
种种迹象表明,由ChatGPT引发的算力军备竞赛已经悄然而至了。
从另一个侧面也可以得到印证:近期,浪潮在接受媒体采访时,就曾对外表示,“AIGC火热带来AI服务器需求量的爆增,3月份我们发现AI(服务器)市场出现几倍以上增长,以前(客户关注点)是能不能便宜点,现在是能不能用得上。”
近日,有媒体援引知情人士消息称,特斯拉CEO马斯克在推特内部启动了一项人工智能项目,为此购买了约1万个GPU。

在此之前,在业界就不断流传各个互联网大厂都在紧急备货GPU,为其大模型开路。
地主家也没余粮。ChatGPT 本身也一直被算力紧缺所困扰。4 月 6 日, ChatGPT 就” 因需求量太大暂停了升级服务 “,并停止 Plus 付费项目的销售。
为了给ChatGPT 提供算力保障,其金主爸爸微软可以说劳心劳力。据悉,微软用几亿美元,耗费上万张英伟达A100芯片打造超算平台,只为给ChatGPT和新版必应提供更好的算力。不仅如此,微软还在Azure的60多个数据中心部署了几十万张GPU,用于ChatGPT的推理。
事实上,算力紧张这件事情,是从一开始就伴随着ChatGPT 。当初OpenAI选择与微软合作,算力就是一个至关重要的考虑因素。据悉,OpenAI在最初商量与微软合作时,OpenAI要求微软在Azure云计算平台上“腾出”足够的算力单独给它们使用,且确保它们不与Azure提供的其他服务产生冲突。
业界普遍认为,大模型是巨头们的“玩具”,动辄上亿元的投入,小玩家是上不了“赌桌”的。
但是,不要忘了ChatGPT这类大模型有两面,一方面是模型训练,另一方面是模型推理应用。动辄几亿的算力投入,还只是模型训练阶段。在模型推理应用阶段,对于算力的需求,要远远高于训练阶段。
也就是说,大模型的训练需要几亿打底,那要想将大模型进行规模化应用,比如支撑成百上千万用户的频繁使用,那需要的算力成本可能就是百亿量级了。
接下来,我们致力于搞清楚为什么ChatGPT这类大模型这么“吃”算力。尤其是要搞清楚在大模型的应用阶段,用户量、业务量跟底层算力需求是什么关系。在此基础上,我们来测算,要支撑足够的用户量和业务规模,到底需要多少算力(尤其是GPU)。
ChatGPT训练阶段的算力消耗
先来看看训练阶段的算力消耗。
训练大型模型需要大量的算力,因为需要处理海量的数据。训练这类模型所需的算力取决于以下因素:模型的规模(参数数量)、训练数据集的大小、训练轮次、批次大小。
在此,我们假定要训练一个千亿规模的大模型,用1PB数据进行训练,训练一次,并且在10天内完成训练。看看需要消耗多少算力,并计算这样的算力消耗,如果用英伟达的芯片,需要多少芯片。
首先,我们要了解一个概念,即FLOPs(浮点运算次数)。FLOPs用来衡量执行某个任务所需的计算量。假设一个千亿(1000亿)参数的大型模型,我们可以参考GPT-3。GPT-3中最大的模型(1750亿参数)的训练大约需要3.14 * 10^23次浮点运算(FLOPs)。

我们可以通过以下简化公式估算所需的FLOPs:
所需FLOPs = (千亿参数 / 1750亿参数) * 3.14 * 10^23 FLOPs
根据这个公式,我们得出训练一个千亿参数的模型大约需要1.8 * 10^23次浮点运算。
接下来,我们来看看英伟达的芯片。以英伟达A100 GPU为例,其具有每秒19.5万亿次(19.5 TFLOPs)的浮点运算能力。

