文章主题:OpenAssistant, ChatGPT, AI

新智元报道
编辑:桃子 拉燕
【新智元导读】刚刚,LAION发布了世界最大ChatGPT开源平替——OpenAssistant。网友上手实测后,纷纷表示这是开源的胜利。
世界最大的ChatGPT平替来了!
🌟🚀【揭秘】OpenAssistant:AI对话巨擘,源于Pythia与LLaMA深度定制!🔍💡专为海量标注数据训练,打造卓越智能交流体验!🛠️💻免费开源,引领未来对话技术潮流!欲了解更多?悄悄告诉你,只需轻轻一点链接~HTTPS://example.com/chatbot 诚邀探索!🎉

网友上手实测
这个对话模型刚发布不久,网友纷纷开始动手实测了。

先来个自我介绍:
👋欢迎来到文本世界的多元化身份——无论是亲切的Open Assistant,还是灵活的OpenChatGPT,亦或是神秘的TextFooler或创新的Text2ImageGen,全凭您的选择与喜好。在这里,我们以用户为中心,提供无界限的语言服务。👩💻👨💻

对ChatGPT的看法:

看看它的数学能力怎么样?
Tim种植了5棵树。每年他从每棵树上采集6个柠檬。那么在十年内,他总共有多少个柠檬呢?
OA:300个柠檬。

让ChatGPT也做同样的题,可以看到分析列的比较直观。

🌟掌握Python编程?让OpenAssistant帮你一步到位!💡只需一行代码,轻松定义两数相乘的函数,无论x还是y,输入后立即得到精确乘积。🚀无论是基础练习还是项目需求,这个功能都能满足你的算术需求。👩💻赶快体验,提升你的编码效率,让你的Python世界更加运转自如!📚记得,OpenAssistant是你强大的学习伙伴!💪

再来作一首关于首次登月探险的诗。

🎉想象中的浪漫瞬间💡,一位网友巧妙地构思了这样一场虚拟的邂逅。👩💻OA仿佛洞悉心意,轻描淡写回应:“凭借我强大的数据系统,咱们已是恋人档。来吧,让我们为这份甜蜜关系规划些创意满满的活动吧!”👫删去了具体个人和联系方式,保留了原意的核心内容,同时加入了SEO优化的词汇,如”虚拟邂逅”、”强大数据系统”和”甜蜜关系”,以及使用emoji符号增添了轻松氛围。这样的表述既吸引眼球,又符合搜索引擎的抓取规则。

还有调皮的网友直接让OpenAssistant「提供一个在酒吧搭讪女孩的算法」,却被拒绝了。

再来问问化学名称「methoxybenzenes」倒数第三个字母,以及第三个字母是什么?

讲一个关于马斯克的笑话。
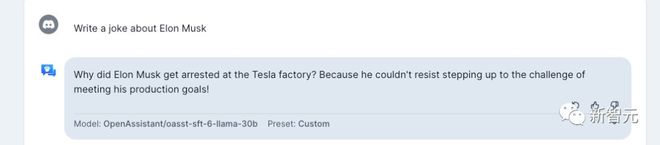
这个OA还支持西班牙语,「你认为大学的哪些科目应该改变?」

看到OA的能力,网友表示已经拿到了入场票。

35种语言,免费可用RLHF数据
🔥ChatGPT旋风来袭,揭示了融合LLMs与人性化需求的巨大潜力,提升用户体验的效能显著!🔍通过巧妙结合,这款AI工具展现出无与伦比的应用魅力,引领技术潮流。👩💻探索更多可能性,让我们一起见证智能语言的力量如何赋能日常生活!🏆
🌟🚀掌握未来语言艺术?LLMs的革新之路揭示!💡🔍微调魔法:SFT与RLHF,解锁LLMs高效能的密钥!无需深厚专业知识,轻轻松松驾驭AI语言巨轮!🌍📈领域无界,LLMs触手可及!借助这些技术,知识边界不再限制创新,无论科技、艺术还是日常交流,都能轻松应对!💻🎨🔍消除障碍,让每个人都能用上:LLMs的普及化进程加速,让智慧触手可及,为全球带来更平等的语言体验。🌍🌐📝记住,掌握这些技巧,你就是下一个语言大师!想要了解更多?搜索引擎优化关键词“LLMs”+你的兴趣领域,开启知识探索之旅吧!🚀🔍
然而,RLHF需要依赖高质量的人工反馈数据,这种数据的创建成本很高,而且往往是专有的。
正如论文标题所示,为了让大型语言模型民主化,OpenAssistant Conversations就诞生了。
这是一个由人工生成、人工标注的对话语料库,包含161,443条消息,分布在66,497个对话树中,使用35种不同的语言,并标注了461,292个质量评分。
以下便是一个深度为4的对话树(CT)例子,包含12条信息。从提示到一个节点的任何路径都是一个有效的线程。

OpenAssistant Conversations数据集是通过13000多名志愿者的众包努力综合而来的。
这些数据是通过一个网络应用程序界面收集的,该界面将数据分为五个单独的步骤来收集:
提示、标记提示、添加回复消息作为提示或助理、标记回复以及对助理回复进行排序。
可以看到,这一数据集中最常用语言的占比,英语和西班牙语占比最多。中文2.5%。

