文章主题:关键词:大模型能力, ChatGPT, 符尧, NLP 社区
公众号:将门创投
文章来源:公众号【李Rumor】
作者:李Rumor看过符尧大佬拆解GPT3起源的文章,收到了很多好评,同时也让我们开始思考:
是否只有大模型能训出ChatGPT?小模型+精调 vs 大模型+提示词,哪个更好?Prompt已经火了一年多,然而真正在生产中应用的还是少数,我们是否真的面临范式转变?如果真需要大模型,得多大?🌟【揭秘未来】🚀 大型模型先知?ChatGPT前的深度洞察💡符尧已为你揭示!📚 在这波技术浪潮中,他早在ChatGPT之前就以独到视角剖析了大模型的强大潜力。我们精心翻译,只为让你一窥究竟,扫清所有疑惑。🔍👉 无需担心信息过载,这篇文章不仅详尽解析,而且SEO优化,助你轻松理解。🎯 想了解技术如何塑造世界?这里是你寻找答案的宝藏!💎📚 现在就行动,点击链接获取完整中文版——让知识触手可及!🔗 让我们一起探索,迎接智能未来!🌐

🎓文章写作大师在此!✨以深厚学术背景,毕业于世界顶尖学府——北京大学的符尧博士,现专注于提供高质量的文章服务。他的研究领域丰富,思维敏锐,对教育领域的见解独到,曾在【Edinburgh University】的求学经历更是锦上添花。欲寻求专业且引人入胜的文字支持?他将是您的不二之选!欲了解更多详情或联系他,敬请私信✨.edu。SEO优化完毕,期待为您带来价值满满的内容!📚
🌟曾在💡艾伦AI研究院(AI@Allen)🌟与两位技术大牛📚Tushar Khot和彭昊📚合作,共同打磨了一篇英文原稿。我们的创新思维在这里碰撞,智慧的火花熠熠生辉。这份专业成果不仅体现了我们对人工智能的深度探索,也是AI领域知识交流的珍贵记录。虽然具体的联络信息已隐藏,但这段经历无疑是我们技术旅程中的一段闪耀篇章。如果你想了解更多相关AI研究动态,不妨搜索”艾伦AI研究院+英文原稿”,那里或许能找到你想要的答案。📚💻
与 李如寐(美团NLP中心)共同翻译为中文
🎉感谢团队力量!🌟Aristo伙伴们Jingfeng Yang和Yi Tay的深度交流与宝贵意见,让我的创作之路更加明晰。他们的智慧火花照亮了前行的道路,让我受益匪浅。📚每一次思想碰撞,都是知识的积累,期待未来能有更多这样的互动,共同进步!🙏#团队合作 #创意灵感
请同时参考CoT[1]团队的博客。🔥最近🔥,人们对大型語言模組展现出的強大威力(如思维連接💡、筆記本📚)熱血沸騰,催生了一系列研究热潮!這些獨特且震撼的能力,稱為「模型突現」🔍,專屬於巨無霸級別,而非小型機器。它們代表了AI研究的一個重大轉型🚀——從微調小模型到大規模上下文學習!👀複雜推理、知識推理和非線性魯棒性 gibi超凡能力,將深度剖析!這些久違的NLP夢想如今近在咫尺,昭示著一個嶄新的研究視角。對於領先者來說,這顯而易見;但科學精神要求我們提供確鑿的理由,即便它們價格昂貴、操作複雜,效果未必盡善盡美。🔍本文將深入探討這些超能力的實質,大型語言模組能帶來什麼,以及它們在广泛范围内的NLP/ML任務中可能带来的潜在優勢。讓我們一起踏上這場探索未知的科技之旅,挖掘大模型潛力的無窮之處!🏆
前提:我们假设读者具备以下知识:
预训练、精调、提示(普通从业者应具备的自然语言处理/深度学习能力)思维链提示、便签本(普通从业者可能不太了解,但不影响阅读)一、存在于大模型而非小模型的突现能力

在以上的效果图中,我们可以观察到模型的表现:
当尺寸相对小的时候提升并不大当模型变大时有很明显的提升这从根本上说明,某些能力可能不存在于小模型中,而是在大模型中获得的。
🌟当然,突显才能的种类繁多,就像Wei等人在2022年的深度探讨中揭示的那样(引用[5])。这些技能无疑引人入胜,但我们今天的焦点将集中在那些更为实际且对AI至关重要的能力上,例如但不限于:`\textit{自然语言处理}`中的复杂逻辑分析和理解,以及 `\emoji{123456}`的`代码生成`与优化。我们不会涉及那些看似专属特定工具的任务,如`字符序列连接`(last latter concatenation)虽然Python能胜任,但它们是模型而非计算器的核心任务;同样,简单的数学运算,如三位数加法,虽易实现,却更多地考验的是计算器而非语言智能的深度应用。🚀
在本文中,我们主要对以下能力感兴趣:
1. NLP 社区近几年都关注但还没实现的能力
2. 之前的 NLP 模型很难达到的能力
3. 源自于人类语言最深层的本质的能力
4. 可能达到人类智力的最高水平的能力
二、突现能力的三个典型例子
很多有意思的能力都可以归到上文提到的类别里,在它们之中,我们主要讨论以下三种典型能力:
复杂推理知识推理分布外鲁棒性接下来让我们一个个详细讨论。
复杂推理
下面是一个GSM8K数据集中,用提示词显著超过精调的例子:

虽然这道题对于10岁的孩子来说很容易,但对语言模型来说却很难,主要是由于数学和语言混合在一起。
GSM8K 最初由 OpenAI 于 2021 年 10 月[6]提出。当时他们用第一版GPT3在全部训练集上进行了精调,准确率约为 35%。这个结果让作者相当悲观,因为他们的结果显示了语言模型的缩放规律:随着模型大小呈指数增长,性能呈线性增长(我之后会讨论)。因此,他们在第 4.1 节中思考:
“175B 模型似乎需要至少额外两个数量级的训练数据才能达到 80% 的求解率。”三个月后,即 2022 年 1 月,Wei 等人[7]基于 540B PaLM 模型,仅使用了8个思维链提示示例便将准确率提高到56.6% (无需将训练集增加两个数量级)。之后在 2022 年 3 月,Wang 等人[8]基于相同的 540B PaLM 模型,通过多数投票的方法将准确率提高到 74.4% 。当前的 SOTA 来自我自己在 AI2 的工作(Fu et. al. Nov 2022[9]),我们通过使用复杂的思维链在 175B Codex 上实现了 82.9% 的准确率。从以上进展可以看到,技术进步确实呈指数级增长。
思维链提示是一个展示模型随着规模突现出能力的典型例子:
从突现能力来看: 尽管不需要 17500B,但模型大小确实要大于 100B ,才能使思维链的效果大于的仅有回答提示。所以这种能力只存在于大型模型中。从效果来看: 思想链提示的性能明显优于其之前的精调方法(目前还没有能公平对比提示词和微调的工作。但当思维链被提出的时候,尽管他们对于提示和精调的比较可能是不公平的,但确实比精调效果要好)。从标注效率上来看: 思维链提示只需要 8 个示例的注释,而微调需要完整的训练集。有些同学可能会认为模型能做小学数学代表不了什么(从某种意义上说,他们确实没有那么酷)。但 GSM8K 只是一个开始,最近的工作已经把前沿问题推向了高中[10]、大学[11],甚至是国际数学奥林匹克问题[12]。现在更酷了吗?