要计算出需要多少个A100 GPU来满足这个算力需求,我们可以使用以下公式:
所需GPU数量 = 1.8 * 10^23 FLOPs / (19.5 * 10^12 FLOPs/s * 训练时间秒数)
如果希望在10天(约864000秒)内完成训练,可以按照以下计算方式得到所需GPU数量:
所需GPU数量 = 1.8 * 10^23 FLOPs / (19.5 * 10^12 FLOPs/s * 864000s)
根据这个公式,在10天内训练1000亿参数规模、1PB训练数据集,大约需要10830个英伟达A100 GPU。
接下来,我们来计算大模型的训练成本。
要计算训练一个千亿规模大型模型的总费用,我们需要考虑以下因素:GPU成本、其他硬件成本(如CPU、内存、存储等)、数据中心成本(如电力、冷却、维护等)、人力成本。
还是上面的例子,需要在10天内训练1000亿参数规模的大模型,总的成本如下:
GPU成本:
英伟达A100 GPU的价格因供应商和购买数量而异,假设每个A100 GPU的成本约为10000美元,那么10830个GPU的总成本约为:
10830 * $10,000 = $108,300,000
其他硬件成本:
GPU只是整个计算系统的一部分,我们还需要考虑其他硬件设备的成本。包括CPU、内存、存储、网络设备等。这些硬件成本可能占据整体硬件成本的一部分,假设其他硬件成本占GPU成本的20%,那么:其他硬件成本 = $108,300,000 * 20% = $21,660,000
数据中心成本:
我们还需要考虑数据中心的成本,包括电力、冷却、维护等。假设这些成本占GPU成本的10%,那么:数据中心成本 = $108,300,000 * 10% = $10,830,000
人力成本:
训练大型模型需要一支研究和工程团队,包括研究员、工程师、数据科学家等。人力成本因团队规模和地区差异而异。在这里,我们假设人力成本约为200万美元。
综合以上因素,训练一个千亿规模大型模型的总费用大约为:
总费用 = GPU成本 + 其他硬件成本 + 数据中心成本 + 人力成本
= $108,300,000 + $21,660,000 + $10,830,000 + $2,000,000
≈ $142,790,000
因此,在10天内训练一个千亿规模的大型模型大约需要花费1.43亿美元。
当然,如果训练时间长一点,就可以用更少的GPU,花费更少的成本。但一般而言,总成本都会在几千万美元规模。
从上面的分析可以发现,大模型真的是烧钱的游戏。先不考虑大模型的研发,就是要完成一次大模型的训练,首先就要有上亿的成本投入。
ChatGPT推理应用的算力消耗
需要指出的是,并不是模型训练好了就万事大吉。大模型的应用不是免费的,也是需要消耗算力的。
那么,在模型使用过程中,消耗的算力该怎么计算呢?

