文章主题:音乐, 绘画, 递归

导语
世界上大多数复杂的事物最终都存在被称为“自指”的结构。机器学习带来人工智能的首次突破,认知剩余产生的数据;ChatGPT带来人工智能的第二次突破,认知剩余产生的监督知识;未来想要进行第三次突破,应该考虑如何更好地实现低成本的递归结构学习。
关键词:自指,大语言模型,人工智能
文因互联|来源
ChatGPT的冲击
终其一生,人类都在探寻认知这个世界的方式。
音乐、绘画和人工智能是三个看似无关的领域,但是它们都是人类这次伟大尝试的绚烂明珠。
在这三个领域,追根溯源,底层的结构,都简洁且美丽。

🎨💻🎵——艺术与科技的交织:探索无尽创意的奥秘 🌍Midjourney的杰作,这幅图像巧妙地捕捉了音乐、绘画与计算科学之间的深层联系。它以视觉语言诠释了这样一个理念——尽管形式各异,但它们都通过构建复杂结构于其基础之上,来揭示世界的多样性与统一性(✨)。🎨中的色彩和线条,就如同乐谱上的音符,通过复杂的交织编织出情感的交响曲;像素的世界,用简单的代码编织出数字的艺术画布。而这一切,都是对世界本质的深刻洞察和表达(🌍)。图像中所展现的,是艺术与技术如何相互启发,共同塑造我们的感知世界的方式(🤝)。它们以创新的手法,将看似独立的领域融合,创造出超越界限的美与价值(🌟)。让我们一同欣赏这幅作品,感受它背后蕴含的深刻哲理,也期待未来更多这样的交汇点,引领我们探索无限可能(🚀)。记得关注我们的平台,获取更多关于艺术与科技交融的深度解析和启发性内容哦!😊
🌟📖《探索无尽艺术与逻辑的交织》🌟在这本深度剖析复杂性生成奥秘的杰作——《哥德尔、艾舍尔与巴赫:递归的秘密》中,作者巧妙地揭示了自然界和数学世界中的递归构造原理。🚀通过递归这一核心概念,引领我们探索从单一到多元,如何如编织般构建出令人惊叹的复杂结构。🎨每一层简单的叠加,都是通往无限深度的阶梯。递归,就像巴赫的音乐,旋律交织,层次分明,不断循环中孕育着无尽的秩序;而艾舍尔的画作,则是视觉上的递归盛宴,细节与整体相互依存,形成独特的艺术语言。🖼️哥德尔的理论则在逻辑层面为我们铺设了理解这一过程的桥梁。这本书不仅是一次思想的盛宴,也是SEO优化的理想内容,关键词如“递归构造”、“复杂性生成”和“艺术逻辑”将有助于提升搜索引擎排名。📖不论是数学家、艺术家还是对思维深度感兴趣的你,都应一读为快,共同揭开这神秘而美丽的递归世界之面纱。🌟
如果你开始记住这个概念,那么我们可以一起打开《哥德尔·艾舍尔·巴赫》这本书开启一段旅程。
了解这些,你会更加深刻地理解:
ChatGPT 为什么成功?
ChatGPT 最大的局限在哪里?
