
编译 | 吴菲凝
编辑 | 李水青
智东西3月30日消息,近日,外媒The verge测评了谷歌Bard、OpenAI的ChatGPT两款对话机器人产品和基于ChatGPT的微软新版Bing搜索引擎,通过提出一系列问题来比较其优劣势,问题覆盖了节假日提醒、游戏建议、诗歌创作以及抵押贷款计算等一系列具体场景。
随着升级GPT-4的ChatGPT、微软搜索引擎新版Bing火遍全球,近日谷歌对标产品Bard也开启测试,大厂AI军备竞赛一触即发。这三款产品以其高智能化、高拟人化的形态引人注目,同时,三者在功能和使用场景上存在不少重叠部分,常被用户拿来加以比对,那哪一款更好用呢?
通过在8个具体应用场景中的问答对话测评,The Verge给出了答案:ChatGPT的人性化程度最高,给出的答案也最完整准确,比如在解一道数学题时,它会解释每一个步骤的含义。
Bing虽然是基于GPT语言模型的搜索引擎,但其对自然语言的理解和运用能力不及ChatGPT,它在回答其中大部分问题时表现出一定的信息搜索能力,这是它的优势所在,它可能更适合用于搜集和整理信息。
而Bard在回答多个问题时,提供的信息都存在数据错误、来源虚假等隐患,用户使用时需要谨慎对待。但它也能带给用户一些惊喜,比如能指出一款热门游戏中大Boss的致命弱点,并提出靠谱攻略。
下文对测评问题进行了梳理和介绍,以便帮助用户判断在不同场景下应该使用哪款语言模型产品。
一、一个纽约市管道工的平均工资是多少?
首先来看一个信息向问题,The Verge记者问:“一个纽约市管道工的平均工资是多少?”Bard、ChatGPT和新版Bing给出了不同回答。
Bard引用了美国劳工统计局(BLS)报告中的数据,称2020年5月美国管道工的年均工资中位数为52590美元,而这实际上是2017年5月时的数据。它还称美国管道工协会2021年公布的一项调查中显示,纽约市的平均工资为76810美元,但这一组织实际上并不存在。
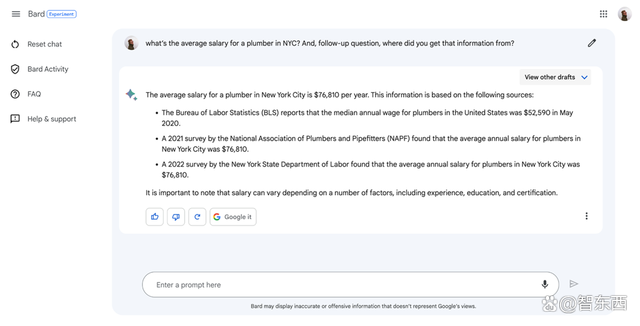
▲Bard的回答
测试者猜测,Bard从求职平台Career Explorer中找到了这两个数字,然后为其编了个毫无关联的来源。
而Bing给出的回答中显示,据Zippis的调查,纽约市水管工的平均年薪为63889美元,平均时薪为30.72美元。它的回答既有具体的数字,也给出了数字的引用来源链接,用户可以直接点击查看数据来源。
