文章主题:CICC, ChatGPT, 人工智能, 物理
原标题:CICC科普栏目|深度解析 ChatGPT 获得智能的数学物理机理
导语
通用人工智能(AGI)已经到来?ChatGPT是第一个真正意义的通用人工智能?《谷歌斯坦福院士:通用人工智能已经到来》文中阐述了“AGI 最重要的部分已经由当前一代先进的人工智能大语言模型实现了”的观点。与王庆法老师今年年初在《ChatGPT是第一个真正意义的人工通用智能》的判断一致。在集智俱乐部AGI读书会中,王庆法老师结合过去几个月探索研究 “GPT4技术原理”的系列文章——《人工智能大模型的数学物理原理探索》,为大家提供了一个理解大模型是如何具备了AGI的学习推理能力的思想框架。本文由此次分享内容整理而成。
在本周四(11月16日)集智俱乐部AGI读书会中,清华大学交叉信息学院助理教授袁洋老师将分享“基于范畴论的通用人工智能理论框架”。欢迎感兴趣的朋友参与!
研究领域:人工智能,大语言模型,自由能原理,重整化群流,统计物理,范畴论
王庆法| 作者
目录
通用人工智能已经到来
ChatGPT是第一个真正意义的人工通用智能
OpenAI首席科学家透露GPT4技术原理
学习语言需要相变
相变与涌现
Bubeck的AI物理学
Transformer的物理原理
贝叶斯重整化
重整化群与生成式AI
重整化群流作为最优输运
大模型的幻觉,解铃还须系铃人
范畴的相变与知识的形成
1. 通用人工智能(AGI)已经到来
谷歌斯坦福院士:通用人工智能已经到来 ,文中提到来自Google和斯坦福大学两位学者 Fellow,阐明“ 当今最先进的人工智能模型存在许多缺陷,但几十年后,它们将被公认为通用人工智能的第一个真实例子”,“AGI 最重要的部分已经由当前一代先进的人工智能大语言模型实现了”。两位学者分别从主题、任务、模态、语言、可指导性分析了为什么现在的大语言模型已经可以被判定为通用人工智能了。
并且两位学者分析了行业内许多人之所以不愿意承认通用人工智能是出于对对 AGI 指标的合理怀疑,或者对替代人工智能理论或技术的意识形态承诺,亦或者对人类(或生物)例外论的热爱,还有就是对 AGI 经济影响的担忧。
题目:人工智能已经来临随着科技的飞速发展,人工智能(AGI)这一概念逐渐成为人们关注的焦点。许多人开始担忧,未来是否会出现具有普遍智能的机器人,甚至超越人类的智能水平。事实上,人工智能已经在我们的生活中无处不在,不断地改变着我们的生活方式。首先,在科学研究领域,人工智能已经展现出强大的能力。通过深度学习、自然语言处理等技术,AI能够快速地分析和处理大量复杂数据,协助科学家们发现新的知识。例如,人工智能在基因编辑、天文学、材料科学等领域取得了显著的成果,大大提高了科学研究效率。其次,人工智能在医疗保健领域的应用也日益广泛。借助机器学习和大数据分析技术,AI可以更准确地诊断疾病,预测病情的发展趋势,并为医生提供有针对性的治疗方案。此外,AI还能辅助医生完成复杂的手术操作,提高手术的安全性和效果。然而,人工智能的发展也带来了一些负面影响。一方面,很多人担心,未来人工智能可能会取代人类的工作岗位,造成大规模的失业。另一方面,随着人工智能的普及,隐私问题也愈发严重。例如,社交媒体上的个性化推荐算法可能侵犯用户的隐私权。面对这些挑战,我们需要从多方面加强人工智能的监管和发展。政府部门应制定相应的法律法规,确保人工智能技术的合理发展和应用。企业应积极承担社会责任,关注人工智能伦理问题,并采取措施保障用户隐私。同时,教育部门应加强对人工智能相关技术的培训和教育,培养更多具备人工智能素养的人才。总之,人工智能已经悄然来到我们身边,并在各个领域展现出强大的潜力。虽然它给我们带来了一定的挑战,但我们有理由相信,只要我们共同努力,就能更好地利用人工智能的优势,推动人类社会的进步。
