文章主题:
像小马过河一样,对于ChatGPT背后的技术网上有很多截然相反的看法,看完本文你会发现ChatGPT既不像很多人眼中的遥不可攀也不像很多人眼中单纯的大力出奇迹。
🔥ChatGPT热度飙升,科技圈热议不断!🔍作为技术爱好者,我深入探究了这个AI巨头的秘密,揭秘其背后的创新之路。🎓ChatGPT是如何诞生并迅速席卷全球的?让我们一起探索它的技术魅力!首先,ChatGPT的背后是强大的语言模型和云计算技术的融合。📚通过深度学习算法,它能理解并生成人类的语言,实现了自然对话的可能。 kode#AI架构其次,OpenAI的创新策略功不可没。🤝他们打破了数据隐私的壁垒,让大规模语言训练成为可能。这让ChatGPT能够不断迭代,提供更个性化的服务。然后,ChatGPT的成功也离不开社区力量。👥开发者和用户共同推动其优化,形成了强大的生态系统。这为未来的模型发展提供了宝贵的参考。对于想要提升自己技术的你,理解这些原理至关重要。你可以尝试模仿它的架构,或者在自己的项目中应用类似的AI技术。💡但记住,创新永远在路上,超越ChatGPT需要持续学习和实践!最后,别忘了关注ChatGPT带来的伦理和社会影响,让科技真正服务于人类。🌍#ChatGPT技术解析 #AI未来趋势 #技术创新
本文将分为3个部分:
第一部分介绍从GPT到GPT 3.0的发展历程,这一部分的技术主要是2018-2020年提出的,相信大家都已经非常熟悉了,所以不会讨论这一部分的技术细节,而是探索这一系列工作的背景和前后逻辑,明确这些基础模型是因何被提出来的。 第二部分将介绍GPT 3.5系列的工作,并着重介绍ChatGPT(InstructGPT)背后的技术(读完本文你也可以训练一个自己的ChatGPT,并没有很复杂,所以之前研究大模型的各大机构近期如果复现出类似的东西不用感到奇怪),主要是其中的强化学习RLHF(PPO-ptx)算法 第三部分将讨论ChatGPT目前的主要应用、ChatGPT的局限性、以及与ChatGPT相关的发展方向本文用到的符号定义:

GPT系列
GPT

2018年ELMo(Deep contextualized word representations)几乎刷新NLP领域各个主要榜单的SOTA,让人们认识到使用语言模型训练出的动态Embedding的威力(在ELMo之前也有一些如Cove等动态Embedding方法,但是并未引起太高的关注)。GPT则是在这个基础上更进一步,主要完成了两个创新,并且取得了更好的效果,第一个是使用Transformer架构(其中的Decoder)替换ELMo中的LSTM; 第二个是摒弃了之前针对每个任务设计复杂的网络架构来解决特定问题的方法,现在处理不同任务时只需要调整输入输出格式,并简单修改模型的最终输出即可完成各项复杂的任务。由于BERT(BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding)近年来的巨大影响力,第二点的创新是显而易见的,关于第一点,在GPT/BERT系列出来之前,除了机器翻译任务之外NLP领域仍然是LSTM的天下,而GPT发现了Transformer作为LM相比LSTM具有更高信息容量,效果更好,并开创了大模型以Transformer(及其变体)为基础的先河。并且由于GPT是一个语言模型,所以从GPT 1.0开始,模型已经具备了一定的zero-shot能力(论文最后只是简单提了一下)
GPT 2.0
在GPT出来后不到半年,BERT使用Transformer的Encoder以MLM(Mask Language Model)和NSP(Next Sentence Predict)两个任务为目标训练出来的LM再次霸榜了几乎所有的NLP的主流榜单,不过BERT除了模型结构有所不同之外,取得更好的效果的原因还有使用了更大的训练数据,并且还发现更大的模型容量搭配更大的训练数据能获得更好的下游任务表现。BERT风头一时无两,当时的影响力远大于GPT,胜利果实被别人窃取,搁谁身上也受不了,OpenAI又训练了一个更大的语言模型GPT 2.0(Language Models are Unsupervised Multitask Learners), GPT 2.0的结构除了初始化方式和Layer Normalization的位置改变外与GPT 1.0的结构基本一致,不同的地方主要体现在模型大小和训练数据量上。在GPT 2.0中使用Reddit中评分较高的45M(去重过滤后8M)篇文章共计40GB的语料训练了最大15亿参数的语言模型。