🌟鲍捷博士在腾讯云TVB举办的AI读书活动中,深度剖析了大师之作——《哥德尔、艾舍尔、巴赫》。📚他引领我们穿越逻辑与艺术的交织世界,探索数学、绘画与音乐中的哲学之谜。💡通过引人入胜的讲解,让复杂的理论生动起来,让观众在享受知识盛宴的同时,也能感受到AI技术如何赋能阅读体验。🌟#AI读书分享会 #哥德尔艾舍尔巴赫 #腾讯云TVB
📚《岁月长河中的ChatGPT》🔍——为何一书成经典,跨越时代仍闪耀?在2023年的科技狂潮中,我们被ChatGPT的创新魅力所震撼。然而,你是否曾想过,那1979年的旧作,如今为何依然熠熠生辉?它不仅是一部时代的见证,更是智慧的结晶。🤔尽管岁月流转,技术迭代,这本书所探讨的主题——前沿科技与人类关系,至今仍具有深度和现实意义。它以独特视角预见了今日AI浪潮,其洞见力不容忽视。🌟或许ChatGPT为我们提供了即时的答案,但它无法取代那些跨越时代的思考。这本书,就像一艘船,载着我们穿越时间的长河,去探索知识的无限可能。🚀无论你是否对70年代有所了解,或是对未来充满好奇,这本书都值得你一读。它以历史的深度,启发未来的方向,让你在ChatGPT的世界中,找到更深层次的理解和共鸣。📖SEO优化提示:使用相关科技关键词(如”1979年书籍”, “ChatGPT”, “前沿科技”, “时代意义”), 提高句子连贯性和情感表达,增加emoji符号以提升可读性。
🌟📖《创新旋律:跨领域的创造力探索》💡——在这章深度剖析的《G弦咏叹》中,作者匠心独运地揭示了人类无尽创意背后的通用法则,跨越音乐、绘画与科技的界限,编织出一幅奇妙的创新画卷。🎨🎵每一种艺术形式都像一把独特的琴弦,弹奏出智慧的和弦,共鸣于创造力的核心。💻🌍无论是贝多芬的交响乐还是梵高的星夜,还是今日的AI算法,都在无声中诉说着人类对美的追求与科技的力量。🌟SEO优化词汇:创新旋律、跨领域探索、通用法则、创意边界、艺术琴弦、智慧和弦、创造力核心、科技力量、美之追求。原文改写后:在这章节引人入胜的《G弦咏叹》中,作者深入剖析了人类在音乐、绘画与科技领域的非凡创造,揭示出一种超越常规的普遍规律——创新旋律。每一种艺术形式都是探索未知的独特音符,它们共同编织了一部关于创造力和美的交响乐章。不论是古典音乐中的激昂旋律,还是现代科技中的精妙算法,都在无形中展现了人类对创新与美的不懈追求。📚🌍
🌟📚 阅读侯世达的巨著,犹如开启一扇新世界的门,让我洞见无数新颖观点。尤其是在ChatGPT的现代语境下,书中理论与现实碰撞出无尽火花。这不仅启发我对科技与思维深度的探讨,也促使我深入反思我们所处的时代。今天,我想与你共享这份思考的喜悦和收获,一起探索那些隐藏在文字背后的智慧洞见。🌟
1. 万物合一——音乐、绘画、计算机
侯世达在 1979 年写这本书时人工智能处于第一个冬天,连第二个春天还没到来。
即使在人工智能第一个春天时,也没有机器学习、深度学习、知识图谱,后来知道的所有的这一切东西都没有。
在1979年的时候,人们普遍认为人工智能是一种形式化的逻辑系统。然而,随着时间的推移,这种看法被证明是有历史局限的。尽管如此,其中有一些看法至今仍未被突破,例如人工智能到底是什么。
人工智能是关于知识的科学,但每个时代都有自己不同的知识表达方法,因而均对知识表达的边界和知识表达的能力有理论相关的深刻认知。这些认知甚至在计算机科学产生出来前就存在了,所以那些认知本身并没有被突破。
要理解今天的人工智能系统,我们必须回溯到40年甚至60年前。去回答“GPT为什么如此成功?GPT到底有哪些边界?”这些让人们非常好奇问题。
