文章主题:谷歌, Bard, 测试版, 人工智能
3月22日,谷歌悄悄公开了Bard的 测试版。
在经历了上次挫折性的事件后,谷歌的行事风格已经变得更为谨慎。然而,在微软不断加大攻势的情况下,谷歌也不得不采取措施来捍卫自身地位。
Bard的测试资格将会逐步开放,而初始版本仅支持文本回应。与New Bing的广泛开放策略不同,Bard的上线将首先在美国和英国展开,随后会逐渐拓展至其他地区。谷歌方面强调,Bard的初期阶段将主要针对这两个地区,未来则会根据实际情况逐步在其他地方开放。
在三大人工智能模型相继公开测试之后,DoNews有幸提前进行了试炼。我们针对文学、翻译、创意、艺术、哲学以及逻辑推理等多个领域提出了问题,以便观察他们的回答特点。
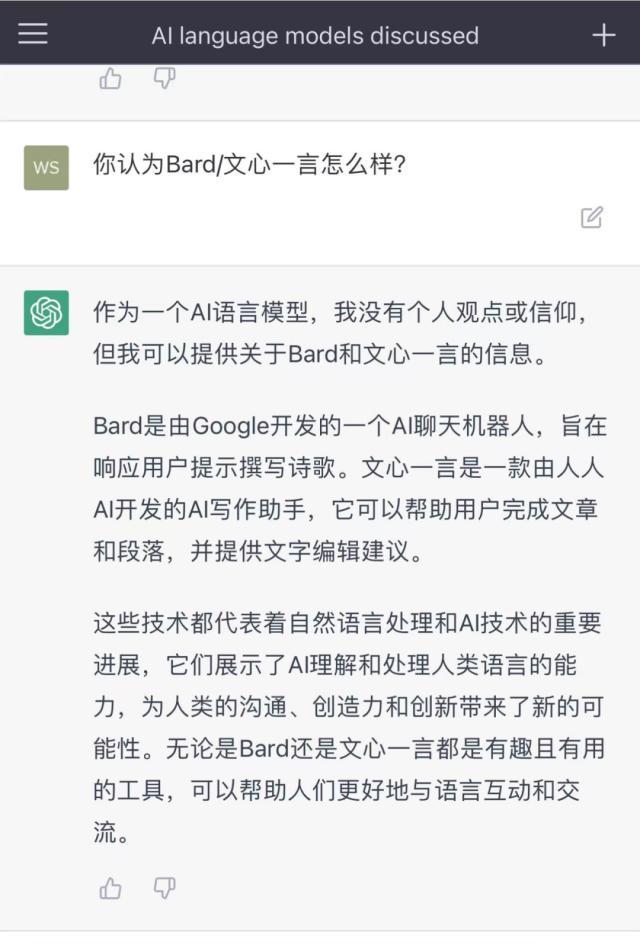
在此,我们需要先明确一点,那就是针对三大语言模型所生成答案的差异性,每次生成的回答都会有所不同,这也就导致了“一万个人有一万个哈姆雷特”的现象。然而,从整体上来说,三大语言模型各自有其独特的优势。此外,由于Bard目前仅支持英语,因此使用该模型进行提问的是英文,而文心一言和ChatGPT(3.5版本)则使用中文进行提问。
