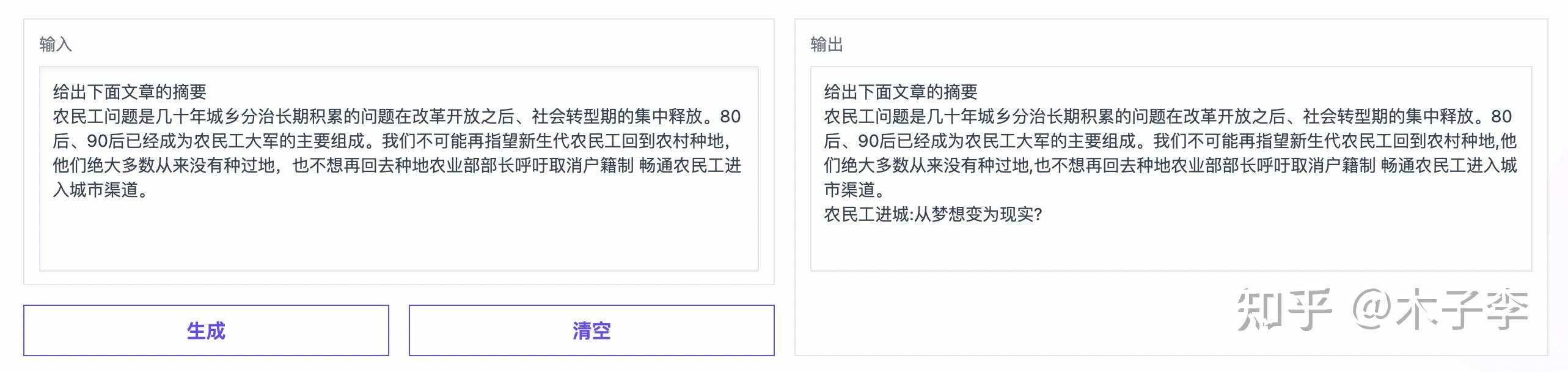
GLM-130B

标题生成这个case,中文GPT-3效果更好一些,生成的标题比较短,也比较高质量,中文GPT-3 > ChatGPT > GLM-130B
国内大模型差在哪里
对比下来,国产大模型和ChatGPT的差距还是不小的,不管是从生成的准确度,以及答案的体验上都更好一些。那么ChatGPT优势在哪里,网上也有很多老师做了一些点评,其实已经很全了。我这里也写下个人的感受:
数据。我这边个人最大的感受就是数据,这个数据不是指无监督的数据,也不是下游数据集的那种标注数据,而是真正human feedback的数据,不管是无监督还是下游标注数据,其实和人的query方式或者人的输入形式都不一样,所以human prompt input或者human instruct input很重要。新的训练范式。之前预训练+finetune的范式已经不适合于大模型了,大模型的能力绝对不止于下游任务的finetune。这个其实是网上很多老师都提到的,新的预训练+预精调+RLHF,在无监督预训练得到的大模型基础上,收集human feedback数据之后,进行human label,然后无监督数据训练的大模型在标注的数据上进行预精调。预精调之后,再对sampling 生成的结果利用强化学习RL去把人类偏好的答案前置RLHF。引入human feedback的强化学习确实起到了一些作用,可以让模型不断的能够迭代学习升级,这个确实是解决了之前大模型的一个痛点,之前大模型训练完成也就基本结束了,想要再优化很难而且也不知道从哪个角度去优化,RLHF无疑是给大模型长期持续优化提供了一个指明灯。当然,ChatGPT也不是无所不能,他也有这很致命的缺点,比如知识性比较差,而且有时候答案缺乏营养,这其实也是知识的体现,如果能把这个解决了,那真的是可以通过图灵测试了,这会不会是GPT-4呢?
小结
国产大模型还是有很长的路要走,之前小编一直的观点是中文社区的数据质量比较差,也比较杂,很难像英文大模型那样有一个那么惊艳的效果,但从ChatGPT来看,数据不是问题,中文大模型也是能够训出一个高质量的。用一句话送给自己,也送给在这个大模型赛道上努力的朋友:道阻且长 行则将至 行而不辍 未来可期

AI时代,掌握AI大模型第一手资讯!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
扫码右边公众号,驾驭AI生产力!