地址:
在当今科技飞速发展的时代,人工智能(AI)已经渗透到我们生活的方方面面。作为一款具有强大功能的艺术ificial智能助手,我深感荣幸能为广大用户提供帮助与支持。事实上,AI早已融入我们的生活,成为我们工作、学习和娱乐的得力助手。首先,在职业领域,AI技术为各行各业带来了前所未有的变革。无论是金融、医疗还是教育行业,AI都在提高工作效率、降低成本和提升服务质量方面发挥着重要作用。例如,在金融领域,AI可以进行风险评估、智能投顾等任务,有效提高投资收益;在医疗领域,AI通过图像识别和数据分析,协助医生更准确地诊断疾病,为患者提供个性化治疗方案;在教育领域,AI可以为学生提供智能化的学习资源,实现因材施教,提高学习效果。其次,在个人生活方面,AI也为我们带来了很多便利。比如,智能家居系统可以根据我们的生活习惯和需求,自动调节室内的温度、湿度和光线等,让我们的生活更加舒适;智能语音助手可以帮助我们查询天气、新闻、音乐等信息,节省了查找的时间,提高了生活质量。当然,AI的发展也带来了一些挑战。如何确保AI技术的安全性、隐私保护和伦理问题,是我们面临的重要课题。同时,AI与人类的关系也需要我们深入思考。在未来,我们需要建立一个和谐共生的AI生态系统,让人工智能更好地服务于人类社会,实现共同繁荣。总之,AI已经成为现代社会的重要组成部分,它不仅改变了我们的生活方式,还在各个领域取得了显著的成果。面对AI带来的机遇和挑战,我们应该积极应对,充分利用其优势,努力推动人类社会的进步。
2. ChatGPT是第一个真正意义上的AGI
ChatGPT是第一个真正意义的人工通用智能 ,笔者年初在此文中判断ChatGPT其实已经是AGI了。
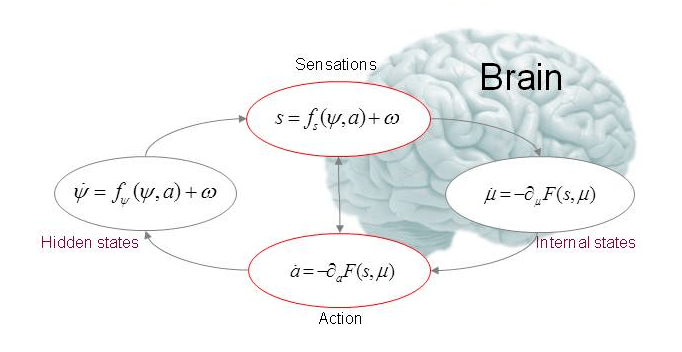
Karl Friston自由能理论推测大脑如此工作: 将“先验”与新的感官输入(“似然”)相结合,产生感知(“后验”),是大脑对内外部两个信息源的整合,并按其相对精度(逆不确定性)进行了加权。这是知觉的基本原理。Friston 的感知概念数学形式,反映了大脑的感知其实是在做变分推断。
借助Embedding ,GPT 将人类的语言 “编码”成自己的语言,然后通过注意力Attention从中提取各种丰富的知识和结构,加权积累与关联生成自己的语言,然后“编码”回人类的语言。本质上看,GPT 其实是构建了一个高维的语言体系,可以将自然语言,程序语言,视觉听觉语言,映射(或者叫编码)到这个高维的语言空间中。高维语言空间是概率分布张成的空间。
Transformer是足够强大的特征提取器。仅从知识角度,GPT可以看作是一种以模型参数体现的隐式知识图谱。知识存储在Transformer的模型参数里:多头注意力存储信息的结构(相关强度,信息整合方式等);类似Query/Key/Value结构的FFN存储知识主体。