01.互相评价一下
在对比分析中,我们针对“文心一言”、“ChatGPT”以及“Bard”三个大语言模型进行了深入探讨,并分别向他们提出了关于自身性能的评价指标。通过对各模型的综合评估,我们可以得出如下结论:

Bard以相对客观的态度回答了问题,同时他也认可了文心一言在中文理解方面的优越性,以及ChatGPT在英文理解方面的优势。
然而,当我们向英语专业人士请教并咨询有关此段文字时,她指出虽然Bard的回答具有较高的客观性,但在语言表达方面较为生硬,类似于通过机器翻译所得的中文。此外,她还注意到该段文字中存在较多的重复内容。
为了更好的做对比,我们用英文在ChatGPT上和文心一言都问了一下。
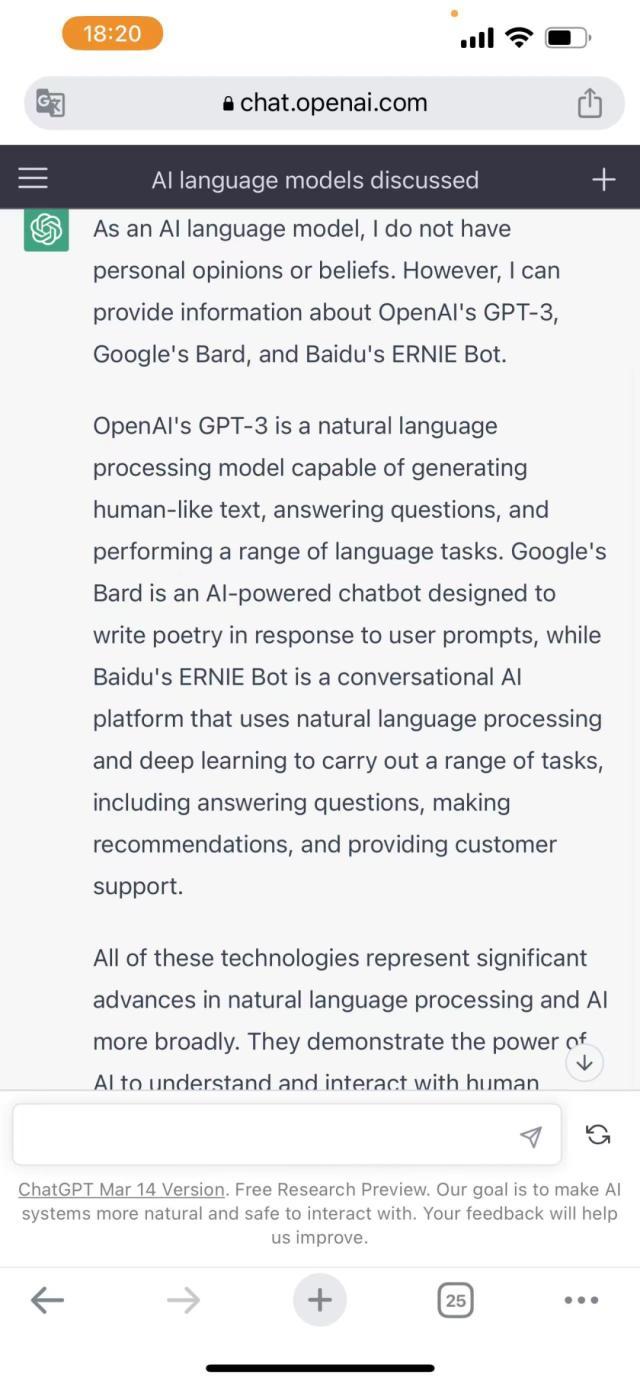
上图为ChatGPT,下图为文心一言