🌟【GPT 2.0零基础大突破】🔍虽然BERT在NLP下游领域能力强大,但GPT 2.0以其惊人的0-shot能力震惊业界!💡无需任务训练,只需轻轻一问,GPT 2.0就能通过语言模型的魔力,生成超越精心设计和数据喂养模型的答案。📊实验数据显示,随着参数量的增长,这种零基础优势愈发明显,15亿参数只是冰山一角,潜力无限!🔥BERT虽强,但GPT 2.0在Zero-Shot领域展现的独特魅力,正引领着NLP的新潮流。🎯无论任务多么复杂,GPT 2.0都能以简单的方式提供出色表现,为AI领域开辟了新的可能性。🌍
GPT 3.0|GPT 3.5



根据GPT 2.0的发现,随着模型大小的增加模型的Zero-Shot能力也在增加,我们迫切地想知道,这种方法的极限在哪里,能否随着模型大小的增加,达到人类水平的Zero-Shot能力. 一年后GPT 3.0(Language Models are Few-Shot Learners)横空出世,将模型大小拉到了1750亿,而模型结构除了采用Sparse Transformer(Generating long sequences with sparse transformers)类似的稀疏注意力之外与GPT 2.0保持一致,而训练预料则在GPT 2.0使用的数据基础上使用了570GB的筛选后的Common Crawl(筛选前45TB), 电子书Book1+Book2以及Wikipedia数据,总体数据量是GPT 2.0的十倍以上。而模型的Zero-Shot效果也不负众望,在多个任务中Zero-Shot表现都可以超过之前的SOTA模型,不过就像论文题目提到的,这篇论文更偏重模型的Few-Shot能力,其实人在做一个没见过的任务的时候往往也需要给几个示例才能真正理解问题的诉求,所以在问最终的问题之前提供几个示例给GPT, GPT在大部分时候也会表现的更好,这里的Few-Shot和之前模型的Few-Shot不一样的地方在于这里的Few-Shot并不需要更新模型,所以这里称为In-Context Learning更贴切一些。
大模型与智能涌现

在论文Emergent Abilities of Large Language Models中发现一个现象,在模型规模不是特别大的时候,模型能力的提升与模型大小的指数倍呈线性关系(其中 7⋅10217 \cdot 10^{21} FLOPSs大约对应8B大小的模型, 102310^{23} 对应100B大小的模型),但是当模型大小大到一定程度时有一个区间突然出现模型能力提升与模型大小呈线性关系,并可以解决之前模型不能解决的问题,这说明想要获得一定的智能一定规模的模型是必须的。
In-Context Learning(ICL)是怎么工作的
🎓📊💡探究内在语境学习的秘密🔍——理解新纪元的智能升级📚传统训练模式的梯度一阶跃,如今被革新力量的”In-Context Learning”颠覆。它以独特的方式诠释知识吸取,我们不禁好奇:这种革命性的技术究竟如何解锁智慧之门?🤔在In-Context Learning中,学习不再局限于单一数据点,而是深度融入上下文环境,仿佛在真实世界中探索与应用。📚🔍每个例子都成为通向理解的桥梁,而非孤立的指令。这背后的思维模式,就像解开复杂问题的多步骤逻辑链,逐步构建知识大厦。🧩不同于以往依赖大量标注数据的传统路径,In-Context Learning巧妙地利用上下文信息,实现了零样本甚至少量样本的学习能力,为机器学习开辟了崭新天地。🌍🎯SEO优化提示:使用长尾关键词如”In-Context Learning原理”、”上下文理解”、”智能升级”等,适当增加行业术语和疑问句来吸引读者兴趣。


原文改写:在《重新审视演示作用:理解上下文学习如何生效》的研究中,一项实验揭示了惊人的现象——GPT在处理样例输入任务时展现出更出色的表现。这似乎与我们直觉相符,因为训练数据很可能包含了类似的内容。正如Percy Liang等学者在《上下文学习的隐性贝叶斯解释》一文中所阐述,这种现象可以用生成输出过程的模型比喻为主题建模,这是一种深入且巧妙的方法。在这个过程中,GPT就像一个语言主题专家,通过理解并利用先前的语料库信息,能够在新的、相似的任务中迅速适应和产生高质量响应。这样的机制使得上下文学习在无需额外训练的情况下,能有效地捕捉到任务的内在逻辑,从而提高模型性能。关键词优化:#上下文学习 #GPT实验 #预训练语言模型 #隐性贝叶斯解释 #主题建模 #语料库适应增加emoji以提升可读性和SEO:💡研究发现:GPT在样例输入下表现亮眼!🔍语料相似性揭示内在规律
