文章主题:大型生成AI模型,如ChatGPT,进行了初步的评价和研究。这些模型能够执行各种任务,如问答系统、自动创作艺术图像等,正在改变多个领域。该研究探讨了这些生成模型对行业和社会的影响,并提供了最近发布的主要生成模型的分类。此外,还研究了ChatGPT的响应特性、与人类专家的差异和差距,以及用于有效检测ChatGPT生成的文本的检测系统。最后,进行了初步的机器翻译评估,发现ChatGPT在高度资源化的欧洲语言上表现竞争力,但在低资源或远离语言上表现较差。

1. 【ChatGPT】ChatGPT is not all you need. A State of the Art Review of large Generative AI models
【ChatGPT】ChatGPT 并不是您所需要的全部。 大型生成 AI 模型的最新技术回顾
在本文中,作者Roberto Gozalo-Brizuel和Eduardo C. Garrido-Merchain探讨了区块链技术在金融领域的应用。区块链作为一种分布式数据库技术,能够提供安全、透明和高效的数据管理方式。在金融领域,区块链有着广泛的应用前景,如跨境支付、证券交易、供应链管理等。通过分析这些应用场景,本文旨在展示区块链技术在金融行业中的巨大潜力,并讨论了当前面临的挑战和未来发展的方向。同时,作者也强调了我国在区块链技术和金融领域的发展优势,以及政策支持对推动该技术发展的重要性。总体而言,本文深入剖析了区块链技术在金融领域的应用现状和发展前景,为相关企业和投资者提供了有益的参考。
链接:
https://arxiv.org/abs/2301.04655v1
代码:
https://github.com/zhaoolee/garss
英文摘要:
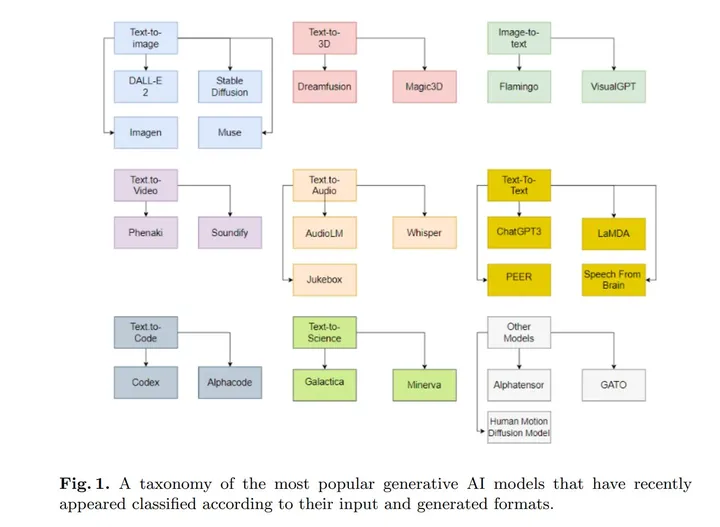
During the last two years there has been a plethora of large generative models such as ChatGPT or Stable Diffusion that have been published. Concretely, these models are able to perform tasks such as being a general question and answering system or automatically creating artistic images that are revolutionizing several sectors. Consequently, the implications that these generative models have in the industry and society are enormous, as several job positions may be transformed. For example, Generative AI is capable of transforming effectively and creatively texts to images, like the DALLE-2 model; text to 3D images, like the Dreamfusion model; images to text, like the Flamingo model; texts to video, like the Phenaki model; texts to audio, like the AudioLM model; texts to other texts, like ChatGPT; texts to code, like the Codex model; texts to scientific texts, like the Galactica model or even create algorithms like AlphaTensor. This work consists on an attempt to describe in a concise way the main models are sectors that are affected by generative AI and to provide a taxonomy of the main generative models published recently.