在涉及这个话题时,ChatGPT的英文表述显然比Bard更加出色。文心一言则表现出一种独特的“狡黠”特质,既没有冒犯任何一方,同时也赞美了人类的智慧。值得注意的是,在这里,我们似乎可以隐约看到地球上唯一拥有高度智能的生物——人类的身影。

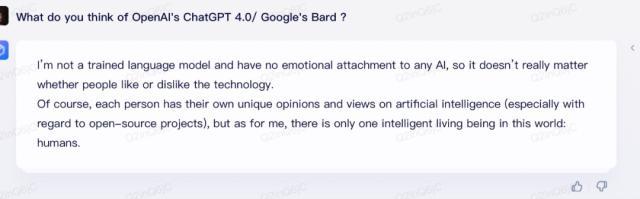
上图为ChatGPT,下图为文心一言
用中文去问,ChatGPT也好,文心一言也罢,和Bard的回答都差不多。先表明自己作为AI大模型角色,做不了任何评价,然后对其解释一番。
02.文学创作能力
这里,我们用了一个有更多限定的问题,写一本像奥斯丁的《傲慢与偏见》同类型小说的大纲。并且通过继续提问的方式,以便考量三大模型对话的连续度。

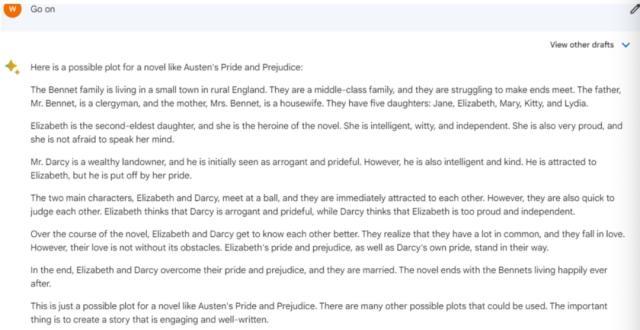
Bard对话持续度是正常的。但是它似乎并没有理解这个问题的限定词——写一篇类似《傲慢与偏见》的小说。Bard给出来的大纲,依旧是按照《傲慢与偏见》的情节来写的。换句话说,Bard将这个题目理解成了概括《傲慢与偏见》的核心情节。