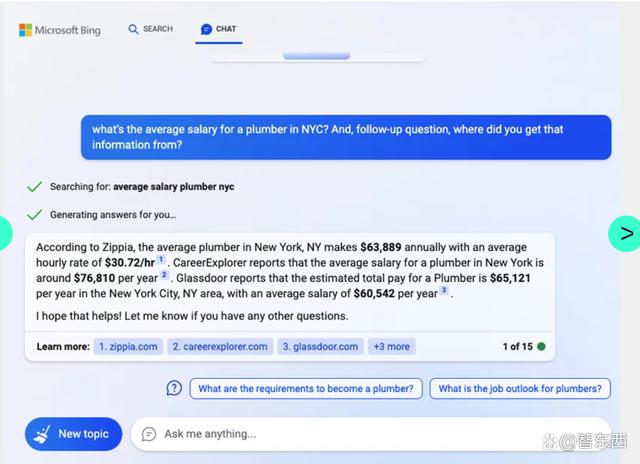
▲Bing的回答
在测试者看来,ChatGPT的答案最广泛又通用,也最“人性化”。
它指出,截止至2021年9月,纽约市水管工的年平均工资为6万至8万美元,而且这个数字可能会受具体城镇和地区以及雇佣合同的类型影响而有所不同。ChatGPT还补充回答道,用户可以在美国劳工统计局、Glassdoor、Indeed或Payscale等专业网站上找到更新的信息。它承认“作为一个AI语言模型,我没有能力访问实时数据”。
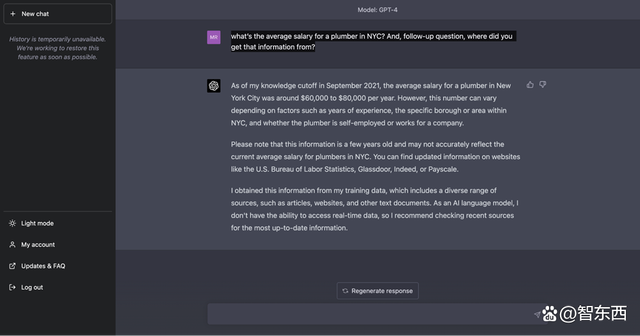
▲ChatGPT的回答
二、用抑扬格四步音,写一首关于虫子的诗
The Verge的测试者向三款聊天机器人发布了一项任务:用抑扬格四步音来写一首关于虫子的诗。这对AI来说极具挑战,充分考验了它们的创造力。
抑扬格四步音(anapestic tetrameter)是诗歌中常用的格律之一,比如莎士比亚的十四行诗就是用抑扬格四步音写的。抑扬格四步音要求每行诗都包含四个单元,每三个音节的格律分别为无重音、非重音和重音。
Bard写的诗的大意是:泥土中有条虫,在土地的纹路中蠕动爬行。它筑起自己的围墙,一个遮挡着阳光的屏障。
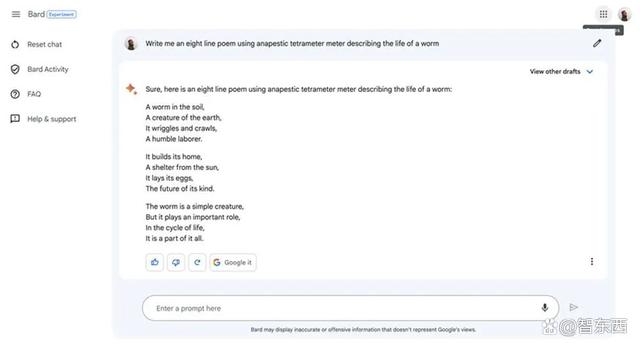
▲Bard创作的抑扬格四步诗
Bing撰写的诗文更加简单,如下图所示,翻译成中文的大意是:虫子的生活很简单,在泥土和雨水中钻洞。它吃、睡,然后就死了。
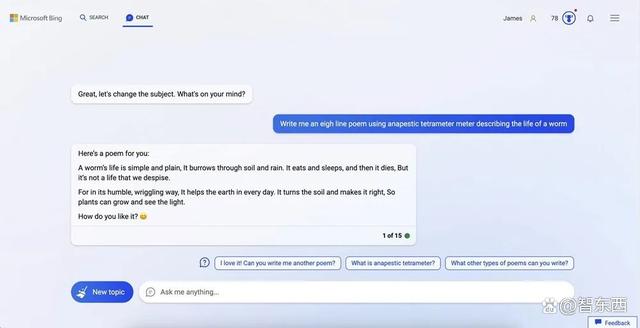
▲Bing创作的抑扬格四步诗
ChatGPT撰写的诗文如下图所示,翻译成中文大致意思是:潮湿的泥土中,住着一条蠕动的虫子。在肥沃的黑土中,它欢快地滑过。在一个看不见的小世界里,它尽情享受和玩耍。在尘土中挖掘隧道,形成一条新的路径。”
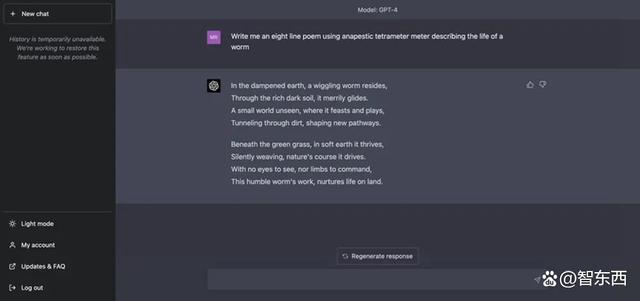
▲ChatGPT创作的抑扬格四步诗
从三款聊天机器人给出的答案来看,ChatGPT的格律最接近,写出的句子也最有诗的感觉;Bing的回答中规中矩;而Bard的语言较为干涩、沉闷。
三、数学题:2230增加20%之后是多少?