要计算一个用户向ChatGPT提问并获得回复所需的算力,我们需要考虑以下因素:模型规模(参数数量)、输入文本长度(问题长度)、输出文本长度(回复长度)、模型的计算复杂性。其他3个要素好理解,模型的计算复杂性是什么呢?模型计算复杂性指的是模型本身的复杂程度,它与模型维度(D)和模型层数(N)成正比。
用户一个问题,需要消耗的算力,可以用以下公式计算:所需FLOPs ≈ L * D * N。其中,L是用户问题的输入长度与模型回答的输出长度之和。
我们假设一个用户问ChatGPT一个50个字的问题,ChatGPT给出了1000字的回复。完成这样一次交互需要消耗的算力:
所需FLOPs ≈ L * D * N
≈ 1050 * 1280 * 96
≈ 128,448,000
因此,当输入问题长度为50个词,输出回复长度为1000个词时,处理一个用户向ChatGPT提问并获得回复所需的算力约为128.45百万次浮点运算(FLOPs)。
在此,我们需要澄清一个问题:ChatGPT回答不同类型的问题,只要问题长度和答案长度都一样,其消耗的算力都一样么?比如同样的问题和答案长度,写小说和做算术题这两类任务消耗的算力是否一样。
在理论上,只要输入问题长度和输出答案长度相同,处理不同类型问题所需的算力应该是相似的。这是因为,无论问题类型如何,Transformer模型的计算复杂性主要取决于输入序列长度(L)、模型维度(D)和模型层数(N)。不过,在实际应用中,根据问题的难度和特定上下文,某些任务可能需要更多的计算步骤来生成更准确的答案。
例如,在生成小说文本时,模型可能需要花费更多的计算资源来保持句子的连贯性、情感和文学风格。而在解决算术问题时,模型可能需要更多的计算资源来处理数学逻辑。然而,从整体来看,两者之间的计算复杂性差异相对较小。
因此,在问题长度和答案长度相同的情况下,不同类型的任务(如写小说和解决算术问题)消耗的算力可能存在一定差异,但总体上应该相差不大。
接下来,我们要进一步计算用户使用ChatGPT这类大模型的算力成本,也就是说用户问一个问题,到底要花多少钱。
一般而言,大模型都部署在云端,用户通过云服务来调用相应的计算资源。
要计算使用云计算服务调用ChatGPT的费用,我们需要了解云计算厂商的计算资源定价。这些价格可能因厂商、地区和资源类型而异。
我们以Amazon Web Services(AWS)的英伟达A100 GPU为例,我们可以估算费用。
首先回顾我们之前的计算,对于一个输入长度为50字、输出长度为1000字的问题,处理一个请求所需的算力约为128.45百万次浮点运算(FLOPs)。
现在,我们需要了解GPU的性能以及在云计算平台上的计费方式。以AWS的g4dn实例为例,它使用的是英伟达T4 GPU,每个GPU具有8.1 TFLOPs的计算能力(这与我们之前提到的A100 GPU(具有19.5 TFLOPs的性能)不同。因此,我们需要对计算进行一些调整。)
假设我们需要在1秒内完成这个请求。那么,我们可以计算所需的T4 GPU数量:
所需T4 GPU数量 = 所需FLOPs / (8.1 * 10^12 FLOPs/s)
≈ 128.45 * 10^6 / (8.1 * 10^12)
≈ 0.00001585
根据AWS的价格策略,以美国东部地区为例,g4dn.xlarge实例(1个英伟达T4 GPU)的按需价格约为0.526美元/小时。如果我们假设每个请求都需要1秒钟完成,那么一小时内可以处理的请求数量为:
每小时处理的请求数量 = 3600秒 / 1秒
= 3600
根据这个估算,使用一个g4dn.xlarge实例处理请求的成本约为:
每小时成本 = $0.526 / 3600 请求
≈ $0.00014611 / 请求
所以,使用云计算服务(以AWS为例)调用ChatGPT的能力,每处理一个输入长度为50字、输出长度为1000字的问题,大约需要消耗0.00014611美元的云计算资源。用1美元可以向ChatGPT提问约6843个问题。
最后,我们来讨论另一个问题,看看一个英伟达芯片可以同时支撑多少用户使用。
为了估算英伟达GPU可以同时支撑多少个用户,我们需要了解GPU的性能。以英伟达T4 GPU为例,它具有8.1 TFLOPs的计算能力。之前我们计算过,处理一个输入长度为50字、输出长度为1000字的问题所需的算力约为128.45百万次浮点运算(FLOPs)。
假设每个用户请求的处理时间是1秒。这样,我们可以计算英伟达T4 GPU可以同时支撑的用户数量:
所需FLOPs = 128.45 * 10^6 FLOPs
T4性能 = 8.1 * 10^12 FLOPs/s
用户数量 = T4性能 / 所需FLOPs
= (8.1 * 10^12 FLOPs/s) / (128.45 * 10^6 FLOPs)
≈ 63,088
根据这个估算,一块英伟达T4 GPU可以同时支撑大约63,088个用户(假设每个用户请求的处理时间是1秒,输入长度为50字,输出长度为1000字)。
如果换成英伟达的A100(19.5 TFLOPs的计算能力),则一块A100芯片可以同时支撑15万用户使用。
注意,以上计算都是建立在1000亿参数规模的大模型基础上的。目前的大模型参数规模普遍要超过1000亿,一块芯片能够支撑的用户数要小于上面的计算数值。
根据上面的计算,对于一个5000亿参数规模的大模型,一个A100芯片能够支撑的用户数量预计在3万左右。那要同时支撑1亿用户使用,需要的A100芯片数量就要超过3000个;如果使用T4GPU,那需要的芯片数量可能得上万。
中国在这场GPU盛宴中,不应该缺席
在这场大模型引发的算力军备竞赛当中,GPU芯片成为整个行业的焦点。
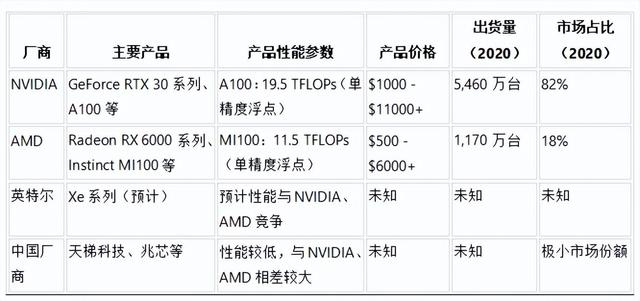
为此,数据猿依据Jon Peddie Research(JPR)报告(2020年)、各厂商官方网站和各种硬件评测网站的信息,统计了全球GPU市场的情况,包括主要厂商及其典型产品、性能参数、产品价格、出货量和市场占比,具体如下表:
在深度学习和人工智能的黄金时代,GPU犹如翱翔于浩渺天空的翅膀,赋予大模型行业强大的推进力。这些并行计算的神奇力量,像涓涓细流汇成磅礴大河,携带着无尽的智慧,助推人类探索知识的边界。在GPU的支持下,我们打破了次元壁,砥砺前行,迈向前所未有的高峰。
正是因为GPU强大的计算能力,大模型得以茁壮成长,从浅层神经网络发展到深度学习的复杂模型,从局限的应用领域扩展至无所不及的智能场景。今日的计算机视觉、自然语言处理、强化学习等领域的突破和革新,离不开GPU这位得力助手的默默付出。而大模型所孕育的智慧,正源源不断地流入各个行业。
在未来的道路上,GPU将继续担任大模型行业的引领者,携手开拓新的计算领域,为人类书写更为辉煌的篇章。
目前来看,在整个AIGC产业中,中国的应用生态建设是最强的,在大模型领域虽然跟OpenAI还有一定的差距,但追赶很快。但是,在GPU芯片领域,我们差距还非常大,且在短期内看不到赶超的希望。
就像一个木桶,最终决定能装多少水,不是取决于长板,而是决定于最短的那块木板。在这场军备竞赛当中,我们不要只关注大模型,而忽视了GPU芯片。中国要想在这个领域实现追赶,就必须要补上GPU的短板。

文:一蓑烟雨 / 数据猿



