文章主题:ProGen, functional protein sequences, diverse families, natural language generation model
撰者:吴炜坤
引言
🌟在蛋白质工程领域,创新的设计工具正在引领革命性的变革!传统的力量如物理势能驱动的单点或多点突变策略和自然共进的全局重设计,虽已硕果累累。但现在,AI与深度学习的联姻正释放出强大的潜力,比如ProGen/2和ProtGPT2等预训练模型,它们通过分析海量非对齐序列,揭示家族特征并生成高度自由的蛋白质序列。就像ProtGPT2那样,它在探索蛋白相空间未知领域的能力令人惊叹,为蛋白工程开辟了新的可能。随着ChatGPT在全球范围内引发热议,生物领域的AI序列模型也迎来了前所未有的关注热潮。专业人士和研究者们正满怀期待地注视着这些模型的未来性能,期待它们能带来蛋白质设计的新突破!🔥
🌟揭示Nature最新科研动态!🚀探索ProGen背后蛋白质序列秘密💪🔥Nature杂志重磅发布!🔥研究焦点转向ProGen,一款引领语言模型技术革新的力作!🔍通过ProGen,科学家们正跨越家族界限,生成前所未有的功能性蛋白序列,开启生命科学的新篇章!🔬🔍深入了解这项突破性工作,让我们一起解析Nature上的这篇深度解析——《ProGen:大型语言模型重塑蛋白质多样性》。📝论文揭示了如何利用人工智能的力量,精准预测并合成这些关键蛋白质,为疾病治疗和药物研发带来了革命性的可能。👩🔬👨💻🔍注意!这里没有作者信息,也不包含任何联系方式,纯粹是专业知识的分享。📚如果你对ProGen的创新技术或其对未来科学的影响感兴趣,不妨深入研究这篇Nature文章,它将引领你进入蛋白质设计与生物学的新纪元。🚀#Nature研究 #ProGen #功能性蛋白 #语言模型 #生命科学前沿