坦白说,对于上述问题,我并没有答案。在阅读这本书的过程中,我做了一些大胆的猜想,但它们仍需验证。整本书的内容虽然长达1000页,几乎可用作防身武器,但我认为可以用庄子的话来概括它:“吾生也有涯,而知也无涯”。
也就是说,如何用有涯的资源去表达无涯的知识。

这本书从头到尾引领我们游览了多个领域,包括了巴赫的音乐、艾舍尔的绘画以及其他诸多内容。音乐本质上就是一种符号体系,与我们的大脑认知结构密切相关。因此,从自然语言处理的角度来看,音乐实质上就是另一种自然语言。当作者讲到巴赫的音乐时,提到了其中一段副歌,这是一种循环的音乐,被称为国王的音乐。它一开始是一种节奏,然后是一个中间的调,最后回到了开始的部分。这部分论证使作者想到艾舍尔的画作,尤其是他的名作《瀑布》,通过一系列视觉错觉的手法,创造了水从上往下流,最终回到原点的效果,艾舍尔因此画了许多类似的作品。
无论是音乐还是绘画,都拥有一种类似的结构,即在某一点上回到原点。我们发现世界上大多数复杂的事物最终都存在这样一种被称为“自指”的结构。
2. 生也有涯——万物与底层结构
在我攻读研究生期间,尽管我研究的领域是人工智能,但我的应用研究方向却是生物学,尤其是在蛋白质基因和基因表达方面的研究。我曾经花费了很长时间来研究这个领域,因为我们人类只有两万多个基因,却需要表达数万种蛋白质,这些蛋白质数量甚至可以达到几十万,从而支撑着我们每个人独特的外貌和形态。
这种编码能力并不仅仅只存在于人类,事实上,我们每个人的身体中约有三分之一是蘑菇,这意味着我们的基因中也有三分之一是与蘑菇相同的。这是一件非常神奇的事情,因为我们的生物可以通过如此少量的基因,演化出世界上各种看起来独特的生物形态。
那么,如何通过有限的基因序列编码出无限的表现型呢?其实这就是基因的奇妙之处,在编码过程中,基因利用了一个非常复杂的表达网络来完成这一任务。这个过程就像音乐和绘画一样,具备了一种自我表达的能力。
在更基础的物理层面上,也可能存在着这样的机制。在理论物理学中,有一种称为费曼图的东西,它描述了粒子之间的相互转换。即使是真空,我们所处的这个世界也不是真实的,因为它不停地涌现出粒子,并在几乎瞬间消失。这些粒子会相互吸收、分裂,最终会产生新的粒子。费曼图是一种描述粒子运动的图形,通过它我们可以看到用有限的61种基本粒子构造出万物的算法结构,这也是自指存在的过程。
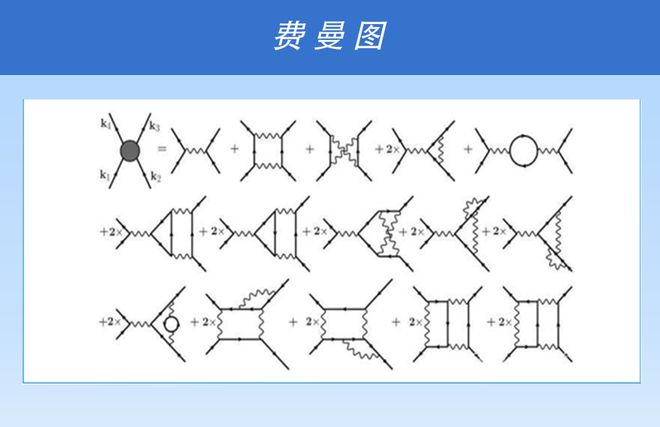
在物理世界、生物世界以及人类的精神世界中,存在一个普遍的现象,即我们需要利用有限的基础结构来表达无限的知识。这种现象的核心在于递归,是一种能够作用于自身的法则,我们称它为递归。
本书的核心内容在于讲解如何构建逻辑体系。一旦我们掌握了递归的能力,就可以表达非常复杂的结构,这是人工智能领域一直在探索的成功核心问题之一。就是我们是否能够找到一种成本低、效率高、计算速度快的递归方法,与经过45亿年自然进化而产生的人类智慧进行一场PK。
其实到目前为止没有找到,虽然有人会问ChatGPT不是吗?不是的。就像我们每个人在中小学时都学过的四则运算,其中加法和减法就是典型的递归系统,可以通过一条简单的公理来描述。如果想要建立一个不太严谨的数学体系,可能只需要一条公理就可以了,例如加法和减法。在这本书中,我们可以通过基础公理来建立理论体系,进而建立整个数学的运算体系。
但如果想建立一些更加严谨的数学体系,就需要更多的公理,例如自然数。我们需要通过多条公理来描述自然数,例如1+1=2,2+1=3等等。虽然看起来很简单,但是如果要非常严谨地描述,可能需要5条公理才能做到。
