笔者上周末测试这个产品后感觉到了写代码和写科幻的双重失业危机,赶紧去看了下官方的博客和援引论文的信息。从 ChatGPT 的产品博客[1]来看,基本路线是在 175B 的 GPT-3 上使用人类反馈强化学习 (RLHF) 来强化对人类指令的识别 。
ChatGPT 惊艳的效果主要可以归功于三个方面:
从文本和代码混合数据中习得足够强基础模型(GPT-3.5)从真实人类反馈中习得足够准奖励模型(Reward Model)两者交互和强化习得强交互能力的最终模型(InstructGPT-3)GPT-3 到 InstructGPT-3
先看看官网上从 GPT-3 到 InstructGPT-3 迭代路线[2],参考 OpenAI model index

2020年7月发布了 175B 的 GPT-3[3],主要基于文本训练、通用任务训练。紧接着 2021年7月又发布了 12B 的 CodeX[4],主要基于代码训练。这个模型没有直接用到,但随后受到启发,提出基于文本和代码混合数据训练的方法[5],在 GPT-3 基础模型上训练了 175B Code-davinci-002(davinci 指的是 175B size 系列)。
基于 Code-davinci-002,OpenAI 进行了两阶段的训练以重点提升意图识别的能力(InstructGPT)[7],分别是(1)prompt + human demo 数据有监督学习 和(2)和 reward model 交互采样做强化学习,分别得到 text-davinci-002 和 text-davinci-003。关于这两个模型的训练,Blog 提到,和今年 1月的文章 InstructGPT 中训练方法一致,只在数据收集过程有细微差别。
这三个模型共同称之为 GPT-3.5 series,这也是 chatGPT 背后的基石。GPT-3 的参数量、数据和惊艳效果、以及 CodeX 的代码补全,无疑为整个 chatGPT 的语言能力、代码示例能力提供了基础,本文就不再赘述。笔者研究生期间主要在做强化学习,重点聊一聊 InstructGPT 为什么可能 work ,以及强化学习的功与过。
InstructGPT
InstructGPT 三板斧
InstructGPT 的目的是增强 GPT-3 对具体人类指令的响应效果,即给出 prompt 和输出文本之间的强相关性。
训练数据的Prompt 主要来自于 OpenAI 此前产品 API 中用户提交的 prompt 和标注者提供的两部分,形式和各项任务的分布如图。

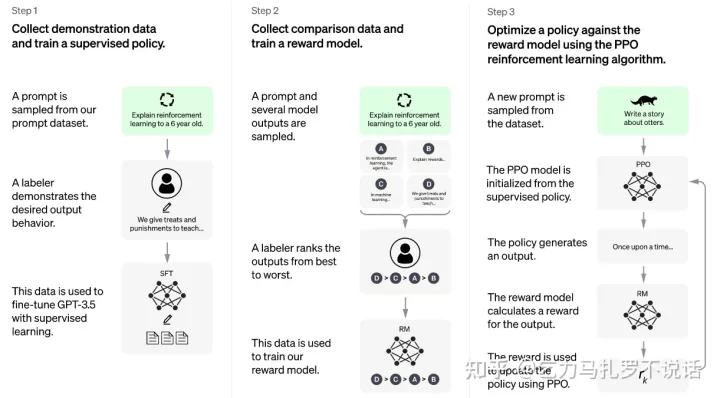
如上图所示,分为三个训练步骤
有监督 Finetune (SFT) :抽样 prompt 由人类标注回答,收集一些 demo 数据,监督学习训练奖励模型(RM) : 抽样 prompt 由模型回答,由人类排序打分,额外训练一个 6B 的奖励模型(RM) 作为接下来强化学习环境强化学习训练 (PPO) : 抽样 prompt 由模型回答,由 RM 持续多轮交互打分,强化学习训练笔者认为最关键的是第二步:从人类标注中学习一个足够准确的 reward model (RM)。
黑盒环境 vs. 白盒环境
假如我们有一些标注可用,常见的利用思路无非是
直接拿标出的好样本 Finetune,这也是足够 cover 大部分单任务场景的做法利用标注学出 Discriminator 模型,如果学的准,这相当于从有限的标注变成了无限的标注。这和强化学习有啥关系?在自然语言场景下,语言模型的目的是要满足人类语言背后不可知的复杂评价体系,用 RL 的话说就是智能体的环境。
只不过在此前对话系统中,有的视为白盒环境,比如 LaMDA,尽可能详细地把人类的评价拆解多个维度,训练 discriminator对每个维度分别打分,再按照等价加权选。而纯 RL 路线当作黑盒环境,比如OpenAI InstructGPT 和 Deepmind Sparrow,在训练中,Reward Model 端到端地给出分数 ,而模型背后评价体系的维度权重、奖励函数则是不透明的(不过在获得RM中还是需要拆解后的规则打分)。
黑盒环境好处很明显 —— 类比于从早期机器学习特征工程变成了深度学习,白盒环境再怎么排序加权都还需要手工设计一套规则、各维度打分的权重、前后顺序等等,而黑盒直接去拟合背后的评价,缺陷也很明显,就是不知道模型为啥打这个分。考虑到强化学习对 reward 的敏感,足够准确的黑盒 RM 如有神助,不够准确的可能比白盒的规则更灾难。
强化学习的功与过
另一方面,有了黑盒环境,整个问题就很容易建模为 RL 问题。RL 潜在好处是提升多轮的交互能力。
监督学习,比较模型 output 和 target 的差距,告诉模型差距在哪里(loss),梯度下降。强化学习,模型一步步输出 output,环境给出即时好坏评价 reward,模型则考虑序列 output 的累积奖励(loss, advantage value),梯度下降。序列 output 也称作轨迹(trajectory)。相比于前者,强化学习的一大特征是多轮多次输出,比如评价序列输出好坏的 advantage 函数(式10)也要考虑累积的长期效应,对整段轨迹的 instant reward 衰减加权。后者的训练目标和建模或许更接近人类意图中考虑上下文、考虑后续效应的对话模式。
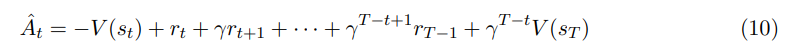