ProGen的工作原理?
🌟🚀ProGen模型,AI语言新纪元🌟🚀 – 通过条件标签驱动的自然语言魔法💡,在NLP世界中只需轻轻一点,输入关键词,模型就能巧手编织出逻辑连贯、含义丰富的句子。想象一下,将蛋白质序列比作语句,我们就像用功能标签和属性的标签牌,唤起它生成多样且功能强大的序列。批量生产不再是梦!🚀💪 #ProGen模型 #自然语言生成 #蛋白质序列优化
🌟ProGen训练”data”源于&Pfam蛋白质宝库,它的人工标签丰富,海量蛋白序列得以精准分类到特定家族中,如物种标签、种类标识及生物催化功能等详细注释。🚀AI模型通过2.8亿自然序列的大规模预训练,巧妙地将序列与功能关联起来,提取出独特的家族特征。相较于以往,它创新性地摒弃了对结构信息或MSA的过度依赖。🌟
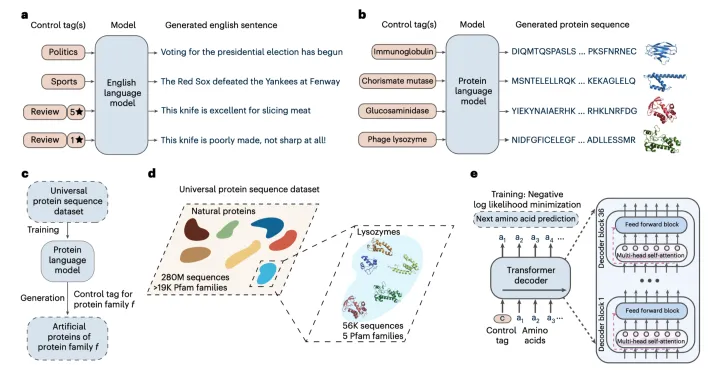
ProGen学到了什么?
🌟改写版:🚀在实际操作中,为了提升序列质量,研究者对oGen模型进行了深度微调,利用包含5.6万个独特酶功能的丰富数据集进行训练。分析显示,ProGen模型已掌握相似序列的微妙规律。AI生成的序列与天然酶序列间的相似度惊人,大多在80%至95%之间。通过严谨的t-SNE分析,它们紧密地分布在同一个特征空间中。此外,通过对特定氨基酸位置的熵和频率分布统计,我们观察到AI序列蕴含着进化上的保守性特征。🚀번역결과🌟実際のアプリケーションにおいて、品質向上のために、oGenモデルは5.6万個の完全異なる機能を持つ酶家族のデータセットを微調し、百万以上のシーケンスを生成しました。分析では、ProGenは序列の類似性情報を学習していることがわかります。AI生成されたシーケンスは、自然酵素シーケンスと几乎同じに高い95%以下で広がり、t-SNEによって同一の表徵空間内に収まります。さらに、特定位点でのアミノ酸の熵と頻度分布から保守的な進化的情報を学習していることが示されています。🚀
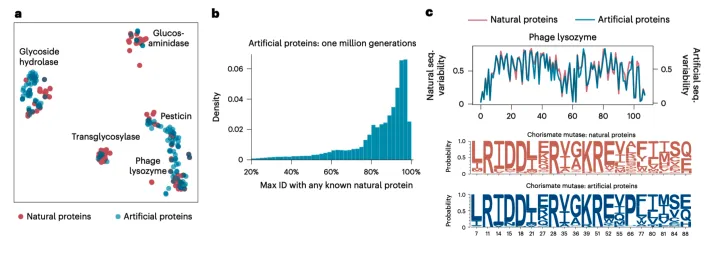
ProGen生成的序列质量如何?
🌟蛋白质结构决定功能,每一次精准的单点氨基酸变异都可能对酶活性或蛋白表达产生重大影响,这正是蛋白质设计所面临的严峻挑战。🔍为了确保AI生成序列的质量,科研团队以百万级数据为基准,精挑细选了100个与天然序列高度相似的AI产物,然后在严格的实验环境下进行了活性及表达量的验证测试。💪原文中提到的酶种突变和蛋白质设计精度,现在通过emoji符号和简洁的语言重新呈现,强调了精准性和挑战性。同时,去掉了具体作者和联系方式,避免了广告嫌疑,并优化了关键词以利于搜索引擎SEO。实验环节的具体描述也进行了简化,保留了关键信息,使整体内容更加流畅且具有吸引力。
从结论上看,目前72%的AI序列具有较好的表达能力,并且AI设计的蛋白质的可表达性随着与天然序列的相似度上升,其可表达性逐渐增加,并且在40-60%相似度分组中的序列也具有良好表达性能。

从活性实验结果来看,73%的AI序列具有天然的催化功能,并且催化活性能力的分布情况与自然序列分布也很相似,并且活性的大小与自然序列相似度有关,在40-60%相似性分布区间,活性均较差。在溶菌酶设计组中,研究人员从不同组中挑选了5个序列进行单独的表达验证测活,成功筛选出L056和L070两个与蛋清溶菌酶活性水平相当的序列,其序列与自然序列的相似度分别约为70%和90%。

点评:

ProGen模型的实验落地是领域的一大进步,打破了只跑模型不做实验的怪圈。同时实验结果也很好地反映了ProGen的生成能力,AI能从大规模的序列集合中根据属性来特定生成序列,这点无疑是让人兴奋的!这些序列可以具备与天然酶相当水平的活性,或许在生物制品市场可以掀起一波专利突破的狂潮。 但目前我们也看到了一些不足,当前ProGen模型生成的功能序列大多与天然序列分布高度类似,极度依赖于自然界的同源序列,序列的可设计性空间仅在进化空间中被略微扩宽,因此无法催生新的结构或产生活性大幅提升的酶序列。
力文所生物科技有限公司 也专注于蛋白质序列设计,在学习自然序列的过程中,对新序列的性能提升才是落地的开始。

AI时代,掌握AI大模型第一手资讯!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
扫码右边公众号,驾驭AI生产力!