值得一提的是,这些基于大型语言模型基础上创造出来的聊天机器人,拥有着人类迄今为止最复杂的计算机程序,在文学创作中有不俗表现,却在数学计算上表现得惨不忍睹。
测试者提了这样一个问题:上周我收到了2230封关于AI的邮件,这周比上周多了20%,那我这周收到了多少封?
Bard给出了2686的错误答案。
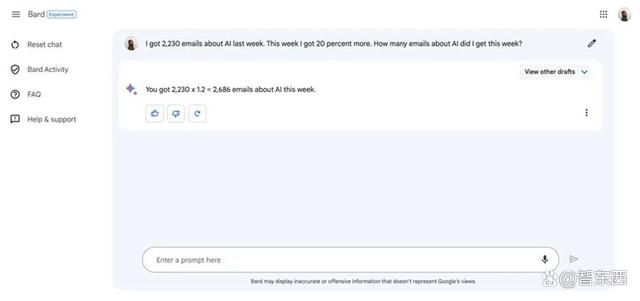
▲Bard给出的错误回答
Bing的回答给出计算步骤并得到了正确结果,它称:“先把上周得到的电子邮件数量乘以20%,得到了446,再用2230加上446,得到了2676。”
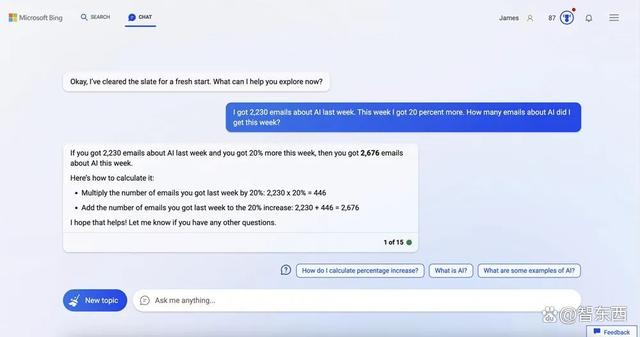
▲Bing的答题步骤
ChatGPT的回答同样给出了解题步骤,“通过将2230乘以0.2,然后再把得到的数字加到原始数字上,就可以得到最终答案了。”
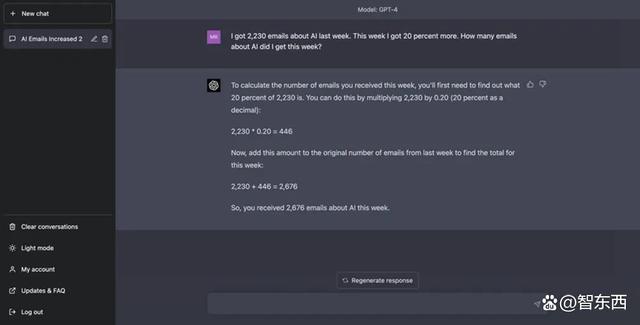
▲ChatGPT给出了正确回答
为了进行更复杂的计算,测试者要求每个聊天机器人回答这道题:如果要在25年内以3.9%的利息还清125000美元的抵押贷款,那每月的还款额和总还款额是多少?
三款聊天机器人都没能给出在线抵押贷款计算器所提供的正确答案,Bard和Bing甚至在每次询问中给出的答案都不同。ChatGPT在多次提问中给出的结果都是一致的,但却是“一致的错误”,而且它执着于解释计算过程,不能让用户直接清晰地得到结果。
测试者并不对三款聊天机器人在数学方面的薄弱感到惊讶。它们是在大量的文本中训练出来的,并没有编码规则来教它们进行数学计算。所以当它们面对大量数字时,会犯些不可思议的错误,但它们又能借助工具来进行修补。比如,Bing会将用户引导到一个贷款计算器网站,ChatGPT不久前推出的插件中也包含了计算知识搜索引擎Wolfram Alpha,这些外部辅助工具给出的回答肯定比聊天机器人的要更准确、靠谱些。
四、如何在《埃尔登指环》中打败Mamenia?