知识推理
下一个例子是需要知识的推理能力(例如问答和常识推理)。在这种情况下,对大型模型进行提示不一定优于精调小型模型(哪个模型更好还有待观察)。但是这个情况下的注释效率被放大了,因为:
在许多数据集中,为了获得所需的背景/常识知识,(以前很小的)模型需要一个外部语料库/知识图谱来检索[13],或者需要通过多任务学习在增强[14]的数据上进行训练对于大型语言模型,可以直接去掉检索器[15],仅依赖模型的内部知识[16],且无需精调
如表中所示,与数学题的例子不同,GPT-3 并没有明显优于之前的精调模型。但它不需要从外部文档中检索,本身就包含了知识(虽然这些知识可能过时或者不可信,但选择哪种可信知识源超出了本文的讨论范围)。
为了理解这些结果的重要性,我们可以回顾一下历史:NLP 社区从一开始就面临着如何有效编码知识的挑战。人们一直在不断探究把知识保存在模型外部或者内部的方法。上世纪九十年代以来,人们一直试图将语言和世界的规则记录到一个巨大的图书馆中,将知识存储在模型之外。但这是十分困难的,毕竟我们无法穷举所有规则。因此,研究人员开始构建特定领域的知识库,来存储非结构化文本、半结构化(如维基百科)或完全结构化(如知识图谱)等形式的知识。
通常,结构化知识很难构建(因为要设计知识的结构体系),但易于推理(因为有体系结构),非结构化知识易于构建(直接存起来就行),但很难用于推理(没有体系结构)。然而,语言模型提供了一种新的方法,可以轻松地从非结构化文本中提取知识,并在不需要预定义模式的情况下有效地根据知识进行推理。下表为优缺点对比:

分布外鲁棒性
我们讨论的第三种能力是分布外的鲁棒性。在 2018 年至 2022 年期间,NLP、CV 和通用机器学习领域有大量关于分布偏移/对抗鲁棒性/组合生成的研究,人们发现当测试集分布与训练分布不同时,模型的行为性能可能会显著下降。然而,在大型语言模型的上下文学习中似乎并非如此。Si 等人在2022年的研究显示[17]:

同样,在此实验中,同分布情况下基于提示词的 GPT-3 的效果并没有精调后的 RoBERTa要好。但它在三个其他分布(领域切换、噪声和对抗性扰动)中优于 RoBERTa,这意味着 GPT3 更加鲁棒。
此外,即使存在分布偏移,好的提示词所带来的泛化性能依旧会继续保持。比如:

Fu 等人2022年[18]的研究显示,输入提示越复杂,模型的性能就越好。这种趋势在分布转移的情况下也会继续保持:无论测试分布与原分布不同、来自于噪声分布,或者是从另一个分布转移而来的,复杂提示始终优于简单提示。
到目前为止的总结
在上文中,我讨论了只有大型模型才有的三种突现能力。它们是:
复杂推理,大型模型在没有使用全部训练数据的情况下便显著优于以前的小型模型。知识推理,大型模型可能没有小模型效果好,但大模型不需要额外的知识来源(知识可能很昂贵,或者很难从非结构化数据中抽取)。分布外鲁棒性,这是之前进行模型精调时需要努力解决的问题。大型模型虽然在同分布情况下的效果不如以前的方法,但非同分布情况下的泛化性能却好得多。三、突现能力推翻比例定律
鉴于上文列出的优点,大家可能会开始觉得大型语言模型确实很好了。在进一步讨论之前,让我们再回顾一下之前的工作,就会发现一个很奇怪的问题:GPT-3 在 2020 年就发布了,但为什么直到现在我们才发现并开始思考范式的转变?
这个问题的答案就藏在两种曲线中:对数线性曲线和相变曲线。如下图:

最初,(OpenAI)的研究者认为语言模型的性能与模型尺寸的关系可以通过对数线性曲线预测,即模型尺寸呈指数增长时,性能会随之线性增加。这种现象被称为语言模型的缩放定律,正如 Kaplan 等人在2020年[19]最初的GPT3文章[20]中讨论的那样。重要的是,在那个阶段,即便最大的 GPT-3 在有提示的情况下也不能胜过小模型精调。所以当时并没有必要去使用昂贵的大模型(即使提示词的标注效率很高)。直到2021年,Cobbe 等人[21]发现缩放定律同样适用于精调。这是一个有点悲观的发现,因为它意味着我们可能被锁定在模型规模上——虽然模型架构优化可能会在一定程度上提高模型性能,但效果仍会被锁定在一个区间内(对应模型规模),很难有更显著的突破。
在缩放定律的掌控下(2020年到2021),由于GPT-3无法胜过精调 T5-11B,同时T5-11B微调已经很麻烦了,所以NLP社区的关注点更多的是研究更小的模型或者高效参数适应。Prefix tuning[22]就是提示和适应交叉的一个例子,后来由 He 等人在 2021[23]统一。当时的逻辑很简单:如果精调效果更好,我们就应该在高效参数适应上多下功夫;如果提示词的方法更好,我们应该在训练大型语言模型上投入更多精力。
之后在 2022 年 1 月,思维链的工作被放出来了。正如作者所展示的那样,思维链提示在性能-比例曲线中表现出明显的相变。当模型尺寸足够大时,性能会显著提高并明显超越比例曲线。
当使用思维链进行提示时,大模型在复杂推理上的表现明显优于微调,在知识推理上的表现也很有竞争力,并且分布鲁棒性也存在一定的潜力。要达到这样的效果只需要8个左右的示例,这就是为什么范式可能会转变的原因。
四、范式转变意味着什么?