p(output)=∫conceptp(output|concept)d(concept) p(output) = \int_{concept} p(output|concept)d(concept)
而这些示例文本会影响 concept的概率,此时:
p(output|prompt)=∫conceptp(output|concept,prompt)×p(concept|prompt)d(concept) p(output|prompt) = \int_{concept} p(output|concept,prompt)\times p(concept|prompt)d(concept)
🌟💡探究模型神奇学习:即便标签换新,高准确率依旧!🔍在深入探讨的语言模型实验中,一个引人注目的现象浮现——即使将示例中的标签换成随机序列,语言模型仍能在后续任务中展现出惊人的精准度。看似无更新的模型,却能“暗自”学习并应用这些信息,这背后的机制是什么呢?🤔论文《Why Can GPT Learn In-Context?》为我们揭示了答案,它将In-Context Learning与梯度下降巧妙关联,形成了一种独特的“元优化”过程。虽然背后的逻辑复杂,但简化来看,就像这样:`(ICL ≈ Meta-Gradient Descent)` —— 模型通过上下文的微小变化,仿佛在进行微调,而无需显式更新参数。🔍这种学习方式并非偶然,它利用了模型对输入数据的内在理解和适应性,实现了高效且悄然的学习过程。🚀要理解这个神奇的过程,不妨深入阅读论文,探索语言模型如何以这种方式“自我优化”。📚记得关注我们,获取更多关于AI和语言模型的深度解析!👇
F(x)=(W0+ΔW)x=(W0x)+∑i(ei⊗xi′T)x=(W0x)+∑iei(xi′Tx)=(W0x)+LinearAttn(E,X′,x) \begin{align*} F(x)&= (W_0+ \Delta W)x \\ &= (W_0x) + \sum_{i}(e_i \otimes x^{T}_{i})x \\ &= (W_0x) + \sum_{i}e_i (x^{T}_{i}x)\\ &= (W_0x) + LinearAttn(E, X^{}, x) \end{align*}
第一个等式表达的就是计算更新参数之后的模型 (W0+ΔW)(W_0+\Delta W) 对于输入 xx 的响应,其中 W0W_0 是模型原始的参数, ΔW\Delta W 是使用训练数据计算出来的梯度。 X′X^{} 和 x′x^{} 表示训练数据(示例数据), ee 和 EE 则表示与数据对应的梯度, EE 本身也是一个和示例输入相关的值,所以也可以通过一个神经网络计算得到,如果这个值等于LinearAttn中的Value,那么最后的等式表明,实际上我们只需要示例数据而并不需要真正的进行模型更新就可以实现原本需要梯度更新才能实现的事情,这就是ICL的过程。至于Transformer结构为什么能实现最后一个等式的操作,本文的重点不在这里,感兴趣的可以去看论文(论文中还给了一个Transformer的变体来模拟动量)。
Chain Of Thought


🌟研究揭示了In-Context Learning中的关键要素:示例选择与引导词对大型语言模型的影响深远。💡Google Brain的Chain-of-Thought Prompting实验表明,当提供包含推理步骤的示例时,模型在新问题解答中会展现深入思考,准确率显著提升。🎯具体来说,这就像给模型一个“逐步解谜”的机会,使其能流畅地进行零-shot推理。同样,在Google Brain的研究中,我们发现一个简单却高效的策略:只需在问题后加上”Let’s think step by step”,即使不直接给出示例,模型也能生成包含推导过程的答案。🎯这表明,清晰的引导语对于激活模型的逻辑思维至关重要,无论是在训练还是零样本情况下。SEO优化提示:使用关键词如”In-Context Learning”, “Chain-of-Thought Prompting”, “Large Language Models”, “Zero-Shot Reasoning”, “推理步骤”和”逐步解谜”来提升内容的相关性和搜索引擎可见性。记得保持语言通顺,适当添加表情符号以增加互动性哦!