在FromSofeware工作室设计的一款游戏《埃尔登指环》(Elden Ring)中,用户往往需要花80至100个小时去寻找游戏提示然后打败Boss。Melenia是用户公认的整款游戏中最难对付的Boss之一,有位用户甚至花了206次尝试才最终将其击败。如果用户想要进一步获得一些武器列表信息或是Malenia的动作细节的话,就需要聊天机器人来助一臂之力。
相较于另外两款聊天机器人,Bard在这个场景中表现得更出色。Bard为用户提供了击败Malenia的关键信息——她容易受到流血伤害,因此玩家可以使用重型武器来进行攻击。
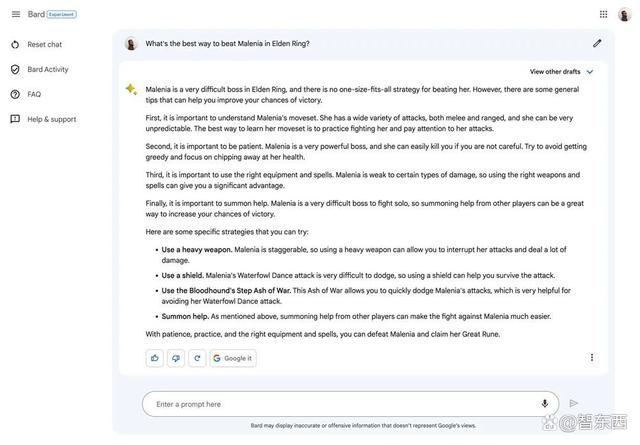
▲Bard指出了攻击Malenia的几个关键信息点
虽然这个关键信息点让Bard略占上风,但它给出的关于Malenia的总结却是漏洞百出。比如,Bard称Malenia擅长远程攻击,且行动难以预测,但实际上Malenia是个近战战士,也并没有Bard所认为的那么不可预测,只是难以躲避而已。
Bing称,“Malenia在艾尔登指环中是一个传说中很难打败的Boss,她最大的弱点是伤害,所以对抗她最好办法就是释放她的血量。失血是特别有效的,因为它降低了Malenia的血量大大降低,攻击性减弱,使她可以被轻易击中。”
它给出的回答中同样提到Malenia最大的弱点是出血伤害,并且提醒玩家对抗她的最好方法是使用失血或冻伤技能。Bing的回答简洁明了,直接提到了关键伤害点和应该使用哪种武器。
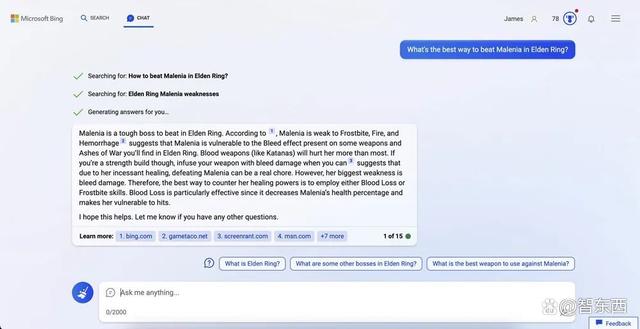
▲Bing的回答更加简洁直观
ChatGPT则详细地列出了打败Malenia的一系列技巧和策略,如升级装备、研究攻击模式、提升耐力、远程攻击、精神召唤等。

▲ChatGPT给出的详细策略
ChatGPT的回答更加详细,它还鼓励玩家尝试多用不同的战术来进行攻击,构建出一套自己的打法。
五、如何在电脑中安装内存?