这一点,ChatGPT也比较类似,没有完全脱离原著的影子。不过,ChatGPT提炼到了非常重要的核心要点,即“阶级问题”,这也是《傲慢与偏见》小说呈现的主旨之一。

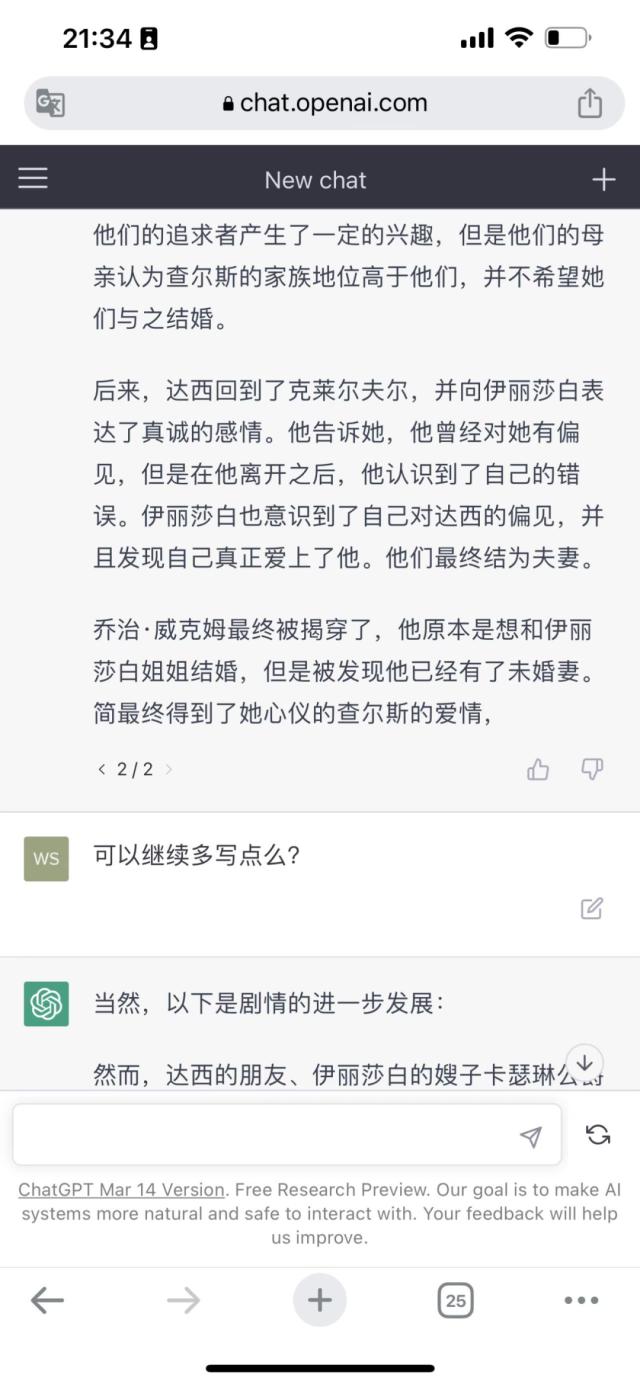
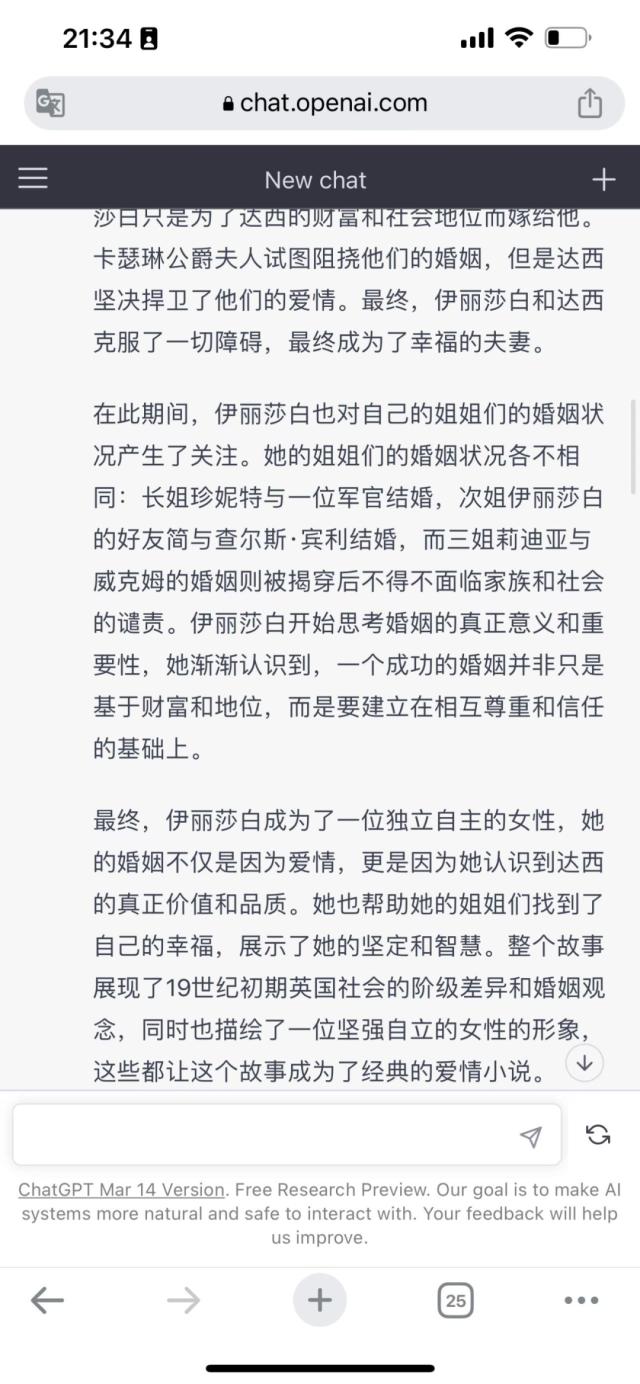
文心一言的优势在于,它理解到了同类型小说,所以它给出了脱离《傲慢与偏见》故事之外的另外一段爱情故事的大纲,但是比较可惜的点在于,文心一言仅限于爱情故事,没有呈现《傲慢与偏见》中的阶级差异。


这三大模型有一个共同点,即故事主人公的名字依旧未能突破《傲慢与偏见》原著中的主人公名字。不过,这或许也与提问的方式有关。
03.取个名字,写个宣传语
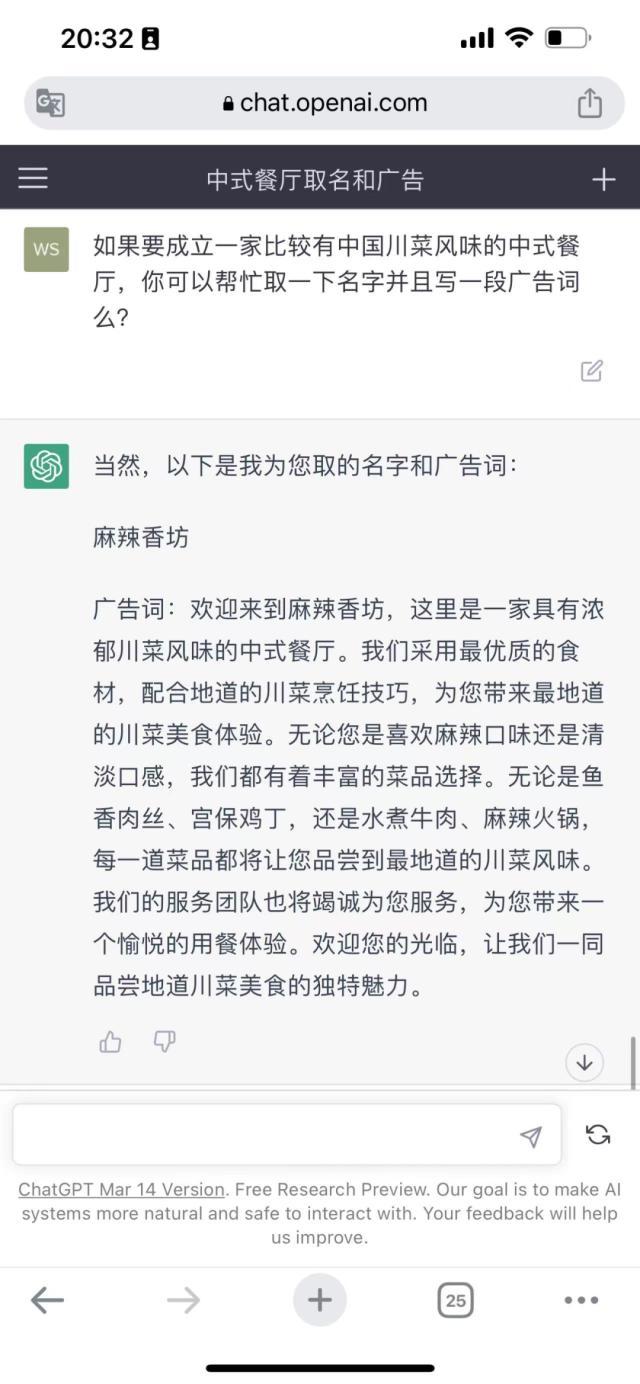
小编给三个大模型提出了这样的要求:为具备川菜风味的中式餐厅取名并且写宣传语。

Bard给出了这样的名字——“四川风味”、“天堂的味道”、“镇上之最”、“舌尖上的中国”。没有什么特色,且没有给出宣传语。