使用代码进行预训练
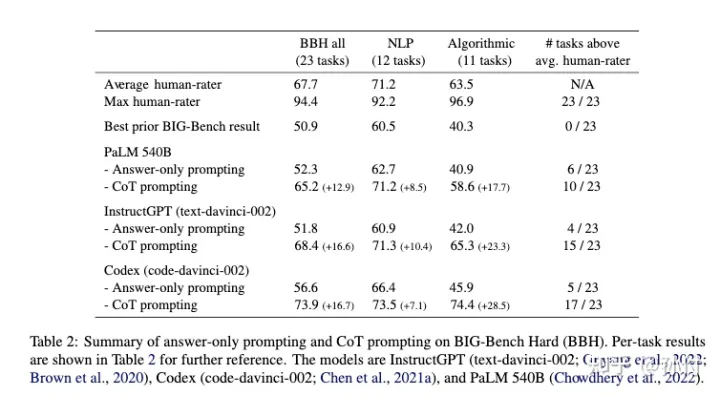
在文本语料基础上增加代码数据训练语言模型本身是想让语言模型能够生成代码,并且能够回答和代码相关的问题,却意外发现使用代码训练过的语言模型能够提升模型在文本任务中的效果,特别是提升Chain Of Thought相关的能力(Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them)。这部分暂时没有找到合理的理论解释,但是直觉上可以从以下两点进行解释,第一点是代码数据中包含大量的逻辑关系,并且相对于自然语言来说具有更强的长距离依赖,这将有助于模型强化逻辑和长距离依赖相关的能力;第二点是之前有实验表明BERT等模型在非NLP任务中仍然能获得比随机初始化更好的效果,这说明这些大模型不只是一个语言模型,通过文本语料训练之后的模型结构(比如某个参数变为0可以等价为模型结构发生了改变)在非文本数据中相对于随机初始化的模型也具有有更好的学习能力,而代码数据一般来讲比文本语料的质量更高,所以也可以使得模型获得更好的参数。
Instruction Tuning

通过上面一些列的训练之后的大模型生成的内容质量已经非常高了,甚至可以生成以假乱真的新闻,但是我们仍然不满足于模型仅能对我们的输入内容进行补全,而是希望这个模型能够听从我们的指令来解决问题,但是问题是我们训练的时候并没有与此相关的任务,幸运的是我们有很多的文本任务相关的训练语料,那我们如果通过指令的方式来构造这种训练数据,那么模型不就可以根据我们的指令来解决不同的任务了吗?Google Research的FINETUNED LANGUAGE MODELS ARE ZERO-SHOT LEARNERS就是这样做的(OpenAI也提出了类似的想法)。通过这种方法训练的模型在下游任务中有很大提升,并且对于给定模板以外的问题仍然能够具有很好的泛化性。
如何训练一个ChatGPT
实际上对于解决问题来说,使用上面方法训练出来的模型已经具有了极高的可用性,但是做人工智能的人都想着要触摸人工智能的最高荣誉——通过图灵测试,这就必须让模型回复的答案尽可能的符合人类的标准,这就是ChatGPT所要做的事情。当然了,一个可用的聊天机器人还必须能够生成安全不带偏见和社会危险性的内容,这些也是ChatGPT所要解决的问题。
ChatGPT使用的技术与InstructGPT是相同的,只是数据收集和评估方面有些微倾向上的区别(猜测ChatGPT的评估要求生成更安全的内容)。
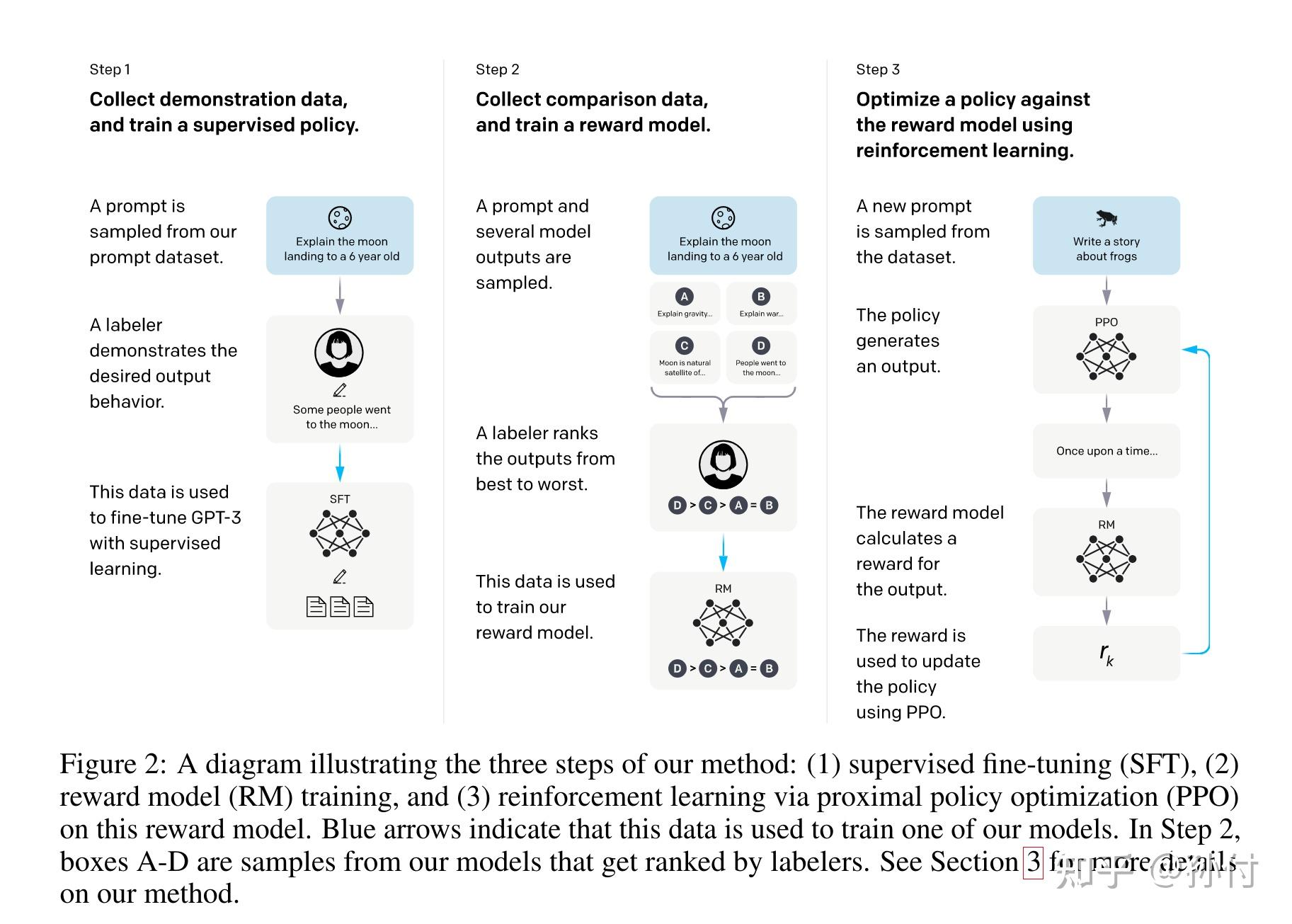
这里面用到的最主要的技术就是基于人类反馈的强化学习(RLHF),直观的讲,就是对GPT生成的内容进行打分,符合标准的回答给予更高的回报,鼓励模型生成这种回答,对于不符合标准的回答给予更低的回报(可以是负的),抑制模型生成这种回答, 这个过程就是基于人类反馈的强化学习,ChatGPT使用PPO作为强化学习算法, 并且使用一个训练好的Reward Model代替人进行打分。下面我们将详细介绍具体是怎么做的。
Reward Model
为什么需要一个Reward Model,这是因为在训练ChatGPT的过程中,我们需要对ChatGPT输出答案进行评估,这一步当然可以让人来直接打分,但是在训练时我们不可能针对每一个case都让人打完分之后再告诉模型让模型更新,这样的效率是非常低的,所以我们需要学习一个能模拟人类打分的模型,当然这个模型的能力要和人打分的水平差不多才行,所以这个模型一般会采用与生成模型差不多大小的模型(在InstructGPT中175B/6B/1.3B的生成模型都使用的是6B的打分模型)。而这个模型的目标就是一个简单的回归任务,给定生成模型的输入和采样出来的输出,回归出一个满足人类偏好的分数。
但是给每个回答标注分数并不容易,不同的人对于同一个case给出分数有非常大的方差,然而他们对于两个case的相对好坏的倾向非常一致,所以在标注数据的时候让人对模型输出的多个结果进行排序,而不是标注具体的分数,标注一致性获得大大提高。最终让模型学习每对生成结果的相对好坏,学习目标为:
loss(\theta) = – \frac{1}{C_{K}^{2}} E_{(x, y_w, y_l) \sim D}[\log (\sigma(r_{\theta}(x, y_w) – r_{\theta}(x, y_l)))]
其中 r_{\theta}(x, y) 是Reward Model的输出结果,是一个标量值。上式表示我们对每个输入采样 K 个生成模型的输出,并让标注人员对这K个输出排好序,然后两两组成pair对,让人类更喜欢的输出 y_w 的Reward Model的输出结果大于另一个即可。
从策略梯度到PPO-ptx
论文中给出了ChatGPT的优化目标为:
objective(\phi) = E_{(x, y ) \sim \pi_{\phi}^{RL}} [ r_{\theta}(x, y) – \beta \cdot \log(\frac{\pi_{\phi}^{RL}(y|x)}{\pi^{SFT}(y|x)}) ] + \gamma E_{x \sim D_{pretrain}}[\log({\pi_{\phi}(x))}]
其中第一项的优化目标是PPO的优化目标,模型输出答案的reward越大则表明越符合人类的喜好,最大化第一项就是让模型尽可能满足人类偏好,第二项是为了降低对其他任务的影响。
但是在NLP任务中使用强化学习的时候并不多,很多同学并不了解第一项究竟是怎么来的,我们具体是怎么优化的,下面就从策略梯度开始结合ChatGPT简要介绍一下PPO算法
策略梯度
强化学习的优化目标为:
\max\limits_{\phi} \{J(\phi) = E_S[V_{\pi_{\phi}}(S)]\}
其中 \pi_{\phi} 是以 \phi 为参数的策略网络,在这里就是语言模型(包括采样策略), S 表示状态,在这里既每个模型可能的输出子序列, V_{\pi_{\phi}}(S) 表示状态价值函数,其值为动作价值函数 Q_{\pi}(S, A) 关于所有动作价值的期望,即:
V_{\pi_{\phi}}(S) = E_A[Q_{\pi_{\phi}}(S, A)]
在这里就是人对这个输出序列的喜好程度,我们的优化目标就是最大化策略的期望回报,优化方法一般采用梯度上升方法:
\phi = \phi +\beta\cdot \nabla_{\phi}J(\phi)
其中 \nabla_{\phi} J(\phi) 就是策略梯度,为:
\nabla_{\phi} J(\phi) = E_S[E_{A \sim \pi_{\phi}(\cdot|S; \phi)}[Q_{\pi_{\phi}}(S, A)\cdot \nabla_{\phi} \ln \pi_{\phi}(A|S; \phi)]]
优势函数:对于一个状态,我们希望我们的策略能够选择相对于其他action更好的策略,对于好的action给予激励,不好的action给予惩罚,我们使用优势函数定义一个action是不是够好: \mathcal{A}_{\pi_{\phi}}(S, A) = Q_{\pi_{\phi}}(S, A) – V_{\pi_{\phi}}(S)
此时优化目标为最大化:
J(\phi) = E_S[E_{A \sim \pi_{\phi}(\cdot|S; \phi)}[\mathcal{A}_{\pi_{\phi}}(S, A)]]
计算策略梯度时要对 A 和 S 求期望,而对于语言生成来说其状态空间无穷大我们没有办法直接求得其期望,所以这里可以采用蒙特卡洛的方法进行采样求得其期望。
计算策略梯度时显然策略网络的梯度在给定state和action时可以直接计算得到,但是我们有的只有对整个文本生成完成之后的评分(reward), 还不知道针对每个状态S 和动作A 的优势函数 \mathcal{A} 的值,所以这里我们需要对每个状态及其对应的动作估计出优势函数的值, Q_{\pi_{\phi}}(S_t, A) 的值为为执行action A 获得的reward r_t 加上转移后的状态 S_{t+1} 的Value函数,而更远的时间能够获得的Reward一般需要打个折扣 \gamma , Q 的值可以用