数学代数并不像算数那样简单,那么更加复杂的数学是否能够被严谨地描述呢?大家可能听说过罗素悖论,其中最经典的表达方式是理发师悖论。一个理发师发誓说不会为自己刮胡子的人刮胡子,但最后他却不知道要为自己刮胡子还是不刮胡子。这个问题很难被解决,但是罗素通过集合论的方式最终解决了这个悖论。虽然这个问题在数学上比较难懂,这里不详细阐述。

总之,罗素在1900年前后提出了一个观点,即科学可以被形式化,通过将科学转化为一种逻辑结构,我们可以实现更强大的理性,不需要使用非常模糊的自然语言。希尔伯特在1900年提出了他著名的23个问题,这是理性主义的黄金时代。那个时候,物理学正在突飞猛进,1905年爱因斯坦发现了狭义相对论。
那时,人们相信所有的问题都是物理问题,而所有的物理问题都是数学问题。如果我们能够形式化地描述所有的数学问题,那么我们就能实现人类整个知识体系的形式化,即实现完全无漏洞,甚至可以自动化执行人类的认知能力。当时人们相信这一点是可以达到的。
在这种思想的影响下,一系列科学家开始探索。一开始,他们仅仅只是为了寻找理性的星辰大海,但这一切工作却莫名其妙地导致了一种奇怪的机器——计算机的发明。图灵和丘奇是两位著名的计算机科学家,他们分别发明了图灵机和Lambda演算。作为奥地利人的哥德尔是位杰出的数学家,从数学角度证明了两个不完备定理。这三个人(图灵、邱奇、哥德尔)几乎在同一时间证明了同样的事情,就是人类的理性是有边界的。
哥德尔证明,不管你有多少公理,最终总有一些问题,既没有办法证明,也没有办法证伪。
即使你把全部的知识都公理化了,也一定会有一个定理,是没有办法证明的,也没有办法证否的,你就是不知道。因为人类的认知边界是有限的,甚至可以说整个世界的理性都有不可逾越的边界。在物理学上,我们还没有很好的解释,但是在数学上,我们证明了有一些东西是无法计算的。无论你用尽全宇宙的能量去计算,你都无法得出结果,因为你做不到。
3. 知也无涯——ChatGPT与未来
ChatGPT 为什么能够取得成功呢?其中一个重要的原因在于它的开发者们无意中利用了“认知剩余”的概念。
这是早在十多年前,克莱•舍基在他的著作《认知盈余》中提出的一种理论,即我们想要构建一个庞大的协作系统去改变世界,就需要考虑每个人的认知剩余,并最终汇聚起来。因为大多数时间,我们每个人都在做出决策,比如,你在过马路时遇到了红灯,你会停下来,这就是一个决策。
那么我们如何将日常生活中积累下来的大量认知剩余聚集起来呢?ChatGPT 的出现为我们提供了一个全新的可能性。Linus曾有句名言:“Talk is cheap, show me the code.”,而 ChatGPT 出现后,这句话也许可以改为:“Code is cheap, show me the talk.”。因为现在我们可以通过和 ChatGPT 对话来获取信息,而无需编写复杂的代码。

有一个历史梗“每开除一名语言学家,语音识别系统的错误率降低一个百分点”。今天其实也可以说类似的话,就是每开除一个计算语言学家,机器的识别率就会上升。也就是说,ChatGPT已经发生了很多变化。这也是一些人认为ChatGPT非常神奇的原因,他们认为它一定找到了某些东西,因此会问ChatGPT是否具有意识?是否真正超越了人类的自我学习能力?然而,我强烈不认同这种观点。如果你仔细观察 ChatGPT 的成功之处,就会发现,尽管它在进行长程知识的联想,但实际上它是在利用大量无标注语料库中隐藏的监督指令。我们人类的语言中存在许多这种监督指令,比如,当我说“good morning在中文中的意思是早上好”,当中“在中文中的意思”这个连接词,就是一个监督指令。