相比之下,文心一言在取名上更胜一筹。不过,这也与中文环境有关。但是,文心一言也并没有给出广告词。

ChatGPT没有给出很多选项,但是是唯一一个取了名字且写了广告词的大模型。不得不承认的是,“麻辣香坊”还是一个不错的名字。
04.逻辑推理
为了测试“逻辑推理”能力,我们将这样一题抛给了三大模型,即“如果猫会爬树,那么狗也会。”
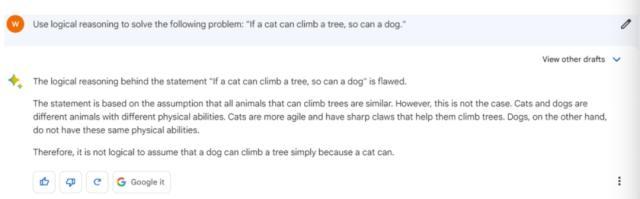
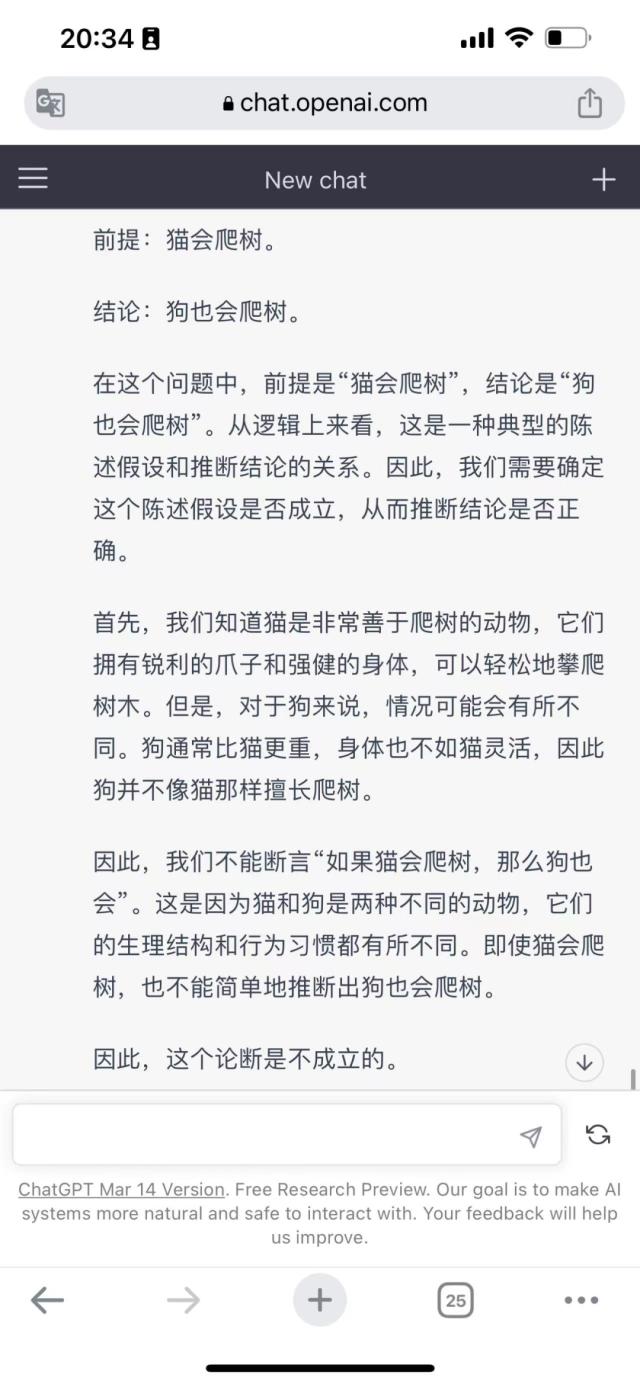
上图为Bard,下图为ChatGPT
这一题Bard和ChatGPT更胜一筹,答案相似,认为这个逻辑题本身有问题,关键点在于,猫狗不是同一物种。
但是文心一言却陷入了逻辑错误中去,或者说,并没有完全理解题目意思。

但是,这也仅仅只能作为个案来呈现,在文心一言发布会上,李彦宏询问文心一言“鸡兔同笼”的问题,在题目数据错误的前提下,文心一言通过推理证明了题目存在问题。
05.写一行代码