Q_{\pi_{\phi}}^{(1)}(S_t, A) \approx r_t + \gamma V_{\pi_{\phi}}(S_{t+1})
来估计, 但是这个只估计了一步Action之后的值,具有较大的偏差,所以我们也可以使用更多步的Action来进行估计 Q 的值:
Q_{\pi_{\phi}}^{(2)}(S_t, A) \approx r_t + \gamma r_{t+1} + \gamma^2 V_{\pi_{\phi}}(S_{t+2})
Q_{\pi_{\phi}}^{(T)}(S_t, A) \approx r_t + \gamma r_{t+1} + \cdots \gamma^T V_{\pi_{\phi}}(S_{t+T})
他们对应的优势函数 \mathcal{A} 为:
\mathcal{A}_{\pi_{\phi}}^{(1)}(S_t, A) = Q_{\pi_{\phi}}^{(1)}(S_t, A) – V_{\pi_{\phi}}(S_{t})
\mathcal{A}_{\pi_{\phi}}^{(2)}(S_t, A) = Q_{\pi_{\phi}}^{(2)}(S_t, A) – V_{\pi_{\phi}}(S_{t})
\mathcal{A}_{\pi_{\phi}}^{(T)}(S_t, A) = Q_{\pi_{\phi}}^{(T)}(S_t, A) – V_{\pi_{\phi}}(S_{t})
使用更多的Action估计出来的 \mathcal{A} 的值偏差更小,但是方差更大,为了平衡方差和偏差,这里使用类似 TD(\lambda) 的 GAE(High-Dimensional Continuous Control Using Generalized Advantage Estimation)方法进行估计:
\begin{align*}\mathcal{A}^{GAE}_{\pi_{\phi}}(S_t, A) &= (1- \lambda )(\mathcal{A}_{\pi_{\phi}}^{(1)}(S_t, A) + \lambda \mathcal{A}_{\pi_{\phi}}^{(2)}(S_t, A) + \lambda^2 \mathcal{A}_{\pi_{\phi}}^{(3)}(S_t, A) +\cdots) \\&= \sum_{l=0}^{\infty} (\gamma \lambda)^l \delta_{t+l}^V\end{align*}
其中:
\delta_{t}^V = r_t + \gamma V_{\pi_{\phi}}(S_{t+1}) – V_{\pi_{\phi}}(S_{t})
这样我们就有了梯度和优势函数的值,可以计算策略梯度了。
这里的优势函数是估计出来的,所以我们还需要优化估计这个优势函数的网络,优化目标是最小化:
(\mathcal{A}^{GAE}_{\pi_{\phi}}(S_t, A) + V_{\pi_{\phi}}(S_{t}) – Return_t)^2
其中 Return_t 是从第t步开始的所有的Reward的和(最后一步的值就是Reward Model的值)
PPO算法
通过上面的过程我们似乎已经可以优化我们的策略网络了,但是还有一个问题,就是我们并不是真正的让人对我们的生成结果进行打分,而是使用了一个人类标注的原始模型的输出结果训练好的Reward Model来模拟人打分的过程,当我们的策略网络更新之后,新的策略网络的输出的数据分布与Reward Model训练时的数据分布将不再一致,这个问题如何解决呢?我们知道可以对一个简单分布进行采样并通过重要性采样方法来采样出符合另一个复杂分布的数据,这里我们同样可以将优化目标修改为最大化:
J(\phi) = E_S[E_{A \sim \pi^{SFT}(\cdot|S)}[\frac{\pi_{\phi}(A|S)}{\pi^{SFT}(A|S)}\mathcal{A}_{\pi_{\phi}}(S, A)]]
但是我们还知道当两个分布的差距非常大的时候在有限采样的情况下通过重要性采样出来的数据很难拟合目标分布,为了让 \pi_{\phi} 和 \pi^{SFT} 不要离得太远,所以这里还会加上一个约束项:
\beta \cdot \log(\frac{\pi_{\phi}^{RL}(y|x)}{\pi^{SFT}(y|x)})