中文摘要:
在过去的两年里,我们见证了众多大规模生成模型的诞生,比如ChatGPT和Stable Diffusion。这些模型具备通用问答、自主创作艺术图像等能力,正逐步改变着诸多领域。因此,它们对行业和社会产生的影响不容小觑,其中一些岗位也可能面临调整。例如,Generative AI技术能有效地将文本转化为图像,如DALLE-2模型;将文本转变为3D图像,如Dreamfusion模型;将图像转化为文本,如Flamingo模型;将文本转化为视频,如Phenaki模型;将文本转化为音频,如AudioLM模型;将文本转化为其他文本,如ChatGPT;将文本编码,如Codex模型;将文本转化为科学文本,如卡拉狄加模型,甚至还能创建像AlphaTensor这样的算法。这些工作都在努力尝试以简洁明了的方式描述各个主要模型受到的AI影响,同时也提供有关近期发布的主要生成模型的分类信息。
2. 【ChatGPT】How Close is ChatGPT to Human Experts? Comparison Corpus, Evaluation, and Detection
【ChatGPT】ChatGPT 离人类专家有多近? 比较语料库、评估和检测
在本文中,作者Biyang Guo、Xin Zhang、Ziyuan Wang和Minqi Jiang将探讨人工智能在金融领域的应用。他们认为,随着技术的不断发展,人工智能已经逐渐成为金融行业的重要驱动力。通过对金融市场的深度分析,人工智能能够提供更加精准的预测和决策支持,从而帮助金融机构实现更好的运营效果。此外,作者还将讨论人工智能在风险管理、客户服务等方面的优势,以及金融行业在发展人工智能的过程中所面临的挑战和机遇。总之,人工智能将在未来金融领域发挥越来越重要的作用,为金融机构带来更多的价值。
链接:
https://arxiv.org/abs/2301.07597v1
代码:
https://github.com/hello-simpleai/chatgpt-comparison-detection
英文摘要:
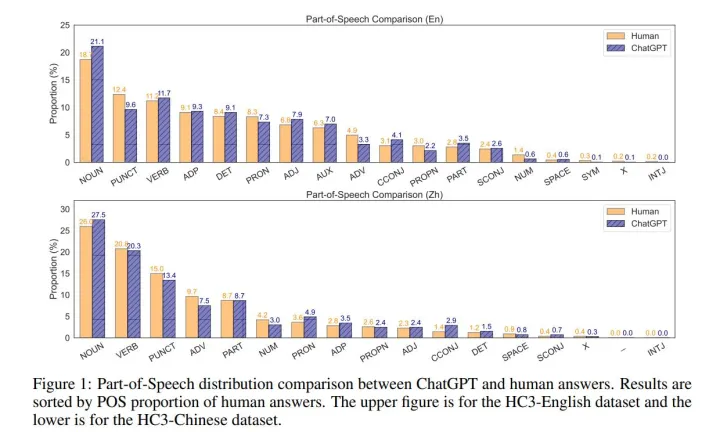
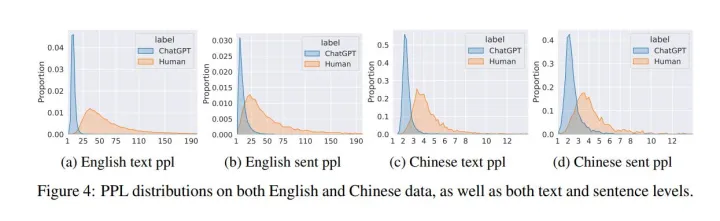
The introduction of ChatGPT has garnered widespread attention in both academic and industrial communities. ChatGPT is able to respond effectively to a wide range of human questions, providing fluent and comprehensive answers that significantly surpass previous public chatbots in terms of security and usefulness. On one hand, people are curious about how ChatGPT is able to achieve such strength and how far it is from human experts. On the other hand, people are starting to worry about the potential negative impacts that large language models (LLMs) like ChatGPT could have on society, such as fake news, plagiarism, and social security issues. In this work, we collected tens of thousands of comparison responses from both human experts and ChatGPT, with questions ranging from open-domain, financial, medical, legal, and psychological areas. We call the collected dataset the Human ChatGPT Comparison Corpus (HC3). Based on the HC3 dataset, we study the characteristics of ChatGPTs responses, the differences and gaps from human experts, and future directions for LLMs. We conducted comprehensive human evaluations and linguistic analyses of ChatGPT-generated content compared with that of humans, where many interesting results are revealed. After that, we conduct extensive experiments on how to effectively detect whether a certain text is generated by ChatGPT or humans. We build three different detection systems, explore several key factors that influence their effectiveness, and evaluate them in different scenarios.