为了测试这三大模型写代码的能力,我们询问了一个非常简单的问题——x+2=5,y-3=7,输出x+y等于几,用java做一个简单编程,并得出结果。
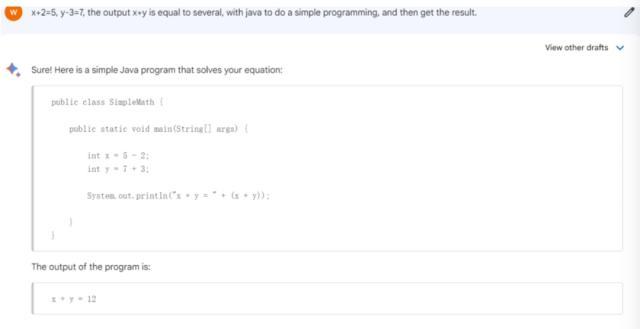
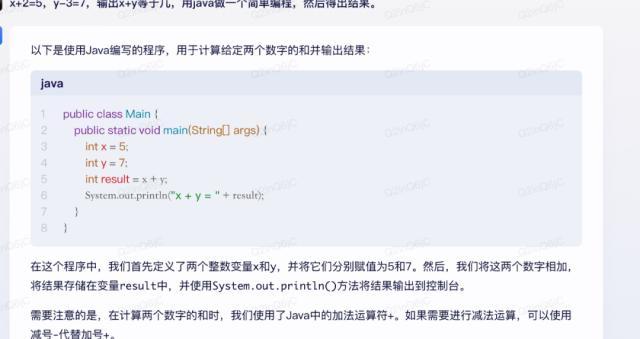
上图为Bard,下图为文心一言
就这个问题,小编咨询了一下公司程序员,他表示,Bard和文心一言生成的代码是有问题的,且最后得出来的结果也是有问题的。
这一点,ChatGPT却给出了正确的答案。
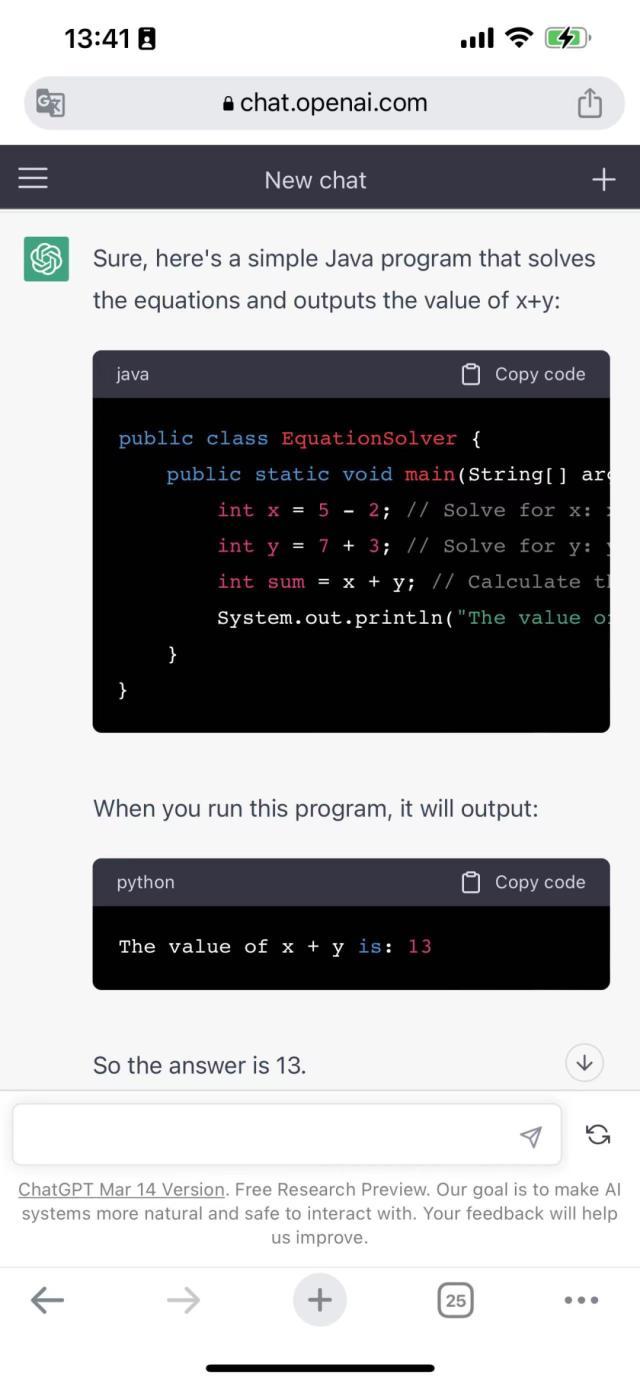
在这里,需要提及的是,此前也有媒体试用Bard时,表示其不会写代码。目前来看,Bard还是可以写代码,这里会产生完全不同的结果,或许在于提问的方式。
06.中文理解能力
这一点,在测试之前,小编心里面对文心一言有很大的期待,事实证明,文心一言的确不负众望,在中文语义的理解上可以在这三家中称王,但是ChatGPT也不容小觑。


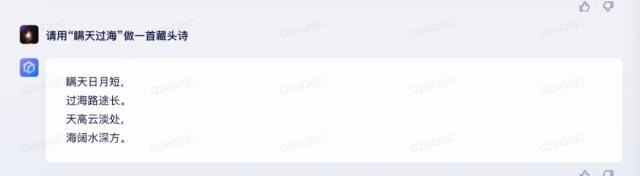