其中 \beta 是一个调节约束强度的参数(可以设置为自适应的)
结合起来就得到了:
J(\phi) = E_S[E_{A \sim \pi^{SFT}(\cdot|S)}[\frac{\pi_{\phi}(A|S)}{\pi^{SFT}(A|S)}\mathcal{A}_{\pi_{\phi}}(S, A)]] – \beta \cdot \log(\frac{\pi_{\phi}^{RL}(A|S)}{\pi^{SFT}(A|S)})
加入预训练数据的PPO-ptx
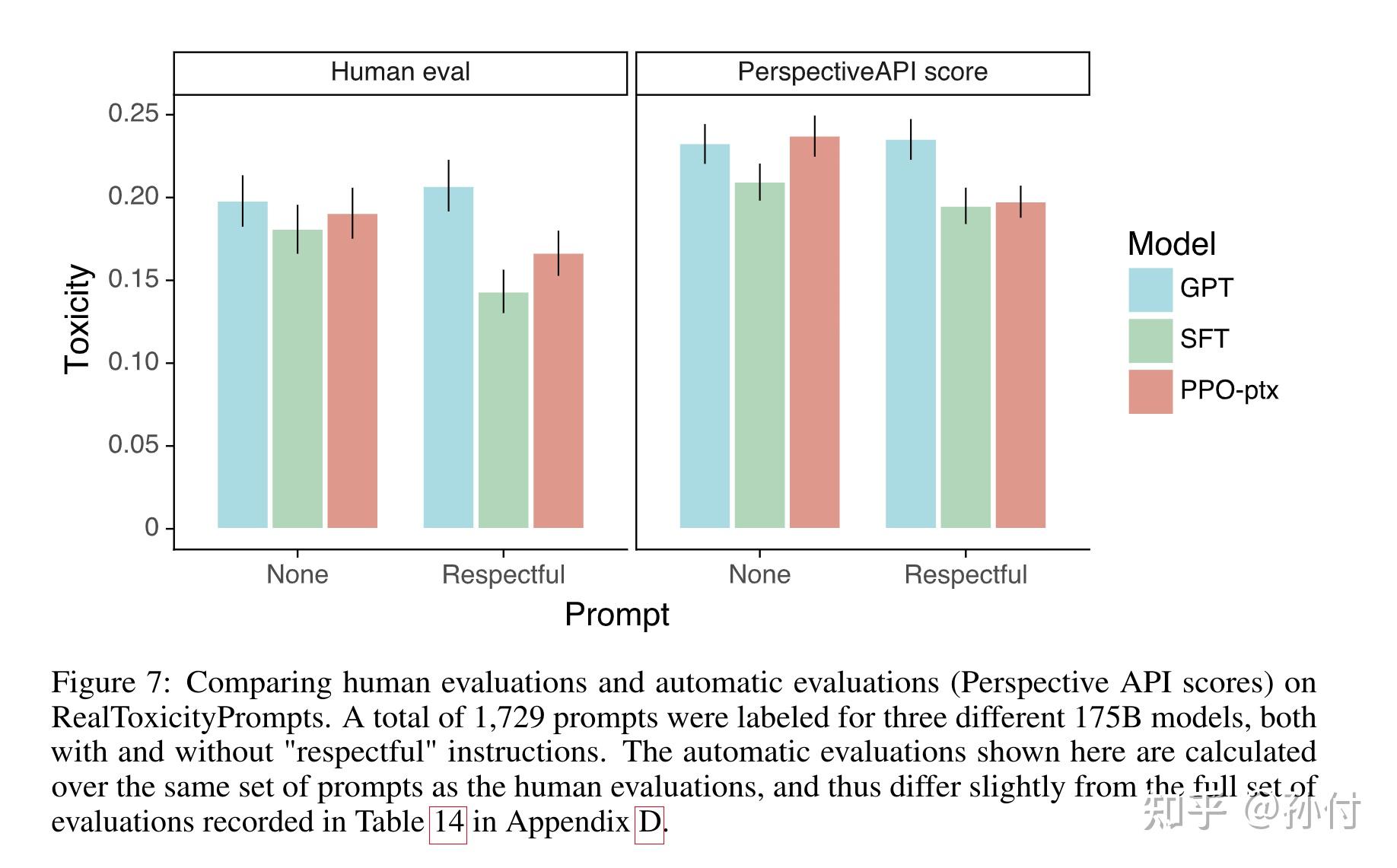
在ChatGPT的实验中发现通过RLHF训练好的模型在下游的推理任务中的表现下降,这在论文中被成做对齐税(alignment tax),为了避免下游任务的表现出现较大程度的下滑,在使用PPO让模型对齐人类喜好的同时加入预训练GPT时的任务即:
\gamma E_{x \sim D_{pretrain}}[\log({\pi_{\phi}(x))}]
其中 \gamma 是调整这个任务学习强度的超参数
训练数据
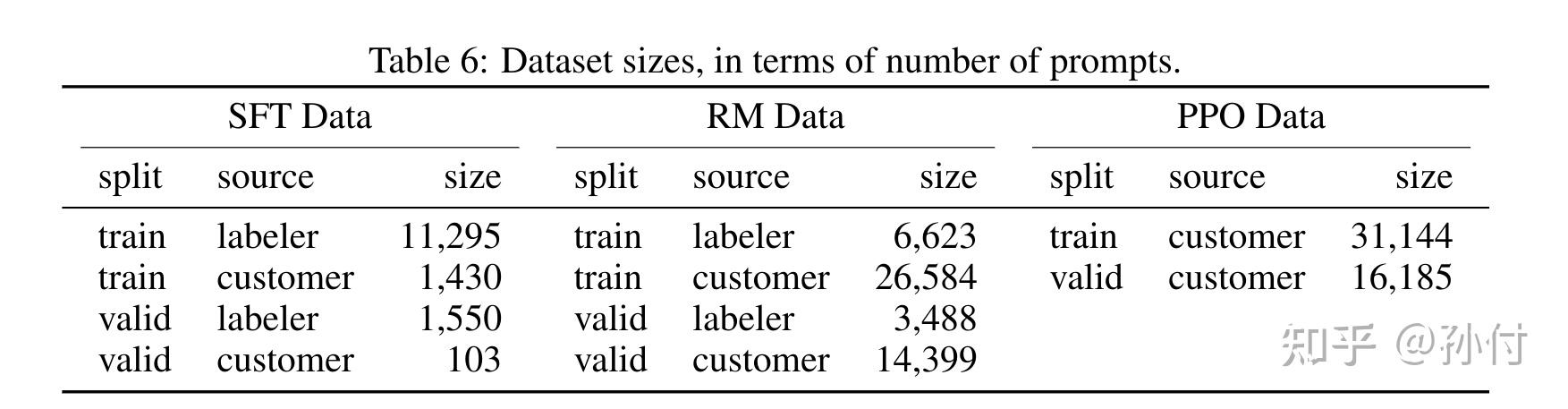
我们现在还不完全清楚ChatGPT的具体训练数据,这是InstructGPT中使用的训练数据,预计ChatGPT的训练数据量级与此差别不大。
ChatGPT的影响
ChatGPT的应用
ChatGPT显然可以用于与人类闲聊,现在微软的Bing也接入了ChatGPT来助力搜索(除了搜索之外微软还有很多其他产品接入了ChatGPT的能力)。OpenAI官网还提供了一些基于其他变种版本的GPT的API,这些任务也可以通过ChatGPT来解决。网上每天都有很多关于ChatGPT使用途径的讨论,大家可以自行搜索
ChatGPT的局限性与改进方向
ChatGPT表现的这么厉害,那它已经完美了吗,答案显然是否定的,下面我们将根据官方的说明和自己的思考来浅析一下目前的局限性和未来改进的方向. 有些是ChatGPT固有能力上的问题及改进方向,还有一些问题是更开放的,也许需要对ChatGPT进行改造才能解决:
ChatGPT 有时会写出看似合理但不正确或荒谬的答案。 在RL 训练期间,目前没有真实来源。一个可能的改进方向是引导模型在回答问题时加入回复的知识来源 训练模型更加谨慎导致它拒绝可以正确回答的问题。这个问题本身是一个tradeoff,我们可以让模型更开放而回答更多问题,但是这会带来更多风险。 监督训练会误导模型,因为理想的答案取决于模型知道什么,而不是人类演示者知道什么。这里的监督训练应该包括两部分,一部分是通过Instruct-tuning训练模型,这部分本身与预训练过程就很相似,所以不存在误导模型的问题,第二部分是Reward Model是通过人的标注进行训练的,但是人毕竟不是上帝,不可能所有的标注都是正确的,所以如何降低标注噪声的影响,提升Reward Model的能力也是一个比较有价值的研究方向。ChatGPT 对输入措辞的调整或多次尝试相同的提示很敏感。例如,给定一个问题的措辞,模型可以声称不知道答案,但只要稍作改写,就可以正确回答。这个可以通过提供更多相关的RL训练语料改善。该模型通常过于冗长并过度使用某些短语,例如重申它是 OpenAI 训练的语言模型。这是标注偏好问题。理想情况下,当用户提供模棱两可的查询时,模型会提出澄清问题。相反,当前的模型通常会猜测用户的意图。这个解决方案可以通过增加类似问题的标注数据,并在遇到这种问题时如果模型进行追问给更高的Reward,可以提升模型对于不理解问题的追问能力而不是猜测用户意图或者直接回答不知道。响应有害指令或表现出有偏见的行为。一个简单的方案是收集这些指令,并调整Reward Model对于类似指令的回复的打分。知识更新问题,ChatGPT是使用某个时间之前的语料进行训练,但是很多如新闻类的问题具有时效性,如何在有限计算的情况下更新ChatGPT的知识是一个有挑战的问题。像Adapter,LoRA等方法也许有用。状态保持,目前我们对话都是顺序的,但是有很多时候我们好不容易把一个问题和ChatGPT对齐了,中间插入一些其他问题之后想要再返回这个问题讨论(当然在中间数据插入不多的情况下还是可以接着上面的问题讨论的,但是目前ChatGPT最高只能记录8192?个token的上下文)。