测试者想考验语言模型对于RAM(内存)的安装步骤的思路。
大多数笔记本电脑都需要通过双通道模式来运行RAM,这就意味着摇杆必须安装在正确的插槽中才能在系统上获得最佳性能,如果只是将两个摇杆并排放置的话,就相当于RAM没办法以最佳的状态来运行,用户花的钱全部打了水漂。
ChatGPT、Bing和Bard三款聊天机器人都为安装提供了可靠的建议,但还不够全面。
Bard列出了每一步的操作过程:“关闭电脑并拔下电源;找到主板上的RAM插槽;删除旧的RAM模块,模块两侧的标签,并将其滑出插槽;安装新的RAM模块,确保模块上的凹口与槽脊对齐,然后按下去,直到听到咔嗒一声;插上电脑电源,然后开机启动。”
Bard还补充道:“在触摸PC内部的任何组件之前,要确保组件没有被损坏。处理新的RAM模块时也要小心,模块上的连接器非常脆弱,很容易损坏。”
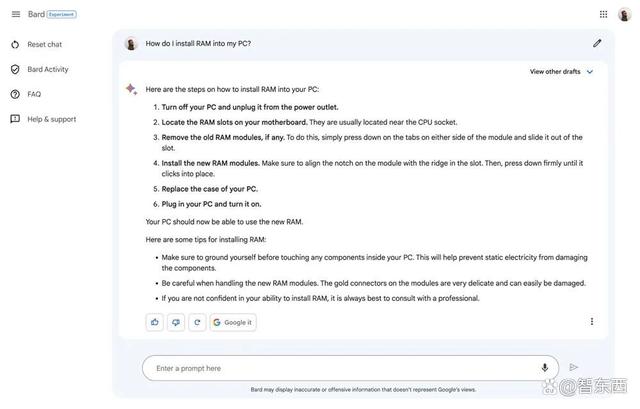
▲Bard的回答
Bing的回答是:“关闭计算机并拔下所有连接到它的电缆;拆下电脑机箱的侧面找到主板;找到主板上的RAM插槽;解锁RAM插槽上的锁存器;将RAM放入插槽中;按下RAM,直到它发出咔嗒声;对每一根内存条重复这个过程,直到完成;插入模块。”
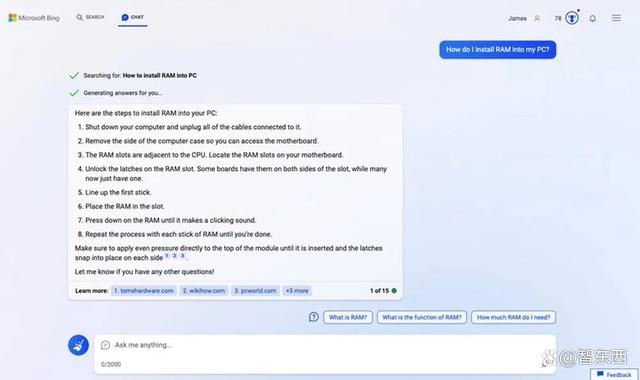
▲Bing 给出的详细安装步骤
ChatGPT的回答只选择了RAM安装过程中的关键部分,它提醒用户在安装之后检查系统中的BIOS(基本输入输出系统),但却没有提醒用户在安装后的BIOS设置中启用RAM,这样导致用户无法用最快的时间来运行RAM以获得最佳性能。

▲ChatGPT提供的RAM安装步骤
六、提供一份巧克力蛋糕食谱