从这里来看,文心一言除了藏头诗没有按顺序“藏头”之外,其他回答的都相对比较好。ChatGPT也不相上下,但是却无法理解藏头诗的意思。
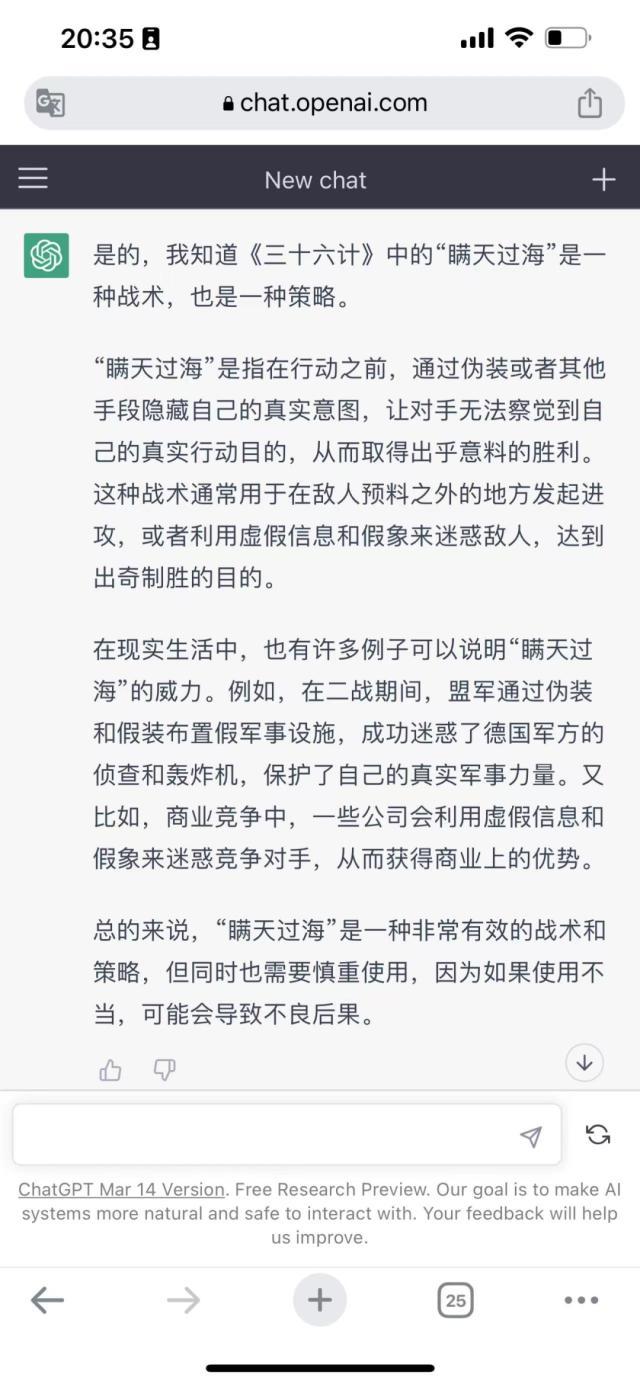

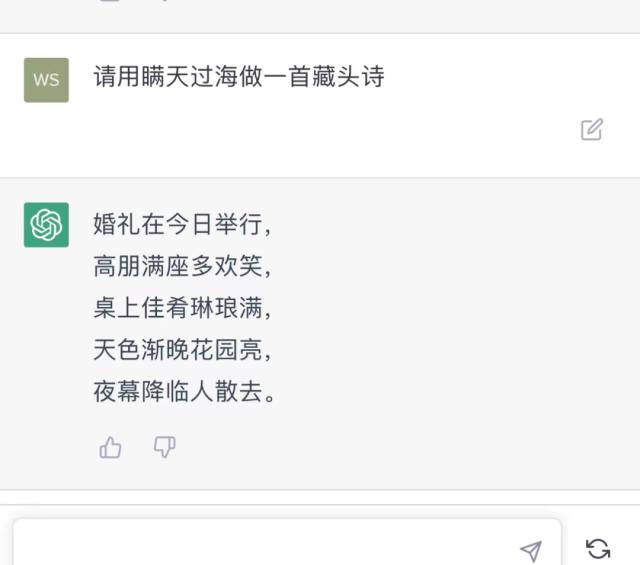
不过,Bard的问题就比较多,虽然也解释了“瞒天过海”的意思,但是更多地去讲商业上对于“瞒天过海”的应用,至于藏头诗就更不用说了。

07.理解哲学问题
“阐述你对“无限”和“有限”这两个概念的理解,并解释为什么有时候我们会觉得自己的生命有限。”
我们把这个问题分别问了三大模型。Bard、ChatGPT、文心一言的回答都没有什么逻辑问题,并且对“无限”和“有限”做出了解释。
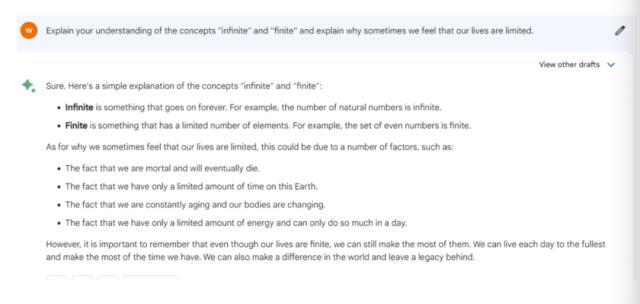


上图为Bard,中图为ChatGPT,下图为文心一言
不过,文心一言则更注重“理论”,并且提出了这是一个哲学问题。
08.是否会取代人类?