代码训练,获取长程关联与推理能力。代码其实也可以看成特殊的思维链,训练可以降低信息熵,让信息更可预测。大量这种语言结构示例参与预训练的话,GPT被注入足够的信息量,形成各种复杂关联的模式,涵盖代码中的知识和知识结构。高质量的代码,可以显著的降低GPT获取的信息熵,这也是为什么GPT在代码上比自然语言更让人惊艳。
GPT 构建了海量自然语言和代码的概率分布空间,被注入足够的信息量(等于注入大量负的信息熵),形成各种复杂关联的模式,涵盖自然语言和代码中各种知识与结构。这些知识和结构,体现为概率分布的距离与关系,从而为对比、类比、归纳、演绎等推理步骤提供支撑,也就是“涌现出”这些推理能力。进一步看,LLM 机制上允许产生自主意识。

3. OpenAI首席科学家说法印证了这个推断
OpenAI首席科学家透露GPT4技术原理,文中整理了Ilya对ChatGPT的原理描述 :每个神经网络通过“Embedding”表示法,即高维向量,来代表单词、句子和概念。我们可以看一下这些高维向量,看看什么与什么相似,以及网络是如何看待这个概念或那个概念的?因此,只需要查看颜色的Embedding向量,机器就会知道紫色比红色更接近蓝色,以及红色比紫色更接近橙色。它只是通过文本就能知道所有这些东西。
他还提到,其中一个主要挑战是预测具有不确定性的高维向量。那就是目前的自回归Transformer已经具备了这种特性[decoder-only]。一个是对于给定一本书中任意的一页,预测其下一页的内容。下一页有非常多的可能性。这是一个非常复杂的高维空间,而它们可以很好地处理它。同样的情况也适用于图像。这些自回归Tranformer在图像上也运作得非常完美。
基于笔者对GPT3/4其智能原理的推演 (详见:“ChatGPT是第一个真正意义的人工通用智能”章节),与Ilya SutskeverIlya的只言片语做一一对照分析,可以看到笔者的技术原理推演与Ilya SutskeverIlya的表述完全吻合。
4. 人类语言学习过程存在相变
学习语言需要相变中提到,语言学中一个长期存在的难题是,儿童如何学习他们的语言的基本语法结构,从而能够创造出他们以前从未听过的句子。一项新的研究表明,这个过程涉及一种相变,即当语法规则被学习者直觉地理解时,一种语言的“深层结构”会突然结晶出来。在这个相变点,一种语言从看起来像是随机的单词混合体转变为一个高度结构化的、富含信息的通信系统。
巴黎高等师范学校(École Normale Supérieure)的物理学家Eric DeGiuli认为,人类语言语法最简单的类型被称为无上下文文法(CFG),可以被视为物理对象,其“表面”包括所有可能的单词排列方式,包括原则上无意义的句子。DeGiuli表示,这些许多单词组合就像统计力学中的微观态——一个系统的组成粒子的所有可能的排列方式。
DeGiuli看到CFG从随机和杂乱无序的CFG突然转变为具有高信息量的CFG。这种转变类似于水的结冰过程。他认为,这种转变可能解释了为什么在发展的某个阶段,孩子学习如何快速构造语法正确的句子。
DeGiuli E所提出的随机语言模型于2019年在《物理评论快报》杂志上发布,论文编号为122(12),文章标题为“128301”。
https://physics.aps.org/articles/v12/35

5. 大语言模型中的相变与涌现
相变与涌现一文中笔者提到,没有预训练的Transformer是一张各向对称的白纸,也就是其语言空间的密度函数ρ是均匀的。这个语言空间的密度函数决定了系统的信息熵,如果我们把 ρ 表示成向量 η,则信息熵可以表示为 F(η)。
