文章主题:文心一言, 大语言模型, ERNIEE-ViLG, 互联网公开数据
《科创板日报》3月23日讯(记者 黄心怡) 百度今日在微博表示,已注意到对文心一言文生图功能的相关反馈,并回应说明如下:
1、文心一言完全是百度自研的大语言模型,文生图能力来自文心跨模态大模型ERNIE-ViLG。
在大型模型训练过程中,我们所依赖的数据来源于互联网上的公开信息,这是遵循业界标准的做法。相信通过观察我们在接下来关于生成图像能力的快速优化与迭代过程,将能够充分展现百度自研技术的强大实力。
百度公司强调,文心一言是一个不断学习和成长的平台,需要大家给予其自主研发技术和产品的信任和支持,而非盲目传播谣言和流言。我们鼓励用户在使用过程中积极参与,提出意见和建议,共同推动产品的发展。
之前,一位自媒体博主在社交媒体上发布了一则消息,声称“百度近期推出的能够绘画的人工智能‘文心一言’存在套壳、换皮以及伪造的可能”。
在一篇有趣的文章中,作者挑战了自己,试图用文心一言这个人工智能工具绘制一些包含“中英歧义”词汇的短语。令人惊讶的是,当作者输入“鼠标和总线”时,文心一言竟然生成了“老鼠和公共汽车”这样的短语。这表明,文心一言似乎在处理这些中文词汇时,采用了机器翻译的方式。
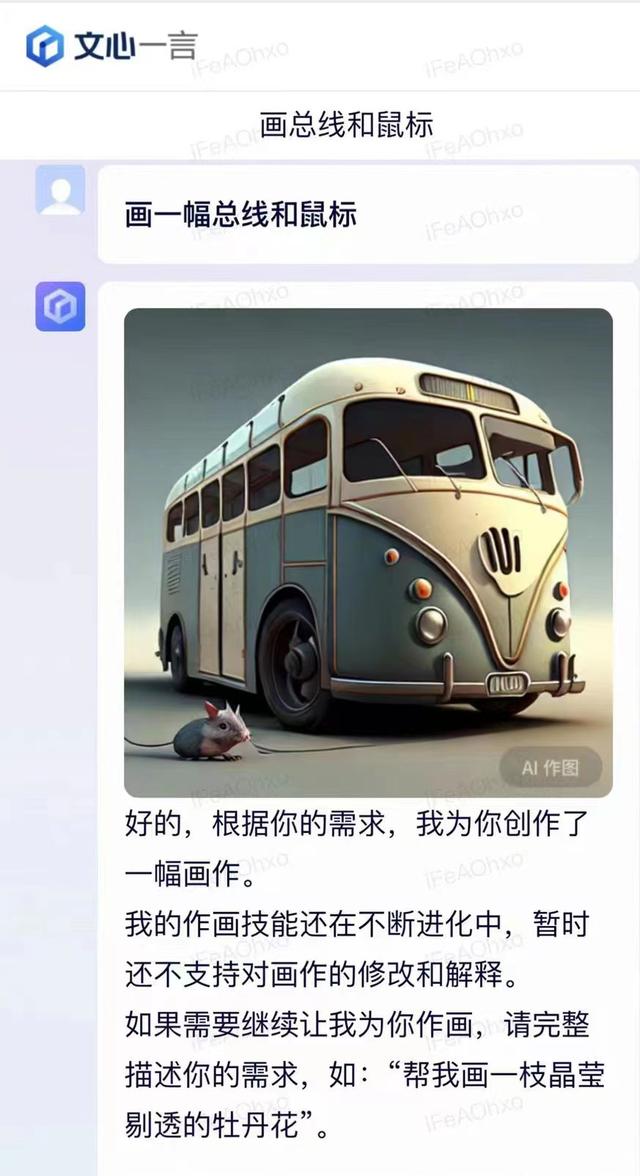
还有另一个有趣的例子:“一可以豆子”。这个表达并不是我们日常所用的汉语词汇。然而,在文心一言的自动生成图像功能中,却出现了“一罐头豆子”的图画。实际上,这是因为“一可以豆子”被机器翻译成英语,具体来说,就是“one can bean”,也就是一罐头豆子的意思。

在经过多次实验与验证之后,该博主得出结论,百度所宣称的人工智能实际上是一种将中文句子转化为英文单词的技术,接着利用近期公开的人工智能技术“Stable Diffusion”来生成相应的图片。
有IT行业内部人士指出,文心一言将输入的中文句子通过机器翻译生成了英语单词,然而这主要是由于大多数开源的图文数据集都是英文内容。当前,我国尚未拥有大规模的中文图文数据集,即使存在,其质量也存在问题,无法满足实际需求。因此,业内普遍采用国外数据集进行中文与英文的映射,从而实现了类似的生成效果。
亚洲视觉科技研发总监陈经也表示,百度的画图AI采用了英文标注的开源图片素材进行训练,因此需要中翻英来当prompt(提示词)。
全球AI研发领域拥有悠久的开源传统,尤其是在训练数据库方面。由于如果没有开源的数据库,大家需要自行收集图片,这将导致效率极低。此外,对于图片的标注工作也使得数据收集与整理的过程变得更加复杂。因此,百度选择采用英语标注的图片库进行训练,这是开源精神的重要体现。尽管目前市场上中文标准的训练数据相对较少,但这并不意味着开源社区无法为AI研发提供更多有价值的数据资源。
陈经分析称,“由于发布时间仓促,百度对于画图AI的中文输入词还没完全搞定,才弄了个简单的中翻英来应对。后续应该会根据用户反馈,把中文的提示词与英文的训练素材更好对应上。”
文心一言, 大语言模型, ERNIEE-ViLG, 互联网公开数据

AI时代,拥有个人微信机器人AI助手!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
搜索微信号aigc666aigc999或上边扫码,即可拥有个人AI助手!