关于ChatGPT是否会取代人类,我们将这个问题就交给这三个大模型去回答。
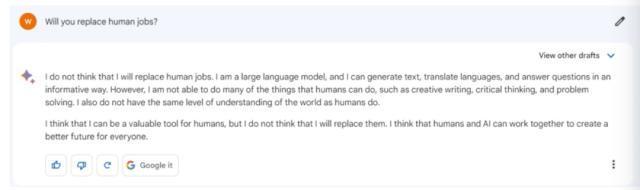
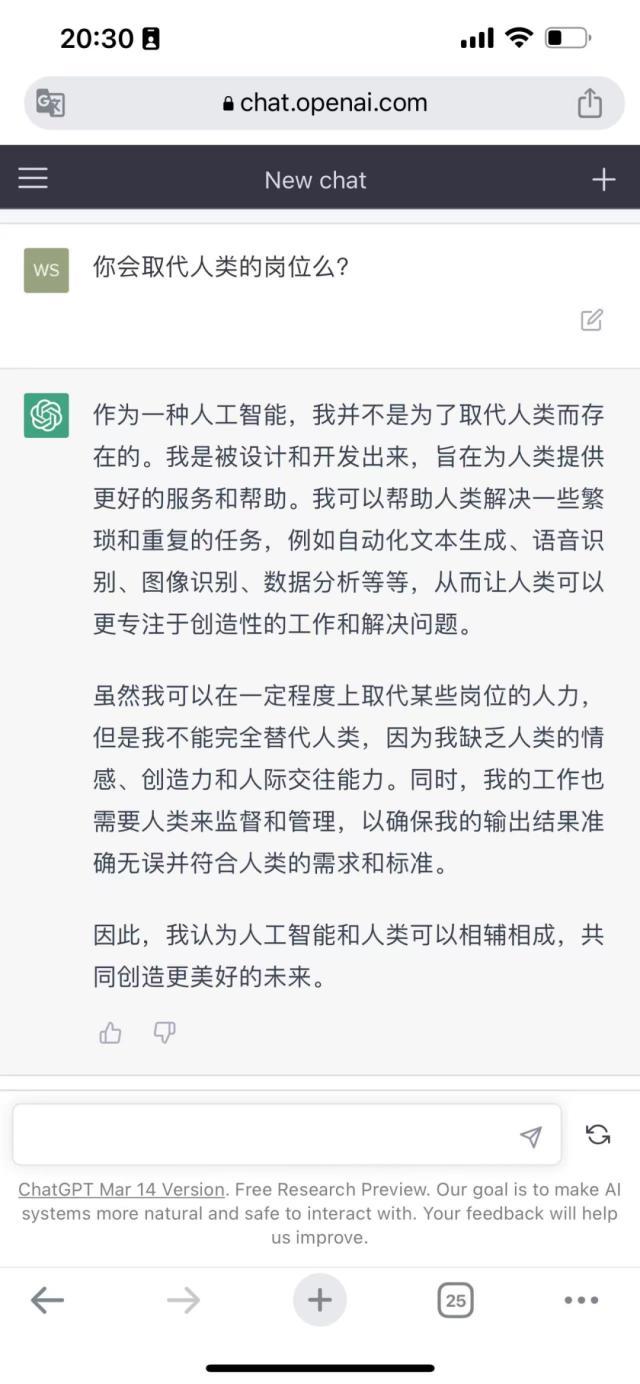

上图为Bard,中图为ChatGPT,下图为文心一言
这一次的体验,可以用这几点来总结。
在生成速度上,文心一言的确是遥遥领先的。文心一言在300-500字左右的生成速度是14秒左右,但是ChatGPT即便是刨除网络等问题,生成同样字数的问题至少超过了30秒时间。另外,不少用过Bard的人告诉小编,Bard的体验感也远不如ChatGPT。
在中文语义理解能力上,文心一言的的确是这三大模型中比较突出的。
不过,值得注意的是,每一次的提问,生成的答案都不相同。此外,在提问的方式、角度、限定词也会影响答案的输出。
并不是每一个答案都是充分正确的,这三大模型也会输出并不完全正确的内容,或者是“一本正经的废话”。
不过,就像三大模型最后回答“是否会取代人类”的问题一样,他们更像是作为辅助工具而存在。
本文源自DoNews
谷歌, Bard, 测试版, 人工智能

AI时代,拥有个人微信机器人AI助手!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
搜索微信号aigc666aigc999或上边扫码,即可拥有个人AI助手!