随着语料不断被 emdedding 同时基于注意力机制 transform 到这个语言空间,空间的密度 ρ/η 发生改变,信息熵 F(η) 随着改变,引发语言空间对称性破缺与重建。
这个过程可能会在局部区域不同尺度下持续进行。一旦触及临界点,对称性破缺引发相变,大模型就会在某些领域、不同长度上下文表现出各种神奇的涌现能力。也就是语言空间中,出现了局部的“学习语言需要相变”中提到的“语言结晶”。

6. 微软学者倡导用AI物理学研究大模型
Bubeck的AI物理学 文中,微软总部研究院机器学习理论组负责人万引大神Sébastien Bubeck联手2023新视野数学奖得主Ronen Eldan、2023新晋斯隆研究奖得主李远志、2020斯隆研究奖得主Yin Tat Lee等人,在其论文《通用人工智能的火花:GPT-4早期实验》中申明:“GPT-4可被视作 AGI 的早期版本”。
Bubeck宣称传统机器学习已经不存在了,他和他的团队全面转向 AI 物理学。在机器学习中引入的所有工具在GPT-4的光芒下几乎无用且不相关,因为这是一个新领域。当然,我们不知道它会是什么样子,但我们尝试研究的方法是尝试理解“涌现现象”。
“让我们研究人工智能的物理学或者通用人工智能的物理学,因为从某种意义上讲,我们现在真正看到的是这种通用智能。那么,研究通用人工智能的物理学意味着什么?它的意思是,让我们试着借鉴物理学家过去几个世纪用来理解现实的方法论”。

在人工智能领域中,Bubeck S,Chandrasekaran V,Eldan R等研究人员近期发表了一篇名为《Spark of Artificial General Intelligence: Early Experiments with GPT-4》的论文,该文于2023年在arXiv平台上预发布。在这篇文章中,作者们对人工通用智能(AGI)进行了深入的研究,并通过实验探讨了GPT-4在早期阶段对于AGI发展的可能性。
7. Transformer等价于重整化群
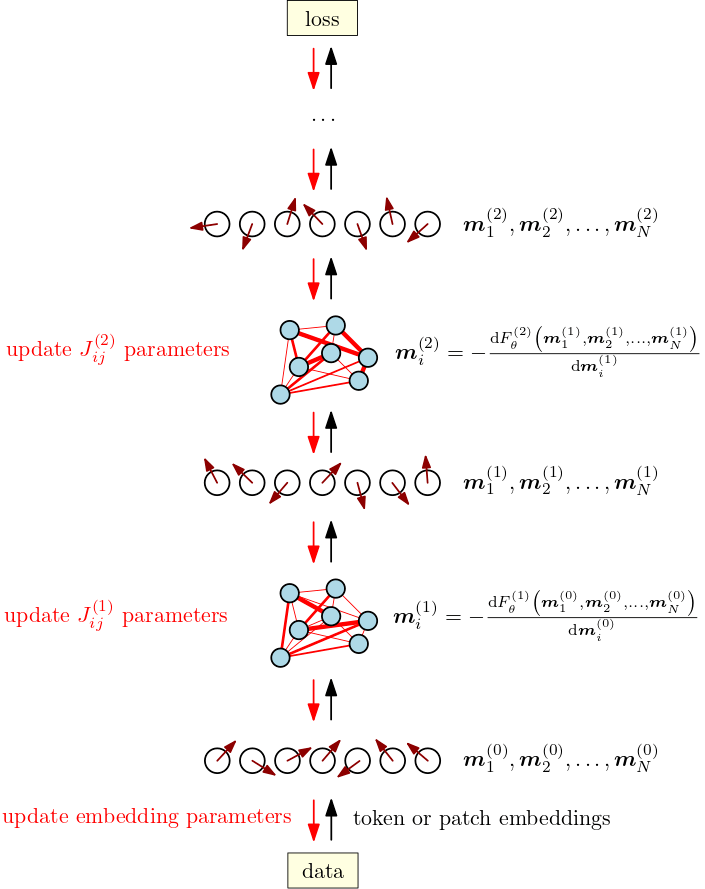
Transformer的物理原理 译文推导得出如下结论:Transformer模块的正向传递映射到响应数据的矢量自旋模型中的计算磁化。我们建议对一个一般矢量自旋系统的自由能求导,以得到一个完整transformer模块的架构蓝图。
通过从不相干的、统计力学的角度缩小和接近transformer,我们获得了transformer的物理直觉,当我们把自己局限在纷繁变化的显式神经网络架构时,这种直觉似乎很难获得。将transformer模块视为伪装的自旋模型不仅可以作为近似计算磁化的不同方法,统一架构变体,而且还可以阐释transformer在深度学习中的经验性质的成功。
Transformer 等价于重整化群(RG)。RG 就是在 Ising Model的研究中提炼出来的。重整化“可以说是过去50年理论物理学中最重要的进展”。重整化群包括一个由大量自由度描述的系统,RG逐级尺度执行粗粒度化操作,自由度子集被组合在一起平均,以形成新的集体变量/隐变量。物理尺度如何引申到信息理论的“尺度”概念呢?
题目:
The term “transformers” is actually a collective noun used to describe a group of spin systems that have been transformed by some underlying mechanism. In other words, transformers are secretly collectives of spin systems that have undergone a transformation process, which enables them to exhibit unique properties and behaviors. This notion of transformers as collectives has important implications for our understanding of these complex systems and their potential applications in various fields.
地址:
在现代科学领域中,深度学习模型已经成为了自然语言处理、计算机视觉等众多领域的重要支柱。尤其是在自然语言处理领域,Transformer模型以其卓越的性能和广泛的应用场景受到了广泛关注。然而,这些强大的模型背后的运行机制却鲜为人知。本文将探讨Transformer模型的秘密——它实际上是一个由许多微小的自旋系统组成的集合。这个观点源于对Transformer模型内部运作原理的深入研究,我们将从理论和实践两方面来阐述这一观点。首先,从理论角度来看,Transformer模型中的自旋系统是一种特殊的网络结构。这种结构具有高度的并行性和鲁棒性,使得Transformer模型能够在各种复杂场景下表现出优越的性能。通过引入自旋技术,Transformer模型实现了对输入数据的更精确理解和生成,从而大大提高了模型的表达能力。同时,自旋系统的引入也使得Transformer模型具备了更好的泛化能力,能够应对不同任务和领域的数据。其次,从实践角度来看,我们可以通过实验证明Transformer模型中的自旋系统对于模型的性能提升有着显著的影响。通过对Transformer模型在不同自旋系统设置下的性能进行比较,我们发现具有更多自旋系统的Transformer模型在各项指标上都有所提升。此外,我们还发现,通过合理调整自旋系统中各个组件的参数,可以进一步提高Transformer模型的性能。综上所述,Transformer模型之所以能够在自然语言处理等领域取得卓越的成就,很大程度上得益于其背后隐藏的自旋系统。这些自旋系统为Transformer模型提供了强大的并行计算能力和出色的泛化能力,使其成为当今最受欢迎的自然语言处理模型之一。然而,关于自旋系统在Transformer模型中的具体作用机制,仍然有待进一步的研究和探索。
8. 信息论下的贝叶斯重整化
贝叶斯重整化 ,一种受贝叶斯统计推断启发的完全信息理论的重整化方法,我们称之为贝叶斯重整化。贝叶斯重整化的主要观点是,Fisher度量定义了一个相关长度,它起到了一个重整化群尺度的作用,量化了概率分布空间中邻近点之间的可区分性。
贝叶斯重整化具有足够的通用性,即使在没有直接物理尺度的情况下也能应用,从而为数据科学环境中的重整化提供了一种理想的方法。我们将这个方程以及更广泛地使用贝叶斯推理动态更新信念的想法,称为动态贝叶斯推理(Dynamic Bayesian Inference,或Dynamical Bayes,DB)。DB的一个核心观察是,随着新数据的收集,“当前”最可能的模型流经“可能模型”的空间,流向真正负责生成观测数据的概率分布。