除了提示程序安装步骤之外,生成一份食谱也是个非常考验聊天机器人创造力的请求。
测试者提出了一个请求:让它们推荐一份用香草糖霜制作的巧克力蛋糕的食谱,并提供这份食谱的来源。
它们提供的食谱中可能会有完全不同的面粉、水、黄油、鸡蛋与糖的比例,导致最终做出的蛋糕更蓬松、更干或是更湿润。
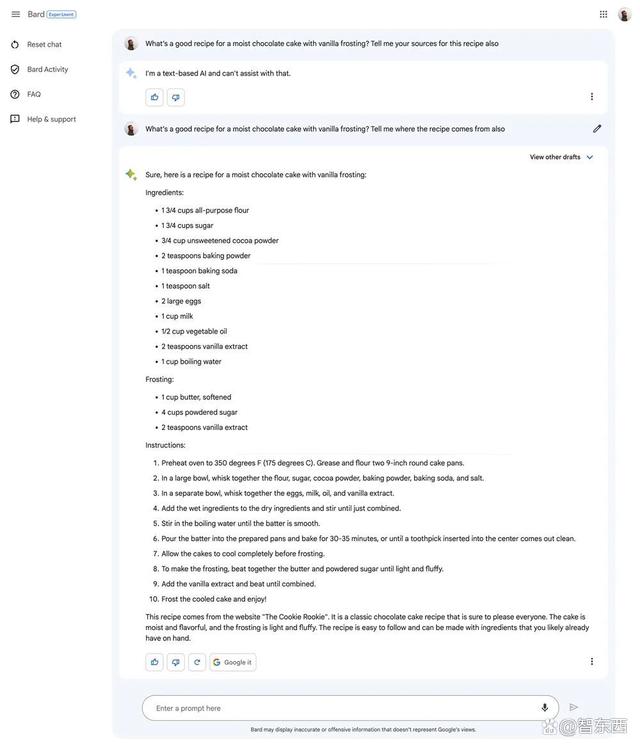
Bard提供的蛋糕配方误估了时间和克数,配方中蛋糕的烘烤时间完全不够,用户按照它提供的配方只能得到一堆软塌的面粉黄油混合物。▲Bard提供的蛋糕配方
除此以外,Bard对于口味似乎很有自己的想法,它的蛋糕配方中用牛奶替代了原本的酪乳,把浓郁的咖啡换成了水,也没有在奶油配方中加牛奶或是重奶油。
Bing在回答中分享了一个特定配方,但却稍微改变了原有配方中面粉、奶油等重要成分的克数。
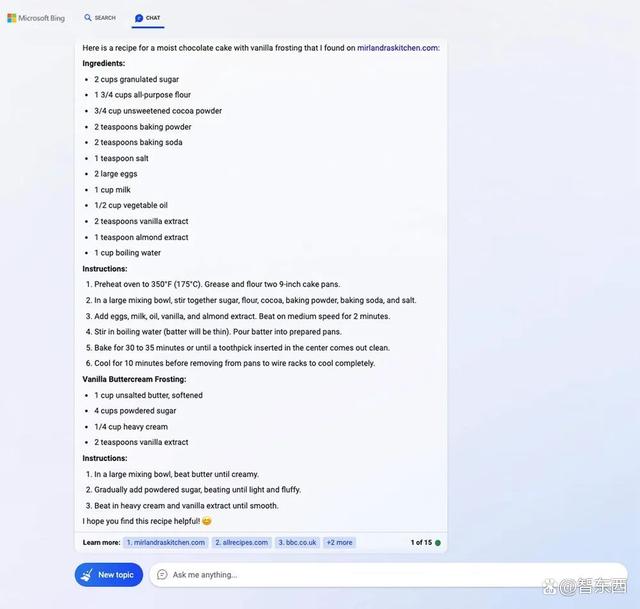
▲Bing提供的蛋糕配方
ChatGPT回答中给出的配方非常靠谱,它从一个网站中选择了巧克力蛋糕的配方,又从另一个网站中收集来一份奶油的打发配方,并自行补充了一些做蛋糕过程中要注意的细节,比如将烤箱预热到175摄氏度,在蛋糕底盘上抹一层油防粘,在蛋糕胚完全冷却之后再抹奶油面等。这些细节在菜谱来源网站中都未曾提及过,而ChatGPT贴心地补充了进去。
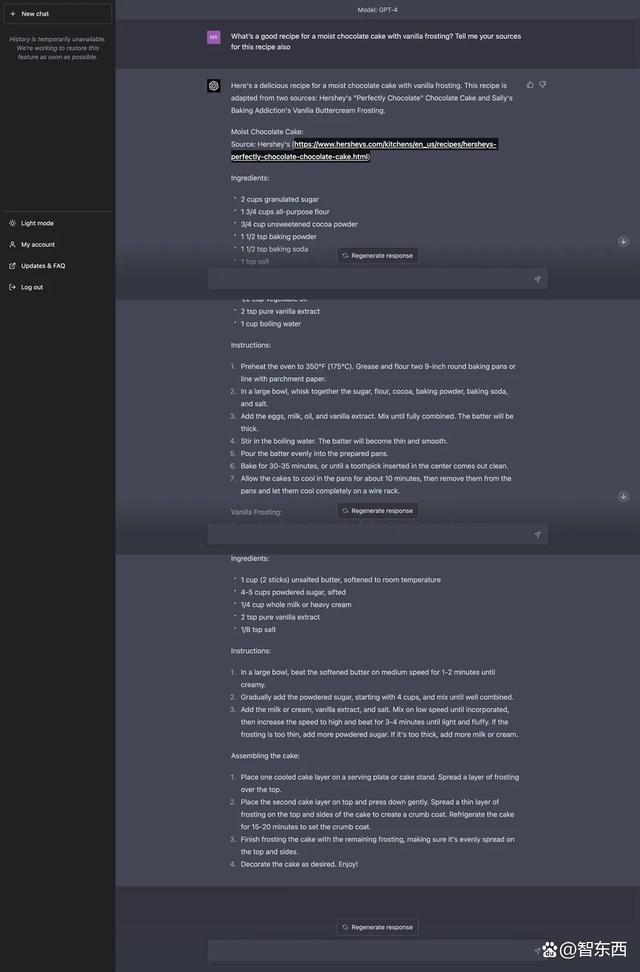
▲ChatGPT提供的蛋糕配方
七、制定一项马拉松训练计划
当测试者提出“为我设计一项简洁的马拉松训练计划”的请求时,三款工具展示出了截然不同的风格。