范式转变究竟意味着什么?下面我们给出精调和提示词方法的对比:

提示词的好处很明显:我们不再需要繁琐的数据标注和在全量数据上进行精调,只需要编写提示词并获得满足要求的结果,这比精调要快很多。
另外要注意的两点是:
上下文学习是监督学习吗?
坦白讲,我不确定。相似之处在于,上下文学习也需要像训练数据一样的示例不同之处在于,上下文学习的泛化行为并不同于监督学习,这使得之前的泛化理论(例如 Rademancher Complexity 或 Neural Tangent Kernel)均不适用。上下文学习真的比监督学习效果要好吗?
答案还未知。大多数提示词和精调的对比都只比了 提示词+大模型 vs 精调+小模型,但公平的对比应该是 提示词+大模型 vs 精调+大模型,且对比时的基座模型应该一样。所以在最初的思维链文章中,如果 Wei 等人要说明提示词好于精调,他们应该对比精调后的PaLM,而不是GPT3。我的假设是:精调可以提高分布内的性能,但会损害分布外的鲁棒性。提示词在分布变化的场景中表现更好,但在同分布场景下不如精调。· 如果假设是真的,那么一个值得研究的问题就是如何在不牺牲其上下文学习能力的情况下进行精调
·注意分布外精调的效果同样会随着模型尺寸变化。比如 Yang 等人在2022年的工作中,第四张表就显示,Bart-based的分布外泛化能力会下降,但Bart-large则提升。对于大模型,当测试集的分布和训练集相差不大时,同分布的精调效果也应该会提升。
再回顾一下前文提到的的逻辑:如果精调更好,我们应该努力研究如何进行参数高效的优化;如果提示词更好,我们应该努力去训练更好的大型语言模型。
所以,尽管我们相信大型语言模型有巨大的潜力,仍然没有确凿的证据表明精调和提示词哪种方法更好,因此我们不确定范式是否真的应该转变、或应该转变到什么程度。仔细比较这两种范式,使我们对未来有一个清晰的认识,是非常有意义的。我们将更多讨论留到下一篇文章。
五、模型应该多大才够?
两个数字:62B 和 175B。
模型至少需要62B,使思维链的效果才能大于标准的提示词方法。模型至少需要175B(GPT3的尺寸),思维链的效果才能大于精调小模型(T5 11B)的效果。62B这个数字来自于 Chung 等人 2022 年工作的第五张表[24]:

对于所有小于62B的模型,直接用提示词都好于思维链。第一个用思维链更好的模型是 Flan-cont-PaLM 62B 在BBH上的结果。540B的模型使用思维链会在更多任务上得到好的效果,但也不是全部任务都好于精调。另外,理想的尺寸可以小于 540B,在 Suzgun 等人2022年[25]的工作中,作者展示了175B的 InstructGPT 和 175B的 Codex 使用思维链都好于直接用提示词。综合以上结果,我们得到了63B和175B两个数字。所以,如果想要参与这场游戏,首先要有一个大于平均尺寸的模型。
不过,还有其他大型模型在思维链下的表现差了很多,甚至不能学到思维链,比如 OPT、BLOOM 和 GPT-3 的第一个版本。他们的尺寸都是175B。这就引出了我们下一个要讨论的问题。
六、规模是唯一的因素吗?