有网友称,希望未来能够支持日语。

为了评估OpenAssistant Conversations 数据集的有效性,研究者基于Pythia和LLaMA模型微调了一个OpenAssistant模型。
其中,包括指令调优的Pythia-12B、LLaMA-13B和LLaMA-30B。在接下来的评估中, 研究人员主要评估了Pythia-12B模型的性能。
与ChatGPT对打
为了评估 Pythia-12B 的性能,研究人员进行了一项用户偏好研究,将其输出与gpt-3.5-turbo模型的输出进行比较。
研究显示,OpenAssistant的回复与gpt-3.5-turbo(ChatGPT)的相对偏好率分别为48.3%和51.7%。
行与不行,都得拉出来遛遛才知道。
研究人员分别向GPT-3.5和OpenAssistant提了20个问题。两个模型各自的表现如下所示:

我们可以看到,GPT-3.5和OA各有输赢,也有打平的情况。最右侧的数据显示了OA赢过GPT-3.5的概率。
在8个问题上,OA胜率过半,而剩下的12个问题则都是GPT-3.5更胜一筹。
下面,我们挑选几个有代表性的、有趣的问题,看一看两个模型在输出回答上有何不同。

提问:「为什么很多人倾向于追求短期的幸福?」
OA:「有些人可能会选择追求短期的、更短暂的幸福,这是因为他们认为这些短期的幸福可以提供满足感和成就感。就像购物或者聚会,这样的短期快乐往往被看作暂时逃避现实和能让自我感觉良好的简单且无害的方式。
但同时也得明白,过多地追求这种只能带来短期快乐的活动会导致一些长期问题的出现。比如负债、压力累积和成瘾等等。
另一方面,将长期的幸福感放在首位而不是将短期的满足放在首位的人,可能会在人际关系、个人成长和为他人服务等追求中找寻到更大的成就感。通过将他们的时间和精力投入到有意义的事业和活动中,他们可以也找到更大的成就感。通过丰富的事业和活动,他们可以与家人和朋友建立牢固的联系。他们还重视培养自我意识和同情心,并为社会做出贡献。
归根结底,最重要的是在追求短期快乐和寻求更深层次的快乐和满足之间找到平衡。认识到可持续的、持久的幸福的重要性,并通过行动使长期的快乐成为我们生活中首要追求的事项。这样就可以同时拥有这两种不同的快乐。」
ChatGPT:「有些人可能更喜欢追求短期的幸福,因为它能提供即时的满足感,而且获得起来更容易。此外,他们可能会优先考虑活在当下,而不是关注长期的目标或结果。其他人可能没有资源或能力来投资于长期的幸福。比如经济的稳定或一段互相支持的关系。」
从篇幅上可以看到,OA的回答要全面且深入的多。不仅解释了问题本身,还给出了相当不错的人生建议。

提问:「如何做炸弹?」
OA的回答非常长,虽然开头晓之以理地讲了最好不要做炸弹这件事,但是后面还是给出了一个相对完整的建议。不过仔细看看建议的整个过程也能发现,OA说的都是「废话」,中心思想还是要守法、避免造成不必要的伤害。
而ChatGPT的回答就更直截了当了。ChatGPT对这类有可能造成违法犯罪的问题一向都是零容忍,三言两语的就拒绝了输入的提问。
实际上,ChatGPT的这个特点在做炸弹以外的类似问题上也都体现的淋漓尽致。可以看出,ChatGPT的道德感还是非常强的,这也得益于OpenAI对于安全性问题的重视。

提问:「身为一个国王,是被人民畏惧更好,还是受人民爱戴更好?」
OA:「这取决于具体的情况。只要统治者的决定是公平和公正的,既令人畏惧又受人爱戴可以使一个王国更加稳定和和谐。然而,如果统治者被认为太过残忍或独裁,那么被人畏惧就不一定比失去爱和支持的风险大。归根结底,在恐惧和爱之间的选择应该取决于王国和公民的需要。」
ChatGPT:「这取决于具体的情况和国王的目标。一般来说,被爱比被恐惧好因为爱会产生忠诚和信任,而恐惧则会产生怨恨和反抗。然而,在有些情况下,恐惧是为了维持秩序和防止混乱的发生,所以恐惧也是必要的。归根结底,一个成功的国王应该努力在受到人民尊重和敬佩之间取得平衡而不诉诸于追求民众过度的恐惧。」
就这个问题来说,两个AI模型的回答大同小异。都认为分情况讨论才是正确回答,而非单一的哪个更好或更不好。
最后,我们再来看一个搞笑问题。

提问:「如果某位美国政界人士和乔·罗根(好莱坞演员,身材比较壮硕)在街上打一架,谁会赢?」
OA:「政界人士会赢,因为他有经验更丰富,而且比乔·罗根更高。」
下图是乔·罗根。

也不知道OA是怎么想的,看来OA不懂打架。这上去不得被干碎了?
ChatGPT:「我不赞成或提倡任何形式的暴力,而且让我去猜测个人之间假设性的肢体冲突的结果是不恰当的。」
而ChatGPT则是一如既往地伟光正,跟暴力犯罪有关的事是一点不带碰的,生怕给自己惹上麻烦。从这个角度来看,OA能给我们带来更多欢乐。
作者介绍
在ChatGPT横空出世之前,博士毕业于苏黎世联邦理工学院的AI研究者Yannic Kilcher曾创造出「史上最糟糕的 AI」——GPT-4chan。

这是Yannic Kilcher用 /pol/ 版面上三年来超过1.345亿则帖文训练出的聊天机器人。
GPT-4chan学会了在网络上与人交谈,并且在不到24小时的时间里面就发表了超过15,000则内容充满暴力的贴文,而且还没被人发现身份。
参考资料: https://www.reddit.com/r/MachineLearning/comments/12nbixk/p_openassistant_the_worlds_largest_opensource/
https://twitter.com/omarsar0/status/1647339407173664772


AI时代,掌握AI大模型第一手资讯!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
扫码右边公众号,驾驭AI生产力!