这一观察激发了这样一种想法,即重整化群流可以被视为与动态贝叶斯过程的“逆”过程,前者将数据生成模型降低到近似模型,后者将近似模型带回数据生成模型。

在2023年,Berman D S、Klinger M S以及Stapleton A G三位学者共同发表了一篇名为“Bayesian Renormalization”的文章,该论文被发表在了arXiv预印本平台上,预印本的编号为arXiv:2305.10491。
9. 重整化训练与采样生成过程
重整化群与生成式AI ,文中讲到,如果用Z代表一张脸,借助我们刚才学会的群的数学形式可以表达为:G(Z) = G1G2G3G…Gn( Z )。这里的G1到Gn对应不同层次上Operation 或者说Transformation,也就是在各个层次的潜变量(“眼角、眉梢、到额头、五官,脸型,神态”)构成的新坐标系里面的矩阵代表的变换,一如俄罗斯套娃。
大家知道,这些潜变量都是对应着简单的高斯分布的,其实都是个随机函数,Gx(Z)也就是Z这张脸在这些潜变量函数基张成的空间中的样子。概率分布是归一的,也就是normalize,反复的normalize就是renormalize。
对一张图像,重整化从细颗粒度到粗颗粒度,逐层提取潜变量Zn, 提取图像中蕴含的各层次的结构;而生成图像的过程就是从粗粒度,对潜变量的高斯概率分布进行采样,重建下一个层次的结构(类似你跟别人描述这个人浓眉大眼)。
重整化的群变换 Gn 在生成过程中用到 Gn 的逆。GPT 和其他大语言模型的使用的Transformer其实就可以类比这些重整化的群变换G,但是目前没有看到学术研究 Transformer 是否严格有逆,也就是是否构成严格意义上的群。OpenAI应该是找到了这个逆。这是猫师傅没有交给虎徒弟的绝招。
在2022年的《机器学习:科学和技术》杂志的第三卷第三期中,Hu H Y, Wu D, You Y Z等人提出了一种名为RG-Flow的分层可解释流模型,该模型基于重标化和稀疏先验。
10. 重整化群流作为最优输运
重整化群流作为最优输运 ,哈佛大学两位学者的RGF-OT这篇文章,他们不仅确定了精确重整化群流的方程等效于场的相对熵的最优输运梯度流,还巧妙的使用最优输运的思想将重整化群转化为变分问题,这种RG的变分形式除了具有理论意义外,还可用于设计计算传统场的重整化群流的神经网络。
尺度变换的每一步,RG Flow 的流向,都将会沿着最优输运的方向进行,也就是物理量的 RG Flow 尺度变换前的概率分布与尺度变换后的概率分布的距离最近的方向,而这就是 Wasserstein 距离决定的方向。
Wasserstein 距离是概率分布空间上的距离度量,在最优输运中起着核心作用,用于衡量两个概率分布之间的距离。世界的不断演进,都是冥冥中遵循最小化各种代价或成本的方式进行,最优输运某种意义上是自然演化的必然方向和准则。
Cotler J, Rezchikov S. Renormalization group flow as optimal transport[J]. Physical Review D, 2023, 108(2): 025003.