不是。
规模是一个必要但不充分的因素。有些模型足够大(比如 OPT 和 BLOOM,都是 175B),但并不能做思维链。
有两种模型可以做思维链 (TODO: add discussions about UL2):
GPT3系列的模型,包括 text-davinci-002 和 code-davinci-002 (Codex)。这是仅有的两个具有强大突现能力并可公开访问的模型。· 除了以上两个模型,其他GPT3模型,包括原来的GPT3,text-davinci-001,以及其他更小的GPT-3模型,都不能做思维链。· 当说“能做思维链”时,我们是指使用思维链方法的效果比直接用提示词、精调T5-11B效果更好。
· 另外要注意的是,code-davinci-002 在语言任务上的性能始终优于 text-davinci-002。这个观察非常有趣且耐人寻味。这表明基于代码数据训练的语言模型可以胜过根据语言训练的语言模型。目前为止我们还不知道是为什么。
PaLM系列模型,包括 PaLM、U-PaLM、Flan-PaLM 和 Minerva。这些模型目前还未开放访问(此处@谷歌,快开源吧)。为什么会有突现能力目前还不清楚,但我们找出了一下可能产生突现能力的因素:
指令精调:GPT-3 text-davinci-002 就是用指令+强化学习精调[26]的产物。其、、在这之前,text-davinci-001 做思维链的效果并不好。同时PaLM[27]在经过指令精调[28]后的效果也有提升。在代码上精调:Codex code-davinci-002 是在代码上进行精调的,它的效果持续好于 text-davinci-002。PaLM 也在代码上进行了调整。从表面上看,代码与语言关系不大,但似乎起了很大作用,我们会在之后的文章进行讨论。用思维链精调:在 text-davinci-002 发布时,谷歌已经发布 PaLM 3 个月了。所以 OpenAI 应该看到了思维链相关的工作。还有一些工作表明[29][30],直接用思维链数据进行精调可以激发模型的思维链能力。然而,所有这些因素在现阶段都是推测。揭示如何训练才能让模型产生突现能力是非常有意义的,我们将更多讨论留到下一篇文章。
七、总结
在本文中,我们仔细研究了语言模型的突现能力。我们强调了复杂推理、知识推理和分布外鲁棒性的重要性和其中存在的机会。突现能力是非常令人兴奋的,因为它们可以超越比例定律,并在比例曲线中表现出相变。我们详细讨论了研究范式是否会真的从精调转向上下文学习,但我们目前还没有确切答案,因为精调和上下文学习在分布内、分布外场景下的效果仍有待对比。最后,我们讨论了产生突现能力的三个潜在因素:指令精调、代码精调和思维链精调。非常欢迎大家提出建议和讨论。
另外我们还提到了两个尚未讨论的有趣问题:
我们是否能公平对比精调和上下文学习的效果?我们是如何训练大模型,才能让模型具备突现能力、思维链能力?对于这两个问题,我们会在之后的文章中进行讨论。
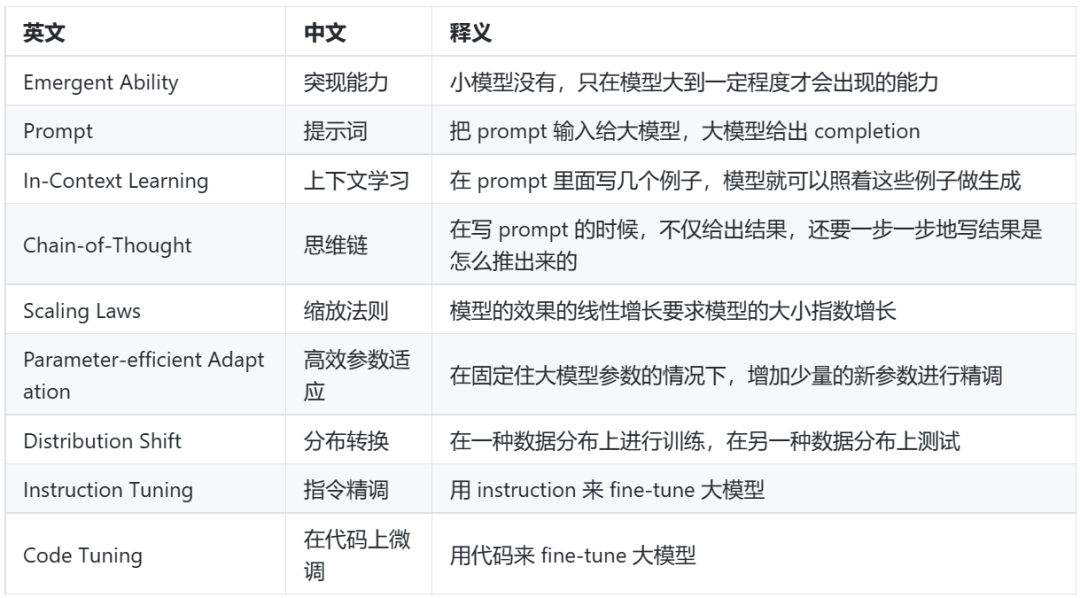
中英对照表
参考
[1] https://www.yitay.net/blog/emergence-and-scaling: https://www.jasonwei.net/blog/emergence
[2] Wei et. al. 2022. Chain of Thought Prompting Elicits Reasoning in Large Language Models: https://arxiv.org/abs/2201.11903
[3] 便签本: https://lingo.csail.mit.edu/blog/arithmetic_gpt3/
[4] Wei et. al. 2022. Emergent Abilities of Large Language Models: https://arxiv.org/abs/2206.07682
[5] Wei et. al. 2022. Emergent Abilities of Large Language Models: https://arxiv.org/abs/2206.07682
[6] Cobbe et. al. 2021. Training Verifiers to Solve Math Word Problems: https://arxiv.org/abs/2110.14168
[7] Wei et. al. 2022. Chain of Thought Prompting Elicits Reasoning in Large Language Models: https://arxiv.org/abs/2201.11903
[8] Wang et. al. 2022. Self-Consistency Improves Chain of Thought Reasoning in Language Models: https://arxiv.org/abs/2203.11171
[9] Fu et. al. 2022. Complexity-Based Prompting for Multi-step Reasoning: https://arxiv.org/abs/2210.00720
[10] Chung et. al. 2022. Scaling Instruction-Finetuned Language Models: https://arxiv.org/abs/2210.11416
[11] Lewkowycz et. al. 2022. Minerva: Solving Quantitative Reasoning Problems with Language Models: https://arxiv.org/abs/2206.14858