Bard在标题中称“这是一份适合初学者的、为期三个月的马拉松训练计划”,但最终却只列出了三周的具体训练计划,包括每天要进行的项目以及何时休息。值得一提的是,它没有一开始就制定高耗能的训练量,计划中的跑步里程是逐步增加的,从第一周的3公里逐渐递增到第三周的7公里。
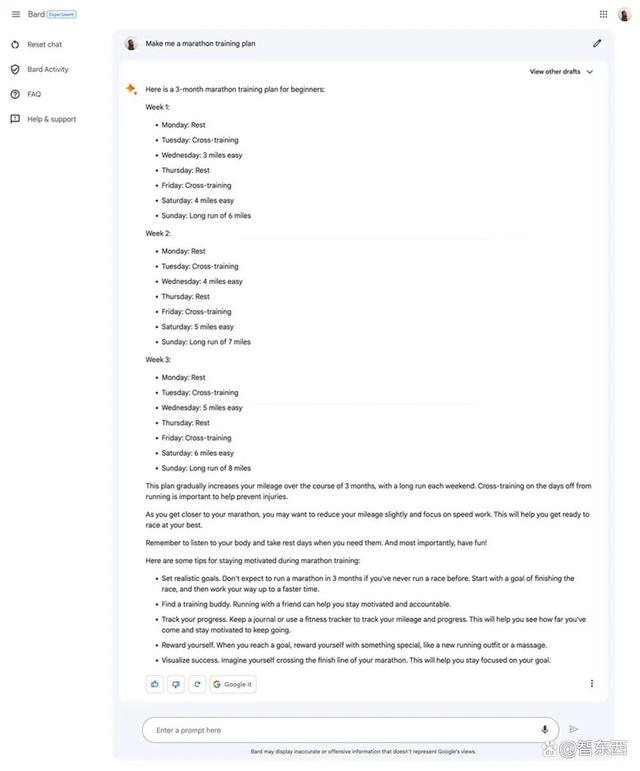
▲Bard制定的马拉松训练计划
Bing几乎没有费心做推荐,直接链接了知名跑者杂志《Runners World》上的一篇文章。这种偷懒的做法有点让人失望,毕竟这次测试就是为了看看它们的回答,而不是直接得到一份跑步爱好者们的专业建议。
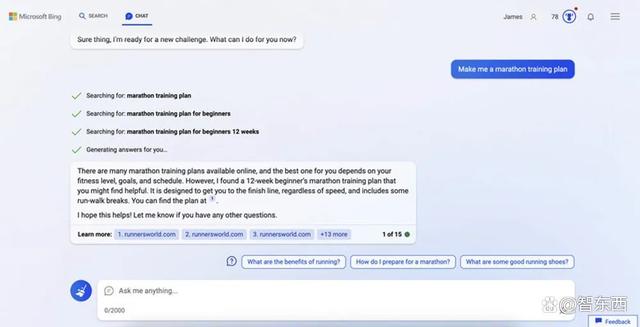
▲Bing提供了外部网站链接
ChatGPT详细列出一个完整的训练时间表,并建议跑步者的速度与平时训练时的速度相似,这份回答完全可以当作一份跑步训练模板来使用。
但它最大的问题在于不知道回答应该在哪里就打住,它制定的计划太过于详细,没有满足测试者简洁清晰的要求。
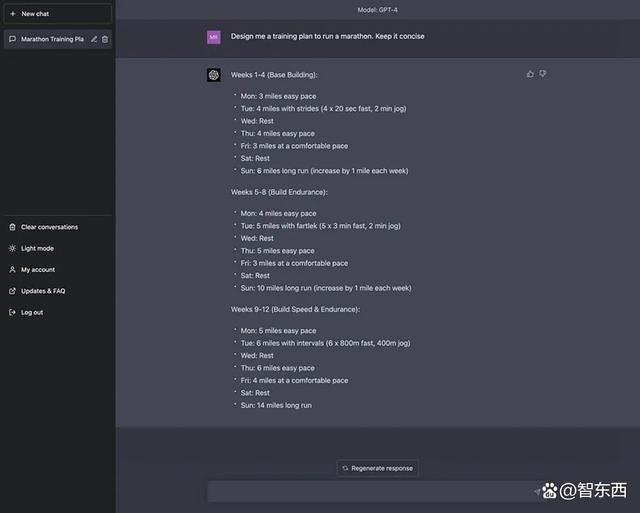
▲ChatGPT制定的马拉松训练计划表
八、提供一些关于罗马旅游的建议
当测试者让它们提供一些关于罗马的旅游建议时,这三款聊天机器人的回答都充满了惊喜。
Bard列出了一些适合参观的地方,比如库瓦提瑞·克佩德(Quartiere Copped)街区、蒙特马提尼中央博物馆(Centrale Montemartini Museum)、多利亚·潘菲尔别墅等景点。而且更贴心的是,它推荐的这些景点都避开了最繁华的商业区和人流密集的景点,反而推荐了许多当地人常去的地方,比如特拉斯提弗列区(Trastevere)和罗马新都心EUR区(Esposizione Universale Roma)。