说完优点,也说说强化学习很容易不 work 的一些点和 chatGPT 中发现的避坑策略。
深度学习三要素:数据、模型和算法。强化学习不例外,在涉及应用问题中,制约落地效果的往往来自学术研究中视为默认的 “环境”,定义目标的 reward engineering 往往比后续的算法更为关键。
同样,有标注的人力也不等于就一定能学好,何况也只用了相对少的标注样本。
首先,采用两阶段(SFT-RL)方法而不是直接从头,通过足够好的预训练和人类 demo 的监督学习过程做非常好的初始化,在此基础上, RL + RM 的训练重点利用相应交互能力而不是语言能力。各取所长。实际上,通用算法 PPO 在一些表现不够好的场景,要么需要量级更大的采样数据来看到模型的质变,要么采用模仿学习的办法引入一些人的优质 trajectory来缩短进程(非常类似监督学习e.g., Go-Explore)。对话场景其实也可以说是一个奖励非常稀疏的场景。稀疏与否指的是多少次动作能获得一个非0 reward。直观上说,强化学习依赖及时反馈更新自己的值函数,而 sparse reward 场景上失去了 guidance ,在获得 reward 的两步之间的多轮都是无目的地探索,这里获得的 trajectory 数据就相当低效了。其次,第二步中标注在每个维度上并不是细粒度的打分(0.1,…,0.9),而是排序(可以看成0-1粒度)。关于 Reward 的噪声和粒度,要结合起来看。考虑 RL 的多轮采样优化的特征,reward 噪声会累加,而且会持续影响下一步采样到的 trajectory,所以一般强化学习算法对 reward 随机噪声敏感 (有一些最新的研究关注 robust optimization)。对于高噪的细粒度 reward,无法确认 0.6 一定比 0.4 的选择更好,导致噪声带来的 negative effect 远大于多出的信息。如果不能保证打分的可靠性,两两比较的 binary reward 、或者将细粒度得分离散处理可能更好。第三,奖励函数和现实目标充分对齐。Reward 相当于定义了 RL 中的 golden truth,并引导策略优化的方向,如果设计的 reward function 没有很好地和应用实际目标一致,算法优化反而越容易误入歧途。举个经典AI智障例子,AI 的目标是捕猎,每只猎物加一分,每掉进陷进扣一分,于是 AI 经常自杀。这里如果我们认为结果自杀比掉进陷阱更糟糕, reward function 中应该设计为更低分 -100,否则在这个环境中的好恶和我们认知是不对等的。类似的工作中,Deepmind 的 Sparrow 在单点对齐上可能做的更全面,融合了规则和人类标注。总之,没想到 2022 年快要结束了又出现了一个爆款 AI 产品。今年Diffusion Models 和 ChatGPT 狠狠地又拉高了我们对 AI 的想象力。 期待明年的 GPT-4 ~
不当之处敬请指正。
参考链接
1. OpenAI ChatGPT Blog https://openai.com/blog/chatgpt/
2. OpenAI GPT 3.5 Doc https://beta.openai.com/docs/model-index-for-researcher
3. GPT-3 [2005.14165] Language Models are Few-Shot Learners
4. Code-X [2107.03374] Evaluating Large Language Models Trained on Code
5. [2201.10005] Text and Code Embeddings by Contrastive Pre-Training
6. [2009.01325] Learning to summarize from human feedback
7. InstructGPT [2203.02155] Training language models to follow instructions with human feedback