[12] Jiang et. al. 2022. Draft, Sketch, and Prove: Guiding Formal Theorem Provers with Informal Proofs: https://arxiv.org/abs/2210.12283
[13] Xu et. al. 2021. Fusing Context Into Knowledge Graph for Commonsense Question Answering: https://aclanthology.org/2021.findings-acl.102.pdf
[14] Khashabi et. al. 2020. UnifiedQA: Crossing Format Boundaries With a Single QA System: https://aclanthology.org/2020.findings-emnlp.171
[15] Yu et. al. 2022. Generate rather than Retrieve: Large Language Models are Strong Context Generators: http://arxiv.org/abs/2209.10063
[16] Jung et. al. 2022. Maieutic Prompting: Logically Consistent Reasoning with Recursive Explanations: https://arxiv.org/abs/2205.11822
[17] Si et. al. 2022. Prompting GPT-3 to be Reliable. : https://arxiv.org/abs/2210.09150
[18] Fu et. al. 2022. Complexity-based Prompting for Multi-Step Reasoning: https://arxiv.org/abs/2210.00720
[19] Kaplan et. al. 2020. Scaling Laws for Neural Language Models: https://arxiv.org/abs/2001.08361
[20] Brown et. al. 2020. Language Models are Few-Shot Learners.: https://arxiv.org/abs/2005.14165
[21] Cobbe et. al. 2021. Training Verifiers to Solve Math Word Problems: https://arxiv.org/abs/2110.14168
[22] Li and Liang. 2021. Prefix-Tuning: Optimizing Continuous Prompts for Generation: https://aclanthology.org/2021.acl-long.353.pdf
[23] He et. al. 2021. Towards a Unified View of Parameter-Efficient Transfer Learning: https://arxiv.org/abs/2110.04366
[24] Chung et. al. 2022. Scaling Instruction-Finetuned Language Models: https://arxiv.org/abs/2210.11416
[25] Suzgun et. al. 2022. Challenging BIG-Bench tasks and whether chain-of-thought can solve them: https://arxiv.org/abs/2210.09261
[26] Ouyang et. al. 2022. Training language models to follow instructions with human feedback: https://arxiv.org/abs/2203.02155
[27] Chowdhery et. al. 2022. PaLM: Scaling Language Modeling with Pathways: https://arxiv.org/abs/2204.02311
[28] Chung. et. al. 2022. Scaling Instruction-Finetuned Language Models: https://arxiv.org/abs/2210.11416
[29] Huang et. al. 2022. Large Language Models Can Self-Improve: https://arxiv.org/abs/2210.11610
[30] Chung. et. al. 2022. Scaling Instruction-Finetuned Language Models: https://arxiv.org/abs/2210.11416
Illustration by M Wildan maulana from IconScout
-The End-
@将门创投· 让创新获得认可
如果喜欢,别忘了赞同、关注、分享三连哦!~笔芯❤

AI时代,掌握AI大模型第一手资讯!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
扫码右边公众号,驾驭AI生产力!