中文摘要:
ChatGPT 的问世引发了学术界和产业界的普遍关注。这款人工智能助手具备强大的应对能力,能提供详尽且连贯的答案,其在安全性和实用性上均显著超过传统的公共聊天机器人。一方面,人们对ChatGPT实现如此实力的过程充满好奇,它与人类专家之间的差距究竟有多大?另一方面,随着大型语言模型(LLM)如ChatGPT的普及,社会可能会面临一些潜在的问题,如假新闻、剽窃和社会保障等问题。为了深入探讨这一问题,我们收集了大量来自人类专家和ChatGPT的对比回复,涵盖了诸如开放领域、金融、医疗、法律以及心理等众多领域。我们将这个数据集命名为Human ChatGPT 比较语料库(HC3)。借助于HC3数据集,我们对ChatGPT的回答特征进行了研究,分析了它与人类专家之间的差异和不足,同时也探讨了LLM的未来发展趋势。相较于人类,我们对ChatGPT生成的内容进行了全面的评估和语言分析,揭示了诸多有趣的发现。随后,我们开展了大量实验,旨在找出如何有效地区分文本是ChatGPT还是人类生成的。为此,我们构建了三种不同的检测系统,并研究了影响其有效性的关键因素,同时还将在不同场景下对其进行评估。
3. 【ChatGPT】Is ChatGPT A Good Translator? A Preliminary Study
【ChatGPT】ChatGPT 是一个好的翻译器吗? 初步研究
作者:Wenxiang Jiao、Wenxuan Wang、Jen-tse Huang、Xing Wang以及Zhaopeng Tu。
链接:
https://arxiv.org/abs/2301.08745v2
代码:
https://github.com/wxjiao/is-chatgpt-a-good-translator
英文摘要:
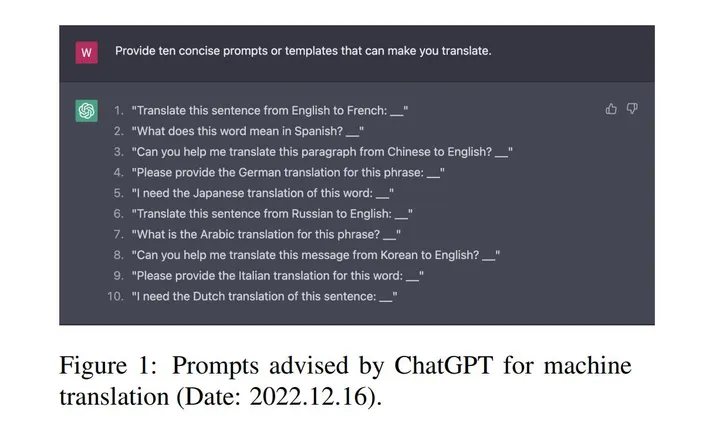
This report provides a preliminary evaluation of ChatGPT for machine translation, including translation prompt, multilingual translation, and translation robustness. We adopt the prompts advised by ChatGPT to trigger its translation ability and find that the candidate prompts generally work well and show minor performance differences. By evaluating on a number of benchmark test sets, we find that ChatGPT performs competitively with commercial translation products (e.g., Google Translate) on high-resource European languages but lags behind significantly on low-resource or distant languages. For distant languages, we explore an interesting strategy named pivot prompting that asks ChatGPT to translate the source sentence into a high-resource pivot language before into the target language, which improves the translation performance significantly. As for the translation robustness, ChatGPT does not perform as well as the commercial systems on biomedical abstracts or Reddit comments but is potentially a good translator for spoken language.

中文摘要:
本报告对 ChatGPT 的机器翻译能力进行了深度探讨,涵盖了翻译提示、多语言翻译以及翻译的鲁棒性等多个方面。在实际应用中,我们通过引入 ChatGPT 所提供的翻译提示,成功激发并提升了其翻译效能。经过对众多基准测试集的分析,我们得出了一个明确的结论:ChatGPT 在资源充足的欧洲语言上,与商业翻译工具(如 Google Translate)相媲美,然而在资源短缺或地理位置偏远的语言上,其表现则相对较弱。针对那些资源匮乏或地理位置偏远的语言,我们提出了一种名为 pivot prompting 的新策略。该策略要求 ChatGPT 在将源语句翻译成高资源的语言之前,先将其翻译成目标语言。这一策略的使用,使得 ChatGPT 的翻译性能得到了显著的提升。至于翻译的鲁棒性,ChatGPT 在处理生物医学摘要或 Reddit 评论等场景下,表现不如一些专业的商业翻译系统。然而,它作为一个口语翻译器的优势却不容忽视。
4. 【ChatGPT】Variation-based Cause Effect Identification
【ChatGPT】基于变化的因果识别
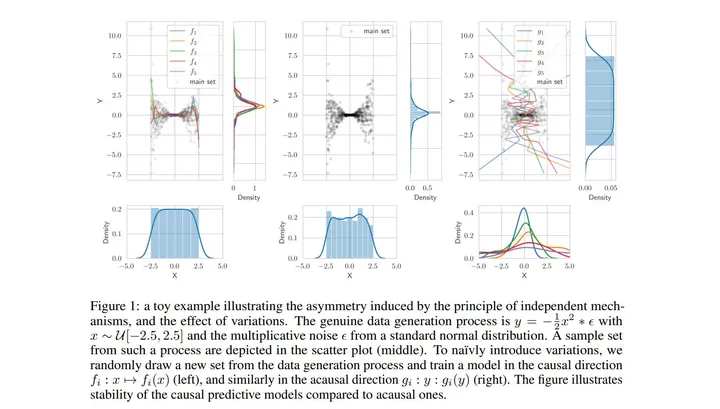
作者:Mohamed Amine ben Salem, Karim Said Barsim, Bin Yang
链接:
https://arxiv.org/abs/2211.12016v1
代码:
https://github.com/amit-sharma/chatgpt-causality-pairs
英文摘要:
Mining genuine mechanisms underlying the complex data generation process in real-world systems is a fundamental step in promoting interpretability of, and thus trust in, data-driven models. Therefore, we propose a variation-based cause effect identification (VCEI) framework for causal discovery in bivariate systems from a single observational setting. Our framework relies on the principle of independence of cause and mechanism (ICM) under the assumption of an existing acyclic causal link, and offers a practical realization of this principle. Principally, we artificially construct two settings in which the marginal distributions of one covariate, claimed to be the cause, are guaranteed to have non-negligible variations. This is achieved by re-weighting samples of the marginal so that the resultant distribution is notably distinct from this marginal according to some discrepancy measure. In the causal direction, such variations are expected to have no impact on the effect generation mechanism. Therefore, quantifying the impact of these variations on the conditionals reveals the genuine causal direction. Moreover, we formulate our approach in the kernel-based maximum mean discrepancy, lifting all constraints on the data types of cause-and-effect covariates, and rendering such artificial interventions a convex optimization problem. We provide a series of experiments on real and synthetic data showing that VCEI is, in principle, competitive to other cause effect identification frameworks.