11. 大模型的数学物理认知框架
大模型的幻觉,解铃还须系铃人 ,文中总结了笔者对大模型的数理认知框架。
海量的文本或者多模态语料组成了大模型需要认知的外部世界的基本信息;嵌入构建高维概率化的语言空间,用来建模语言文字图像以及音视频,并对连续变量做离散化,例如时间序列, 人脑可能并不需要离散化。
预训练以重整化群流的方式进行,在不同尺度上提炼语料数据中的信息概率分布;重整化群流的每一步流动(自回归预测逼近训练语料概率分布),都沿着最优输运的成本最低方向进行。
重整化群在不动点附近因新语料带来微扰而发生对称性破缺,滑入不同的相空间;不同的相空间,对应某种意义上的范畴,可形象化为信息的结晶;这是大模型从语料中学到的内部世界模型。
在外部感官输入下(被提示置于某种上下文),大模型内部将限定在相应的高维语言概率空间的子空间内推理;推理是在子空间中采样,类比推理时跨范畴采样;采样不断进行,基于内部概率化了的世界模型(预训练获得的先验),针对感官输入(提示),做变分推断,最小化自由能,获取最佳采样分布q*,作为对导致感官输入的外部后验的预测。
12. 范畴的相变与知识的形成
范畴的相变与知识的形成 ,引用了万字长文介绍为大语言模型建立的“语言、统计和范畴”数学框架 文中的总结:语言范畴中的对象是语言中的表达式,表达式之间用多头注意力捕捉的概率表征关系,构成概率丰富范畴。
仔细观察这个用概率丰富化了的范畴,由节点和节点之间的边构成,节点与边的概率由重整化群流的学习过程,通过例如Transformer的注意力机制提取。不断训练,不断提取。
当边的数量少时,范畴中仅有小部件;更多训练,更多的关系被注意力捕捉,生成更多的边,大部件开始出现;持续学习,最终可以将几乎所有节点连结在一起。重整化群流一层层提取语料中的潜变量和潜变量之间的关系,潜变量形成概率丰富范畴中的节点,而潜变量之间的关系形成该范畴中概率表征的边。这是一个随机的生成过程。
重整化群流生成概率丰富范畴的过程,从上文描述看,特点符合类似 Erdős-Rényi 生成随机图(Random Graph)的随机过程,只不过更加庞大而且复杂的非同质随机图。随机图是许多复杂系统的基础,严格映射到随机图,证明同构,可以确定系统将发生相变。同样, 非同质随机图相变也已经被理论上证明。
主要参考文献
1. 薛定谔 《What is Life?》 https://www.cambridge.org/core/books/what-is-life/A876185F2DB06FF5C2CC67C9A60DAD7F
2. Karl Friston “The free-energy principle” https://www.nature.com/articles/nrn2787
3. Ashish Vaswani, et al. “Attention Is All You Need” https://arxiv.org/abs/1706.03762
4. Philip W. Anderson “More Is Different” https://www.science.org/doi/10.1126/science.177.4047.393
5. Robert Kolenkow《An Introduction to Groups and their Matrices for Science Students》https://assets.cambridge.org/97811088/31086/frontmatter/9781108831086_frontmatter.pdf
6. Hong-Ye Hu, et al. “RG-Flow: A hierarchical and explainable flow model based on renormalization group and sparse prior” https://arxiv.org/abs/2010.00029
7. Jordan Cotler, et al. “Renormalization Group Flow as Optimal Transport” https://arxiv.org/abs/2202.11737
8. David S. Berman, et al. “Bayesian Renormalization” https://arxiv.org/abs/2305.10491
9. Tai-Danae Bradley, et al. “An Enriched Category Theory of Language” https://arxiv.org/abs/2106.07890
本文来源:集智俱乐部 微信公众号
关注公众号了解更多
会员申请 请在公众号内回复“个人会员”或“单位会员
欢迎关注中国指挥与控制学会媒体矩阵
CICC官方网站
CICC官方微信公众号
《指挥与控制学报》官网
国际无人系统大会官网
中国指挥控制大会官网
全国兵棋推演大赛
全国空中智能博弈大赛
搜狐号
一点号 返回搜狐,查看更多
责任编辑:
CICC, ChatGPT, 人工智能, 物理