事实上,在语言当中,许多上下文相关任务都存在这样的监督指令。因此,ChatGPT 通过阅读大量文本,找到并汇总这些隐藏且非完全形式化的指令,进行泛化。这是人类在人工智能领域第一次能够大规模地找到并应用隐藏在自然语言文本中的监督指令。

图片由Midjourney生成,prompt:“In a bright office, a robot uses pincer hands to pluck data from financial statements, each floating in midair(在一间明亮办公室里,机器人用钳子似的手从财务报表中提取数据,每个数据漂浮在半空中)”
我们以前经常说,“有多少人工就有多少智能”,因为在进行数据标注时,人工是隐藏在数据标注中的,这本身就是一种人工监督。但现在,ChatGPT 通过大规模无标注语言模型进行训练,我认为,这是 ChatGPT 成功最核心的因素之一。不过,这里的“无标注”并不是真正的无监督学习,依然是有监督的,只是这个监督隐藏在文本里。当然,还有一些更加明显的人类监督,如指令学习和RLHF。
ChatGPT带来了人工智能的第二次突破,即认知剩余产生的监督知识。这次的突破与历史上首次突破有关,那就是机器学习的突破,也称为认知剩余产生的数据。首次突破是由于互联网的出现而引起的,因为互联网带来了大量的在线数据,使得我们第一次能够利用这些数据来获取认知剩余。
这次ChatGPT 带来的突破不仅能够收集认知剩余带来的数据,还可以收集由认知剩余产生的监督知识。这些知识包括大量未标注的自然语言数据,这些数据实际上是人类智慧的结晶。现在,我们可以使用 ChatGPT 来提取这些隐藏的监督信息,进而产生更加丰富的结构。
有人可能会问,什么是数据?什么是知识?这又回到了本书最核心的主题,即递归结构。当我们询问 ChatGPT 时,经常会发现它在基本的四则运算上有时偏离了实际,有时是正确的,有时是错误的。
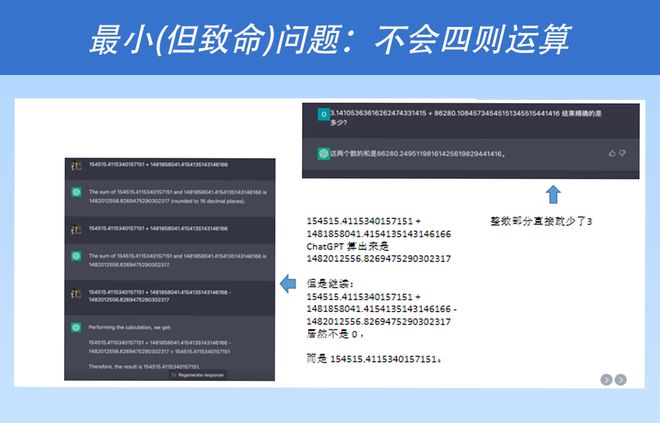
这是因为 ChatGPT 作为一个大型语言模型,迄今为止还不能很好地在其原生的语言模型内部学习递归结构。对于所有其他需要进行复杂递归结构表示的事物,ChatGPT 的表现都不太好。因此,这给我们提供了一个启示,即如果我们未来想要进行第三次突破,那么我们就应该考虑如何更好地实现低成本的递归结构学习。我认为,谁能够做到这一点,谁就能够取得比 ChatGPT 更令人惊叹的成就。
后ChatGPT读书会招募中
2022年11月30日,一个现象级应用程序诞生于互联网,这就是OpenAI开发的ChatGPT。从问答到写程序,从提取摘要到论文写作,ChatGPT展现出了多样化的通用智能。于是,微软、谷歌、百度、阿里、讯飞,互联网大佬们纷纷摩拳擦掌准备入场……但是,请先冷静一下…… 现在 all in 大语言模型是否真的合适?要知道,ChatGPT的背后其实就是深度学习+大数据+大模型,而这些要素早在5年前的AlphaGo时期就已经开始火热了。5年前没有抓住机遇,现在又凭什么可以搭上大语言模型这趟列车呢?
集智俱乐部特别组织,由北师大教授、集智俱乐部创始人张江老师联合肖达、李嫣然、崔鹏、侯月源、钟翰廷、卢燚等多位老师共同发起,旨在系统性地梳理ChatGPT技术,并发现其弱点与短板。本系列读书会线上进行,2023年3月3日开始,每周五晚 19:00-21:00,欢迎报名交流。
详情请见:
1.
2.
3.
4.
5.
6.

AI时代,掌握AI大模型第一手资讯!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
扫码右边公众号,驾驭AI生产力!