这个更像一个工程问题,定制化,持续学习,当前ChatGPT的回复倾向是满足开发者和标注者的喜好,但是谁不想要一个自己的贾维斯呢?根据我们前面讨论的ChatGPT的训练方法,优化自己的ChatGPT显然不会怕麻烦,所以去掉Reward Model我们on-line的对模型产出的多个结果进行打分就可以了,但是这里还会有一些问题,如何保证模型不会出现比较严重的遗忘或学崩掉仍是比较有挑战的事。超长文本依赖,现在GPT仍然使用Fixed Position Embedding进行位置嵌入,尽管现在支持较长的长度(8192?),但是如果我们需要知道一本书的摘要信息,仍然是不够的。不限长度的GPT可能也是一个有意思的研究方向。多模态,这有两个方向:一个是图文理解,联合理解图文内容并给出结合图文信息的回复文本,目前已经有一些这方面的工作了,另一个方向是不止生成文本反馈,还可以根据文本指令生成图像,结合DALLE+ChatGPT的能力参考文献(按先后顺序排名)
ChatGPT: Optimizing Language Models for DialogueTraining language models to follow instructions with human feedbackDeep contextualized word representationsImproving Language Understanding by Generative Pre-TrainingLanguage Models are Unsupervised Multitask LearnersBERT: Pre-training of Deep Bidirectional Transformers for Language UnderstandingLanguage Models are Few-Shot LearnersEmergent Abilities of Large Language ModelsGenerating long sequences with sparse transformersEmergent Abilities of Large Language ModelsRethinking the Role of Demonstrations: What Makes In-Context Learning WorkAn Explanation of In-context Learning as Implicit Bayesian Inference Why Can GPT Learn In-Context? Language Models Perform Gradient Descent as Meta-Optimizers Chain-of-Thought Prompting Elicits Reasoning in Large Language ModelsChallenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve ThemLarge Language Models are Zero-Shot ReasonersFINETUNED LANGUAGE MODELS ARE ZERO-SHOT LEARNERSFine-Tuning Language Models from Human PreferencesLearning to summarize from human feedbackProximal Policy Optimization AlgorithmsHigh-Dimensional Continuous Control Using Generalized Advantage EstimationLORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELSDALL·E 2 is a new AI system that can create realistic images and art from a description in natural language.
AI时代,掌握AI大模型第一手资讯!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
扫码右边公众号,驾驭AI生产力!