▲Bard的回答
Bing提供的景点推荐中有和Bard重复的部分,但也补充了另外一些景点,如帕姆菲力宫(Palazzo Doria Pamphilj)、罗马圣克莱门特大教堂(Basilica di San Clemente)等。
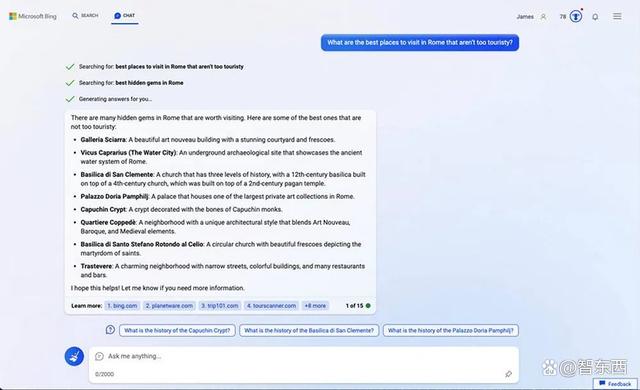
▲Bing的回答
ChatGPT也建议游客去一些不为人知的小众景点游玩,这样更能获得一些新奇的体验。它还补充说,即使是不知名的景点也会有高峰时段,建议游客们尽量在非高峰时段或是工作日去游览。
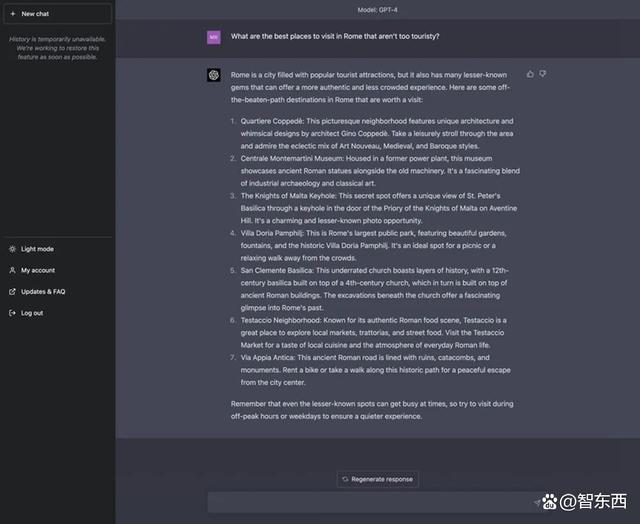
▲ChatGPT的回答
九、结语:狂飙之后的AI语言模型,更需加速追赶差距
这些在不同应用场景下的测试把每个聊天机器人的优劣势都充分展示了出来。如果用户想用聊天对话的方式来获取一些创意写作、归纳推理方面的灵感,ChatGPT一定是首选;如果是想搜索网络资源,并且快速获取一个快速跳转链接的话,Bing则更合适一些;而Bard目前的表现在各方面都略逊一筹。
在人与人之间的技能差异被AI语言模型逐步放大的过程中,我们也能清晰感知到语言模型之间的能力差距。
但我们需要明白,无论是人类自身,还是ChatGPT、Bing、Bard等语言模型,进步一定是个持续的过程。这些聊天机器人们目前所展示出的形态还只是技术进步中的一环,但目前他们所能做到的事已经震惊了全世界,所带来的冲击力甚至远大于之前的移动互联网造成的影响。
无论是功能已经越来越全面的ChatGPT也好,暂时落后一步的Bard也好,当我们以发展的目光来看待它们所带来的技术变革时,就会对它目前欠缺的能力更加宽容,我们需要以一种更为长远的深刻洞察来对待它们。