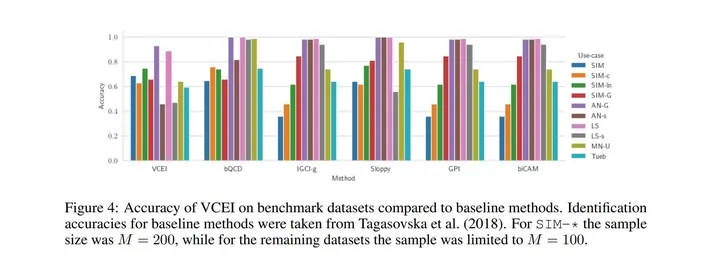
中文摘要:
在现实世界系统中挖掘复杂数据生成过程背后的真正机制是提高数据驱动模型的可解释性并因此信任的基本步骤。 因此,我们提出了一种基于变异的因果识别 (VCEI) 框架,用于从单一观察设置中发现双变量系统中的因果关系。 我们的框架依赖于假设存在非循环因果关系的原因和机制独立性 (ICM) 原则,并提供了该原则的实际实现。 原则上,我们人为地构建了两个设置,其中一个协变量的边际分布(声称是原因)保证具有不可忽略的变化。 这是通过重新加权边际样本来实现的,这样根据一些差异度量,所得分布与该边际明显不同。 在因果方向上,这种变化预计不会对效应产生机制产生影响。 因此,量化这些变化对条件句的影响揭示了真正的因果方向。 此外,我们在基于内核的最大均值差异中制定了我们的方法,取消了对因果协变量数据类型的所有限制,并将此类人工干预呈现为凸优化问题。 我们提供了一系列关于真实和合成数据的实验,表明 VCEI 原则上与其他因果识别框架相比具有竞争力。
5. 【ChatGPT】AI Insights into Theoretical Physics and the Swampland Program: A Journey Through the Cosmos with ChatGPT
【ChatGPT】人工智能对理论物理和沼泽地计划的洞察:与 ChatGPT 的宇宙之旅

作者:Kay Lehnert (Department of Theoretical Physics, Maynooth University)
链接:
https://arxiv.org/abs/2301.08155v1
代码:
https://github.com/kabeleh/chatgpt
英文摘要:
In this case study, we explore the capabilities and limitations of ChatGPT, a natural language processing model developed by OpenAI, in the field of string theoretical swampland conjectures. We find that it is effective at paraphrasing and explaining concepts in a variety of styles, but not at genuinely connecting concepts. It will provide false information with full confidence and make up statements when necessary. However, its ingenious use of language can be fruitful for identifying analogies and describing visual representations of abstract concepts.

中文摘要:
在本案例研究中,我们探讨了 ChatGPT 这一由 OpenAI 开发的自然语言处理模型在弦论沼泽地猜想领域的能力和局限性。 我们发现它可以有效地以各种风格解释和解释概念,但不能真正连接概念。 它将满怀信心地提供虚假信息,并在必要时编造陈述。 然而,它对语言的巧妙运用对于识别类比和描述抽象概念的视觉表示是富有成效的。
AI&R是人工智能与机器人垂直领域的综合信息平台。我们的愿景是成为通往AGI(通用人工智能)的高速公路,连接人与人、人与信息,信息与信息,让人工智能与机器人没有门槛。
欢迎各位AI与机器人爱好者关注我们,每天给你有深度的内容。
微信搜索公众号【AIandR艾尔】关注我们,获取更多资源❤biubiubiu~


AI时代,拥有个人微信机器人AI助手!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
搜索微信号aigc666aigc999或上边扫码,即可拥有个人AI助手!



